
Heim >Datenbank >MySQL-Tutorial >Ausführliche Erläuterung der Verwendung der Funktionen „Partition nach' und „row_number' in SQL Server
Ausführliche Erläuterung der Verwendung der Funktionen „Partition nach' und „row_number' in SQL Server

- coldplay.xixinach vorne
- 2020-07-24 17:39:544425Durchsuche

Die Partitionierung nach Schlüsselwörtern ist Teil der Analysefunktion. Sie unterscheidet sich von der Aggregatfunktion dadurch, dass sie mehrere Datensätze in einer Gruppe zurückgeben kann, während die Aggregatfunktion im Allgemeinen nur einen zum Reflektieren hat Statistiken. Werteaufzeichnungen, Partitionierung nach wird zum Gruppieren des Ergebnissatzes verwendet. Wenn nicht angegeben, wird der gesamte Ergebnissatz als Gruppe behandelt.
Ich habe heute in der Gruppe eine Frage gesehen und ich werde sie hier zusammenfassen: Fragen Sie die neuesten Datensätze in verschiedenen Kategorien ab. Ist das auf den ersten Blick nicht sehr einfach? Wenn Sie klassifizieren möchten, verwenden Sie „Gruppieren nach“; wenn Sie den neuesten Datensatz wünschen, verwenden Sie „Sortieren nach“. Versuchen Sie dann, es in Ihrer eigenen Tabelle zu erstellen:
Verwandte Lernempfehlungen: MySQL-Video-Tutorial
Zuerst füge ich die Daten ein Die Tabelle erscheint in umgekehrter Reihenfolge der Einreichungszeit:
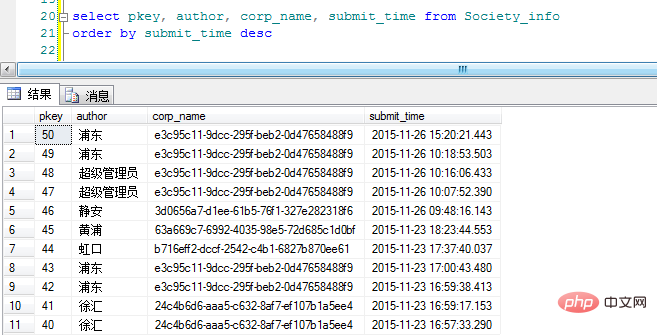
„corp_name“ ist die GUID der Kategorie (bitte entschuldigen Sie die Willkür meiner Benennung). OK, hier ist die ursprüngliche Idee, Group By hinzuzufügen, um den Anzeigeeffekt zu sehen:
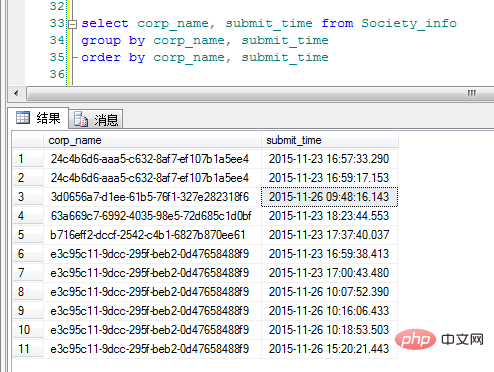
Äh, ähm. Dieses Ergebnis unterscheidet sich von dem, was ich mir vorgestellt habe. Es scheint, dass Sie das Problem beim Schreiben von Code immer noch rational analysieren müssen.
Da es sich bei den Anforderungen um unterschiedliche Datenkategorien handelt, gibt es neben der Verwendung von „Gruppieren nach“ noch andere Funktionen, die verwendet werden können? Ich habe einige Nachforschungen angestellt und herausgefunden, dass es tatsächlich eine Over-Funktion (Partition nach) gibt. Was ist also der Unterschied zwischen dieser Funktion und der normalerweise verwendeten Group By-Funktion? Neben der einfachen Gruppierung von Ergebnissen wird Group By im Allgemeinen zusammen mit Aggregatfunktionen verwendet und ist eine Oracle-Analysefunktion, auf die ich hier nicht näher eingehen werde.
Sehen Sie sich den Code an:
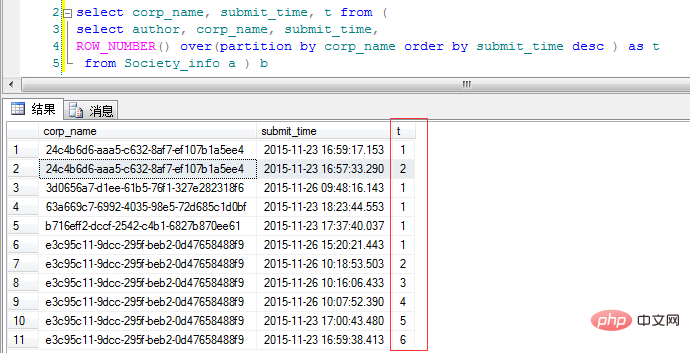
over(partition by corp_name order by subscribe_time desc ) as t . Es wird nach Unternehmensname klassifiziert und in umgekehrter chronologischer Reihenfolge sortiert. Die Spalte „t“ gibt hier die Anzahl der Vorkommen verschiedener Unternehmensnamensklassen an. Die Anforderung besteht darin, nur die neuesten Übermittlungsdaten verschiedener Kategorien abzufragen noch einmal für „t“. :
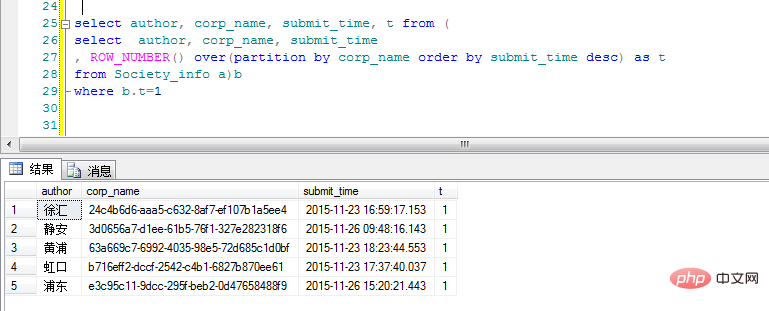
Okay, ich bitte Sie nicht, sie zu mögen, aber ich möchte nur, dass Sie mir einen Daumen hoch geben Wenn du dir die Brüste in meinem Avatar ansiehst, wünsche ich dir ein sicheres Leben! ! !
ps: Detaillierte Erläuterung der Verwendung der SQL Server-Datenbankpartitionierung nach und ROW_NUMBER()-Funktionen
Einige Nutzungserfahrungen der SQL-Partitionierung nach Feldern
Schau zuerst Beispiel:
if object_id('TESTDB') is not null drop table TESTDB create table TESTDB(A varchar(8), B varchar(8)) insert into TESTDB select 'A1', 'B1' union all select 'A1', 'B2' union all select 'A1', 'B3' union all select 'A2', 'B4' union all select 'A2', 'B5' union all select 'A2', 'B6' union all select 'A3', 'B7' union all select 'A3', 'B3' union all select 'A3', 'B4'
-- Alle Informationen
SELECT * FROM TESTDB A B ------- A1 B1 A1 B2 A1 B3 A2 B4 A2 B5 A2 B6 A3 B7 A3 B3 A3 B4
-- Nach Verwendung der PARTITION BY-Funktion kann
SELECT *,ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) NUM FROM TESTDB A B NUM ------------- A1 B1 1 A1 B2 2 A1 B3 3 A2 B4 1 A2 B5 2 A2 B6 3 A3 B7 1 A3 B3 2 A3 B4 3
sehen, dass es eine zusätzliche Spalte mit NUM in der gibt Diese NUM zeigt die gleiche Anzahl von Zeilen an. Wenn es beispielsweise 3 A1 gibt, markiert er die Nummer jedes A1.
-- Verwenden Sie einfach das Ergebnis von ROW_NUMBER() OVER
SELECT *,ROW_NUMBER() OVER(ORDER BY A DESC)NUM FROM TESTDB A B NUM ------------------------ A3 B7 1 A3 B3 2 A3 B4 3 A2 B4 4 A2 B5 5 A2 B6 6 A1 B1 7 A1 B2 8 A1 B3 9
Sie können sehen, dass es nur die Zeilennummer markiert.
--Eine tiefergehende Anwendung
SELECT A = CASE WHEN NUM = 1 THEN A ELSE '' END,B FROM (SELECT A,NUM = ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) FROM TESTDB) T A B --------- A1 B1 B2 B3 A2 B4 B5 B6 A3 B7 B3 B4
Als nächstes werden wir die Verwendung der Funktion ROW_NUMBER() anhand mehrerer Beispiele vorstellen.
Beispiele sind wie folgt:
1. Verwenden Sie die Funktion row_number() zur Nummerierung, z. B.
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
Prinzip: Sortieren nach psd zuerst. Nach dem Sortieren nummerieren Sie jedes Datenelement.
2. Sortieren Sie die Reihenfolge nach aufsteigendem Preis und sortieren Sie jeden Datensatz mit dem folgenden Code:
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3. Zählen Sie jeden Datensatz. Alle Bestellungen von Die einzelnen Haushalte werden in aufsteigender Reihenfolge nach dem Betrag der jeweiligen Kundenbestellung sortiert und die einzelnen Kundenbestellungen sind nummeriert. Auf diese Weise wissen Sie, wie viele Bestellungen jeder Kunde aufgegeben hat .
Wie im Bild gezeigt:

Der Code lautet wie folgt:
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order
4 Bestellung wurde aufgegeben.

Der Code lautet wie folgt:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order ) select MAX(rows) as '下单次数',customerID from tabs group by customerID
5. Zählen Sie den Mindesteinkaufsbetrag unter allen Bestellungen jedes Kunden und zählen Sie auch die geänderten Bestellungen. Wie oft hat der Kunde gekauft?
如图:

上图:rows表示客户是第几次购买。
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,customerID,totalPrice, DID from OP_Order ) select * from tabs where totalPrice in ( select MIN(totalPrice)from tabs group by customerID )
6.筛选出客户第一次下的订单。

思路。利用rows=1来查询客户第一次下的订单记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order ) select * from tabs where rows = 1 select * from OP_Order
7.rows_number()可用于分页
思路:先把所有的产品筛选出来,然后对这些产品进行编号。然后在where子句中进行过滤。
8.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
如下代码:
select ROW_NUMBER() over(partition by customerID order by insDT) as rows, customerID,totalPrice, DID from OP_Order where insDT>'2011-07-22'
以上代码是先执行where子句,执行完后,再给每一条记录进行编号。
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung der Verwendung der Funktionen „Partition nach' und „row_number' in SQL Server. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!