
Heim >Datenbank >MySQL-Tutorial >Einführung wichtiger Wissenspunkte: Der Einfügungspuffer von InnoDB
Einführung wichtiger Wissenspunkte: Der Einfügungspuffer von InnoDB

- coldplay.xixinach vorne
- 2020-10-30 17:01:522456Durchsuche
Die Spalte „MySQL-Video-Tutorial“ stellt den Einfügepuffer von InnoDB vor.
Die InnoDB-Engine verfügt über mehrere Schlüsselfunktionen, die ihr eine bessere Leistung und Zuverlässigkeit verleihen: 
Puffer einfügen
- Doppeltes Schreiben
- Adaptiver Hash-Index (Adaptiver Hash-Index)
- Asynchrones IO (Async IO)
- Aktualisieren Nachbarseite (Flush Neighbor Page)
- Heute ist unser Thema , da die zugrunde liegende Datenspeicherstruktur der InnoDB-Engine ein B+-Baum ist und wir für den Index Clustered-Indizes und Nicht-Clustered-Indizes haben.
Das Einfügen von Daten führt zwangsläufig zu Änderungen im Index. Clustered-Indizes sind im Allgemeinen in aufsteigender Reihenfolge. Ein nicht gruppierter Index verfügt nicht unbedingt über Daten. Seine diskrete Natur führt zu kontinuierlichen Änderungen in der Struktur während des Einfügens, was zu einer verringerten Einfügeleistung führt. 插入缓冲(Insert Buffer)
Wenn Sie das Bild oben sehen, denken Sie vielleicht, dass der Einfügepuffer eine Komponente des InnoDB-Pufferpools ist. 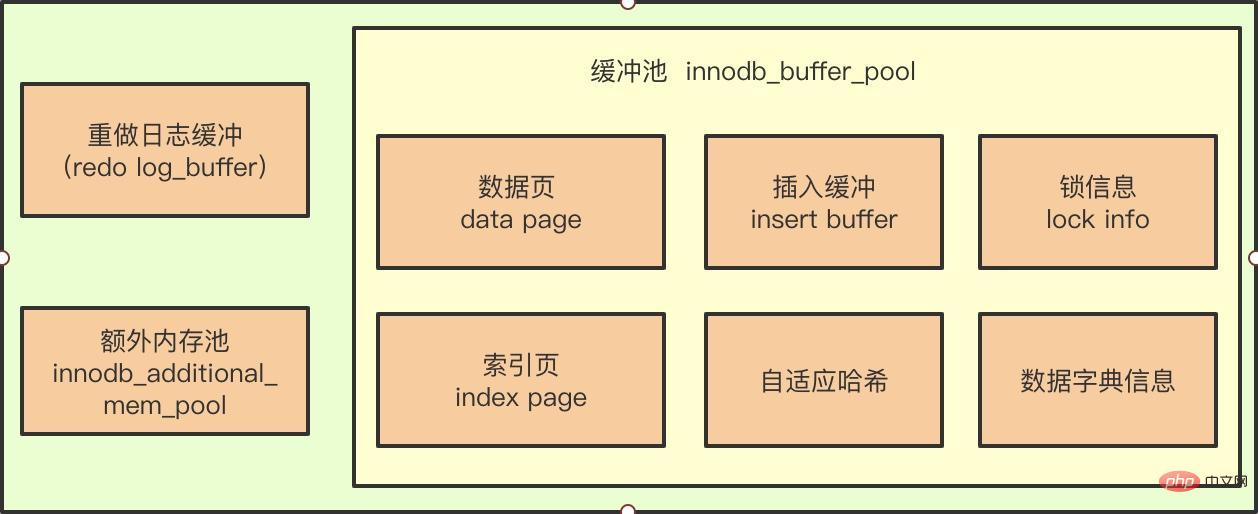
Die Rolle des Einfügepuffers
Lassen Sie uns zunächst über einige Punkte sprechen:
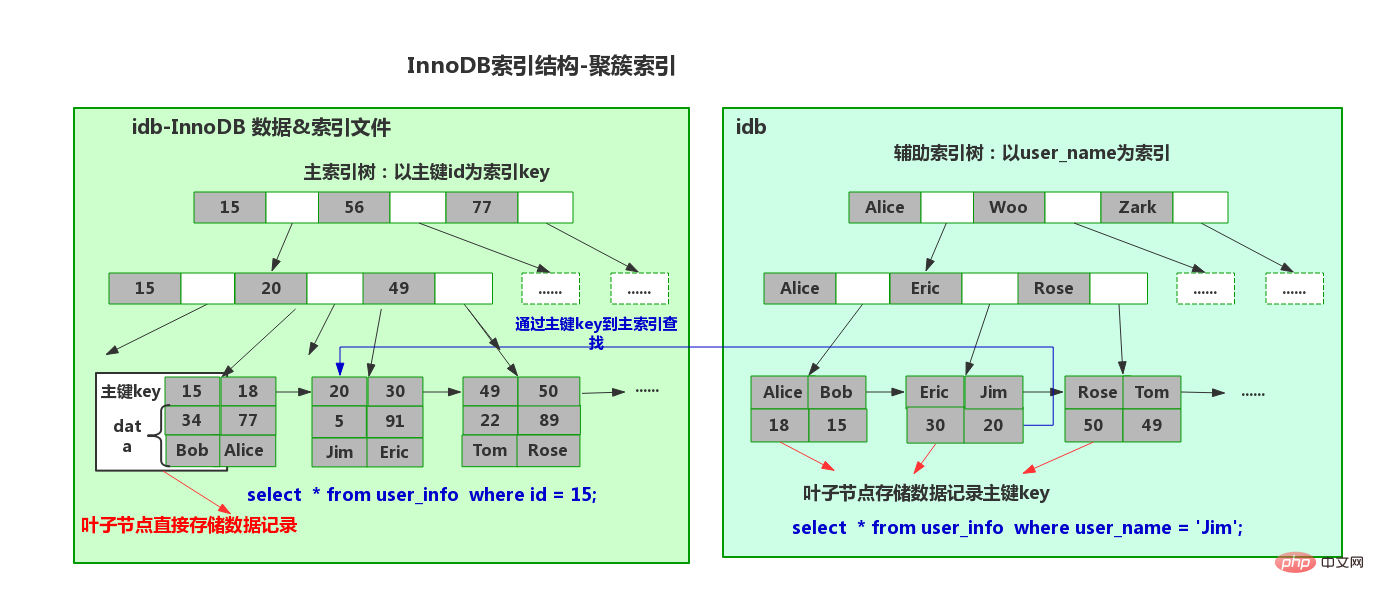
Eine Tabelle kann nur einen Primärschlüsselindex haben, da ihr physischer Speicher ein B+-Baum ist. (Vergessen Sie nicht die in den Clustered-Index-Blattknoten gespeicherten Daten. Es gibt nur eine Kopie der Daten.)- Einfügung des Clustered-Index Zuerst wissen wir, dass in der InnoDB-Speicher-Engine der Primärschlüssel die eindeutige Kennung der Zeile ist (d. h. der Clustered-Index, über den wir oft sprechen). Normalerweise fügen wir Daten inkrementell entsprechend dem Primärschlüssel ein, sodass der Clustered-Index sequentiell ist und kein zufälliges Lesen von der Festplatte erfordert.
-
Zum Beispiel Tabelle:
CREATE TABLE test( id INT AUTO_INCREMENT, name VARCHAR(30), PRIMARY KEY(id) );复制代码
Wie oben habe ich eine Primärschlüssel-ID erstellt, die die folgenden Eigenschaften aufweist:
 Die Id-Spalte erhöht sich automatisch.
Die Id-Spalte erhöht sich automatisch.
Wenn ein NULL-Wert in die Id-Spalte eingefügt wird, ist dies der Fall Der Wert erhöht sich aufgrund von AUTO_INCREMENT Gleichzeitig werden die Zeilendatensätze auf der Datenseite in der Reihenfolge entsprechend dem Wert der ID gespeichert
Im Allgemeinen besteht aufgrund der Ordnung des Clustered-Index keine Notwendigkeit, nach dem Zufallsprinzip zu arbeiten Lesen Sie die Daten auf der Seite, da diese Art der sequentiellen Einfügung sehr schnell ist. Aber wenn Sie die Spalten-ID in Daten wie UUID einfügen, erfolgt Ihre Einfügung so zufällig wie bei einem nicht gruppierten Index. Dies führt dazu, dass sich Ihre B+-Baumstruktur ständig ändert und die Leistung unweigerlich beeinträchtigt wird.- Einfügung eines nicht gruppierten Indexes
- Oft hat unsere Tabelle viele nicht gruppierte Indizes. Ich frage beispielsweise nach dem B-Feld ab, und das B-Feld ist nicht eindeutig. Wie in der folgenden Tabelle gezeigt:
CREATE TABLE test( id INT AUTO_INCREMENT, name VARCHAR(30), PRIMARY KEY(id), KEY(name) );复制代码
Der nicht gruppierte Index ist ebenfalls ein B+-Baum, aber die Blattknoten speichern den primären Schlüssel- und Namenswert des Clustered-Index.
Da es keine Garantie dafür gibt, dass die Daten in der Namensspalte sequentiell sind, darf das Einfügen des nicht gruppierten Indexbaums nicht sequentiell erfolgen. Wenn in die Namensspalte Zeittypdaten eingefügt werden, erfolgt das Einfügen des nicht gruppierten Index natürlich auch sequentiell.
Die Einführung des Einfügepuffers- Es ist ersichtlich, dass die diskrete Natur des Einfügens von nicht gruppierten Indizes zu einer Verringerung der Einfügeleistung führt. Daher hat die InnoDB-Engine den Einfügepuffer entwickelt, um die Einfügeleistung zu verbessern.
- Lassen Sie mich sehen, wie man mit dem Einfügepuffer einfügt:
Insert Buffer的使用要求:
- 索引是非聚集索引
- 索引不是唯一(unique)的
只有满足上面两个必要条件时,InnoDB存储引擎才会使用Insert Buffer来提高插入性能。
那为什么必须满足上面两个条件呢?
第一点索引是非聚集索引就不用说了,人家聚集索引本来就是顺序的也不需要你
第二点必须不是唯一(unique)的,因为在写入Insert Buffer时,数据库并不会去判断插入记录的唯一性。如果再去查找肯定又是离散读取的情况了,这样InsertBuffer就失去了意义。
Insert Buffer信息查看
我们可以使用命令SHOW ENGINE INNODB STATUS来查看Insert Buffer的信息:
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 7545, free list len 3790, seg size 11336, 8075308 inserts,7540969 merged sec, 2246304 merges ...复制代码
使用命令后,我们会看到很多信息,这里我们只看下INSERT BUFFER 的:
seg size 代表当前Insert Buffer的大小 11336*16KB
free listlen 代表了空闲列表的长度
size 代表了已经合并记录页的数量
Inserts 代表了插入的记录数
merged recs 代表了合并的插入记录数量
merges 代表合并的次数,也就是实际读取页的次数
merges:merged recs大约为1∶3,代表了Insert Buffer 将对于非聚集索引页的离散IO逻辑请求大约降低了2/3
Insert Buffer的问题
说了这么多针对于Insert Buffer的好处,但目前Insert Buffer也存在一个问题:
即在写密集的情况下,插入缓冲会占用过多的缓冲池内存(innodb_buffer_pool),默认最大可以占用到1/2的缓冲池内存。
占用了过大的缓冲池必然会对其他缓冲池操作带来影响
Insert Buffer的优化
MySQL5.5之前的版本中其实都叫做Insert Buffer,之后优化为 Change Buffer 可以看做是 Insert Buffer 的升级版。
插入缓冲( Insert Buffer)这个其实只针对 INSERT 操作做了缓冲,而Change Buffer 对INSERT、DELETE、UPDATE都进行了缓冲,所以可以统称为写缓冲,其可以分为:
Insert Buffer
Delete Buffer
Purgebuffer
总结:
Insert Buffer到底是个什么?
其实Insert Buffer的数据结构就是一棵B+树。
在MySQL 4.1之前的版本中每张表有一棵Insert Buffer B+树
目前版本是全局只有一棵Insert Buffer B+树,负责对所有的表的辅助索引进行Insert Buffer
这棵B+树存放在共享表空间ibdata1中
以下几种情况下 Insert Buffer会写入真正非聚集索引,也就是所说的Merge Insert Buffer
- 当辅助索引页被读取到缓冲池中时
- Insert Buffer Bitmap页追踪到该辅助索引页已无可用空间时
- Master Thread线程中每秒或每10秒会进行一次Merge Insert Buffer的操作
一句话概括下:
Insert Buffer 就是用于提升非聚集索引页的插入性能的,其数据结构类似于数据页的一个B+树,物理存储在共享表空间ibdata1中 。
相关免费学习推荐:mysql视频教程
Das obige ist der detaillierte Inhalt vonEinführung wichtiger Wissenspunkte: Der Einfügungspuffer von InnoDB. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!