
Heim >Backend-Entwicklung >Python-Tutorial >Ausführliche Erläuterung des URL-Crawlers, des Anforderungsmoduls und des Parse-Moduls von Python
Ausführliche Erläuterung des URL-Crawlers, des Anforderungsmoduls und des Parse-Moduls von Python

- coldplay.xixinach vorne
- 2021-03-21 15:15:584885Durchsuche
„Artikelverzeichnis“
 URL analysieren
URL analysieren
Escape-URL
- robots.txt-Datei
- (kostenlose Lernempfehlung:
- Python-Video-Tutorial
- )
urllib-
- Achten Sie auf Versionsunterschiede. Es gibt 3 Versionen von
urllib: Python2.X enthält die Moduleurllibundurllib2und Python3 code>urllib2 und urlparse werden in das Paketurllibsynthetisiert, währendurllib3ein neues Toolpaket eines Drittanbieters ist. Wenn Sie auf Probleme wie „Kein Modul namens urllib2“ stoßen, liegt dies fast immer an unterschiedlichen Python-Versionen. -
urllib3ist eine leistungsstarke, wohldefinierte Python-Bibliothek für HTTP-Clients. Es bietet viele Funktionen, die in der Python-Standardbibliothek nicht zu finden sind: Komprimierungskodierung, Verbindungspooling, Thread-Sicherheit, SSL/TLS-Authentifizierung, HTTP- und SCOCKS-Proxys usw. Es kann über pip installiert werden:pip install urllib3
urllibist ein Tool zur Verarbeitung von URLs im Python-Paket , der Quellcode befindet sich unter /Lib/. Es enthält mehrere Module: das Modulrequest, das zum Öffnen, Lesen und Schreiben von URLs verwendet wird, das Modulerror, das durch das Modulrequestverursachte Ausnahmen verursacht, und das Modulparsewird zum Parsen von URLs verwendet, das Modulresponsewird zur Antwortverarbeitung verwendet und das Modulrobotparserwird zur Analyse von Robotern verwendet .txt-Dateien. Sie können den neuesten Code auch über GitHub herunterladen:
Sie können den neuesten Code auch über GitHub herunterladen: - Achten Sie auf Versionsunterschiede. Es gibt 3 Versionen von
git clone git://github.com/shazow/urllib3.git python setup.py install
urllib3 Referenzdokumentation: https://urllib3.readthedocs.io/en/latest/ request-Modul urllib.request Das Modul definiert Funktionen und Klassen zum Öffnen von URLs in Anwendungen wie Identitätsauthentifizierung, Umleitung und Cookies. Lassen Sie uns kurz das request-Paket vorstellen. Dieses Paket wird für erweiterte Nicht-Low-Level-HTTP-Client-Schnittstellen verwendet. Seine Fehlertoleranz ist leistungsfähiger als das request-Modul. request verwendet urllib3, das die Funktionen von urllib2 erbt, HTTP-Verbindungspersistenz und Verbindungspooling unterstützt, die Verwendung von Cookies zur Aufrechterhaltung von Sitzungen, Datei-Uploads, automatische Dekomprimierung, Unicode-Antworten, HTTP(S)-Proxy unterstützt, usw. . Weitere Einzelheiten finden Sie im Dokument http://requests.readthedocs.io.
urllib.request vorgestellt. Zugriffs-URL
urllib是Python中用来处理URL的工具包,源码位于/Lib/下。它包含了几个模块:用于打开及读写的urls的request模块、由request模块引起异常的error模块、用于解析urls的parse模块、用于响应处理的response模块、分析robots.txt文件的robotparser模块。
注意版本差异。urllib有3个版本:Python2.X包含urllib、urllib2模块,Python3.X把urllib、urllib2以及urlparse合成到urllib包中,而urllib3是新增的第三方工具包。若遇到"No module named urllib2"等问题几乎都是Python版本不同导致的。
urllib3是一个功能强大、条例清晰、用于HTTP客户端的Python库。它提供了许多Python标准库里所没有的特性:压缩编码、连接池、线程安全、SSL/TLS验证、HTTP和SCOCKS代理等。可以通过pip进行安装:pip install urllib3
也可以通过GitHub下载最新代码:
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=false,context=None)
urllib3参考文档:https://urllib3.readthedocs.io/en/latest/
request模块
urllib.request模块定义了身份认证、重定向、cookies等应用中打开url的函数和类。
再简单介绍下request包,该包用于高级的非底层的HTTP客户端接口,容错能力比request模块强大。request使用的是urllib3,它继承了urllib2的特性,支持HTTP连接保持和连接池,支持使用cookie保持会话、文件上传、自动解压缩、Unicode响应、HTTP(S)代理等。更多具体可参考文档http://requests.readthedocs.io。
下面将介绍urllib.request模块常用函数和类。
访问URL
一、urlopen()
from urllib import requestwith request.urlopen("http://www.baidu.com") as f:
print(f.status)
print(f.getheaders())#运行结果如下200[('Bdpagetype', '1'), ('Bdqid', '0x8583c98f0000787e'), ('Cache-Control', 'private'), ('Content-Type', 'text/html;charset=utf-8'), ('Date', 'Fri, 19 Mar 2021 08:26:03 GMT'), ('Expires', 'Fri, 19 Mar 2021 08:25:27 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BAIDUID=B050D0981EE3A706D726852655C9FA21:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BIDUPSID=B050D0981EE3A706D726852655C9FA21; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1616142363; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BAIDUID=B050D0981EE3A706FA20DF440C89F27F:FG=1; max-age=31536000; expires=Sat, 19-Mar-22 08:26:03 GMT; domain=.baidu.com; path=/; version=1; comment=bd'), ('Set-Cookie', 'BDSVRTM=0; path=/'), ('Set-Cookie', 'BD_HOME=1; path=/'), ('Set-Cookie', 'H_PS_PSSID=33272_33710_33690_33594_33600_33624_33714_33265; path=/; domain=.baidu.com'), ('Traceid', '161614236308368819309620754845011048574'), ('Vary', 'Accept-Encoding'), ('Vary', 'Accept-Encoding'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('Connection', 'close'), ('Transfer-Encoding', 'chunked')]
该函数用于抓取URL数据,十分重要。带有如上所示的参数,除了URL参数外(字符串或Request对象)其余参数都有默认值。
①URL参数
from urllib import parsefrom urllib import request
data = bytes(parse.urlencode({"pro":"value"}),encoding="utf8")response = request.urlopen("http://httpbin.org/post",data=data)print(response.read())#运行结果如下b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "pro": "value"\n }, \n "headers": {\n "Accept-Encoding": "identity", \n "Content-Length": "9", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.9", \n "X-Amzn-Trace-Id": "Root=1-60545f5e-7428b29435ce744004d98afa"\n }, \n "json": null, \n "origin": "112.48.80.243", \n "url": "http://httpbin.org/post"\n}\n'
②data参数
如果向服务器发送数据,那么data参数必须是一个有数据的byes对象,否则为None。在Python3.2之后可以是一个iterable对象。若是,则headers中必须带有Content-Length参数。HTTP请求使用POST方法时,data必须有数据;使用GET方法时,data写None即可。
from urllib import request
response = request.urlopen("http://httpbin.org/get",timeout=1)print(response.read())#运行结果如下b'{\n "args": {}, \n "headers": {\n "Accept-Encoding": "identity", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.9", \n "X-Amzn-Trace-Id": "Root=1-605469dd-76a6d963171127c213d9a9ab"\n }, \n "origin": "112.48.80.243", \n "url": "http://httpbin.org/get"\n}\n'
对数据进行POST请求,需要转码bytes类型或者iterable类型。这里通过bytes()进行字节转换,考虑到第一个参数为字符串,所以需要利用parse模块(下面会讲)的urlencode()方法对上传的数据进行字符串转换,同时指定编码格式为utf8。测试网址httpbin.org可以提供HTTP测试,从返回的内容可以看出提交以表单form作为属性、以字典作为属性值。
③timeout参数
该参数是可选的,以秒为单位指定一个超时时间,若超过该时间则任何操作都会被阻止,如果没有指定,那么默认会取sock.GLOBAL_DEFAULT_TIMEOUT对应的值。该参数仅对http、https、ftp连接有效。
超时后会抛出urllib.error.URLError:
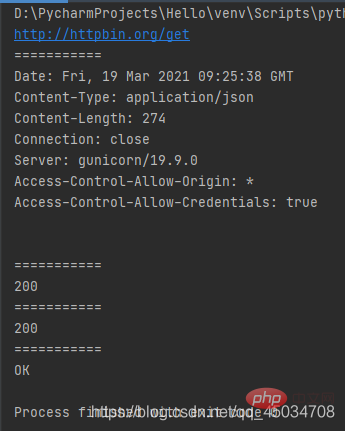
from urllib import request
response = request.urlopen("http://httpbin.org/get")print(response.geturl())print("===========")print(response.info())print("===========")print(response.getcode())print("===========")print(response.status)print("===========")print(response.msg)
④返回对象的常用方法和属性
除了前三个urlopen() 1. urlopen()
urllib.request.build_opener([handler1 [handler2, ...]])
- Diese Funktion wird zum Erfassen von URL-Daten verwendet und ist sehr wichtig. Bei den oben gezeigten Parametern haben die übrigen Parameter mit Ausnahme der URL-Parameter (String oder
- ①URL-Parameter
urllib.request.install_opener(opener)
②Datenparameter- Wenn Daten an den Server gesendet werden, muss der Datenparameter ein
byes-Objekt mit Daten sein, andernfalls ist er None. Nach Python 3.2 kann es ein iterierbares Objekt sein. Wenn ja, muss der Content-Length-Parameter inheadersenthalten sein. Wenn die HTTP-Anfrage die MethodePOSTverwendet, müssen Daten Daten enthalten; bei Verwendung der MethodeGETkönnen Daten als „Keine“ geschrieben werden.
Request-Objekt) Standardwerte. class urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
POST-Anfrage für Daten zu stellen, müssen Sie den Typ bytes oder den Typ iterable transkodieren. Hier wird die Bytekonvertierung über bytes() durchgeführt. Da der erste Parameter eine Zeichenfolge ist, muss die Methode urlencode() des Parse-Moduls verwendet werden (siehe). unten). Die hochgeladenen Daten werden in Zeichenfolgen konvertiert und das Kodierungsformat wird als utf8 angegeben. Die Testwebsite httpbin.org kann HTTP-Tests bereitstellen. Aus dem zurückgegebenen Inhalt können wir ersehen, dass die Übermittlung ein Formular als Attribut und ein Wörterbuch als Attributwert verwendet. Die Ausnahme urllib.error.URLError:from urllib import requestfrom urllib import parse
data = parse.urlencode({"name":"baidu"}).encode('utf-8')headers = {'User-Agent':'wzlodq'}req = request.Request(url="http://httpbin.org/post",data=data,headers=headers,method="POST")response = request.urlopen(req)print(response.read())#运行结果如下b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "name": "baidu"\n }, \n "headers": {\n "Accept-Encoding": "identity", \n "Content-Length": "10", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "wzlodq", \n "X-Amzn-Trace-Id": "Root=1-605491a4-1fcf3df01a8b3c3e22b5edce"\n }, \n "json": null, \n "origin": "112.48.80.34", \n "url": "http://httpbin.org/post"\n}\n'
 ④Gibt die allgemeinen Methoden und Eigenschaften des Objekts zurück
④Gibt die allgemeinen Methoden und Eigenschaften des Objekts zurück
Zusätzlich zu den ersten drei allgemeinen urlopen()-Parametern gibt diese Funktion das dateiähnliche Objekt zurück, das als Kontextmanager (Kontextmanager) verwendet wird enthält die folgende Methode:
- 1xx(informational):请求已经收到,正在进行中。
- 2xx(successful):请求成功接收,解析,完成。
- 3xx(Redirection):需要重定向。
- 4xx(Client Error):客户端问题,请求存在语法错误,网址未找到。
- 5xx(Server Error):服务器问题。
二、build_opener()
urllib.request.build_opener([handler1 [handler2, ...]])
该函数不支持验证、cookie及其他HTTP高级功能。要支持这些功能必须使用build_opener()函数自定义OpenerDirector对象,称之为Opener。
build_opener()函数返回的是OpenerDirector实例,而且是按给定的顺序链接处理程序的。作为OpenerDirector实例,可以从OpenerDirector类的定义看出他具有addheaders、handlers、handle_open、add_handler()、open()、close()等属性或方法。open()方法与urlopen()函数的功能相同。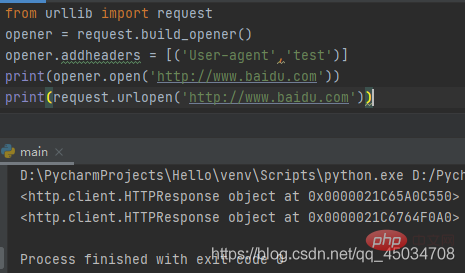
上述代码通过修改http报头进行HTTP高级功能操作,然后利用返回对象open()进行请求,返回结果与urlopen()一样,只是内存位置不同而已。
实际上urllib.request.urlopen()方法只是一个Opener,如果安装启动器没有使用urlopen启动,调用的就是OpenerDirector.open()方法。那么如何设置默认全局启动器呢?就涉及下面的install_opener函数。
三、install_opener()
urllib.request.install_opener(opener)
安装OpenerDirector实例作为默认全局启动器。
首先导入request模块,实例化一个HTTPBasicAuthHandler对象,然后通过利用add_password()添加用户名和密码来创建一个认证处理器,利用urllib.request.build_opener()方法来调用该处理器以构建Opener,并使其作为默认全局启动器,这样Opener在发生请求时具备了认证功能。通过Opener的open()方法打开链接完成认证。
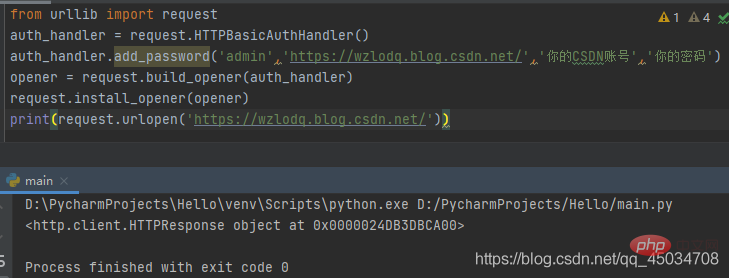
当然了,CSDN不需要账号密码也可以访问,读者还可以在其他网站上用自己的账号进行测试。
除了上述方法外,还有将路径转换为URL的pathname2url(path)、将URL转换为路径的url2pathname(path),以及返回方案至代理服务器URL映射字典的getproxies()等方法。
Request类
前面介绍的urlopen()方法可以满足一般基本URL请求,如果需要添加headers信息,就要考虑更为强大的Request类了。Request类是URL请求的抽象,包含了许多参数,并定义了一系列属性和方法。
一、定义
class urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
- 参数url是有效网址的字符串,同
urlopen()方法中一样,data参数也是。 - headers是一个字典,可以通过
add_header()以键值进行调用。通常用于爬虫爬取数据时或者Web请求时更改User-Agent标头值参数来进行请求。 - origin_req_host是原始请求主机,比如请求的是针对HTML文档中的图像的,则该请求主机是包含图像页面所在的主机。
- Unverifiable指示请求是否是无法验证的。
- method指示使用的是HTTP请求方法。常用的有GET、POST、PUT、DELETE等,
代码示例:
from urllib import requestfrom urllib import parse
data = parse.urlencode({"name":"baidu"}).encode('utf-8')headers = {'User-Agent':'wzlodq'}req = request.Request(url="http://httpbin.org/post",data=data,headers=headers,method="POST")response = request.urlopen(req)print(response.read())#运行结果如下b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "name": "baidu"\n }, \n "headers": {\n "Accept-Encoding": "identity", \n "Content-Length": "10", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "wzlodq", \n "X-Amzn-Trace-Id": "Root=1-605491a4-1fcf3df01a8b3c3e22b5edce"\n }, \n "json": null, \n "origin": "112.48.80.34", \n "url": "http://httpbin.org/post"\n}\n'
注意data参数和前面一样需是字节流类型的,不同的是调用Request类进行请求。
二、属性方法
①Request.full_url
full_url属性包含setter、getter和deleter。如果原始请求URL片段存在,那么得到的full_url将返回原始请求的URL片段,通过添加修饰器@property将原始URL传递给构造函数。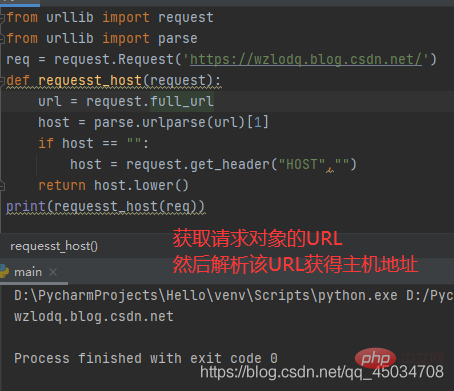
②Request.type:获取请求对象的协议类型。
③Request.host:获取URL主机,可能含有端口的主机。
④Request.origin_req_host:发出请求的原始主机,没有端口。
⑤Request.get_method():返回显示HTTP请求方法的字符串。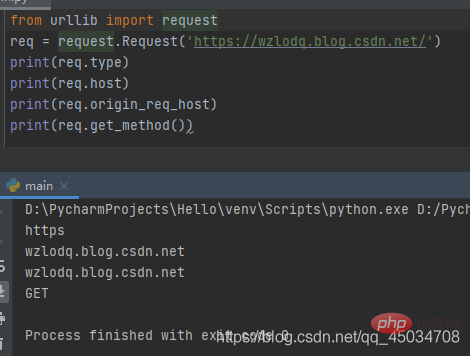
(插播反爬信息 )博主CSDN地址:https://wzlodq.blog.csdn.net/
⑥Request.add_header(key,val):向请求中添加标头。
from urllib import requestfrom urllib import parse
data = bytes(parse.urlencode({'name':'baidu'}),encoding='utf-8')req = request.Request('http://httpbin.org/post',data,method='POST')req.add_header('User-agent','test')response = request.urlopen(req)print(response.read().decode('utf-8'))
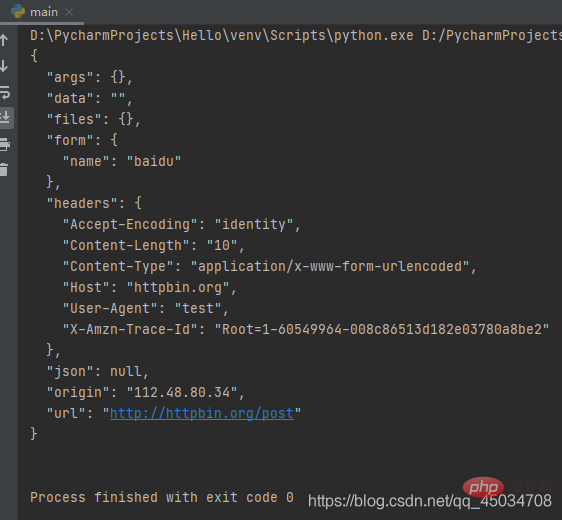
上述代码中,通过add_header()传入了User-Agent,在爬虫过程中,常常通过循环调用该方法来添加不同的User-Agent进行请求,避免服务器针对某一User-Agent的禁用。
其他类
BaseHandler为所有注册处理程序的基类,并且只处理注册的简单机制,从定义上看,BaseHandler提供了一个添加基类的add_parent()方法,后面介绍的类都是继承该类操作的。
- HTTPErrorProcessor:用于HTTP错误响应过程。
- HTTPDefaultErrorHandler:用于处理HTTP响应错误。
- ProxyHandler:用于设置代理。
- HTTPRedirectHandler:用于设置重定向。
- HTTPCookieProcessor:用于处理cookie。
- HEEPBasicAuthHandler:用于管理认证。
parse模块
parse模块用于分解URL字符串为各个组成部分,包括寻址方案、网络位置、路径等,也可将这些部分组成URL字符串,同时可以对“相对URL"进行转换等。
解析URL
一、urllib.parse.urlparse(urlstring,scheme=’’,allow_fragments=True)
解析URL为6个部分,即返回一个6元组(tuple子类的实例),tuple类具有下标所示的属性:
| 属性 | 说明 | 对应下标指数 | 不存在时的取值 |
|---|---|---|---|
| scheme | URL方案说明符 0 | scheme参数 | |
| netloc | 网络位置部分 | 1 | 空字符串 |
| path | 分层路径 | 2 | 空字符串 |
| params | 最后路径元素的参数 | 3 | 空字符串 |
| query | 查询组件 | 4 | 空字符串 |
| fragment | 片段标识符 | 5 | 空字符串 |
| username | 用户名 | None | |
| password | 密码 | None | |
| hostname | 主机名 | None | |
| port | 端口号 | None |
最后组成的URL结构为scheme://netloc/path;parameters?query#fragment
举个栗子:
from urllib.parse import *res = urlparse('https://wzlodq.blog.csdn.net/article/details/113597816')print(res)print(res.scheme)print(res.netloc)print(res.path)print(res.params)print(res.query)print(res.username)print(res.password)print(res.hostname)print(res.port)print(res.geturl())print(tuple(res))print(res[0])print(res[1])print(res[2])
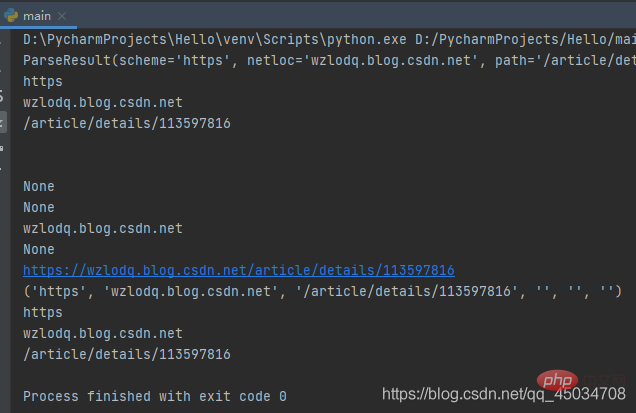
需要注意的是urlparse有时并不能很好地识别netloc,它会假定相对URL以路径分量开始,将其取值放在path中。
二、urllib.parse.urlunparse(parts)
是urlparse()的逆操作,即将urlparse()返回的原则构建一个URL。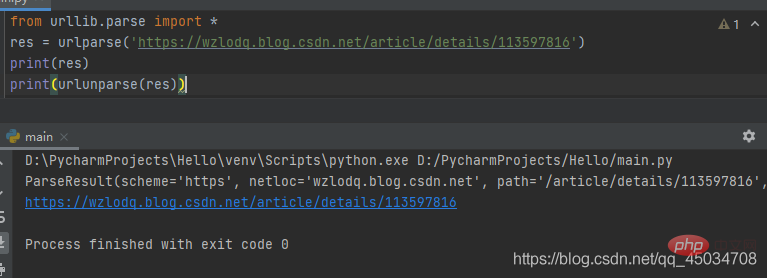
三、urllib.parse.urlsplit(urlstring,scheme=’’.allow_fragments=True)
类似urlparse(),但不会分离参数,即返回的元组对象没有params元素,是一个五元组,对应下标指数也发生了改变。
from urllib.parse import *sp = urlsplit('https://wzlodq.blog.csdn.net/article/details/113597816')print(sp)#运行结果如下SplitResult(scheme='https', netloc='wzlodq.blog.csdn.net', path='/article/details/113597816', query='', fragment='')
四、urllib.parse.urlunsplit(parts)
类似urlunparse(),是urlsplit()的逆操作,不再赘述。
五、urllib.parse.urljoin(base,url,allow_fragments=True)
该函数主要组合基本网址(base)与另一个网址(url)以构建新的完整网址。
相对路径和绝对路径的url组合是不同的,而且相对路径是以最后部分路径进行替换处理的: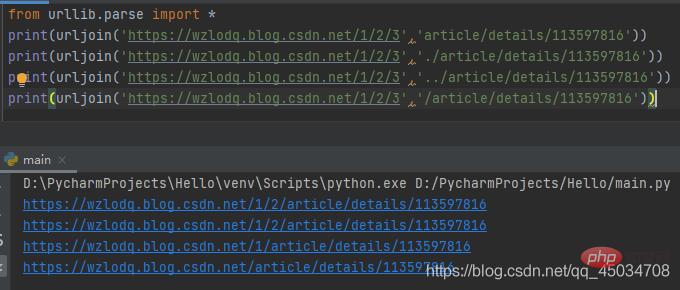
六、urllib.parse.urldefrag(url)
根据url进行分割,如果url包含片段标识符,就返回url对应片段标识符前的网址,fragment取片段标识符后的值。如果url没有片段标识符,那么fragment为空字符串。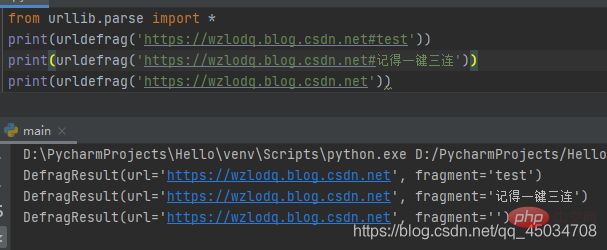
转义URL
URL转义可以避免某些字符引起歧义,通过引用特殊字符并适当编排非ASCII文本使其作为URL组件安全使用。同时也支持反转这些操作,以便从URL组件内容重新创建原始数据。
一、urllib.parse.quote(string,safe=’/’,encoding=None,errors=None)
使用%xx转义替换string中的特殊字符,其中字母、数字和字符’_.-‘不会进行转义。默认情况下,此函数用于转义URL的路径部分,可选的safe参数指定不应转义的其他ASCII字符——其默认值为’/’。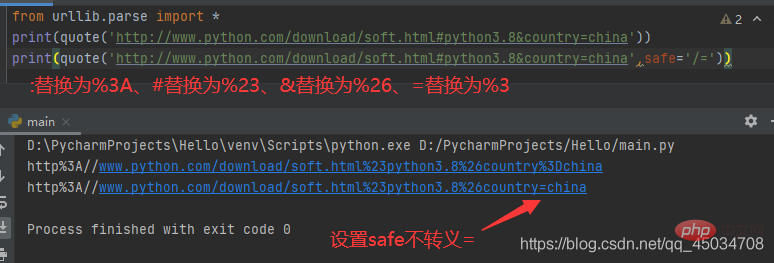
特别注意的是若string是bytes,encoding和errors就无法指定,否则报错TypeError。
二、urllib.parse.unquote(string,encoding=‘utf-8’,errors=‘replace’)
该函数时quote()的逆操作,即将%xx转义为等效的单字符。参数encoding和errors用来指定%xx编码序列解码为Unicode字符,同bytes.decode()方法。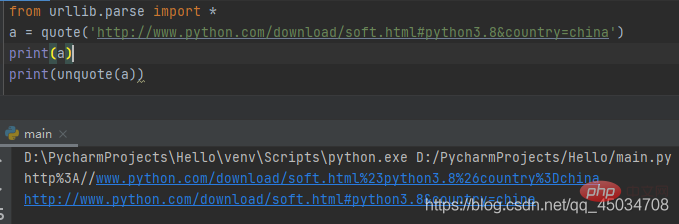
三、urllib.parse.quote_plus(string,safe=’’,encoding=None,errors=None)
该函数时quote()的增强版,与之不同的是用+替换空格,而且如果原始URL有字符,那么+将被转义。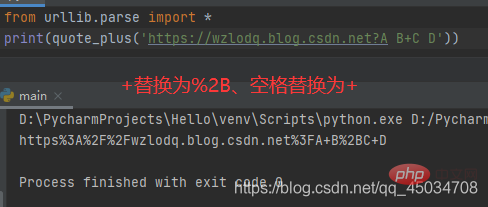
四、urllib.parse.unquote_plus(string,encoding=‘utf-8’,errors=‘replace’)
类似unquote(),不再赘述。
五、urllib.parse.urlencode(query,doseq=False,safe=’’,encoding=None,errors=None,quote_via=quote_plus)
该函数前面提到过,通常在使用HTTP进行POST请求传递的数据进行编码时使用。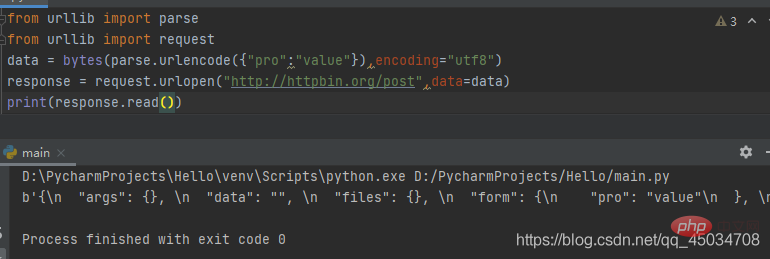
robots.txt文件
robotparser模块很简单,仅定义了3个类(RobotFileParser、RuleLine、Entry)。从__all__属性来看也就RobotFileParser一个类(用于处理有关特定用户代理是否可以发布robots.txt文件的网站上提前网址内容)。
robots文件类似一个协议文件,搜索引擎访问网站时查看的第一个文件,会告诉爬虫或者蜘蛛程序在服务器上可以查看什么文件。
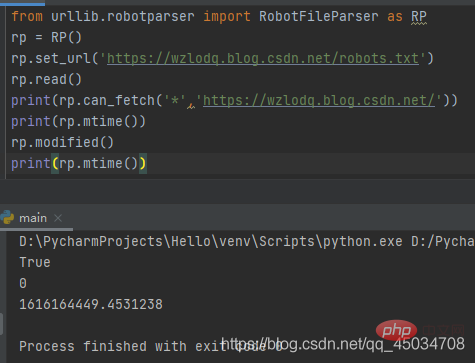
RobotFileParser类有一个url参数,常用以下方法:
- set_url(): wird verwendet, um die URL festzulegen, die auf die robots.txt-Datei verweist.
- read(): Liest die robots.txt-URL und stellt sie dem Parser zur Verfügung.
- parse(): wird zum Parsen der robots.txt-Datei verwendet.
- can_fetch(): Wird verwendet, um zu bestimmen, ob die URL im Voraus abgerufen werden kann.
- mtime(): Gibt die Zeit zurück, zu der die robots.txt-Datei zuletzt gecrawlt wurde.
- modified(): Legt den Zeitpunkt fest, zu dem die robots.txt-Datei zuletzt gecrawlt wurde, auf den aktuellen Zeitpunkt.
Viele kostenlose Lernempfehlungen finden Sie im Python-Tutorial(Video)
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung des URL-Crawlers, des Anforderungsmoduls und des Parse-Moduls von Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!