
Erfahren Sie, wie Sie zig Millionen Datensätze in SQL Server verarbeiten

- coldplay.xixinach vorne
- 2020-11-27 16:42:299611Durchsuche
In der Spalte
SQLTutorial erfahren Sie, wie Sie zig Millionen Datensätze verarbeiten.

Empfohlen: SQL-Tutorial
Projekthintergrund
Die Schwierigkeit des Projekts ist wirklich unglaublich Schlachtfeld, und ich bin nur ein Soldat darin. Es gibt zu viele Taktiken, zu viele Wettbewerbe zwischen hochrangigen Beamten und zu viele Insider-Geschichten. Bezüglich der spezifischen Situation dieses Projekts werde ich, wenn ich Zeit habe, einen entsprechenden Blogbeitrag schreiben.
Dieses Projekt erfordert eine Umweltüberwachung. Im Moment bezeichnen wir die überwachte Ausrüstung als Sammelgerät, und die Eigenschaften der Sammelausrüstung werden als Überwachungsindikatoren bezeichnet. Projektanforderungen: Das System unterstützt nicht weniger als 10w Überwachungsindikatoren, die Datenaktualisierung jedes Überwachungsindikators darf nicht länger als 20 Sekunden sein und die Speicherverzögerung darf 120 Sekunden nicht überschreiten. Dann können wir durch einfache Berechnungen den Idealzustand ermitteln – die zu speichernden Daten sind: 30 W pro Minute, 1800 W pro Stunde, also 432 Millionen pro Tag. In Wirklichkeit wird die Datenmenge etwa 5 % größer sein. (Tatsächlich ist das meiste davon Informationsmüll, der durch Datenkomprimierung verarbeitet werden kann, aber wenn andere sich mit Ihnen anlegen wollen, was können Sie tun?)
Die oben genannten Indikatoren sind meiner Meinung nach für viele Studenten erforderlich Haben Sie viel Erfahrung in der Verarbeitung großer Datenmengen? Das ist alles. Nun, ich habe auch viel über die Verarbeitung großer Datenmengen gelesen, aber wenn ich mir die klaren Erklärungen anderer Leute ansehe, scheint es wirklich einfach zu sein, herauszufinden, was verteilt ist und was Lesen und Schreiben trennt. Das Problem ist jedoch nicht so einfach. Wie ich oben sagte, handelt es sich um ein sehr schlechtes Projekt und ein typisches Projekt harter Konkurrenz in der Branche.
- Es gibt keine weiteren Server, aber zusätzlich zur Datenbank und dem zentralen Sammler (also dem Programm zur Datenanalyse, Alarmierung und Speicherung) unterstützt dieser Server auch die 300.000-Punkt-Northbound-Schnittstelle (SNMP). Das Programm ist optimiert, die CPU ist das ganze Jahr über zu mehr als 80 % ausgelastet. Da das Projekt die Verwendung von Dual-Machine-Hot-Standby erfordert, haben wir, um Zeit zu sparen und unnötige Probleme zu reduzieren, zugehörige Dienste zusammengestellt, damit wir die Eigenschaften von HA (extern erworbenes HA-System) voll ausnutzen können.
- Das System Die Anforderungen an die Datenkorrektheit sind extrem hoch. Es ist erforderlich, dass es zwischen dem unteren Erfassungssystem und dem Überwachungssystem der obersten Ebene keine Unterschiede in den Daten gibt. Unsere Systemarchitektur ist wie folgt. Sie können sehen, dass der Datenbankdruck sehr hoch ist , insbesondere auf dem LevelA-Knoten:
 Die Hardwarekonfiguration ist wie folgt:
Die Hardwarekonfiguration ist wie folgt: -
CPU:Intel® 500 GB 7200 U/min 3,5'' SATA3-Festplatte, Raid5.
Datenbankversion verwendet die SQLServer2012-Standardversion, die Originalsoftware bereitgestellt von HP, dem viele NB-Funktionen der Enterprise-Version fehlen.
Empfehlen Sie Ihre eigene LinuxC/C++-Kommunikationsgruppe: 973961276! Ich habe einige Lernbücher, Videomaterialien und Interviews mit großen Herstellern zusammengestellt, die ich persönlich für besser halte, und sie in den Gruppendateien geteilt. Freunde, die sie benötigen, können sie selbst hinzufügen! ~
Das erste Hindernis, auf das wir gestoßen sind, war, dass wir festgestellt haben, dass SQL Server unter dem vorhandenen Programm keine so große Datenmenge verarbeiten konnte. Was ist die spezifische Situation?
Unsere Speicherstruktur
Um eine große Menge historischer Daten zu speichern, erstellen wir im Allgemeinen eine physische Tabelle. Andernfalls sind es jeden Tag Hunderte Millionen Datensätze im Jahr. Daher ist unsere ursprüngliche Tabellenstruktur wie folgt:CREATE TABLE [dbo].[His20140822](
[No] [bigint] IDENTITY(1,1) NOT NULL,
[Dtime] [datetime] NOT NULL,
[MgrObjId] [varchar](36) NOT NULL,
[Id] [varchar](50) NOT NULL,
[Value] [varchar](50) NOT NULL,
CONSTRAINT [PK_His20140822] PRIMARY KEY CLUSTERED (
[No] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]) ON [PRIMARY]No als eindeutige Kennung, Erfassungsgeräte-ID (Guid), Überwachungsindikator-ID (varchar(50)), Aufzeichnungszeit und Aufzeichnungswert. Und verwenden Sie die Erfassungsgeräte-ID und die Überwachungsindikator-ID als Index, um eine schnelle Suche zu erleichtern. Batch-SchreibenBulKCopy wurde zum Schreiben verwendet. Ja, das ist es. Es behauptet, Millionen von Datensätzen in Sekunden zu schreiben
Was ist das Problem? Die obige Architektur ist für 40 Millionen Daten pro Tag geeignet. Als die Konfiguration jedoch an den oben genannten Hintergrund angepasst wurde, überlief das zentrale Überwachungsprogramm den Speicher. Die Analyse ergab, dass zu viele Daten empfangen und im Speicher abgelegt wurden, aber keine Zeit blieb, sie in die Datenbank zu schreiben, was letztendlich dazu führte Die generierten Daten, die größer als verbraucht sind, führen zu einem Speicherüberlauf und das Programm funktioniert nicht.
Wo ist der Engpass? Liegt es am RAID-Festplattenproblem? Handelt es sich um ein Datenstrukturproblem? Handelt es sich um ein Hardwareproblem? Liegt es an der SQL Server-Version? Ist es ein Problem, dass es keine Partitionstabelle gibt? Oder ist es ein Programmproblem?
Wenn nicht, bat uns der Projektleiter, 48 Stunden lang ununterbrochen zu arbeiten, und wir mussten überall Leute anrufen, um um Hilfe zu bitten. .
Aber zu diesem Zeitpunkt müssen wir ruhig sein, wieder ruhig ... SQLServer-Version? Hardware? Es ist derzeit unwahrscheinlich, dass es ersetzt wird. RAID-Festplattenarray, wahrscheinlich nicht. Was ist also los? Ich kann mich wirklich nicht beruhigen.
Vielleicht verstehen Sie die angespannte Atmosphäre am Tatort nicht. Tatsächlich fällt es mir nach so langer Zeit schwer, in diese Situation zurückzukehren. Aber man kann sagen, dass wir jetzt vielleicht über verschiedene Methoden verfügen oder als Außenstehende mehr Gedanken haben, aber wenn ein Projekt Sie so sehr unter Druck setzt, dass Sie aufgeben müssen, werden Ihre Gedanken und Überlegungen zu diesem Zeitpunkt durch die Umweltfaktoren vor Ort eingeschränkt . Es können erhebliche Abweichungen auftreten. Es kann dazu führen, dass Sie schnell nachdenken, oder dass Ihr Denken stagniert. In dieser Hochdruckumgebung machten einige Kollegen sogar noch mehr kleine Fehler, ihr Denken war völlig durcheinander und ihre Effizienz war noch geringer ... Sie haben 36 Stunden lang kein Auge zugetan oder sind einfach drangeblieben Baustelle (an regnerischen Tagen war überall Schlamm und sie waren trocken) Wenn es fertig ist, ist bis dahin alles Schlamm) Schielen Sie zwei oder drei Stunden lang und machen Sie es dann eine Woche lang weiter! Oder machen Sie weiter!
Viele Leute haben viele Ideen gegeben, aber sie scheinen nützlich zu sein und einige sind nutzlos. Warten Sie, warum „scheint zu funktionieren, aber nicht zu funktionieren“? Ich scheine vage eine Richtung begriffen zu haben. Übrigens, wir laufen jetzt in einer Live-Umgebung. Es gab vorher keine Probleme, aber das bedeutet nicht, dass es unter dem aktuellen Druck keine zu großen Auswirkungen hat , also sollten wir es aufschlüsseln. Ja, es handelt sich um einen „Unit-Test“, bei dem es sich um einen Test einer einzelnen Methode handelt. Wofür braucht jeder einzelne Schritt Zeit?
Schritt-für-Schritt-Test zur Überprüfung von Systemengpässen
Ändern der Parameter von BulkCopy
Zunächst dachte ich daran, die Parameter von BulkCopy, BulkCopyTimeout, , zu ändern BatchSize, ständige Tests und Anpassungen, die Ergebnisse schwanken immer in einem bestimmten Bereich, haben aber keine tatsächliche Auswirkung. Es kann sich auf einige CPU-Zahlen auswirken, aber es entspricht bei weitem nicht meinen Erwartungen. Die Schreibgeschwindigkeit schwankt immer noch zwischen 10.000 und 2.000 Mal in 5 Sekunden, was weit von der Anforderung entfernt ist, 20.000.000 Datensätze in 20 Sekunden zu schreiben. BulkCopyTimeout、BatchSize,不断的测试调整,结果总是在某个范围波动,实际并没有影响。或许会影响一些CPU计数,但是远远没有达到我的期望,写入的速度还是在5秒1w~2w波动,远远达不到要求20秒内要写20w的记录。
按采集设备存储
是的,上述结构按每个指标每个值为一条记录,是不是太多的浪费?那么按采集设备+采集时间作为一条记录是否可行?问题是,怎么解决不同采集设备属性不一样的问题?这时,一个同事发挥才能了,监控指标+监控值可以按XML格式存储。哇,还能这样?查询呢,可以用for XML这种形式。
于是有了这种结构:No、MgrObjId、Dtime、XMLData
Speicherung nach Sammelgerät
Ja, die obige Struktur ist eine Aufzeichnung für jeden Wert jedes Indikators. Ist es zu viel Abfall? Ist es also möglich, das Erfassungsgerät + die Erfassungszeit als Datensatz zu verwenden? Die Frage ist, wie das Problem der unterschiedlichen Attribute verschiedener Erfassungsgeräte gelöst werden kann. Zu diesem Zeitpunkt zeigte ein Kollege sein Talent. Überwachungsindikatoren + Überwachungswerte können im XML-Format gespeichert werden. Wow, kann das passieren? Für Abfragen können Sie XML verwenden. Wir haben also diese Struktur: No, MgrObjId, Dtime, XMLData
Datentabellenpartition???
Andere Programme stoppen
Ist das der Flaschenhals von SQL Server? Auf keinen Fall, ist das der Flaschenhals von SQL Server? Ich habe die relevanten Informationen online überprüft und festgestellt, dass dies möglicherweise der Engpass von IO ist. Was kann ich sonst noch tun, um den Server zu aktualisieren und die Datenbank zu ersetzen?
Moment mal, da scheint noch etwas anderes zu sein, Index, richtiger Index! Das Vorhandensein des Index wirkt sich auf das Einfügen und Aktualisieren aus
Entfernen Sie den IndexJa, die Abfrage wird nach dem Entfernen des Index definitiv langsamer sein, aber ich muss zuerst überprüfen, ob das Entfernen des Index das Schreiben beschleunigt. Wenn Sie die Indizes der Felder MgrObjId und Id endgültig entfernen.
Führen Sie es aus, und jedes Mal werden 100.000 Datensätze geschrieben, und es kann innerhalb von 7 bis 9 Sekunden geschrieben werden, wodurch die Systemanforderungen erfüllt werden.
Wie löse ich die Abfrage?
🎜Eine Tabelle benötigt mehr als 400 Millionen Datensätze pro Tag, was ohne Index nicht abzufragen ist. was zu tun! ? Ich dachte wieder an unsere alte Methode, physische Untertabellen. Ja, ursprünglich haben wir den Zeitplan nach Tagen unterteilt, jetzt teilen wir den Zeitplan nach Stunden. Dann gibt es 24 Tabellen, jede Tabelle muss nur etwa 18 Millionen Datensätze speichern. 🎜🎜Fragen Sie dann den Verlauf eines Attributs in einer Stunde oder mehreren Stunden ab. Das Ergebnis ist: langsam! langsam! ! langsam! ! ! Es ist einfach unvorstellbar, mehr als 10 Millionen Datensätze ohne Indizierung abzufragen. Was kann man sonst noch tun? 🎜🎜Weitere Tabellenaufteilung, dachte ich, wir können die Tabelle auch weiterhin nach dem zugrunde liegenden Sammler aufteilen, da die Sammlungsausrüstung in verschiedenen Sammlern unterschiedlich ist. Wenn wir dann die historische Kurve abfragen, können wir nur die historische Kurve von a überprüfen einzelner Indikator. Dann kann er auf verschiedene Tabellen verteilt werden. 🎜说干就干,结果,通过按10个采集嵌入式并按24小时分表,每天生成240张表(历史表名类似这样:His_001_2014112615),终于把一天写入4亿多条记录并支持简单的查询这个问题给解决掉了!!!
查询优化
在上述问题解决之后,这个项目的难点已经解决了一半,项目监管也不好意思过来找茬,不知道是出于什么样的战术安排吧。
过了很长一段时间,到现在快年底了,问题又来了,就是要拖死你让你在年底不能验收其他项目。
这次要求是这样的:因为上述是模拟10w个监控指标,而现在实际上线了,却只有5w个左右的设备。那么这个明显是不能达到标书要求的,不能验收。那么怎么办呢?这些聪明的人就想,既然监控指标减半,那么我们把时间也减半,不就达到了吗:就是说按现在5w的设备,那你要10s之内入库存储。我勒个去啊,按你这个逻辑,我们如果只有500个监控指标,岂不是要在0.1秒内入库?你不考虑下那些受监控设备的感想吗?
但是别人要玩你,你能怎么办?接招呗。结果把时间降到10秒之后,问题来了,大家仔细分析上面逻辑可以知道,分表是按采集器分的,现在采集器减少,但是数量增加了,发生什么事情呢,写入可以支持,但是,每张表的记录接近了400w,有些采集设备监控指标多的,要接近600w,怎么破?
于是技术相关人员开会讨论相关的举措。
在不加索引的情况下怎么优化查询?
有同事提出了,where子句的顺序,会影响查询的结果,因为按你刷选之后的结果再处理,可以先刷选出一部分数据,然后继续进行下一个条件的过滤。听起来好像很有道理,但是SQLServer查询分析器不会自动优化吗?原谅我是个小白,我也是感觉而已,感觉应该跟VS的编译器一样,应该会自动优化吧。
具体怎样,还是要用事实来说话:
结果同事修改了客户端之后,测试反馈,有较大的改善。我查看了代码: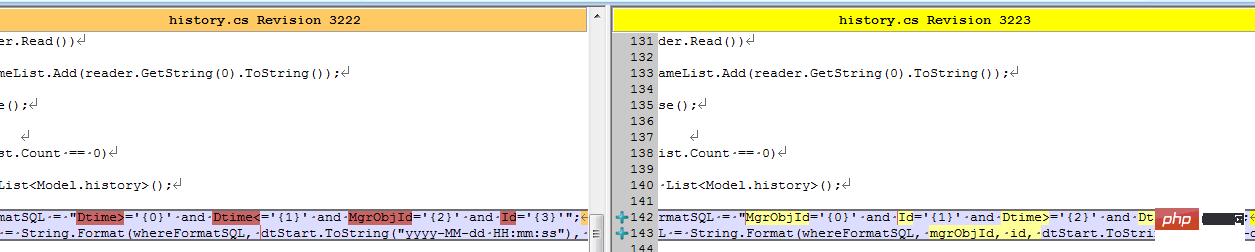
难道真的有这么大的影响?等等,是不是忘记清空缓存,造成了假象?
于是让同事执行下述语句以便得出更多的信息:
--优化之前DBCC FREEPROCCACHEDBCC DROPCLEANBUFFERSSET STATISTICS IO ONselect Dtime,Value from dbo.his20140825 WHERE Dtime>='' AND Dtime<='' AND MgrObjId='' AND Id=''SET STATISTICS IO OFF--优化之后DBCC FREEPROCCACHEDBCC DROPCLEANBUFFERSSET STATISTICS IO ONselect Dtime,Value from dbo.his20140825 WHERE MgrObjId='' AND Id='' AND Dtime>='' AND Dtime<=''SET STATISTICS IO OFF
结果如下: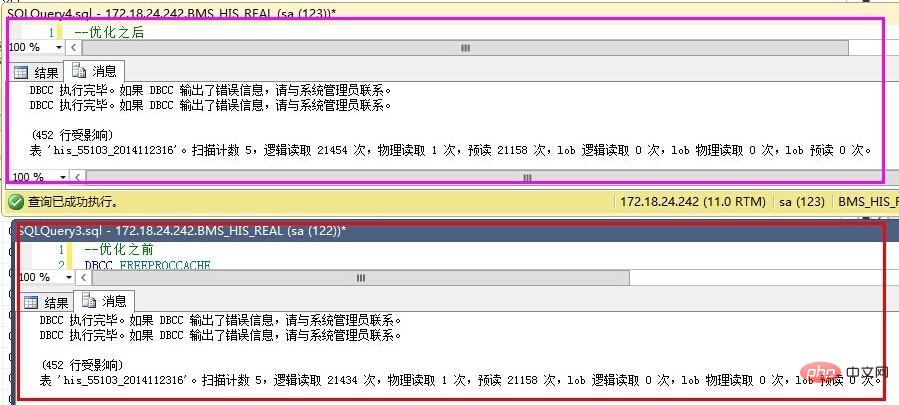
优化之前反而更好了?
仔细查看IO数据,发现,预读是一样的,就是说我们要查询的数据记录都是一致的,物理读、表扫描也是一直的。而逻辑读取稍有区别,应该是缓存命中数导致的。也就是说,在不建立索引的情况下,where子句的条件顺序,对查询结果优化作用不明显。
那么,就只能通过索引的办法了。
建立索引的尝试
建立索引不是简单的事情,是需要了解一些基本的知识的,在这个过程中,我走了不少弯路,最终才把索引建立起来。
下面的实验基于以下记录总数做的验证:
按单个字段建立索引
这个想法,主要是受我建立数据结构影响的,我内存中的数据结构为:Dictionary44c8bf3c168555d7e46180150f40c496>。我以为先建立MgrObjId的索引,再建立Id的索引,SQLServer查询时,就会更快。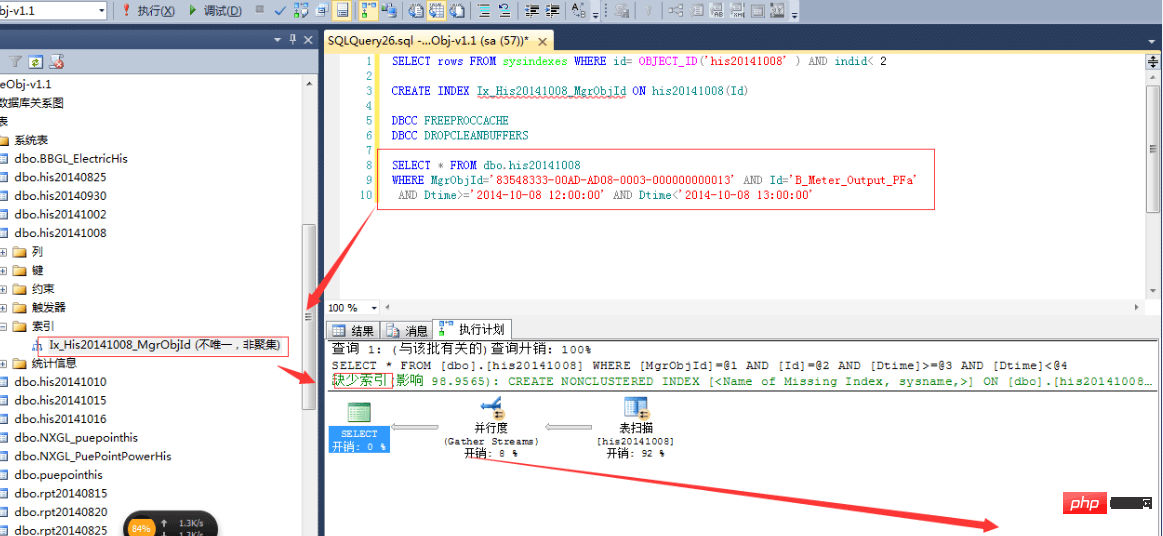
先按MgrObjId建立索引,索引大小为550M,耗时5分25秒。结果,如上图的预估计划一样,根本没有起作用,反而更慢了。
按多个条件建立索引
OK,既然上面的不行,那么我们按多个条件建立索引又如何?CREATE NONCLUSTERED INDEX Idx_His20141008 ON dbo.his20141008(MgrObjId,Id,Dtime)
结果,查询速度确实提高了一倍: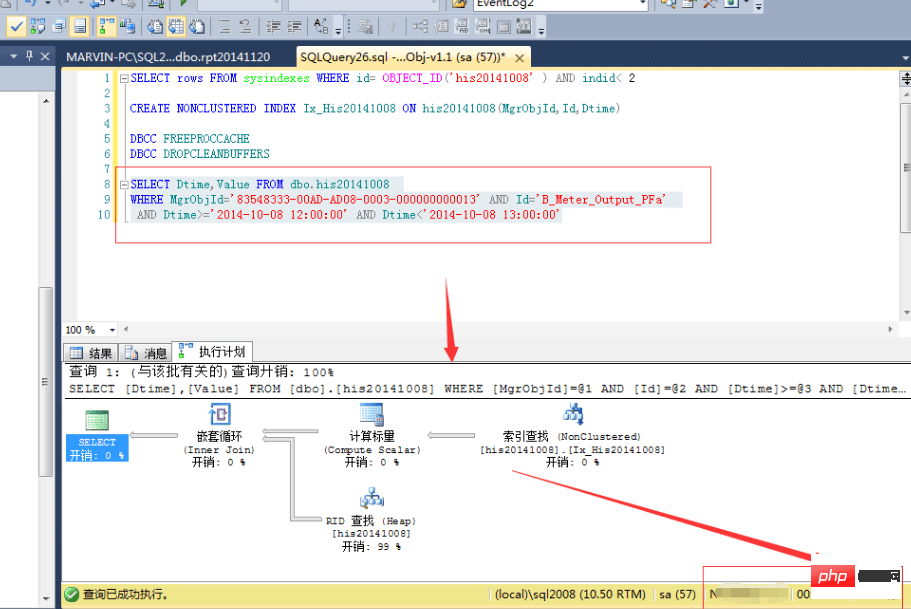
等等,难道这就是索引的好处?花费7分25秒,用1.1G的空间换取来的就是这些?肯定是有什么地方不对了,于是开始翻查资料,查看一些相关书籍,最终,有了较大的进展。
正确的建立索引
首先,我们需要明白几个索引的要点:
- Nach der Indizierung wird durch Sortieren nach den am wenigsten wiederholten Indexfeldern der optimale Effekt erzielt. Wenn für unsere Tabelle ein Clustered-Index von No erstellt wird, ist es am besten, No zuerst in die where-Klausel einzufügen, gefolgt von Id, dann MgrObjId und schließlich time. Wenn der Zeitindex eine Stunde ist, ist es am besten, dies nicht zu tun verwenden
-
Die Reihenfolge der where-Klausel bestimmt, ob der Abfrageanalysator den Index zum Abfragen verwendet . Wenn beispielsweise der Index von MgrObjId und Id eingerichtet ist, verwendet
where MgrObjId='' und Id='' und Dtime=''die Indexsuche undwhere Dtime='' und MgrObjId= '' und Id=''verwenden nicht unbedingt die Indexsuche.where MgrObjId='' and Id='' and Dtime=''就会采用索引查找,而where Dtime='' and MgrObjId='' and Id=''则不一定会采用索引查找。 - 把非索引列的结果列放在包含列中。因为我们条件是MgrObjId和Id以及Dtime,因此返回结果中只需包含Dtime和Value即可,因此把Dtime和Value放在包含列中,返回的索引结果就有这个值,不用再查物理表,可以达到最优的速度。
跟上述几点原则,我们建立以下的索引:CREATE NONCLUSTERED INDEX Idx_His20141008 ON dbo.his20141008(MgrObjId,Id) INCLUDE(Value,Dtime)
Fügen Sie die Ergebnisspalte der nicht indizierten Spalte in die enthaltende Spalte ein
. Da unsere Bedingung MgrObjId, Id und Dtime ist, müssen wir nur Dtime und Value in die enthaltene Spalte einfügen, und das zurückgegebene Indexergebnis muss nicht überprüft werden Der physische Tisch erreicht die optimale Geschwindigkeit. Den oben genannten Grundsätzen folgend erstellen wir den folgenden Index:
Den oben genannten Grundsätzen folgend erstellen wir den folgenden Index: CREATE NONCLUSTERED INDEX Idx_His20141008 ON dbo.his20141008(MgrObjId,Id) INCLUDE(Value,Dtime)
Die benötigte Zeit beträgt: mehr als 6 Minutenuhr, die Indexgröße beträgt 903M.
Schauen wir uns den geschätzten Plan an:
Wie Sie sehen, wird der Index hier vollständig verwendet, ohne dass ein zusätzlicher Verbrauch entsteht. Die tatsächlichen Ausführungsergebnisse dauerten weniger als 1 Sekunde und die Ergebnisse wurden in weniger als einer Sekunde aus den 11 Millionen Datensätzen herausgefiltert! ! So hübsch! !
Wie wendet man den Index an?
Nachdem das Schreiben und das Lesen abgeschlossen sind, wie kann man beides kombinieren? Wir können die Daten von vor einer Stunde indizieren, nicht jedoch die Daten der aktuellen Stunde. Das heißt, erstellen Sie beim Erstellen von Tabellen keine Indizes! !
Wie können Sie sonst noch optimieren? Sie können versuchen, das Lesen und Schreiben zu trennen und zwei Bibliotheken zu schreiben, eine ist eine Echtzeitbibliothek und die andere ist eine schreibgeschützte Bibliothek. Die Daten innerhalb einer Stunde werden in der Echtzeitdatenbank abgefragt, und die Daten vor einer Stunde werden in der schreibgeschützten Datenbank regelmäßig abgefragt und dann werden die Daten über eine Woche hinweg analysiert, verarbeitet und dann gespeichert. Auf diese Weise können die Daten unabhängig vom Zeitraum der Abfrage korrekt verarbeitet werden: Abfragen der Echtzeitdatenbank innerhalb einer Stunde, Abfragen der schreibgeschützten Datenbank innerhalb einer Stunde bis einer Woche und Abfragen der Berichtsdatenbank innerhalb einer Woche vor. Wenn Sie kein physisches Tabellen-Sharding benötigen, können Sie den Index regelmäßig in der schreibgeschützten Bibliothek neu erstellen.
- Zusammenfassung
- Wie Sie Milliarden von Daten (historische Daten) in SQL Server verarbeiten, können Sie wie folgt vorgehen:
- Alle Indizes der Tabelle entfernen
- SqlBulkCopy zum Einfügen verwenden
- Tabellen aufteilen oder Partitionen verkleinern Die Gesamtdatenmenge in jeder Tabelle.
- Erstellen Sie einen Index, nachdem eine Tabelle vollständig geschrieben wurde.
- Geben Sie die Indexfelder korrekt an.
Das obige ist der detaillierte Inhalt vonErfahren Sie, wie Sie zig Millionen Datensätze in SQL Server verarbeiten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!