
Heim >Backend-Entwicklung >Python-Tutorial >Python-Datenanalyse: Praktischer Überblick über die Datenanalyse
Python-Datenanalyse: Praktischer Überblick über die Datenanalyse

- coldplay.xixinach vorne
- 2021-01-06 09:48:392249Durchsuche
Python-TutorialDie Spalte stellt Übersichtsdaten vor.

Empfohlen (kostenlos): Python-Tutorial
Artikelverzeichnis
- 1. Einführung in die Datenanalyse
- 1. Grundlagen des Big-Data-Zeitalters
- 2. Datenanalyst Berufsaussichten
- 3. Der Weg zum Datenanalysten
- 1. Python-Version
- 3. Umgebungsvariablenkonfiguration
- 4. Installieren Sie pip
- 5. Einführung und Installation von Anaconda
- 1. Laden Sie Anaconda herunter und installieren Sie es.3 Tools
- 4. und Verarbeitung Die Daten werden in der MongoDB-Datenbank gespeichert.
Aktuelle Daten Es hat ein - explosives Wachstum gezeigt, und jede Minute kann es zu Folgendem kommen:
-
- 13.000+ iPhone-App-Downloads
- 98.000+ neue Weibo-Beiträge auf Twitter
- 168 Millionen+ E-Mails gesendet
- 12306 1840+ ausgestellte Tickets
-
- Im Zeitalter von Big Data haben drei große Veränderungen stattgefunden:
- Von Zufallsstichproben zu vollständigen Daten
- Von Genauigkeit zu Verwirrung
- Von Ursache und Wirkung Relevant für verwandte Beziehungen
- Nennen Sie ein typisches Beispiel:
- Männer kaufen etwas Bier, wenn sie in den Supermarkt gehen, um Windeln zu kaufen. Die Ergebnisse der Big-Data-Analyse veranlassen den Supermarkt, etwas Bier in die Nähe der Windelregale zu stellen und so den Umsatz zu steigern und Windeln zu kaufen Es besteht kein kausaler Zusammenhang mit dem Bierkauf, es besteht jedoch ein gewisser Zusammenhang.
- Der inländische Big-Data-Anwendungsstatus ist wie folgt (von CSDN):
Datenanalysten
Statistische Analyse Prädiktive Analyse
Prozessoptimierung
- Plattformentwicklung
- Anwendungsentwicklung
- Technischer Support
- Datenarchitekt
- Architekturdesign
- Der Grund, warum Sie Datenanalyse erlernen sollten, liegt darin, dass Daten immer häufiger und kostengünstiger werden und die Analyse Daten liefern kann, die knapp sind und
Service. 2. Karriereaussichten für Datenanalysten
F: Die Kapazität des Ofens ist begrenzt. Welche Brotsorten sollten wir für die Herstellung auswählen?
Der Schlüssel besteht darin, das Starprodukt zu finden. Dazu muss der Gesamtumsatz an Brot gezählt, dann der relative Anteil jeder Brotsorte am Gesamtumsatz berechnet und der Produktion von Produktkombinationen Vorrang gegeben werden, die 70 % ausmachen können. des Umsatzes. Dabei werden die statistische Häufigkeitsverteilungstabelle und das Histogramm verwendet. Diese Analysemethode wird wie folgt auch ABC-Analysemethode genannt: 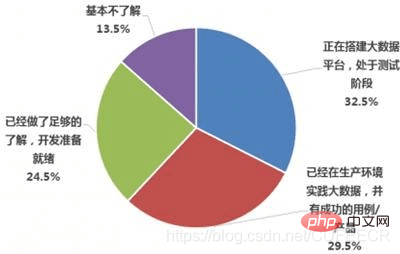
Bewertung der Wirksamkeit des Marketingplans
Bei der Statistik geht es nicht nur um die Analyse von Daten, sondern um die Ergebnisse Der Schlüssel zur Analyse liegt darin, darüber zu spekulieren, wie man das Kundenverhalten beeinflussen kann, es in einem spezifischen „Geschäftsplan“ zu formulieren und entsprechend zu handeln.- F: Wenn Sie Brot online verkaufen möchten, welche Art von Werbung ist effektiver?
- A: Schreiben Sie zwei Arten von Texten und lassen Sie sie eine Zeit lang laufen, um zu sehen, wie effektiv sie sind.
- Um die Werbewirksamkeit zu vergleichen, ist es am besten, statistische
- randomisierte kontrollierte Experimente zu verwenden, um zwei Arten von Anzeigen nach einer gewissen Zeit zufällig erscheinen zu lassen. Beobachten Sie, welche Werbewirkung besser ist, und verwenden Sie dann die Werbung mit der besseren Leistung auf einer großer Maßstab.
- Produktqualitätskontrolle
F: Wie kann man am Brot erkennen, ob der Bäcker Abstriche gemacht hat? - A: Überprüfen Sie stichprobenartig ein paar Brote und wiegen Sie sie, um zu sehen, ob der Gewichtsunterschied zu groß ist.
- Sie müssen zuerst das durchschnittliche Brotgewicht kennen und dann das Brot probieren, um zu sehen, ob das Brotgewicht eine glockenförmige Kurve mit Normalverteilung aufweist? Weicht er von der Kurve ab, kann dies auf ein Problem mit der Brotqualität hinweisen. Wie folgt:
Ein guter Datenanalyst ist ein guter Produktplaner und ein Führer in der Branche.
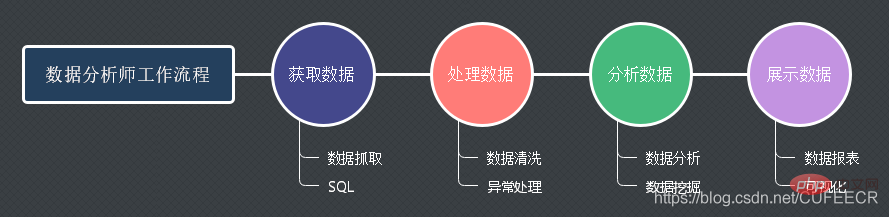
In IT-Unternehmen werden hervorragende Datenanalysten sehr wahrscheinlich zu hochrangigen Führungskräften des Unternehmens.Der Arbeitsablauf eines Datenanalysten ist wie folgt:

Drei Hauptaufgaben eines Datenanalysten:
- Historie analysieren
- Zukunft vorhersagen
- Auswahl optimieren
8 Fähigkeiten, die ein Datenanalyst benötigt:
- Statistik
- Statistische Tests, P-Werte, Verteilungen, Schätzung
- Grundlegende Werkzeuge
- Python
- SQL
- Multivariablenkalkül und lineare Algebra
- Daten.Wrangling
- Datenvisualisierung
- Softwareentwicklung
- Maschinelles Lernen. Denken von Datenwissenschaftlern Branchenkenntnisse
-
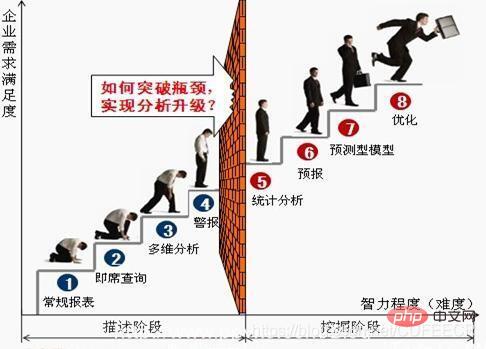
- Der Entwicklungsprozess eines typischen Datenanalysten:
Selbstentwicklung zum Datenanalysten:
- Sensibel
- Erkunden
- Akribisch ous
Die Fähigkeiten, die ein Datenanalyst besitzen muss, sind folgende: Vertraut mit der Excel-Datenverarbeitung
Ausgeprägte DatensensibilitätVertraut mit Unternehmensgeschäfts- und Branchenkenntnissen- Methoden zur Stammdatenanalyse
- Grundlegend Analysemethoden
- Kontrastive Analysemethode
- Strukturanalysemethode
- Funnel-Plot-Analysemethode
- Umfassende Bewertungsanalysemethode
- Faktoranalysemethode
- Matrixkorrelationsanalyse
- Erweiterte Analysemethode
- Korrelationsanalysemethode
- Regressionsanalysemethode
- Clusteranalysemethode
- Diskriminanzanalysemethode
- Hauptkomponentenanalysemethode
- Faktoranalysemethode
- Zeitreihen
- In einem anderen Job Inhalte und Verantwortlichkeiten von Praktikern der Branchendatenanalyse:
- Beteiligung an der Datenanalyse
- Lernen, tägliche Berichte zu erstellen
- Tägliche Verkaufs- und Bestandstabellen
- Produktverkaufsprognose
- Bestandsberechnung und Frühwarnung
- Matrixkorrelationsanalyse
- Bereitstellen von Datenunterstützung für die Produktoptimierung
- Überprüfen von Produktverbesserungseffekten
- Bereitstellen von E-Mails und Berichten für die Geschäftsleitung
- Internet + Analyse
- KPI-Indikatorüberwachung
- Jeder eine Art eines regelmäßigen Berichts
- Offline-Modellierung und -Analyse für das Unternehmen
- Die sehr wichtige Fachgrundlage der Datenanalyse ist Mathematik, aber es spielt keine Rolle, wenn Sie nicht gut sind In der Mathematik können Sie mit
- Python Folgendes lernen:
Erste Schritte mit Python ist nicht schwierig und seine mathematischen Anforderungen sind nicht zu hoch. Sie müssen wissen, wie man eine algorithmische Logik in der Sprache ausdrückt. - Python verfügt über viele gepackte Werkzeugbibliotheken und Befehle mit welchen mathematischen Methoden ein Problem gelöst und aufgebaut werden soll.
- Wenn Sie schnell mit der Python-Datenanalyse beginnen möchten, müssen Sie Python-bezogene Toolkits gut nutzen: (1) Das größte Merkmal von Python ist, dass es eine riesige und aktive „Scientific Computing“-Community hat Der Trend, Python für wissenschaftliche Berechnungen zu verwenden, wird immer deutlicher.
- (2) Da Python über kontinuierlich verbesserte Bibliotheken verfügt, ist es zu einer wichtigen Alternative für Datenverarbeitungsaufgaben geworden. In Kombination mit seiner starken Stärke in der allgemeinen Programmierung ist es durchaus möglich, Python als Sprache zum Erstellen datenzentrierter Anwendungen zu verwenden. einschließlich:
- Häufig verwendete Datenanalysebibliotheken
- Numpy
Scipy
Pandasmatplotlib
Häufig verwendete erweiterte Datenanalysebibliotheken
sci kit-learn
nltkigraph-
- ( 3 ) Als wissenschaftliche Computerplattform kann Python problemlos C-, C++- und Fortran-Codes integrieren.
- Vorbereitung für die Datenanalyse:
- Vergröße der Daten
- Drawing und Visualisierung
- Daten -Aggregation und Gruppierung der Verarbeitung
- DATA -Mining
- -Kommon -Algorithmen für die Datenanalyse und Data -Mining:
- Clustering-Algorithmus
- Dimensionalitätsreduktionsalgorithmus
- Die Methode zum Lernen und zur Teilnahme an der Datenanalyse ist:
- Denken Sie gründlich nach
Mehr zusammenfassen- 2. Python-Installation und Umgebungskonfiguration
- 1.Python-Version
-
Python ist in zwei Hauptversionen unterteilt, 3.X und 2.X.
Version 3.0 von Python wird oft als Python 3000 oder kurz Py3k bezeichnet. Dies ist ein wesentliches Upgrade im Vergleich zu früheren Versionen von Python.
Um nicht zu viel Belastung mit sich zu bringen, Python 3.
Die meisten Bibliotheken von Drittanbietern arbeiten hart daran, mit der Python 3.X-Version kompatibel zu sein.2. Installieren Sie Python auf verschiedenen Systemen
(1) Unix- und Linux-Systeme
- Besuchen Sie http://www.python.org/download/
- Wählen Sie das für Unix/Linux geeignete Quellcode-Komprimierungspaket
- Laden Sie das komprimierte Paket herunter und dekomprimieren Sie es.
- Wenn Sie einige Optionen anpassen müssen, ändern Sie Module/Setup.
- Führen Sie das Skript
./configureaus../configure脚本 makemake install
(2)Window系统
- 访问http://www.python.org/download/
- 在下载列表中选择Window平台安装包
由于官网下载很缓慢,因此我已经将Python各版本的安装包下载整理好了,可以直接点击加QQ群963624318 在群文件夹Python相关安装包中下载即可。 - 下载后,双击下载包,进入Python安装向导,安装非常简单,只需要使用默认的设置一直点击下一步直到安装完成即可。
(3)Mac系统
自带python 2.7,可以执行brew install python安装新版本。3.环境变量配置
Windows系统需要配置环境变量。
如果在安装Python时没有选择添加环境变量,则需要手动添加,需要将安装Python的路径
XXXPythonXXX和XXXPythonXXXScripts添加到环境变量,有两种方式:- 命令行添加
CMD中分别执行path=%path%;XXXPythonXXX和path=%path%;XXXPythonXXXScripts即可。 - 在系统设置中添加
右键计算机 → 属性 → 高级系统设置 → 系统属性 → 环境变量 → 双击path → 添加XXXPythonXXX和XXXPythonXXXScripts安装路径,如下:
最后依次点击确认退出即可。
4.安装pip
pip是Python中的包安装和管理工具,在安装Python时可以选择安装pip,在Python 2 >=2.7.9或Python 3 >=3.4中自带。
如果没有安装pip,可以通过命令安装:
- Linux或者Mac
pip install -U pip - Windows(cmd输入)
python -m pip install -U pip
make
(2) Windows-Systemmake install<strong></strong>
Besuchen Sie http://www.python.org/download/Wählen Sie das Windows-Plattform-Installationspaket in der Download-Liste aus Seit dem Download vom offiziellen Die Website ist sehr langsam. Ich habe Python installiert. Die Installationspakete für jede Version wurden heruntergeladen und sortiert. Sie können direkt auf klicken, um der QQ-Gruppe beizutreten. 963624318 Laden Sie es einfach im Gruppenordner Python-bezogenes Installationspaket herunter.Doppelklicken Sie nach dem Herunterladen auf das Download-Paket, um den Python-Installationsassistenten aufzurufen. Die Installation ist sehr einfach, verwenden Sie einfach die Standardeinstellungen und klicken Sie so lange auf
Weiter, bis die Installation abgeschlossen ist.
(3) Das Mac-Systemwird mit Python 2.7 geliefert. Sie können
3. Konfiguration der Umgebungsvariablenbrew install pythonausführen, um die neue Version zu installieren.Das Windows-System muss Umgebungsvariablen konfigurieren.
Wenn Sie sich bei der Installation von Python nicht für das Hinzufügen von Umgebungsvariablen entschieden haben, müssen Sie diese manuell hinzufügen. Sie müssen den Pfad zur Installation von PythonXXXPythonXXXundXXXPythonXXXScriptshinzufügen Umgebungsvariablen. Es gibt zwei Möglichkeiten:Befehlszeilenaddition Führen Sie
Hinzufügenpath=%path%;XXXPythonXXXbzw.path=%path%;XXXPythonXXXScriptsin CMD aus.Klicken Sie mit der rechten Maustaste auf den Computer → Eigenschaften → Erweiterte Systemeinstellungen → Systemeigenschaften → Umgebungsvariablen → Doppelklicken Sie auf den Pfad → Fügen Sie die
XXXPythonXXX- undXXXPythonXXXScripts hinzu. code> Installationspfade wie folgt: <strong> <img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/358c8a88f9e5aa428fac4f7d79ca24e2-6.png" class="lazy" alt="Umgebungsvariablen festlegen"></strong><strong> </strong>Klicken Sie abschließend auf „Bestätigen“, um den Vorgang zu beenden. <img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/358c8a88f9e5aa428fac4f7d79ca24e2-5.png" class="lazy" border="0" alt="Python-Datenanalyse: Praktischer Überblick über die Datenanalyse" title="Python-Datenanalyse: Praktischer Überblick über die Datenanalyse"><strong></strong>4. Pip installieren
Wenn pip nicht installiert ist, können Sie es über den folgenden Befehl installieren: 🎜🎜🎜Linux oder Mac🎜
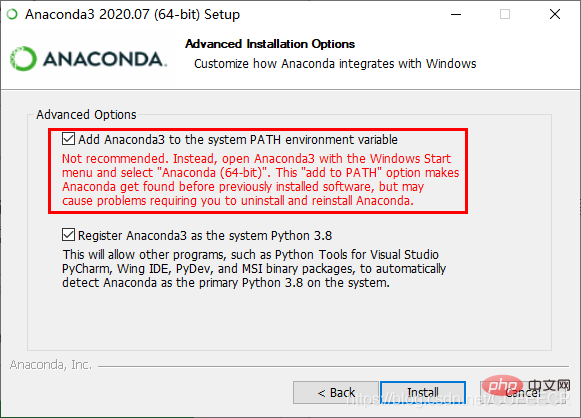
pip ist ein Paketinstallations- und Verwaltungstool in Python. Sie können wählen, ob Sie pip bei der Installation von Python 2 >=2.7.9 oder Python 3 >=3.4 installieren möchten.pip install -U pip🎜🎜Windows (cmd-Eingabe)🎜python -m pip install -U pip🎜🎜🎜🎜5. Integrierte Entwicklungsumgebungsauswahl🎜🎜🎜Python verfügt über viele Editoren, einschließlich PyCharm usw. Wählen Sie hier PyCharm:🎜 PyCharm ist eine von JetBrains erstellte Python-IDE, die Mac OS unterstützt. Windows, Linux-System. 🎜 Beinhaltet 🎜Debugging🎜, Syntaxhervorhebung, Projektmanagement, 🎜Codesprung🎜, 🎜intelligente Eingabeaufforderungen🎜, automatische Vervollständigung, Unit-Tests, Versionskontrolle und andere Funktionen. 🎜🎜Sie können die entsprechende Version zum Herunterladen und Installieren unter https://www.jetbrains.com/pycharm/download/ auswählen. 🎜🎜🎜3. Einführung und Installation von Anaconda🎜🎜🎜Anaconda ist eine Python-Distribution, die für 🎜wissenschaftliches Rechnen🎜 verwendet werden kann -in häufig verwendeter wissenschaftlicher Berechnungsbibliothek. 🎜 Es löst zwei Hauptprobleme des offiziellen Python: 🎜 (1) Bietet eine Paketverwaltungsfunktion, die das Problem der häufigen Fehler bei der Installation von Paketen von Drittanbietern auf der Windows-Plattform löst. 🎜 (2) Bietet eine Umgebungsverwaltungsfunktion, ähnlich wie bei virtualenv. Dies löst das Problem Probleme mit der Koexistenz und dem Wechsel mehrerer Python-Versionen. 🎜🎜🎜2. Laden Sie Anaconda herunter und installieren Sie es🎜🎜🎜Laden Sie das Installationspaket direkt von der offiziellen Website https://www.anaconda.com/products/inpidual herunter und laden Sie das Installationspaket von 🎜Python3.8🎜🎜Personal Edition herunter 🎜, aber die Download-Geschwindigkeit der offiziellen Website ist langsam, daher habe ich das Anaconda-Installationspaket für Python 3.8 heruntergeladen und sortiert. Sie können direkt darauf klicken, um die QQ-Gruppe hinzuzufügen 🎜963624318 Laden Sie es einfach im Gruppenordner 🎜Python-bezogenes Installationspaket 🎜 herunter. 🎜🎜Direkt installieren, nachdem der Download abgeschlossen ist. Bitte beachten Sie, dass während des Klickvorgangs eine Aufforderung zum Hinzufügen von Umgebungsvariablen angezeigt wird. Sie müssen dies wie folgt überprüfen: 🎜🎜🎜Klicken Sie abschließend auf Weiter. Klicken Sie nach Abschluss der Installation auf die Win-Taste (unter Windows-System), um die Liste der zuletzt hinzugefügten Anwendungen oder Anwendungen wie unten gezeigt anzuzeigen:
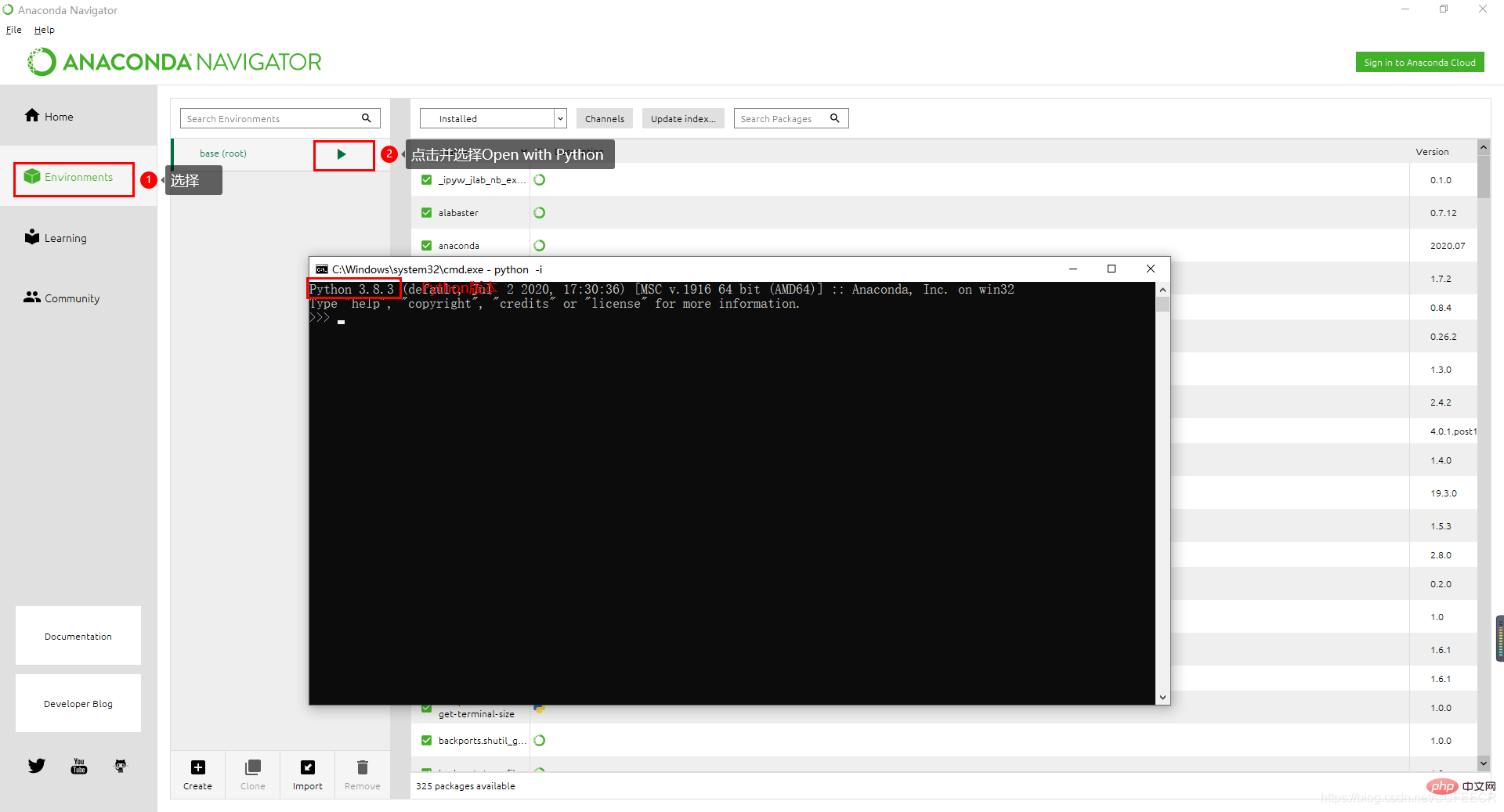
Zu diesem Zeitpunkt können Sie auf Anaconda Navigator klicken , wie unten gezeigt:
Sie können sehen, dass die von Anaconda erstellte Basisumgebung auch die Standardumgebung ist. Sie können auch die standardmäßig installierten Bibliotheken sehen.
Öffnen Sie das Anaconda-Befehlszeilentool Anaconda Powershell Prompt, geben Sie
python -Vein und geben Sie außerdemPython 3.8.3ein.python -V,也打印Python 3.8.3。还可以通过命令创建新的conda环境,如
conda create --name py27 python=2.7执行后即创建了一个名为py27的Python版本为2.7的conda环境。激活环境执行命令
conda activate py27,停用使用命令conda deactivate。可以在命令行中执行
conda list查看已经安装的库,如下:# packages in environment at E:\Anaconda3: # # Name Version Build Channel _ipyw_jlab_nb_ext_conf 0.1.0 py38_0 alabaster 0.7.12 py_0 anaconda 2020.07 py38_0 anaconda-client 1.7.2 py38_0 anaconda-navigator 1.9.12 py38_0 ... zlib 1.2.11 h62dcd97_4 zope 1.0 py38_1 zope.event 4.4 py38_0 zope.interface 4.7.1 py38he774522_0 zstd 1.4.5 ha9fde0e_0
3.conda工具的介绍和包管理
conda是Anaconda下用于包管理和环境管理的工具,功能上类似pip和virtualenv的组合,conda的环境管理与virtualenv是基本上是类似的操作。
安装成功后conda会默认加入到环境变量中,因此可直接在命令行窗口运行conda命令。常见的conda命令和含义如下:
命令含义 conda命令 conda –h 查看帮助 基于python3.6版本创建名为python36的环境 conda create --name python36 python=3.6 激活此环境 activate python36(Windows)、source activate python36(linux/mac) 查看python版本 python -V 退出当前环境 deactivate python36 删除环境 conda remove -n py27 --all 查看所有安装的环境 conda info -e conda的包管理常见命令如下:
包管理命令意义 包管理命令 安装matplotlib conda install matplotlib 查看已安装的包 conda list 包更新 conda update matplotlib 删除包 conda remove matplotlib 在conda中,
Sie können eine neue Conda-Umgebung auch über Befehle wieanything is a package一切皆是包conda create --name py27 python=2.7erstellen. Nach der Ausführung wird eine Conda-Umgebung mit dem Namen py27 mit Python Version 2.7 erstellt.Um die Umgebung zu aktivieren, führen Sie den Befehl
conda –h🎜🎜Hilfe anzeigen🎜🎜🎜🎜Erstellen Sie eine Umgebung mit dem Namen. python 36 basierend auf der Python3.6-Version 🎜 🎜Conda Create --Name Python36 Python=3.6 🎜🎜🎜 Aktuelle Umgebung beenden🎜🎜python36 deaktivieren🎜🎜🎜🎜Umgebung löschen🎜🎜conda entfernen -n py27 --all🎜🎜🎜🎜Alle installierten Umgebungen anzeigen🎜🎜conda info -e🎜🎜🎜🎜🎜Allgemeine Befehle für Die Paketverwaltung von ist wie folgt folgt: 🎜🎜🎜🎜🎜Paketverwaltungsbefehlsbedeutung🎜🎜Paketverwaltungsbefehl🎜🎜🎜🎜🎜🎜Matplotlib installieren🎜🎜conda matplotlib installieren🎜🎜🎜🎜Installierte Pakete anzeigen🎜🎜conda-Liste🎜 🎜 🎜🎜Paket-Update🎜🎜Conda-Update matplotlib🎜🎜🎜🎜Paket entfernen🎜🎜conda matplotlib entfernen🎜🎜🎜🎜🎜In Conda istconda activate py27aus, und um die Umgebung zu deaktivieren, verwenden Sie den Befehlconda activate.Sie können conda listwie folgt in der Befehlszeile ausführen, um die installierten Bibliotheken anzuzeigen:import pymongoclass Product: def __init__(self,productId:int ,name, imageUrl, categories, tags): self.productId = productId self.name = name self.imageUrl = imageUrl self.categories = categories self.tags = tags def __str__(self) -> str: return self.productId +'^' + self.name +'^' + self.imageUrl +'^' + self.categories +'^' + self.tagsclass Rating: def __init__(self, userId:int, productId:int, score:float, timestamp:int): self.userId = userId self.productId = productId self.score = score self.timestamp = timestamp def __str__(self) -> str: return self.userId +'^' + self.productId +'^' + self.score +'^' + self.timestampif __name__ == '__main__': myclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/") mydb = myclient["goods-users"] # val attr = item.split("\^") # // 转换成Product # Product(attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim) Python-Datenanalyse: Praktischer Überblick über die Datenanalyse = mydb['Python-Datenanalyse: Praktischer Überblick über die Datenanalyse'] with open('Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.csv', 'r',encoding='UTF-8') as f: item = f.readline() while item: attr = item.split('^') product = Product(int(attr[0]), attr[1].strip(), attr[4].strip(), attr[5].strip(), attr[6].strip()) Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.insert_one(product.__dict__) # print(product) # print(json.dumps(obj=product.__dict__,ensure_ascii=False)) item = f.readline() # val attr = item.split(",") # Rating(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt) Python-Datenanalyse: Praktischer Überblick über die Datenanalyse = mydb['Python-Datenanalyse: Praktischer Überblick über die Datenanalyse'] with open('Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.csv', 'r',encoding='UTF-8') as f: item = f.readline() while item: attr = item.split(',') rating = Rating(int(attr[0]), int(attr[1].strip()), float(attr[2].strip()), int(attr[3].strip())) Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.insert_one(rating.__dict__) # print(rating) item = f.readline()3. Conda-Tool-Einführung und Paketverwaltung Paketverwaltung unter verwendet Anaconda Die Tools von und Environment Managementähneln funktional der Kombination von Pip und Virtualenv. Condas Umgebungsmanagement und Virtualenv sind grundsätzlich ähnliche Vorgänge. Nach erfolgreicher Installation wird Conda standardmäßig zu den Umgebungsvariablen hinzugefügt, sodass Sie den Conda-Befehl direkt im Befehlszeilenfenster ausführen können.Übliche Conda-Befehle und Bedeutungen sind wie folgt: BefehlsbedeutungConda-Befehl alles ein Paket, alles ist ein Paket, Conda selbst kann als Paket betrachtet werden, das können Sie sehen Python-Umgebung Als Paket kann Anaconda auch als Paket betrachtet werden. Zusätzlich zu gewöhnlichen Paketen von Drittanbietern, die Updates unterstützen, unterstützen diese drei Pakete auch die folgenden Befehle: 🎜🎜🎜🎜🎜operation🎜🎜command🎜🎜🎜🎜🎜 🎜Conda selbst aktualisieren🎜🎜Conda aktualisieren Conda🎜🎜🎜🎜Anaconda-Anwendung aktualisieren🎜🎜Conda Anaconda aktualisieren🎜🎜🎜🎜Python aktualisieren, vorausgesetzt, die aktuelle Python-Umgebung ist 3.8.1 und die neueste Version ist 3.8.2, dann wird es so sein aktualisiert auf 3.8 .2🎜🎜conda update python🎜🎜🎜🎜四、Jupyter Notebook
1.Jupyter Notebook基本介绍
Jupyter Notebook(此前被称为IPython notebook)是一个交互式笔记本,支持运行40多种编程语言。
在开始使用notebook之前,需要先安装该库:
(1)在命令行中执行pip install jupyter来安装;
(2)安装Anaconda后自带Jupyter Notebook。在命令行中执行
jupyter notebook,就会在当前目录下启动Jupyter服务并使用默认浏览器打开页面,还可以复制链接到其他浏览器中打开,如下:可以看到,notebook界面由以下部分组成:
(1)notebook名称;
(2)主工具栏,提供了保存、导出、重载notebook,以及重启内核等选项;
(3)notebook主要区域,包含了notebook的内容编辑区。2.Jupyter Notebook的使用
在Jupyter页面下方的主要区域,由被称为单元格的部分组成。每个notebook由多个单元格构成,而每个单元格又可以有不同的用途。
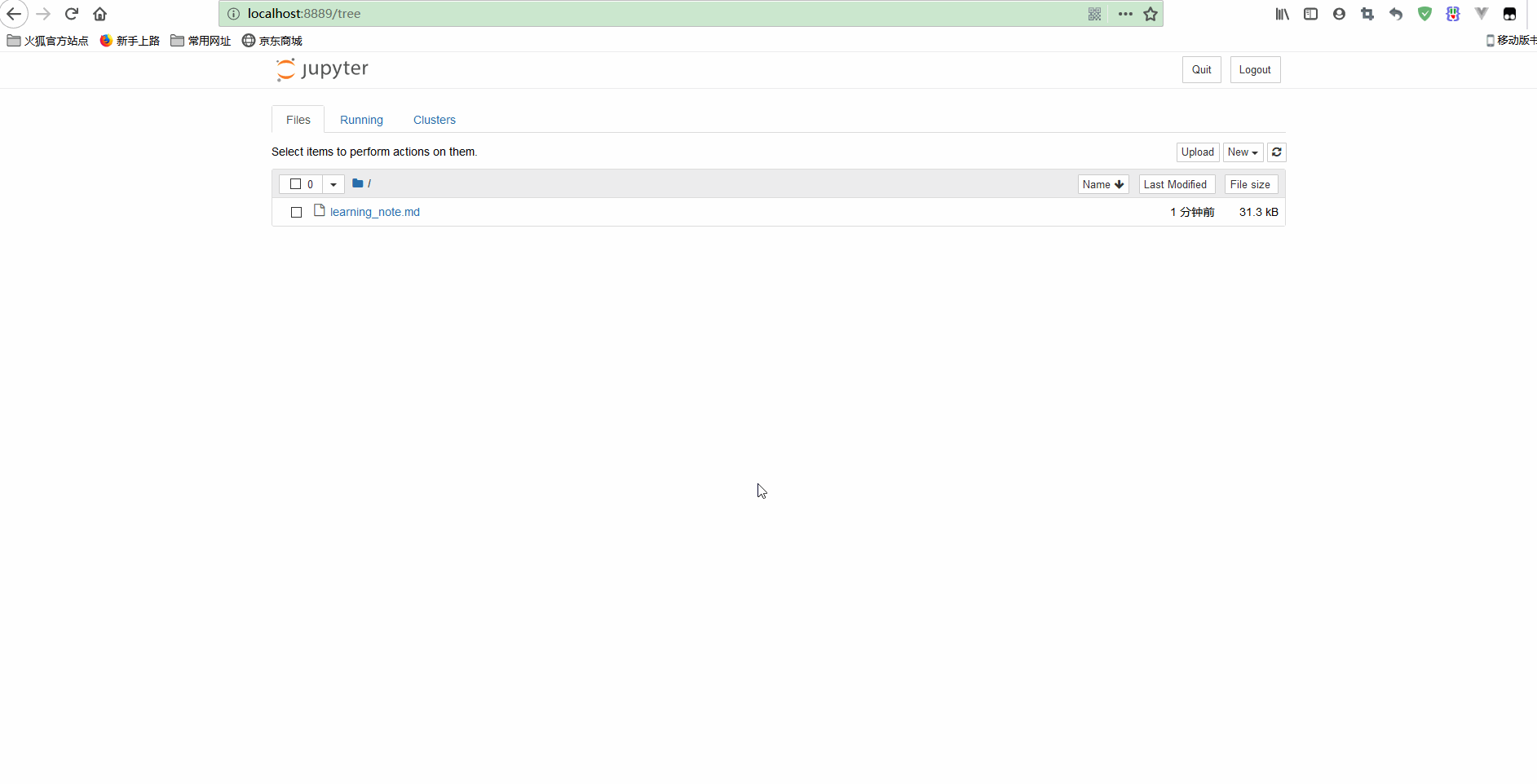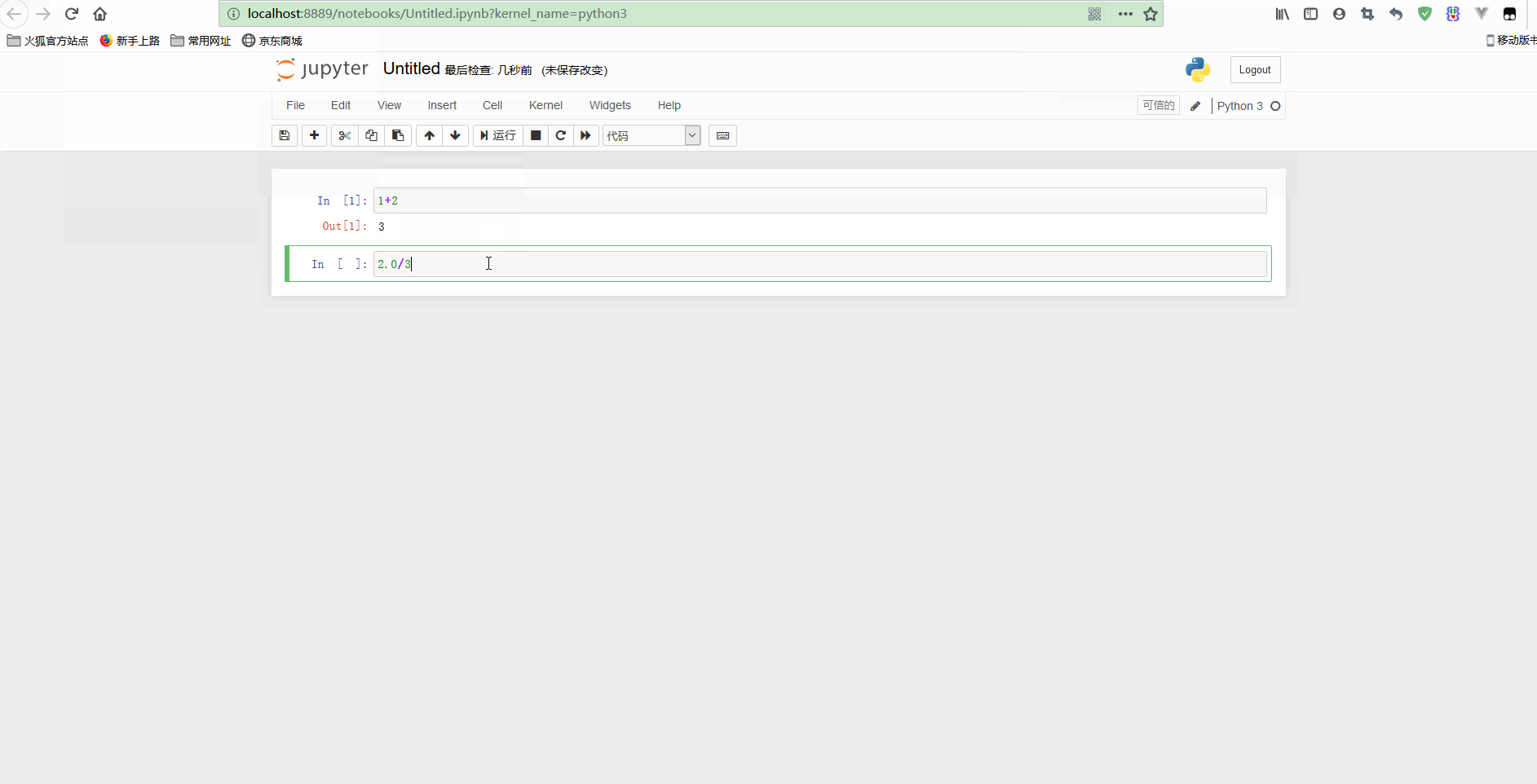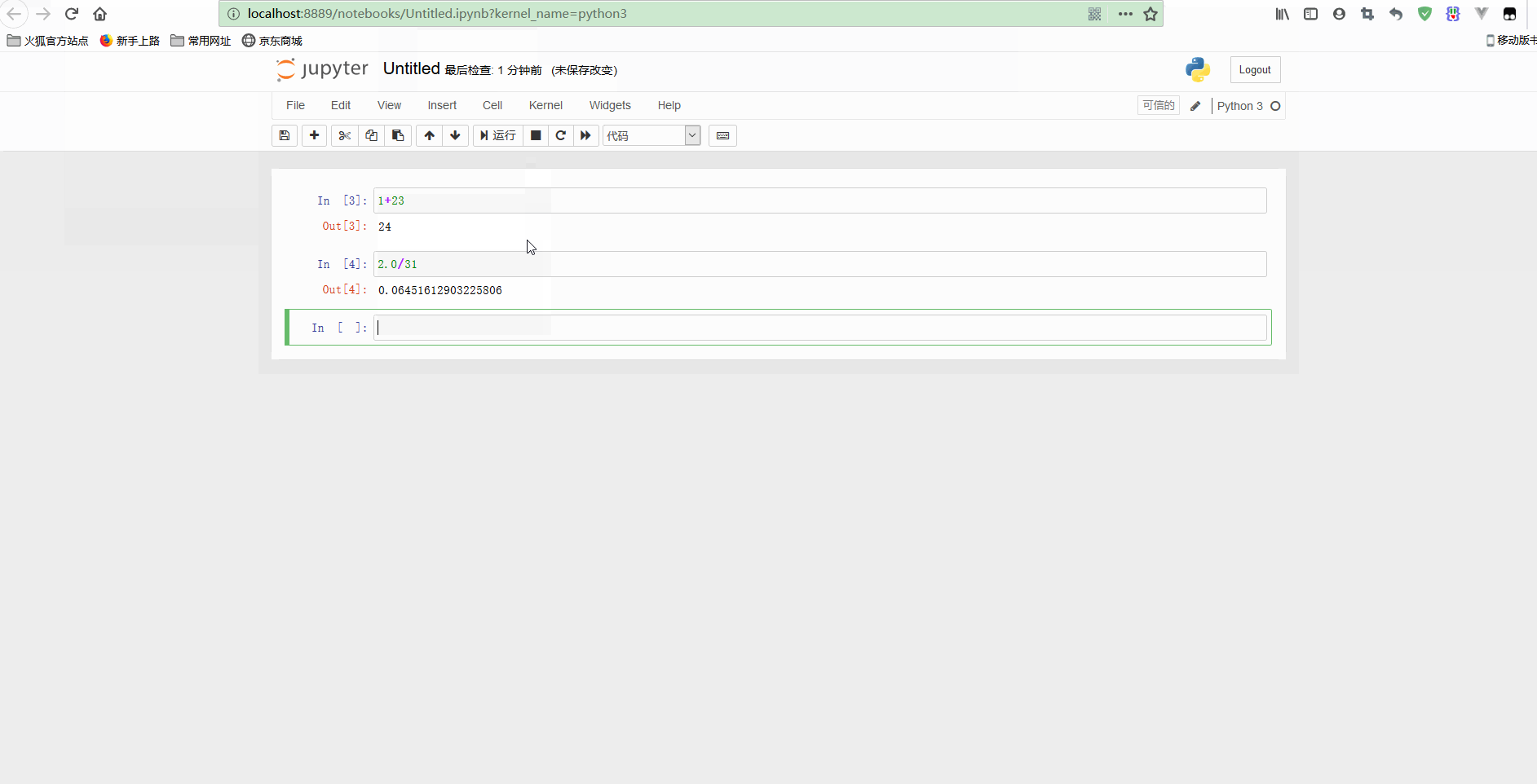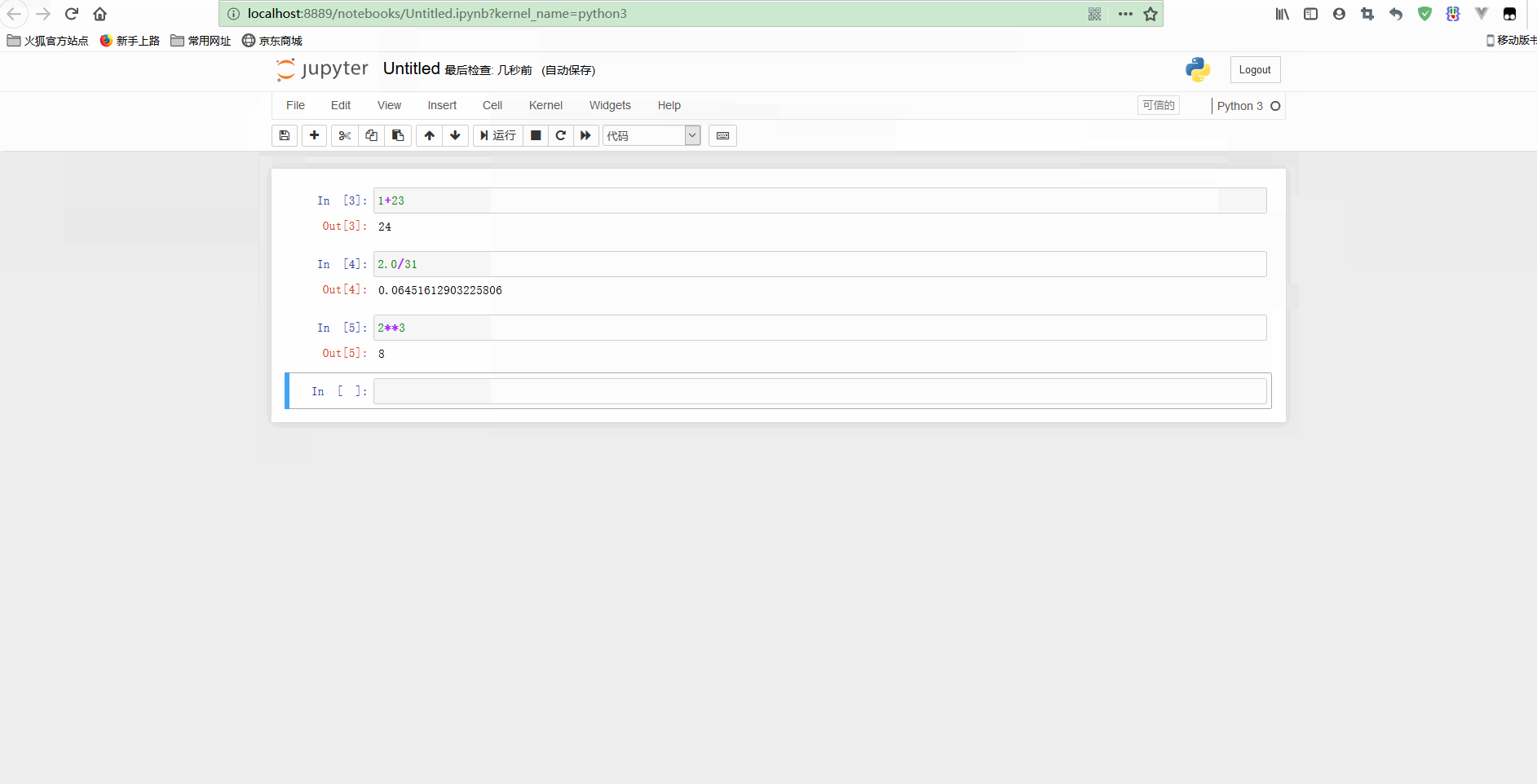
上图中看到的是一个代码单元格(code cell),以[ ]开头,在这种类型的单元格中,可以输入任意代码并执行。
例如,输入1 + 2并按下Shift + Enter,单元格中的代码就会被计算,光标也会被移动到一个新的单元格中。如果想新建一个notebook,只需要点击New,选择希望启动的notebook类型即可。
简单使用示意如下:
可以看到,notebook可以修改之前的单元格,对其重新计算,这样就可以更新整个文档了。如果你不想重新运行整个脚本,只想用不同的参数测试某个程式的话,这个特性显得尤其强大。
不过,也可以重新计算整个notebook,只要点击Cell -> Run all即可。再测试标题和其他代码如下:
可以看到,在顶部添加了一个notebook的标题,还可以执行for循环等语句。
3.Jupyter中使用Python
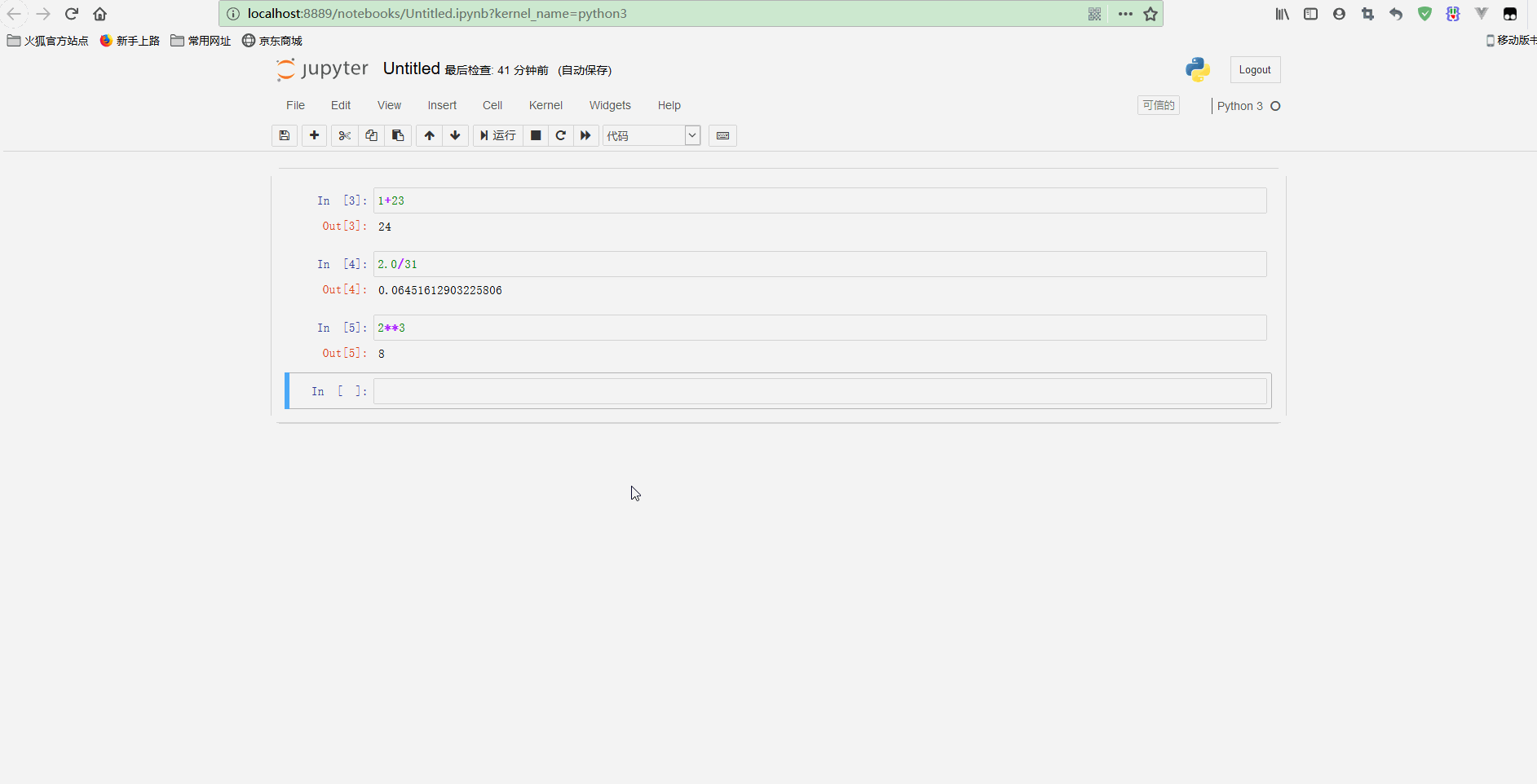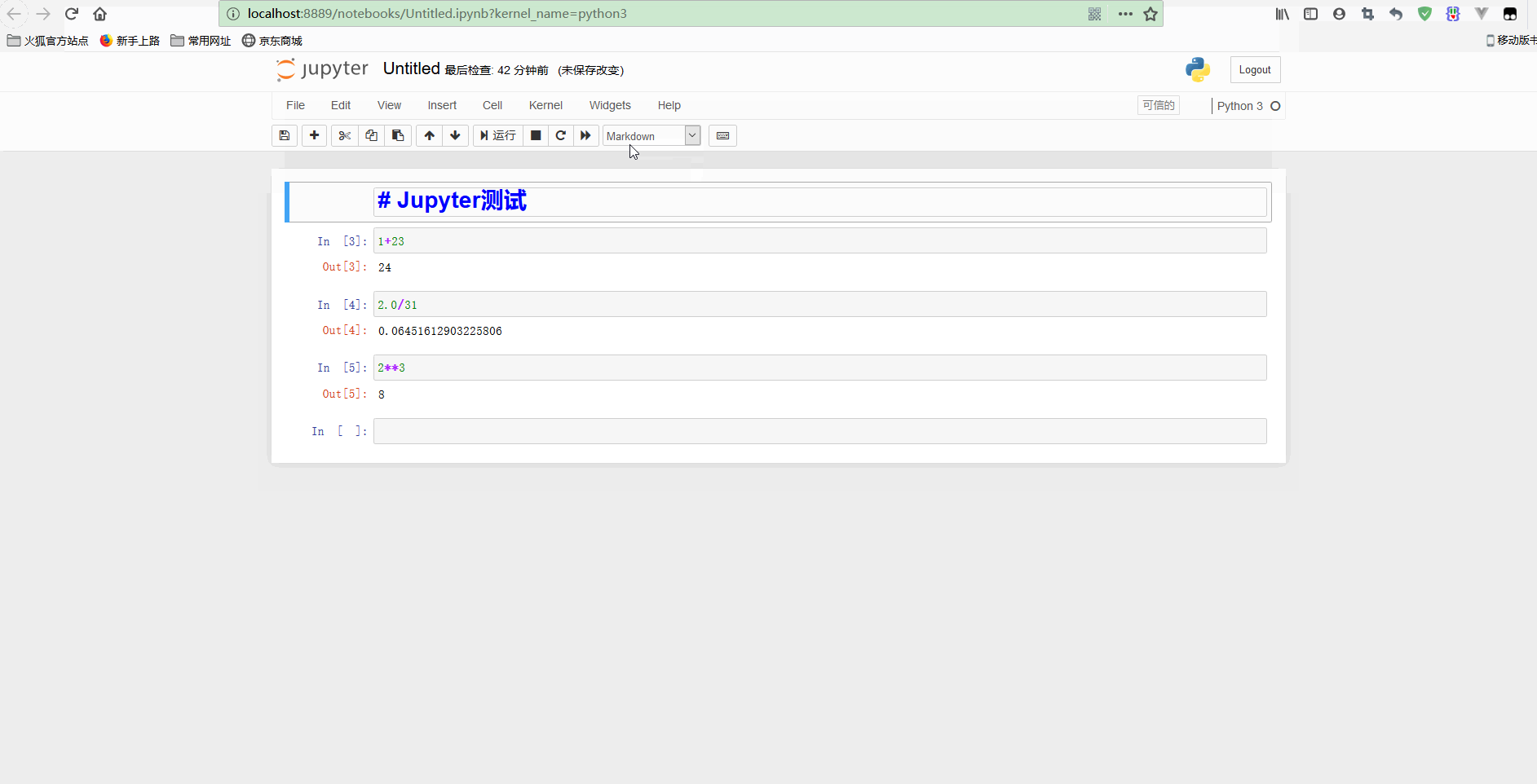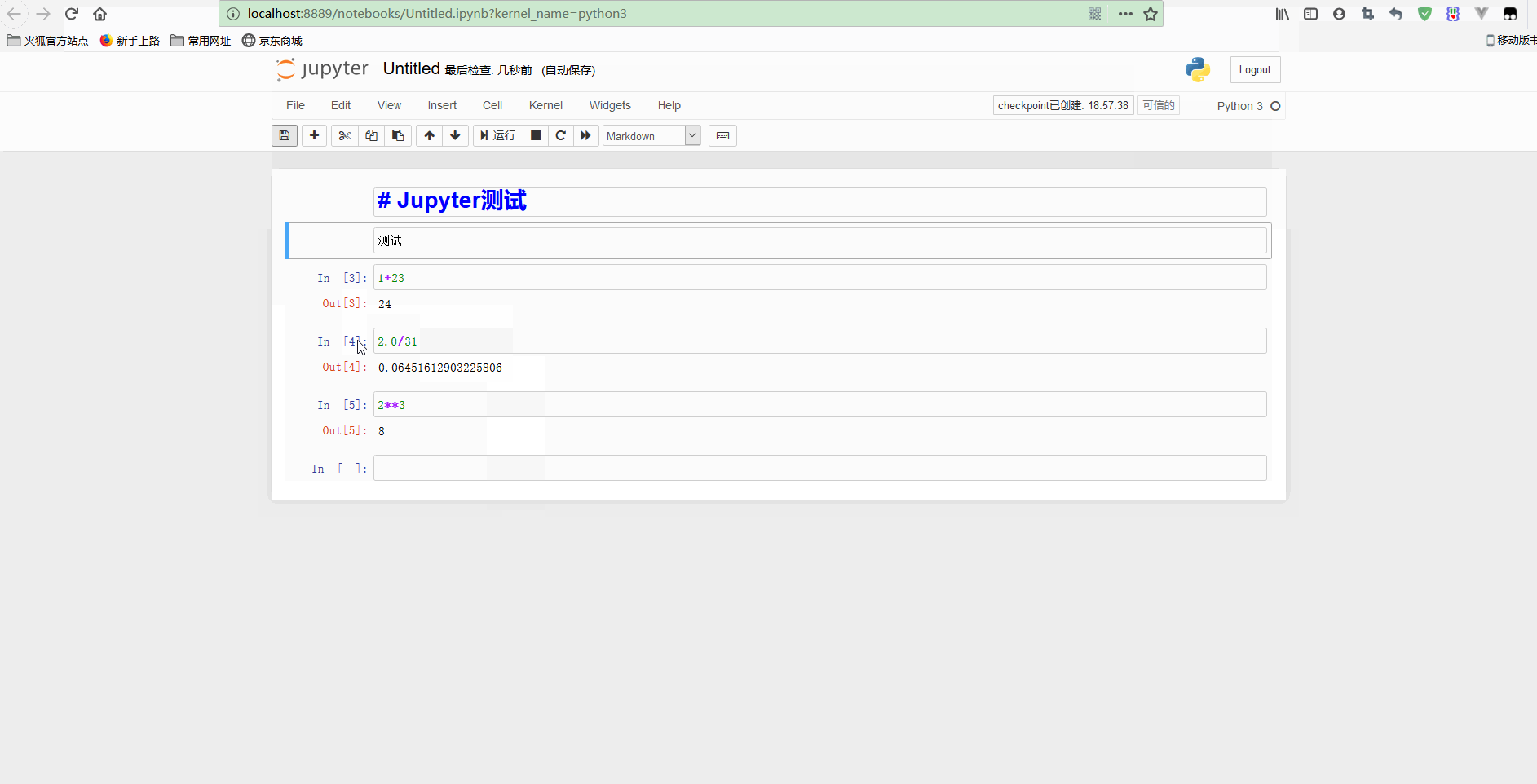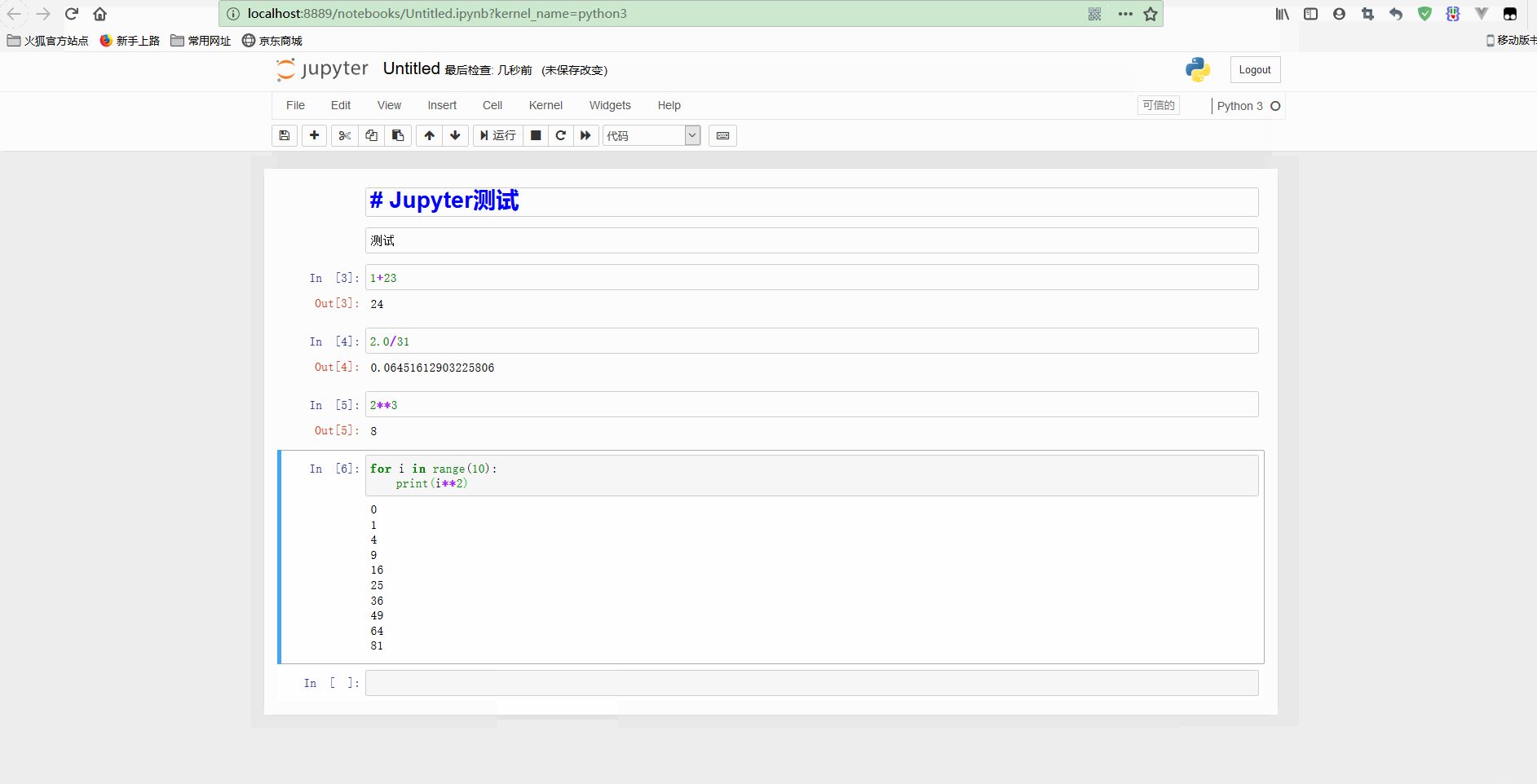
Jupyter测试Python变量和数据类型如下:
测试Python函数如下:
测试Python模块如下:
可以看到,在执行出错时,也会抛出异常。
测试数据读写如下:
数据读写很重要,因为进行数据分析时必须先读取数据,进行数据处理后也要进行保存。
4.数据交互案例
加载csv数据,处理数据,保存到MongoDB数据库
有csv文件Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.csv和Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.csv,分别是商品数据和用户评分数据,如下:
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
963624318 在群文件夹Python数据分析实战中下载即可。现在需要通过Python将其读取出来,并将指定的字段保存到MongoDB中,需要在Anaconda中执行命令
conda install pymongo安装pymongo。Python代码如下:
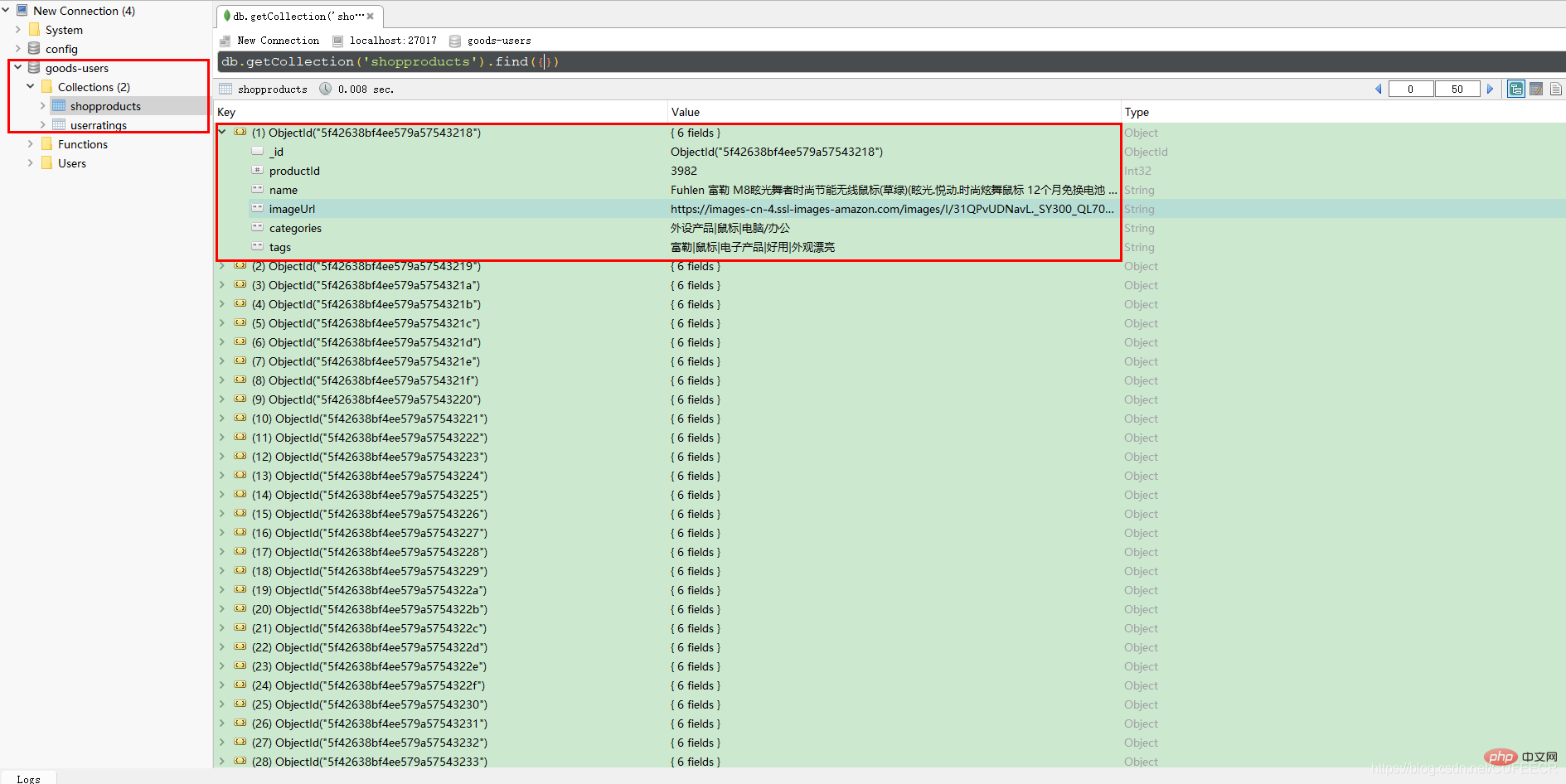
import pymongoclass Product: def __init__(self,productId:int ,name, imageUrl, categories, tags): self.productId = productId self.name = name self.imageUrl = imageUrl self.categories = categories self.tags = tags def __str__(self) -> str: return self.productId +'^' + self.name +'^' + self.imageUrl +'^' + self.categories +'^' + self.tagsclass Rating: def __init__(self, userId:int, productId:int, score:float, timestamp:int): self.userId = userId self.productId = productId self.score = score self.timestamp = timestamp def __str__(self) -> str: return self.userId +'^' + self.productId +'^' + self.score +'^' + self.timestampif __name__ == '__main__': myclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/") mydb = myclient["goods-users"] # val attr = item.split("\\^") # // 转换成Product # Product(attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim) Python-Datenanalyse: Praktischer Überblick über die Datenanalyse = mydb['Python-Datenanalyse: Praktischer Überblick über die Datenanalyse'] with open('Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.csv', 'r',encoding='UTF-8') as f: item = f.readline() while item: attr = item.split('^') product = Product(int(attr[0]), attr[1].strip(), attr[4].strip(), attr[5].strip(), attr[6].strip()) Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.insert_one(product.__dict__) # print(product) # print(json.dumps(obj=product.__dict__,ensure_ascii=False)) item = f.readline() # val attr = item.split(",") # Rating(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt) Python-Datenanalyse: Praktischer Überblick über die Datenanalyse = mydb['Python-Datenanalyse: Praktischer Überblick über die Datenanalyse'] with open('Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.csv', 'r',encoding='UTF-8') as f: item = f.readline() while item: attr = item.split(',') rating = Rating(int(attr[0]), int(attr[1].strip()), float(attr[2].strip()), int(attr[3].strip())) Python-Datenanalyse: Praktischer Überblick über die Datenanalyse.insert_one(rating.__dict__) # print(rating) item = f.readline()在启动MongoDB服务后,运行Python代码,运行完成后,再通过Robo 3T查看数据库如下:
显然,保存数据成功。
使用Jupyter处理商铺数据
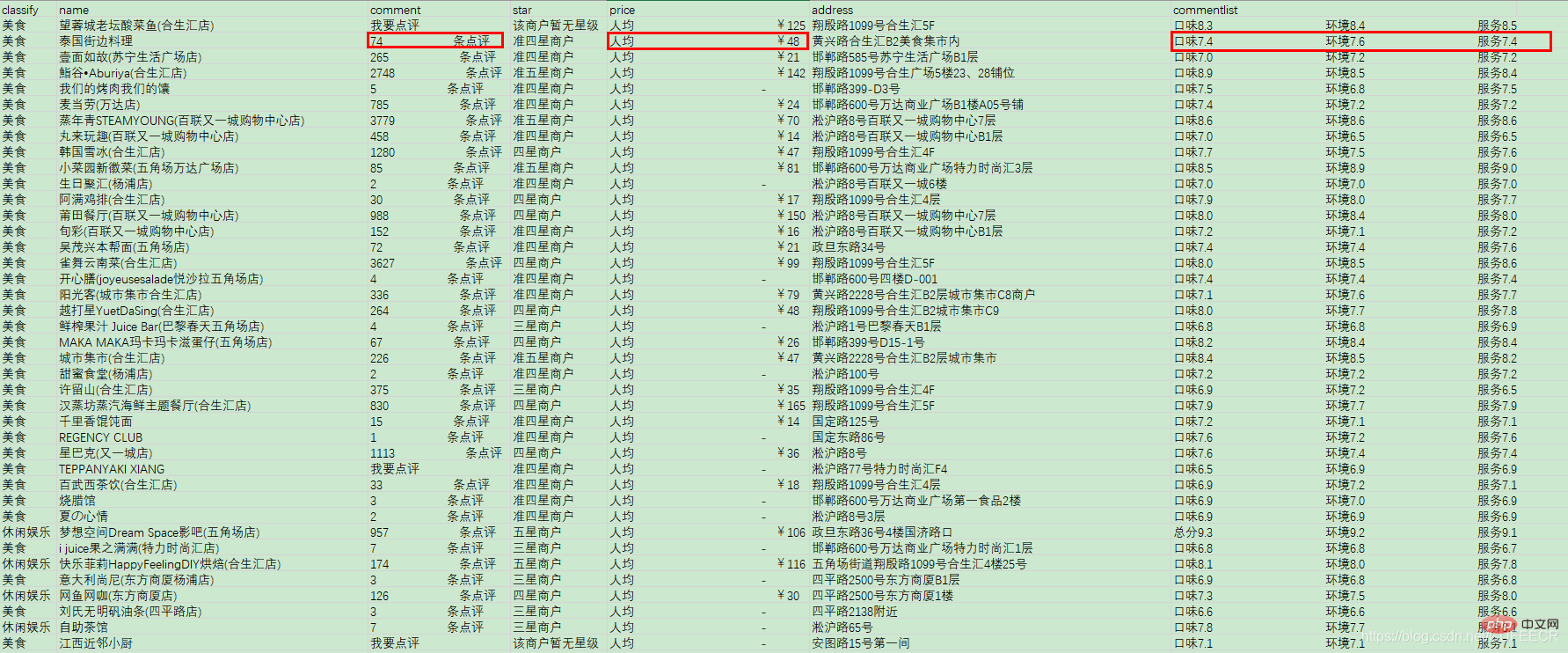
待处理的数据是商铺数据,如下:
包括名称、评论数、价格、地址、评分列表等,其中评论数、价格和评分均不规则、需要进行数据清洗。
如需获取数据、代码等相关文件进行测试学习,可以直接点击加QQ群
963624318 在群文件夹Python数据分析实战中下载即可。Jupyter中处理如下:
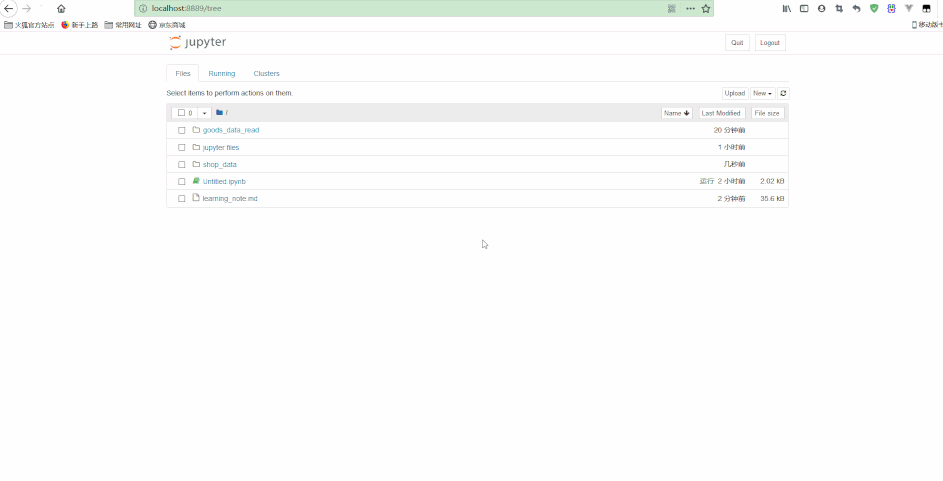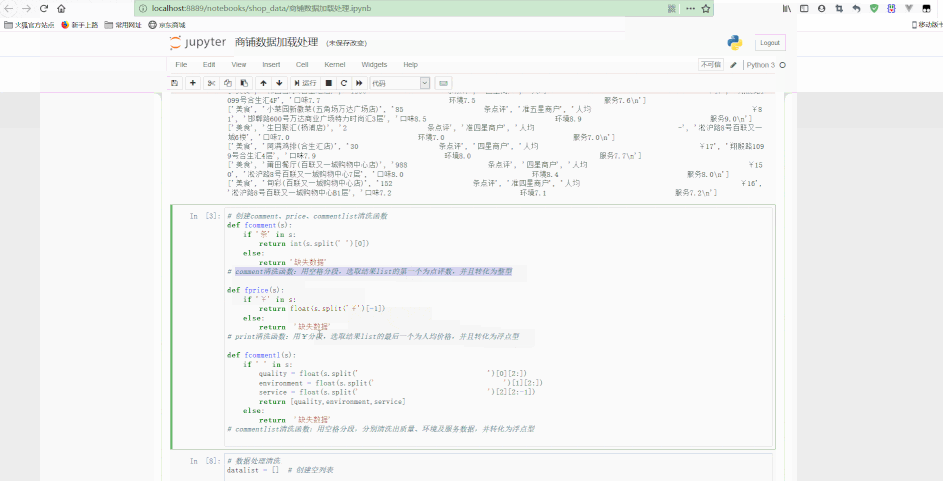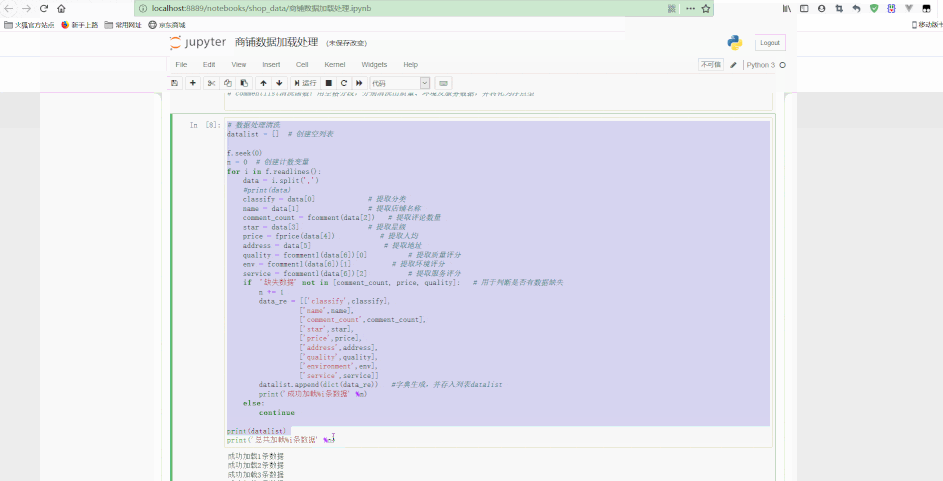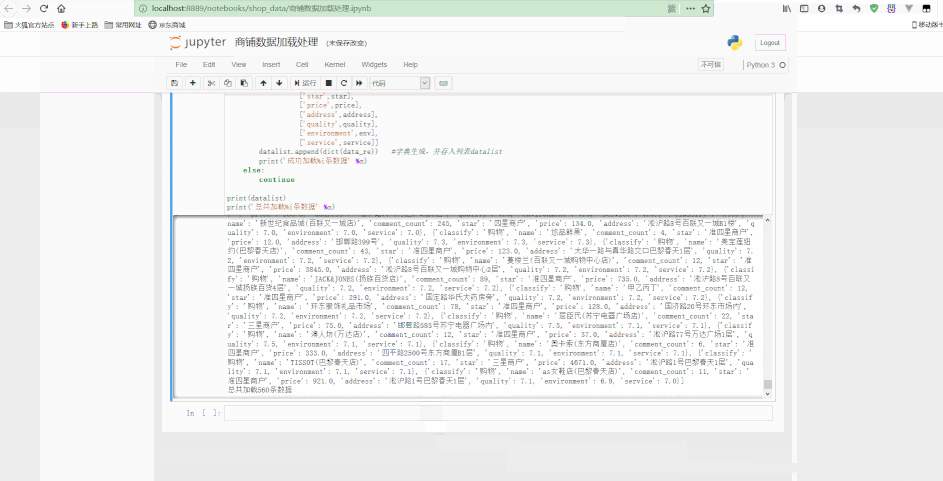
可以看到,最后得到了经过清洗后的规则数据。
完整Python代码如下:
# 数据读取f = open('商铺数据.csv', 'r', encoding='utf8')for i in f.readlines()[1:15]: print(i.split(','))# 创建comment、price、commentlist清洗函数def fcomment(s): '''comment清洗函数:用空格分段,选取结果list的第一个为点评数,并且转化为整型''' if '条' in s: return int(s.split(' ')[0]) else: return '缺失数据'def fprice(s): '''price清洗函数:用¥分段,选取结果list的最后一个为人均价格,并且转化为浮点型''' if '¥' in s: return float(s.split('¥')[-1]) else: return '缺失数据'def fcommentl(s): '''commentlist清洗函数:用空格分段,分别清洗出质量、环境及服务数据,并转化为浮点型''' if ' ' in s: quality = float(s.split(' ')[0][2:]) environment = float(s.split(' ')[1][2:]) service = float(s.split(' ')[2][2:-1]) return [quality, environment, service] else: return '缺失数据'# 数据处理清洗datalist = [] # 创建空列表f.seek(0)n = 0 # 创建计数变量for i in f.readlines(): data = i.split(',') # print(data) classify = data[0] # 提取分类 name = data[1] # 提取店铺名称 comment_count = fcomment(data[2]) # 提取评论数量 star = data[3] # 提取星级 price = fprice(data[4]) # 提取人均 address = data[5] # 提取地址 quality = fcommentl(data[6])[0] # 提取质量评分 env = fcommentl(data[6])[1] # 提取环境评分 service = fcommentl(data[6])[2] # 提取服务评分 if '缺失数据' not in [comment_count, price, quality]: # 用于判断是否有数据缺失 n += 1 data_re = [['classify', classify], ['name', name], ['comment_count', comment_count], ['star', star], ['price', price], ['address', address], ['quality', quality], ['environment', env], ['service', service]] datalist.append(dict(data_re)) # 字典生成,并存入列表datalist print('成功加载%i条数据' % n) else: continueprint(datalist)print('总共加载%i条数据' % n)f.close()更多编程相关知识,请访问:编程教学!!
 Die Fähigkeiten, die ein Datenanalyst besitzen muss, sind folgende:
Die Fähigkeiten, die ein Datenanalyst besitzen muss, sind folgende:  963624318 在群文件夹Python相关安装包中下载即可。
963624318 在群文件夹Python相关安装包中下载即可。


Das obige ist der detaillierte Inhalt vonPython-Datenanalyse: Praktischer Überblick über die Datenanalyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Einführung in das Python-Lernen. Warum gibt es Tupel?
- Python-Grundlagen, Dekoratoren und Übungen
- Einblick in die Grundlagen von Python
- Der Python-Socket vervollständigt die einfache Kommunikation
- Python führt verschachteltes JSON ein, um es in Sekundenschnelle in Dataframe umzuwandeln!
- Lehren: Lernen Sie alle 30 Sekunden einen Python-Trick