
Heim >häufiges Problem >Was sind die drei Implementierungsmethoden verteilter Sperren?
Was sind die drei Implementierungsmethoden verteilter Sperren?

- 青灯夜游Original
- 2020-12-14 11:29:5447238Durchsuche
Drei Möglichkeiten zur Implementierung verteilter Sperren: 1. Implementieren Sie verteilte Sperren basierend auf der Datenbank. 2. Implementieren Sie verteilte Sperren basierend auf dem Cache (Redis usw.). 3. Implementieren Sie verteilte Sperren basierend auf Zookeeper. Aus Leistungssicht (von hoch nach niedrig): „Cache-Modus > Zookeeper-Modus > = Datenbankmodus“.

Die Betriebsumgebung dieses Artikels: Windows-System, Redis 6.0, Thinkpad T480-Computer.
Drei Möglichkeiten zur Implementierung verteilter Sperren:
. Implementieren Sie verteilte Sperren basierend auf dem Cache (Redis usw.);
1. Implementieren Sie eine verteilte Sperre basierend auf der Datenbank Verwenden Sie select … where … für die Aktualisierung der exklusiven Sperre Hinweis: Andere zusätzliche Funktionen sind grundsätzlich die gleichen wie bei der Implementierung ist „where name= lock“, das Namensfeld muss indiziert werden, sonst wird die Tabelle gesperrt. In einigen Fällen, beispielsweise wenn die Tabelle nicht groß ist, verwendet der MySQL-Optimierer diesen Index nicht, was zu Problemen mit der Tabellensperre führt.
2. Optimistische Sperre
Der größte Unterschied zwischen der sogenannten optimistischen Sperre und den vorherigen besteht darin, dass sie sich nicht gegenseitig ausschließt und während des Betriebs keine Sperre verursacht Es wird davon ausgegangen, dass kein Parallelitätskonflikt vorliegt, erst wenn die Aktualisierung der Version fehlschlägt. Unsere Eilverkäufe und Flash-Verkäufe nutzen diese Implementierung, um Überverkäufe zu verhindern.
Implementieren Sie eine optimistische Sperre, indem Sie ein inkrementelles Versionsnummernfeld hinzufügen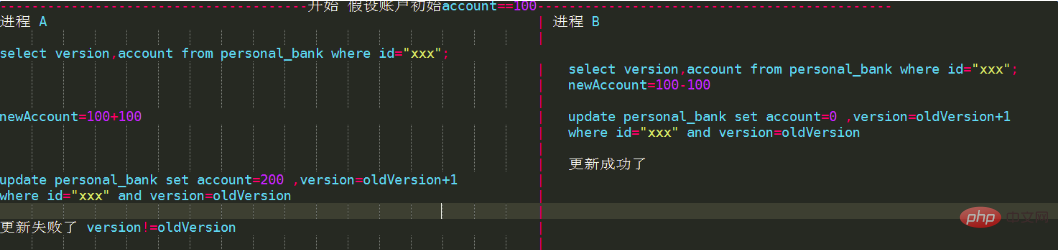
1. Einführung in die Verwendung von Befehlen: (1) SETNXSETNX Schlüsselwert: Nur wenn der Schlüssel nicht vorhanden ist, legen Sie eine Zeichenfolge mit dem Schlüsselwert fest und geben Sie 1 zurück. Wenn der Schlüssel vorhanden ist, tun Sie nichts und geben Sie 0 zurück. (2) Ablaufdatum des Schlüssels: Legen Sie ein Zeitlimit für den Schlüssel fest. Das Gerät wird nach dieser Zeit automatisch freigegeben, um einen Deadlock zu vermeiden. (3) delete
delete key: delete key
Bei Verwendung von Redis zur Implementierung verteilter Sperren werden hauptsächlich diese drei Befehle verwendet.
2. Implementierungsidee:
(1) Verwenden Sie beim Erwerb der Sperre setnx, um sie zu sperren, und fügen Sie der Sperre mit dem Befehl „expire“ eine Zeitüberschreitung hinzu lock ist eine zufällig generierte UUID, die zur Beurteilung verwendet wird, wann die Sperre aufgehoben wird.
(2) Beim Erwerb der Sperre wird auch eine Timeout-Zeit für den Erwerb festgelegt. Bei Überschreitung dieser Zeit wird der Erwerb der Sperre aufgegeben.
(3) Wenn Sie eine Sperre aufheben, verwenden Sie die UUID, um festzustellen, ob es sich um die Sperre handelt. Wenn es sich um die Sperre handelt, führen Sie „Delete“ aus, um die Sperre aufzuheben.
3. Einfacher Implementierungscode der verteilten Sperre:
/**
* 分布式锁的简单实现代码 */
public class DistributedLock {
private final JedisPool jedisPool;
public DistributedLock(JedisPool jedisPool) {
this.jedisPool = jedisPool;
}
/**
* 加锁
* @param lockName 锁的key
* @param acquireTimeout 获取超时时间
* @param timeout 锁的超时时间
* @return 锁标识
*/
public String lockWithTimeout(String lockName, long acquireTimeout, long timeout) {
Jedis conn = null;
String retIdentifier = null;
try {
// 获取连接
conn = jedisPool.getResource();
// 随机生成一个value
String identifier = UUID.randomUUID().toString();
// 锁名,即key值
String lockKey = "lock:" + lockName;
// 超时时间,上锁后超过此时间则自动释放锁
int lockExpire = (int) (timeout / );
// 获取锁的超时时间,超过这个时间则放弃获取锁
long end = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() results = transaction.exec();
if (results == null) {
continue;
}
retFlag = true;
}
conn.unwatch();
break;
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retFlag;
}
}
4. Testen Sie die gerade implementierte verteilte Sperre
Im Beispiel werden 50 Threads verwendet, um das sofortige Beenden eines Produkts zu simulieren, und der –-Operator wird verwendet, um die zu reduzieren Produkt und die Ergebnisse werden geordnet. Mithilfe der Funktion können Sie sehen, ob es gesperrt ist.
public class Service {
private static JedisPool pool = null;
private DistributedLock lock = new DistributedLock(pool);
int n = 500;
static {
JedisPoolConfig config = new JedisPoolConfig();
// 设置最大连接数
config.setMaxTotal(200);
// 设置最大空闲数
config.setMaxIdle(8);
// 设置最大等待时间
config.setMaxWaitMillis(1000 * 100);
// 在borrow一个jedis实例时,是否需要验证,若为true,则所有jedis实例均是可用的
config.setTestOnBorrow(true);
pool = new JedisPool(config, "127.0.0.1", 6379, 3000);
}
public void seckill() {
// 返回锁的value值,供释放锁时候进行判断
String identifier = lock.lockWithTimeout("resource", 5000, 1000);
System.out.println(Thread.currentThread().getName() + "获得了锁");
System.out.println(--n);
lock.releaseLock("resource", identifier);
}
}Simulieren Sie Threads, um Flash-Kill-Dienste auszuführen.
public class ThreadA extends Thread {
private Service service;
public ThreadA(Service service) {
this.service = service;
}
@Override
public void run() {
service.seckill();
}
}
public class Test {
public static void main(String[] args) {
Service service = new Service();
for (int i = 0; i Die Ergebnisse sind wie folgt, die Ergebnisse sind in der richtigen Reihenfolge: <p></p><p></p><p>Wenn Sie den Teil mit Sperren auskommentieren: </p><pre class="brush:php;toolbar:false">public void seckill() {
// 返回锁的value值,供释放锁时候进行判断
//String indentifier = lock.lockWithTimeout("resource", 5000, 1000);
System.out.println(Thread.currentThread().getName() + "获得了锁");
System.out.println(--n);
//lock.releaseLock("resource", indentifier);
}Wie aus den Ergebnissen ersichtlich ist , einige werden asynchron ausgeführt:
Drei, Implementierung verteilter Sperren basierend auf Zookeeper
(1) Erstellen Sie ein Verzeichnis mylock; (2) Wenn Thread A die Sperre erwerben möchte, erstellen Sie einen temporären Sequenzknoten im mylock-Verzeichnis (3) Holen Sie sich alle untergeordneten Knoten im Mylock-Verzeichnisknoten und rufen Sie dann den Geschwisterknoten ab, der kleiner als er selbst ist. Wenn er nicht vorhanden ist, bedeutet dies, dass der aktuelle Thread die kleinste Sequenznummer hat und die Sperre erhält. (4) Thread B erhält alle Knoten, stellt fest, dass es sich nicht um den kleinsten Knoten handelt, und richtet Überwachungsknoten ein, die kleiner als er selbst sind.
(5) Nachdem Thread A die Verarbeitung abgeschlossen hat, löscht er seinen eigenen Knoten und stellt fest, ob er der kleinste ist Wenn ja, erhält er die Sperre. Hier empfehlen wir Curator, eine Apache-Open-Source-Bibliothek, bei der es sich um einen ZooKeeper-Client handelt. Der von Curator bereitgestellte InterProcessMutex dient zum Erfassen von Sperren und die Release-Methode zum Freigeben von Sperren.
Der Implementierungsquellcode lautet wie folgt:
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang.StringUtils;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryNTimes;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
/**
* 分布式锁Zookeeper实现
*
*/
@Slf4j
@Component
public class ZkLock implements DistributionLock {
private String zkAddress = "zk_adress";
private static final String root = "package root";
private CuratorFramework zkClient;
private final String LOCK_PREFIX = "/lock_";
@Bean
public DistributionLock initZkLock() {
if (StringUtils.isBlank(root)) {
throw new RuntimeException("zookeeper 'root' can't be null");
}
zkClient = CuratorFrameworkFactory
.builder()
.connectString(zkAddress)
.retryPolicy(new RetryNTimes(2000, 20000))
.namespace(root)
.build();
zkClient.start();
return this;
}
public boolean tryLock(String lockName) {
lockName = LOCK_PREFIX+lockName;
boolean locked = true;
try {
Stat stat = zkClient.checkExists().forPath(lockName);
if (stat == null) {
log.info("tryLock:{}", lockName);
stat = zkClient.checkExists().forPath(lockName);
if (stat == null) {
zkClient
.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.forPath(lockName, "1".getBytes());
} else {
log.warn("double-check stat.version:{}", stat.getAversion());
locked = false;
}
} else {
log.warn("check stat.version:{}", stat.getAversion());
locked = false;
}
} catch (Exception e) {
locked = false;
}
return locked;
}
public boolean tryLock(String key, long timeout) {
return false;
}
public void release(String lockName) {
lockName = LOCK_PREFIX+lockName;
try {
zkClient
.delete()
.guaranteed()
.deletingChildrenIfNeeded()
.forPath(lockName);
log.info("release:{}", lockName);
} catch (Exception e) {
log.error("删除", e);
}
}
public void setZkAddress(String zkAddress) {
this.zkAddress = zkAddress;
}
}Vorteile: Es verfügt über Funktionen für hohe Verfügbarkeit, Wiedereintrittsfähigkeit und blockierende Sperren, die das Problem des Fehler-Deadlocks lösen können.
Nachteile: Da Knoten häufig erstellt und gelöscht werden müssen, ist die Leistung nicht so gut wie bei Redis. Viertens, Vergleich
Implementierung verteilter DatenbanksperrenNachteile: 1. Die Leistung des Datenbankvorgangs ist schlecht und es besteht die Gefahr einer Tabellensperre. Redis (Cache) verteilte Sperrenimplementierung 1 Die Ablaufzeit des Sperrlöschfehlers ist schwer zu kontrollieren Kurz gesagt: ZooKeeper bietet eine gute Leistung und Zuverlässigkeit. Aus Sicht der Benutzerfreundlichkeit (von niedrig nach hoch) Datenbank > Cache > Zookeeper
2 Nachdem der nicht blockierende Vorgang fehlgeschlagen ist, werden CPU-Ressourcen beansprucht.
3 Lange Zeit kann mehr Verbindungsressourcen beanspruchen
Nachteile:
2. Nicht blockierend, nachdem der Vorgang fehlgeschlagen ist Erforderlich und CPU-Ressourcen sind belegt dann mit den Followern synchronisiert.
Das obige ist der detaillierte Inhalt vonWas sind die drei Implementierungsmethoden verteilter Sperren?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!