
Heim >Datenbank >MySQL-Tutorial >Sehr beliebtes Teilen: Ideen zur MySQL-Optimierung, die mit der Produktion im Einklang stehen
Sehr beliebtes Teilen: Ideen zur MySQL-Optimierung, die mit der Produktion im Einklang stehen

- 藏色散人nach vorne
- 2021-11-05 14:16:082360Durchsuche
Vorwort
Der Ausgangspunkt für das Schreiben dieses Artikels ist die Aufzeichnung meiner gesammelten Erfahrungen im Umgang mit Daten am Arbeitsplatz. Während ich schreibe, stelle ich fest, dass aus jedem Punkt weiteres Hintergrundwissen abgeleitet wird, beispielsweise die Notwendigkeit einer Optimierung bei der Optimierung Der Index erfordert ein gewisses Verständnis für langsame Abfragen, Explain und andere verwandte Funktionen. Die Einführung von Elasticsearch erfordert beispielsweise das Lösen von Datensynchronisierungen, das Erlernen von Elasticsearch-Kenntnissen usw. Aufgrund der Länge des Artikels ist es unmöglich, jeden Punkt im Detail zu erklären Wie bei einem Video-Tutorial kann ich aufgrund meines begrenzten Wissens nur einige allgemeine Punkte zusammenfassen. Dennoch ist der Artikel bereits sehr lang. Wenn Sie sich für einen bestimmten Punkt interessieren, wenden Sie sich bitte an Baidu/Google, um detaillierte Informationen zu einzelnen Details zu erhalten.
Der Artikel ist ziemlich lang. Wenn Sie interessiert sind, möchten Sie ihn vielleicht durchlesen. Ich hoffe, Sie haben nicht Dutzende Minuten verschwendet. [Empfohlenes Lernen: „MySQL-Video-Tutorial“]
Denkperspektive
Die Datenbanktechnologie hat bisher die manuelle Verwaltungsphase, die Dateisystemphase und die Datenbanksystemphase durchlaufen.
In den Anfängen, als es noch kein Softwaresystem gab, konnte der reale Betrieb eines bestimmten Unternehmens auch durch die manuelle Verwaltungsphase der manuellen Buchhaltung und mündlichen Vereinbarungen realisiert werden. Diese Form existiert schon seit langem und ist relativ ineffiziente Lösung. In der nächsten Phase, mit der Entwicklung der Computertechnologie, gab es eine Dateisystemphase, die die manuelle Buchhaltung durch Excel-Tabellen ersetzte, was die Produktivität bis zu einem gewissen Grad verbesserte. In der Softwaresystemphase, bei der es sich um ein Datenbanksystem mit einfacher Bedienung und hoher Effizienz handelt, wurde die Produktivität erneut verbessert, spezifische Probleme in der realen Welt werden in Daten abstrahiert und das reale Geschäft wird durch den Fluss und die Änderung von Daten dargestellt. In Softwaresystemen besteht die Datenspeicherung im Allgemeinen aus einer relationalen Datenbank und mehreren nicht relationalen Datenbanken.
Die Datenbank ist eng mit dem Systemgeschäft verbunden. Dies erfordert, dass der Produktmanager den Datenspeicher- und Abfrageprozess beim Entwurf des Geschäfts versteht und ob neue Referenzen referenziert werden müssen. Ein vom Produktmanager entworfenes Unternehmen besteht beispielsweise darin, statistische Analysen und Zusammenfassungen von Daten für mehrere MySQL-Tabellen mit einem einzigen Tabellenvolumen von Millionen durchzuführen. Wenn MySQL-Mehrtabellenabfragen direkt verwendet werden, treten auf jeden Fall langsame Abfragen auf, die zu msyql führen In diesem Fall besteht die Lösung darin, entweder einen Kompromiss auf der Produktseite einzugehen oder den Technologie-Stack zu ändern.
In der Systemarchitektur und Datenbanklösung sollten wir diejenige wählen, die besser zu den Teamfähigkeiten des Unternehmens passt. In der frühen Phase des Systems wird jedoch die kostengünstigste Lösung sein. Wenn Sie auf die Banknotenfunktion der MySQL-Datenbank stoßen und nichts tun können, ist die Einführung der wichtigsten Softwaredienste mit Kernfunktionen die kostengünstigste Lösung. Wenn Sie auf Probleme stoßen, ist es an der Zeit, Ihren Wert widerzuspiegeln.
Ein armer Junge verliebt sich in ein reiches Mädchen. Die kurzfristige Süße ist der echten Klassenungleichheit nicht gewachsen. Das Happy End gibt es nur in der Fantasie des armen Jungen und der Fernsehserie von Lehrer Qiong Yao.
Wie man die Leistung der Datenspeicherung bei begrenzten Kosten verbessern kann, ist die zentrale Idee, die in diesem Artikel diskutiert wird.
Hintergrundwissen
Ich glaube, dass jeder in seiner täglichen Arbeit oft mit den folgenden Inhalten in Berührung kommt.
Relationale Datenbank
Relationale Datenbank ist eine Datenorganisation, die aus zweidimensionalen Tabellen und den Verbindungen zwischen ihnen besteht. Sie bietet Funktionen wie Transaktionsdatenkonsistenz und Datenpersistenz für die Software und ist der Kernspeicher des Softwaresystems. Dienste sind die Datenbanken, mit denen wir während der Entwicklung und bei Vorstellungsgesprächen am häufigsten in Kontakt kommen. Bei einigen kleinen Outsourcing-Projekten reicht MySQL aus, um alle Geschäftsanforderungen zu erfüllen. Es ist etwas, mit dem wir oft in Kontakt kommen, und es steckt tatsächlich voller Geheimnisse. Wir werden die Geheimnisse in den folgenden Kapiteln ausführlich besprechen.
Vorteile:
- Transaktionen
- Persistenz
- Relativ verbreitete SQL-Sprache
Probleme
- Sehr hohe Anforderungen an Festplatten-E/A
- Die Aggregationsabfrage großer Datenmengen ist ineffizient Überlastung
- Level Verschiedene durch Erweiterung verursachte Probleme sind schwer zu bewältigen
- Nicht-relationale Datenbank – NoSql
- Als relationale Datenspeichersoftware hat die MySQL-Datenbank Vor- und offensichtliche Nachteile, also die Datenmenge in der Software Wenn die Erweiterung und die Geschäftskomplexität weiter zunehmen, können wir nicht erwarten, alle Probleme durch die Verbesserung der Funktionen der MySQL-Datenbank zu lösen. Stattdessen müssen wir andere Speichersoftware einführen und verschiedene Arten von NoSQL verwenden, um das kontinuierliche Problem zu lösen Erweiterung des Datenvolumens des Softwaresystems und der Geschäftskomplexität. Es gibt kein Problem mit der Werbung.
Schlüsselwerttyp
In Unternehmen werden häufig die Inhalte bestimmter Tabellen abgefragt, die meisten Abfrageergebnisse bleiben jedoch unverändert, sodass Schlüsselwerte wie Memcached und Redis entstanden sind. Speichersoftware, Cache-Modul weit verbreitet in Systemen. Redis verfügt über mehr Datenstrukturen und Persistenz als Memcached und ist damit das am weitesten verbreitete NoSQL vom KV-Typ.
Suchtyp
Im Szenario der Volltextsuche kann die Abfrageoptimierung des MySQLB+-Baumindex den Index nicht treffen. Jede ähnliche Schlüsselwortabfrage ist ein vollständiger Tabellenscan Es ist weiterhin unterstützbar, aber beim Speichern der Daten treten langsame Abfragen auf. Wenn der Geschäftscode nicht gut geschrieben ist und in einer Transaktion eine Like-Abfrage aufgerufen wird, tritt eine Lesesperre auf. ElasticSearch mit invertiertem Index als Kern kann das Szenario der Volltextsuche perfekt erfüllen. Gleichzeitig unterstützt ElasticSearch auch große Datenmengen und die Dokumentation und Ökologie ist ebenfalls sehr gut Typ.
Dokumenttyp
Der Dokumenttyp NoSql bezieht sich auf einen Typ von NoSql, der halbstrukturierte Daten als Dokumente speichert, sodass der Dokumenttyp NoSql aufgrund dessen kein Schema hat Aufgrund der Eigenschaften von Schema können wir Daten nach Belieben speichern und lesen. Daher löst das Aufkommen von dokumentenbasiertem NoSql das Problem der unbequemen Erweiterung relationaler Datenbanktabellenstrukturen. Der Autor hat die
Spaltenformel
noch nie verwendet. Für Unternehmen einer bestimmten Größe ist häufig eine flexible Datenzusammenfassung in Echtzeit erforderlich. Diese Art von Geschäft ist nicht für die Lösung durch Vorberechnungslösungen geeignet Das Unternehmen kann einen Plan zum Berechnen und Zusammenfassen verwenden, aber wenn die Menge der zusammengefassten Daten zunimmt, wird der letzte Schritt des Sammelns der zusammengefassten Daten allmählich sehr langsam. Das spaltenorientierte NoSql ist das Produkt dieses Szenarios ist eine der repräsentativsten Technologien im Big-Data-Zeitalter. Die Anwendung von HBase ist jedoch sehr umfangreich und erfordert häufig einen vollständigen Satz von Hadoop-Ökosystemen. Das Unternehmen des Autors verwendet Alibaba Cloud kompatibel mit MySQL-Abfragesoftware für Anweisungen. Die leistungsstarken Abfragefunktionen der Zusammenfassungs- und Spaltenspeichersoftware reichen aus, um verschiedene Echtzeit- und flexible Datenzusammenfassungsdienste zu unterstützen.
Fall
Wenn man das Jahr 2021 als Zeitpunkt nimmt, beginnen die meisten Systeme in der Anfangsphase mit dem folgenden Plan. Als nächstes werde ich in diesem Fall langsam einige Anpassungen vornehmen.
Die Vorteile von Hardware-Upgrades nehmen mit der Zeit ab. Dies ist die schnellste Optimierungslösung, wenn Zeit und Personal knapp sind. Der Nutzen einer Software-Optimierung ist in Zukunft höher, aber auch der technische Personalbedarf ist in Zukunft höher. Wenn Zeit und Personal es zulassen, ist sie die kostengünstigste Optimierungslösung. Hardware- und Softwareoptimierung schließen sich nicht gegenseitig aus. Bei Bedarf können beide gleichzeitig die Obergrenze der MYSQL-Leistung erreichen.

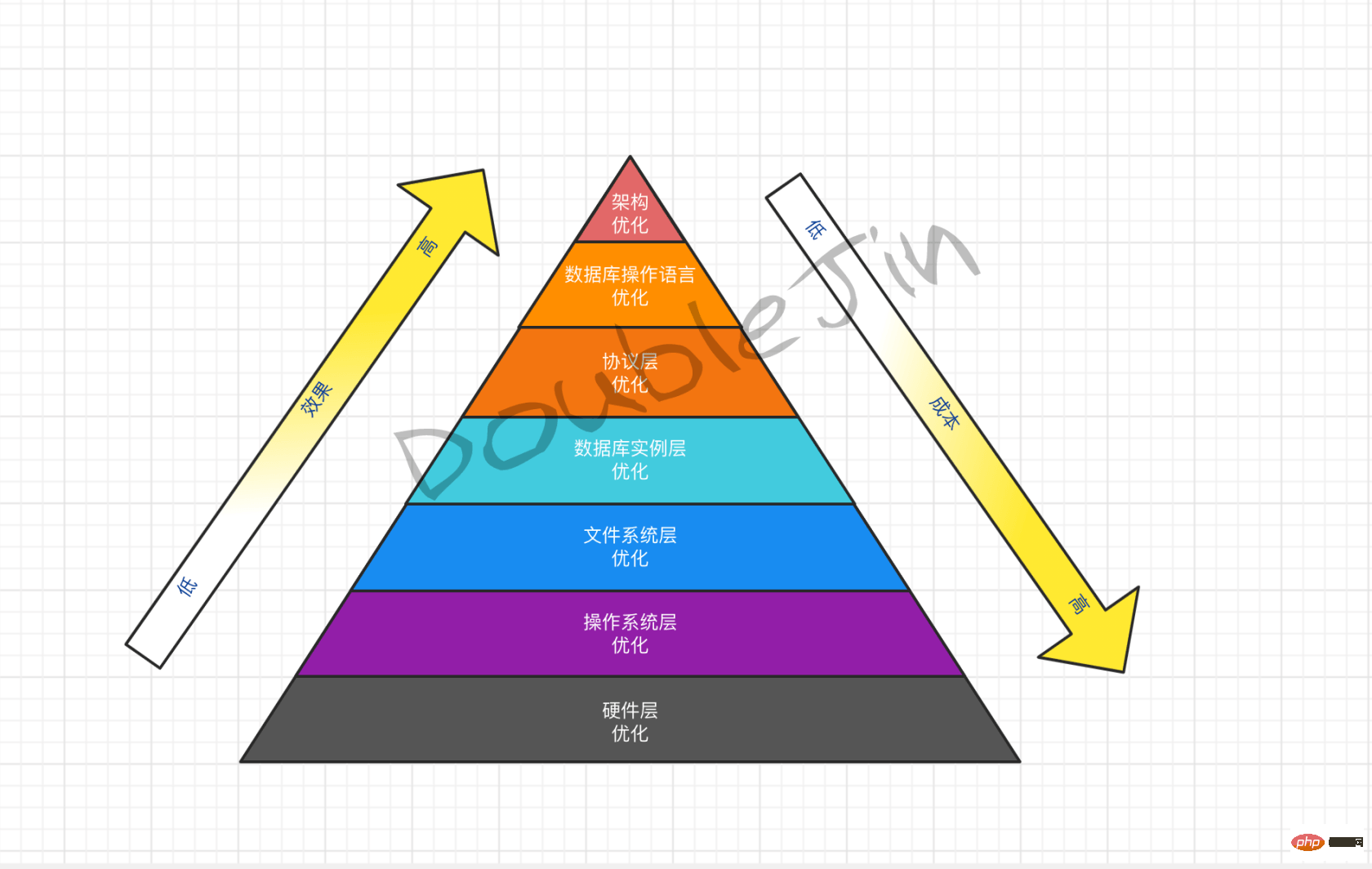
Phase 1
Festplatten-E/A verbessern, SSD-Festplatte verwenden (qualitative Verbesserung)- Speicher erhöhen, Abfrage-Cache-Speicherplatz erhöhenCPU-Anzahl erhöhen Anzahl der Kerne, Ausführungs-Threads erhöhen
- Phase zwei
- Aktivieren Sie die integrierte Lese- und Schreibtrennfunktion
- Phase drei
- Der MySQL-Dienst des Dienstanbieters wird durch eine Cloud-native verteilte Datenbank ersetzt.
- Aktivieren Sie die integrierte Lese- und Schreibtrennfunktion.
- Aktivieren Sie die integrierte Untertabellenfunktion.
Sanfte Optimierung - Abfrage - OLTP
OLTP wird hauptsächlich zum Aufzeichnen einer bestimmten Art von Geschäftsereignis verwendet, z. B. des Benutzerverhaltens. Wenn das Verhalten auftritt, zeichnet das System auf, wann und wo der Benutzer was getan hat. Eine solche Zeile (oder mehrere Zeilen). ) von Daten werden in der Datenbank hinzugefügt, gelöscht und geändert. Der Aktualisierungsverarbeitungsvorgang erfordert eine hohe Echtzeitleistung, starke Stabilität und die Sicherstellung einer erfolgreichen Datenaktualisierung in einer zeitnahen Art und Weise. Gängige Geschäftssysteme sind OLTP und die verwendeten Datenbanken sind Transaktionsdatenbanken wie MySlq, Oracle usw. Für OLTP sind die Verbesserung der Abfragegeschwindigkeit und der Dienststabilität der Kern der Optimierung

- Langsame Abfrage
- Erkennen Sie SQL mit Effizienzproblemen durch langsame Abfrageprotokolle
- Problem-SQL-Fehlerbehebungsrichtung
- Es liegt ein Problem mit dem Indexdesign vor
- Es liegt ein Problem mit der SQL-Anweisung vor
- Der falsche Index wurde ausgewählt in der Datenbank
- Eine einzelne Tabelle ist groß
- Erläutern Sie die detaillierte Analyse
- SQL-Ausführungsverhältnis anzeigen
- Indextrefferstatus anzeigen (Schlüsselpunkte)
- MySQL-Optimierer
- Wenn der Optimierer einen Index auswählt, wird dies der Fall sein Beziehen Sie sich auf die Kardinalität des Index.
- Die Kardinalität ist automatisch. Was verwaltet und geschätzt wird, ist möglicherweise nicht genau. Wenn der Index nicht trifft oder der falsche Index verwendet wird, liegt ein Problem mit dem Optimierer vor Die Indexinformationen und die Neuberechnung der Basis können die Verwendung von Indizes erzwingen und den Index für den Geschäftscode erzwingen (gemeinsamer Index) wird von der Ausführung der Abfrageanweisung bis zum zurückgegebenen Ergebnis usw. verwendet.)
- Abgedeckte Indizes können die Rückgabe von Tabellenabfragen reduzieren.
- Wenn die Datenabfrage mehr als einen Index verwendet, handelt es sich nicht um einen abdeckenden Index.
- count (Primärschlüssel) – wie oben
- count(1) – Scannt nur den Indexbaum, es gibt keinen Prozess zum Parsen von Datenzeilen, es ist schneller Theorie, aber es wird immer noch bestimmt, ob 1 null ist
-
- ORDER BY
- minimiert zusätzliche Sortierung, spezifiziert die Where-Bedingung
- Where-Anweisung und ORDER BY-Anweisungskombination erfüllen das Präfix ganz links
- Am effizientesten – Indexabdeckung (weniger Szenarien, die Wahrscheinlichkeit, dass sie auftritt)
- Das ORDER-Feld muss indiziert sein und sich im selben Index wie die WHERE-Bedingung und der Ausgabeinhalt befinden
- Paging-Abfrage
- Finden Sie zunächst eine Möglichkeit, die Indexabdeckung zu verwenden
- Zunächst Finden Sie die ID der erforderlichen Daten heraus und geben Sie die Tabelle zurück, um die endgültige Ergebnismenge zu erhalten ) MIT BTREE
- Vor MySQL5.6 müssen Sie dann den Index verwenden, um store_id in (1, 2) abzufragen Fügen Sie alle Tabellen hinzu, um film_id = 3 zu überprüfen
- MySQL5.6. Wenn es im Index gelesen werden kann, verwenden Sie direkt die Indexfilterung.
- Lose Index-Scan ,
guide_id) MIT BTREE- select film_id from table where guide_id = 3
- MySQL8.0 neue Funktionen
-
- Funktionsoperation
- Wenn Sie Funktionsoperationen für das Indexfeld ausführen, gibt der Optimierer den Index auf
- Optimieren Sie die Verwendung serverseitiger Logik anstelle von MySQL-Funktionen
-
store_id_guide_id(store_id,guide_id) USING BTREE - select * from table where store_id in (1,2) and guide_id = 3;
- MySQL5.6之前,需要先拿用索引查询store_id in (1,2),再全部加表验证film_id = 3
- MySQL5.6之后,如果索引中可以判读,直接使用索引过滤
-
- 松散索引扫描
- KEY
store_id_guide_id(store_id,guide_idDie Einzeltabellengröße ist zu groß. - Aktualisieren Sie MySQL. Basierend auf meiner aktuellen Erfahrung, Alibaba Wenn die Cloud-PolarDB-Clusterversion eine einzelne Tabelle mit 200 Millionen hat, gibt es kein Problem beim Abfragen des Trefferindex (hohe Priorität)
- Datenabrechnung – Beispielsweise können Pipeline-Daten gemäß a abgerechnet werden Bestimmter Zeitpunkt, um den neuesten Wert zu erhalten und die abgerechnete Pipeline zu übertragen. Gehen Sie zur Sicherungstabelle (mittlere Priorität)
- Trennung von heißen und kalten Daten – Daten, die nicht abgerechnet werden können, werden nach der Häufigkeit der Abfrage unterschieden, niedrige Frequenz Die Daten werden zur Abfrage in eine andere Tabelle übertragen, und der Eintrag der Abfrage wird in Bezug auf das Geschäft unterschieden (mittlere Priorität). Verwaltet das Einfügen und Abfragen nach der Aufteilung der Tabelle (mittlere Priorität).
- Aufteilung der Code-Implementierungstabelle nach bestimmten Regeln. Die Aufteilung einer einzelnen Tabelle in mehrere Tabellen erfordert nach der Aufteilung in den meisten Framework-ORMs von PHP und GO bestimmte Änderungen ORM in JAVA verfügt über native Unterstützung. Es wird empfohlen, dies in der frühen Phase des Projekts und später zu berücksichtigen. Je größer der Schwierigkeitsgrad (niedrige Priorität), desto sanfter die Optimierung
- KEY
- Sperre
- Je nach Granularität können MySQL-Sperren in globale Sperren, Sperren auf Tabellenebene und Zeilensperren unterteilt werden. Globale Sperren. Self-Google/Baidu Die Sperre ist in Tabellensperre (Datensperre) und Metadatensperre unterteilt. Tabellensperre, Selbstgoogle/Baidu, Metadatensperre, Selbstgoogle/Baidu, Zeilensperre sperrt Daten Zeilen, die in gemeinsame Sperren und exklusive Sperren unterteilt sind
- Parameterkonfiguration
- Passen Sie den Parameter innodb_lock_wait_timeout an
- Der Standardwert beträgt 50 Sekunden. Das heißt, wenn die Sperre nach 50 Sekunden Wartezeit nicht erworben wird, meldet die aktuelle Anweisung einen Fehler.
- Wenn die Wartezeit zu lang ist, melden Sie kann diesen Parameter entsprechend kürzen.
- Aktive Deadlock-Erkennung: innodb_deadlock_detect Außerhalb von Transaktionen so weit wie möglich, um die Anzahl der gesperrten Zeilen zu reduzieren Die Anzahl der Suchzeilen beträgt weniger als 100.000 – MySQL ist schwer zu transportieren. Verbessern Sie die CPU-, Io- und Speicherhardware von MySQL. Mehr als 100.000 Suchzeilen geeignet für die Volltextsuche, aber die Flexibilität der Datenstruktur ist schlecht.
- Datensynchronisierung
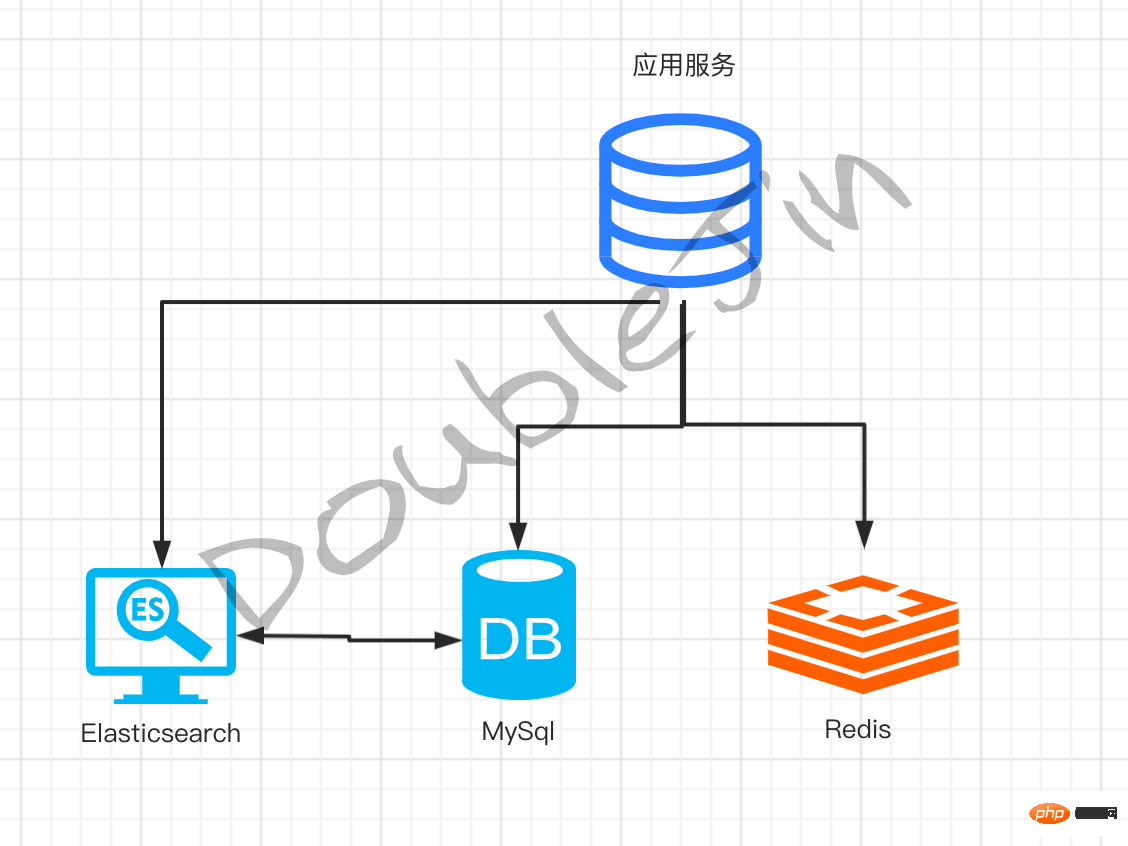
- Wenn der Geschäftscode Daten ändert, werden diese gleichzeitig mit Elasticsearch synchronisiert.
Das Abbrechen des Abonnements für das MySQL-Protokoll löst die Synchronisierung aus - Analog zur Tabelle
Feld von MySQL Sobald der Typ festgelegt ist, ist eine Änderung verboten und neue Felder sind zulässig - Passen Sie den Parameter innodb_lock_wait_timeout an
- Die spezifische Methode ist Google/Baidu
- Elasticsearch-Document
- Das Datendokument des Benutzers wird gespeichert in es - analog zur Zeile von MySQL
Durch Metadaten und Json-Objektzusammensetzung - Parameterkonfiguration
Metadaten und Json-Objektdetails self-google/baidu
- Elasticsearch-word segmenter
- self-google/baidu
Elasticsearch- invertierter Index (Schlüssel)- self-google/baidu
Elasticsearch-Aggregation AnalysisAutomatic google/baidu - Statistical Business-OLAP
OLAP wird für die Entscheidungsanalyse relativer Daten verwendet zu OLTP-Transaktionsverarbeitungsszenarien Es handelt sich um eine Anwendung in der Big-Data-Analyse. Die oben erwähnte Offline-Data-Warehouse-Idee ist kein spezifischer Technologie-Stack. Wenn Ihre Lösung die Idee der OLAP-Analyse und -Verarbeitung widerspiegeln kann, dann ist die Lösung. - Der frühe Aufbau eines Data Warehouse bezieht sich hauptsächlich auf die Modellierung und Zusammenfassung von Unternehmensdatenbanken wie ERP, CRM, SCM und anderen Daten in der Data Warehouse-Engine gemäß den Anforderungen der Entscheidungsanalyse Unterstützung der Management- und Personalentscheidungen (mittel- und langfristige strategische Entscheidungen). Mit der Entwicklung der IT-Technologie in Richtung Internet und Mobilität werden Datenquellen immer zahlreicher. Unstrukturierte Daten werden auf der Grundlage der ursprünglichen Geschäftsdatenbank angezeigt, z. B. Website-Protokolle, IoT-Gerätedaten, eingebettete APP-Daten usw. Die Menge dieser Daten Es ist mehrere Größenordnungen größer als bisherige strukturierte Daten.
- Unabhängig davon, wie sich das Unternehmen, mit dem OLAP konfrontiert ist, verändert, ist es untrennbar mit den folgenden Schritten verbunden: Bestimmen des Analysefelds –>Geschäftsdaten mit der Computerbibliothek synchronisieren –>Modellierung der Datenbereinigung –>Mit dem Data Warehouse synchronisieren –> ;Der Außenwelt zugänglich machen
- Die Berechnungsquellendatenbank wird speziell für die Datenbereinigung verwendet. Der Zweck besteht darin, eine Beeinträchtigung der Leistung der Geschäftsdatenbank während der Datenbereinigung zu vermeiden. Durch die Bereinigung der Daten in der Berechnungsquellendatenbank nach Geschäft und Dimension wird die Verwendbarkeit und Wiederverwendbarkeit der Daten erhöht und die endgültigen detaillierten Echtzeitdaten erhalten, die dann an das Data Warehouse übertragen und vom Data Warehouse bereitgestellt werden die endgültigen Entscheidungsanalysedaten.
- DEMO-Plan
- Produktionsplan
- Die Software in jedem Link kann durch Software mit derselben Funktion ersetzt werden. Wenn das Team vom Software-Implementierungsplan am überzeugtesten ist, dann ist der Plan OLAP.
- Zusammenfassung
- Optimierung muss bodenständig sein, mit schrittweiser Anhäufung von Fähigkeiten und mehreren Iterationsrunden und kann nicht über Nacht erreicht werden. Führen Sie mehrere Iterationsrunden auf der Grundlage Ihrer eigenen Grundlagen, Geschäftsszenarien und zukünftigen Entwicklungserwartungen durch.
Das Prinzip der Iteration besteht darin, zunächst die Effizienz eines einzelnen Softwaredienstes durch sanfte Optimierung und harte Optimierung zu verbessern. Wenn die Optimierungskosten niedriger sind als der Umsatz, beziehen Sie sich auf ausgereifte Lösungen auf dem Markt und führen Sie diese auf der Grundlage zukünftiger Entwicklungserwartungen ein Achten Sie bei der Verwendung neuer Software für kombinierte Innovationen darauf, diese nicht blind zu kopieren. Nur durch organische Integration können Sie die Auswirkungen von 1+1>2, 2+1>3 erzielen Wenn ein Engpass auftritt, wiederholen Sie diesen Vorgang. - Vielen Dank für das Lesen des gesamten Artikels. Die im Inhalt vorgeschlagenen Optimierungspunkte sind nicht unbedingt die besten Lösungen für Ihre persönliche Arbeit sind herzlich eingeladen, diese zu besprechen und auszutauschen.
Das obige ist der detaillierte Inhalt vonSehr beliebtes Teilen: Ideen zur MySQL-Optimierung, die mit der Produktion im Einklang stehen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was soll ich tun, wenn der MySQL-Index fehlschlägt? Kurze Analyse der Fehlergründe
- Was ist Kubernetes? So stellen Sie eine darauf basierende MySQL-Datenbank bereit
- Erhalten Sie ein umfassendes Verständnis der kombinierten Indizes in MySQL und sehen Sie die Unterschiede zu einspaltigen Indizes
- Analysieren Sie, was MySQL-Index-Pushdown ist. Hilft es bei der Optimierung?