
Heim >Datenbank >MySQL-Tutorial >Relationale Datenbank MySQL drei: Beginnend mit dem Lebenszyklus einer SQL
Relationale Datenbank MySQL drei: Beginnend mit dem Lebenszyklus einer SQL

- coldplay.xixinach vorne
- 2020-11-13 17:16:472946Durchsuche
Die Spalte „MySQL-Tutorial“ stellt den Lebenszyklus von SQL in relationalen Datenbanken vor.
MYSQL-Abfrageverarbeitung
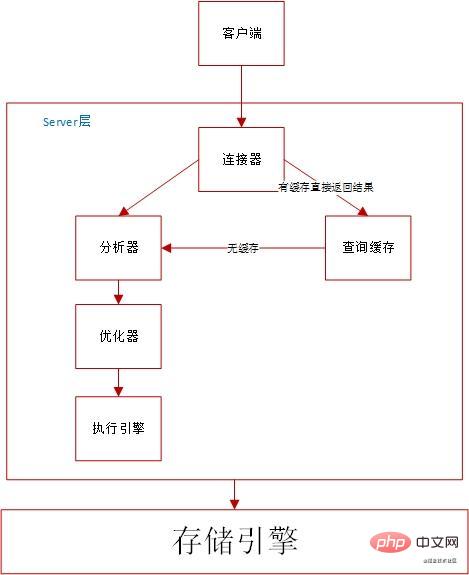
SQL-Ausführungsprozess ist im Grunde der gleiche wie MySQL-Architektur
. Die Verbindung wird zum Abfragen von SQL-Anweisungen und zum Ermitteln von Berechtigungen verwendet. Abfragecache:Ausführungsprozess:
- Mit Index: Der erste Aufruf besteht darin, die erste Zeile abzurufen, die die Bedingung erfüllt. Anschließend wird eine Schleife ausgeführt, um die nächste Zeile abzurufen, die die Bedingung erfüllt Ohne Index: Rufen Sie die InnoDB-Engine-Schnittstelle auf, um die erste Zeile dieser Tabelle abzurufen, beurteilen Sie die SQL-Abfragebedingung, überspringen Sie sie, wenn dies nicht der Fall ist, und speichern Sie diese Zeile im Ergebnissatz, wenn dies der Fall ist. Rufen Sie die Engine-Schnittstelle auf, um die nächste abzurufen Zeile und wiederholen Sie die gleiche Beurteilungslogik, bis Sie diese letzte Zeile der Tabelle erhalten. Der Executor gibt einen Datensatz, der aus allen Zeilen besteht, die die Bedingungen während des oben genannten Durchlaufprozesses erfüllen, als Ergebnismenge an den Client zurück keine Daten zurückgeben
[root@localhost][(none)]> explain select * from 表名 where project_id = 36;
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
| 1 | SIMPLE | 表名 | NULL | ref | project_id | project_id | 4 | const | 797964 | 100.00 | NULL |
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+复制代码
id
id hat von oben nach unten die gleiche Ausführungsreihenfolge
id ist unterschiedlich, je größer der ID-Wert, desto höher die Priorität, desto früher wird es ausgeführt
select_type
- SIMPLE: einfache Auswahlabfrage, die Abfrage enthält keine Unterabfragen oder Unions.
- PRIMARY: Die Abfrage enthält Unterteile und die äußerste Abfrage ist als primär markiert.
DERIVED: Sie ist Teil der Unterabfrage von
DEPENDENT UNTERABFRAGE: Die erste in der Unterabfrage SELECT, die Unterabfrage hängt vom Ergebnis der äußeren Abfrage ab SUBQUERY bedeutet, dass die Unterabfrage in der Select- oder Where-Liste enthalten ist,
MATERIALIZED: bedeutet die Unterabfrage der In-Bedingung hinter where
UNION: bedeutet die zweite oder zweite in der Union. Die folgende Select-Anweisung
- UNION RESULT: Das Ergebnis der Union
- Table-Objekt
type
- const > eq_ref > ref > Bereich > Index > ALLE (Abfrageeffizienz)
- system:表中只有一条数据,这个类型是特殊的const类型
- const:针对于主键或唯一索引的等值查询扫描,最多只返回一个行数据。速度非常快,因为只读取一次即可。
- eq_ref:此类型通常出现在多表的join查询,表示对于前表的每一个结果,都只能匹配到后表的一行结果,并且查询的比较操作通常是=,查询效率较高
- ref:此类型通常出现在多表的join查询,针对于非唯一或非主键索引,或者是使用了最左前缀规则索引的查询
- range:范围扫描 这个类型通常出现在 <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中
- index:索引树扫描
- ALL:全表扫描(full table scan)
- 可能使用的索引,注意不一定会使用
- 查询涉及到的字段上若存在索引,则该索引将被列出来
- 当该列为NULL时就要考虑当前的SQL是否需要优化了
- 显示MySQL在查询中实际使用的索引,若没有使用索引,显示NULL。
- 查询中若使用了覆盖索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
- 索引长度
- 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
- 返回估算的结果集数目,并不是准确的值
- 示返回结果的行数占需读取行数的百分比, filtered 的值越大越好
- Using where:表示优化器需要通过索引回表,之后到server层进行过滤查询数据
- Using index:表示直接访问索引就足够获取到所需要的数据,不需要回表
- Using index condition:在5.6版本后加入的新特性(Index Condition Pushdown)
- Using index for group-by:使用了索引来进行GROUP BY或者DISTINCT的查询
- Using filesort:当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大
- Using temporary 临时表被使用,时常出现在GROUP BY和ORDER BY子句情况下。(sort buffer或者磁盘被使用)
possible_keys
key
key_length
ref
rows
filtered
extra
光看 filesort 字面意思,可能以为是要利用磁盘文件进行排序,实则不全然。 当MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个 数据块进行排序,然后将各个块合并成有序的结果集(实际上就是外排序)。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必 须将查询的结果集生成一个临时表,在连接完成之后行行filesort操作,此时,EXPLAIN输出“Using temporary;Using filesort”。
提高查询效率
正确使用索引
为解释方便,来一个demo:
DROP TABLE IF EXISTS user; CREATE TABLE user( id int AUTO_INCREMENT PRIMARY KEY, user_name varchar(30) NOT NULL, gender bit(1) NOT NULL DEFAULT b’1’, city varchar(50) NOT NULL, age int NOT NULL )ENGINE=InnoDB DEFAULT CHARSET=utf8; ALTER TABLE user ADD INDEX idx_user(user_name , city , age); 复制代码
什么样的索引可以被使用?
- **全匹配:**SELECT * FROM user WHERE user_name='JueJin'AND age='5' AND city='上海';(与where后查询条件的顺序无关)
- 匹配最左前缀:(user_name )、(user_name, city)、(user_name , city , age)(满足最左前缀查询条件的顺序与索引列的顺序无关,如:(city, user_name)、(age, city, user_name))
- **匹配列前缀:**SELECT * FROM user WHERE user_name LIKE 'W%'
- **匹配范围值:**SELECT * FROM user WHERE user_name BETWEEN 'W%' AND 'Z%'
什么样的索引无法被使用?
- **where查询条件中不包含索引列中的最左索引列,则无法使用到索引: **
SELECT * FROM user WHERE city='上海';
SELECT * FROM user WHERE age='26';
SELECT * FROM user WHERE age='26' AND city=‘上海';
H ** Auch wenn die Wo-Anfragen links sind, kann der Index nicht zum Abfragen des Benutzernamens bei N verwendet werden: **- SELECT*from user where user_name like '%n'
- SELECT * FROM user WHERE user_name='JueJin' AND city LIKE '上%' AND age = 31;
- SELECT * FROM user WHERE user_name= concat(user_name,'PLUS');
Wählen Sie die entsprechende Indexspaltenreihenfolge
Die Reihenfolge der Indexspalten ist bei der Erstellung eines zusammengesetzten Indexes sehr wichtig. Die richtige Indexreihenfolge hängt von der Abfragemethode ab, die den Index verwendet Die Indexreihenfolge des kombinierten Indexes kann selektiv sein. Die höchste Spalte wird an der Spitze des Indexes platziert. Diese Regel steht im Einklang mit der selektiven Methode des Präfixindexes. Dies bedeutet nicht, dass die Reihenfolge aller kombinierten Indizes damit bestimmt werden kann Regel. Der spezifische Index muss entsprechend dem spezifischen Abfrageszenario bestimmt werden.- Abgedeckte Indexbedingungen
- Wenn ein Index die Werte aller abzufragenden Felder enthält, wird er als abdeckender Index bezeichnet SELECT user_name, city, age FROM user WHERE user_name='Tony' AND age= '28' AND city='Shanghai';
Denn die abzufragenden Felder (user_name, city, age) sind alle in den Indexspalten enthalten Für den kombinierten Index wird eine abdeckende Indexabfrage verwendet, um zu überprüfen, ob ein abdeckender Index verwendet wird. Der Wert in „Extra“ im Ausführungsplan lautet „Using index“, was beweist, dass die Verwendung eines abdeckenden Indexes die Zugriffsleistung erheblich verbessern kann .
- Index zum Sortieren verwenden
ORDER BY-Klausel Die nachfolgende Spaltenreihenfolge muss mit der Spaltenreihenfolge des kombinierten Index übereinstimmen und die Sortierrichtung (Vorwärts-/Rückwärtsreihenfolge) aller Sortierspalten muss konsistent seinSortierung Verfügbare Demos:Der abgefragte Feldwert muss in der Indexspalte enthalten sein und diese erfüllen der abdeckende Index
SELECT Benutzername, Stadt, Alter FROM Benutzertest ORDER BY user_name;
- SELECT user_name, city, age FROM user_test ORDER BY user_name,city;
- SELECT user_name, city, age FROM user_test ORDER BY user_name DESC,city DESC;
- SELECT user_name, city, age FROM user_test WHERE user_name='Tony' SELECT user_name, city, age,
FROM user_test ORDER BY user_name; Stadt, Alter FROM Benutzertest ORDER NACH Benutzername
ASC- ,Stadt
- DESC ; Geben Sie keine Daten zurück, die vom Benutzerprogramm nicht benötigt werden.
- LIMIT: MySQL kann nicht die erforderliche Datenmenge zurückgeben. Das heißt, MySQL fragt immer alle Daten ab Tatsächlich wird der Druck der Netzwerkdatenübertragung verringert und die Anzahl der gelesenen Datenzeilen wird nicht verringert.
- Unnötige Spalten entfernen
Die SELECT *-Anweisung entfernt alle Felder in der Tabelle, unabhängig davon, ob die Daten im Feld für die aufrufende Anwendung nützlich sind. Dadurch werden Serverressourcen verschwendet und sogar die Serverleistung beeinträchtigt
- Wenn sich die Struktur der Tabelle in Zukunft ändert, erhält die SELECT *-Anweisung möglicherweise falsche Daten.
- Beim Ausführen der SELECT *-Anweisung müssen Sie zunächst herausfinden, welche Spalten sich in der Tabelle befinden, und dann mit der Ausführung der SELECT *-Anweisung beginnen kann in einigen Fällen zu Leistungsproblemen führen Die Verwendung der SELECT *-Anweisung deckt den Index nicht ab, was der Optimierung der Abfrageleistung nicht förderlich ist
- Die Vorteile der korrekten Verwendung des Index
- Vollständigen Tabellenscan vermeiden
- Beim Abfragen einer einzelnen Tabelle muss ein vollständiger Tabellenscan jede Zeile abfragen
- Bei der Abfrage mehrerer Tabellen muss ein vollständiger Tabellenscan mindestens jede Zeile in allen Tabellen abrufen
- Erhöhen Sie die Geschwindigkeit.
- Sie können schnell die erste Zeile der Ergebnismenge finden und Gruppierung
- Wenn abdeckende Indizes verwendet werden können Die Kosten für die Vermeidung von Zeilenschleifen
- Index
- Wenn zu viele Indizes vorhanden sind, wird die Datenänderung langsam
- InnoDB-Speicher-Engine speichert Indizes und Daten zusammen.
- Best Practices für Indexe.
- Erwägen Sie die Verwendung von Indizes für die folgenden Spalten
- WHERE-Klausel Spalten in
- Erwägen Sie die Verwendung von Präfixindizes für Zeichenfolgenspalten
- Kann schneller vergleichen und Schleifen durchführen
- Speicherplatz reduzieren I/ Wenn die O
select-Anweisung eine geringe Effizienz aufweist, sollten Sie einen vollständigen Tabellenscan vermeiden
- Versuchen Sie, den Index zu erhöhen
- where-Anweisung
Tabellenverbindungsbedingungen
- Verwenden Sie die Analysetabelle, um statistische Informationen zu sammeln
- Berücksichtigen Sie die Speicher-Engine-Schicht, um die Speicher-Engine-Schicht zu berücksichtigen. Optimierung
- Optimieren Sie die Tabellenverknüpfungsmethode
- Fügen Sie Indizes für die Spalten der ON- oder USING-Klausel hinzu.
- Verwenden Sie SELECT STRAIGHT_JOIN, um die Tabellenverbindungsreihenfolge zu erzwingen.
- Fügen Sie Indizes hinzu die Spalten von ORDER BY und GROUP BY
- join Das Beitreten ist nicht unbedingt effizienter als eine Unterabfrage
- Weitere verwandte kostenlose Lernempfehlungen:
- MySQL-Tutorial
- (Video)
Das obige ist der detaillierte Inhalt vonRelationale Datenbank MySQL drei: Beginnend mit dem Lebenszyklus einer SQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!