
Heim >Datenbank >MySQL-Tutorial >Verstehen Sie die Checkpoint-Technologie von InnoDB
Verstehen Sie die Checkpoint-Technologie von InnoDB

- coldplay.xixinach vorne
- 2020-10-28 17:14:332684Durchsuche
In der Spalte „MySQL-Tutorial“ lernen Sie die Checkpoint-Technologie von InnoDB kennen.
In einem Satz: Checkpoint-Technologie ist der Vorgang, bei dem schmutzige Seiten im Cache-Pool zu einem bestimmten Zeitpunkt zurück auf die Festplatte geleert werden. Sind Probleme aufgetreten?

Wir alle wissen, dass die Entstehung des Pufferpools dazu dient, die Lücke zwischen CPU- und Festplattengeschwindigkeit zu schließen, sodass wir beim Lesen und Schreiben der Datenbank keine Festplatten-E/A-Vorgänge ausführen müssen. Beim Pufferpool werden alle Seitenvorgänge zunächst im Pufferpool abgeschlossen. Wenn beispielsweise in einer DML-Anweisung ein Datenaktualisierungs- oder Löschvorgang durchgeführt wird, wird der Datensatz auf der Pufferpoolseite geändert. Da die Daten auf der Pufferpoolseite zu diesem Zeitpunkt neuer sind als die Daten auf der Festplatte wird als Dirty Page bezeichnet.
Egal was passiert, die Speicherseitendaten müssen nach der Hauptversammlung wieder auf die Festplatte geleert werden. Hierbei gibt es mehrere Probleme:
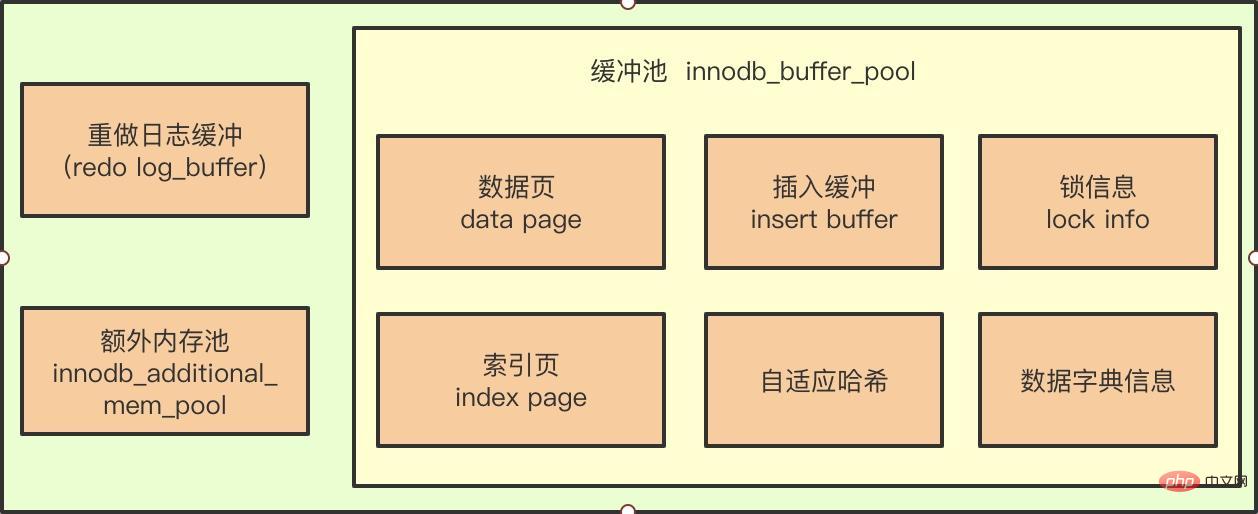 Wenn sich eine Seite ändert, wird die neue Seitenversion auf die Festplatte geleert , dann ist dieser Overhead sehr groß Die Daten können nicht wiederhergestellt werden
Wenn sich eine Seite ändert, wird die neue Seitenversion auf die Festplatte geleert , dann ist dieser Overhead sehr groß Die Daten können nicht wiederhergestellt werden
- (Redo-Log), das Ändern der Pufferpool-Datenseite, sodass das System nach einem Neustart bei einem Stromausfall weiterarbeiten kann.
- Prinzip des WAL-Richtlinienmechanismus
- InnoDB für Stellen Sie sicher, dass keine Daten verloren gehen und das Redo-Protokoll gepflegt wird. Bevor die Datenseite im Pufferpool geändert wird, muss der geänderte Inhalt im Redo-Protokoll aufgezeichnet werden und das Redo-Protokoll muss früher als die entsprechende Datenseite auf die Festplatte geleert werden.
Wenn ein Fehler auftritt und Speicherdaten verloren gehen, stellt InnoDB die Datenseiten des Pufferpools in den Zustand vor dem Absturz zurück, indem das Redo-Protokoll beim Neustart erneut abgespielt wird.
Checkpoint
Es liegt auf der Hand, dass wir uns mit der WAL-Strategie zurücklehnen und entspannen können. Das Problem tritt jedoch erneut im Redo-Log auf:
- Das Redo-Log kann nicht unendlich sein, und wir können unsere Daten nicht endlos speichern und darauf warten, gemeinsam auf der Festplatte aktualisiert zu werden.
- Wenn die Datenbank im Leerlauf ist und wiederhergestellt wird, wenn das Redo-Log vorhanden ist zu groß Wenn es groß ist, sind auch die Wiederherstellungskosten sehr hoch
Um die Aktualisierungsleistung verschmutzter Seiten zu lösen, wann und unter welchen Umständen verschmutzte Seiten aktualisiert werden sollten, wird die Checkpoint-Technologie verwendet.
Der Zweck von Checkpoint
1. Verkürzen Sie die Wiederherstellungszeit der Datenbank
Wenn die Datenbank inaktiv ist und wiederhergestellt wird, müssen nicht alle Protokollinformationen wiederholt werden. Weil die Datenseite vor Checkpoint zurück auf die Festplatte geleert wurde. Stellen Sie einfach das Redo-Log nach dem Checkpoint wieder her.
2. Wenn der Pufferpool nicht ausreicht, leeren Sie die verschmutzten Seiten auf die Festplatte.
Wenn der Pufferpoolspeicher nicht ausreicht, läuft die zuletzt verwendete Seite gemäß dem LRU-Algorithmus über Seite, dann muss ein Prüfpunkt erzwungen werden. Die fehlerhaften Seiten, bei denen es sich um neue Versionen der Seiten handelt, werden zurück auf die Festplatte geleert.
3. Wenn das Redo-Log nicht verfügbar ist, aktualisieren Sie die schmutzigen Seiten
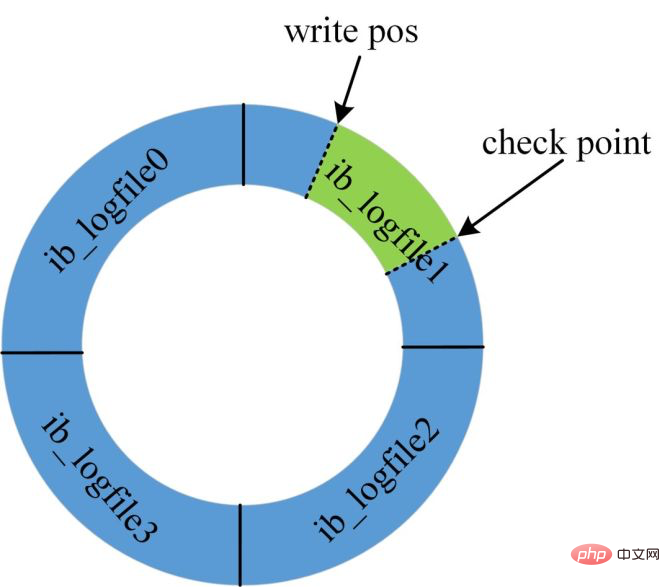
Wie in der Abbildung gezeigt, ist das Redo-Log nicht verfügbar, da die aktuelle Datenbank für die zyklische Verwendung ausgelegt ist und daher nicht unendlich viel Speicherplatz bietet .
Wenn das Redo-Protokoll voll ist, werden alle Aktualisierungsanweisungen blockiert, da das System zu diesem Zeitpunkt keine Aktualisierungen akzeptieren kann.
Zu diesem Zeitpunkt muss die Generierung eines Checkpoints erzwungen werden und die Schreibposition muss nach vorne verschoben werden. Die schmutzigen Seiten innerhalb des Fortschrittsbereichs müssen auf die Festplatte geleert werden.
Arten von Checkpoints. Die Zeit und Bedingungen dafür Das Auftreten von Checkpoints und die Auswahl schmutziger Seiten sind sehr komplex.
Checkpoint Wie viele verschmutzte Seiten werden jedes Mal auf die Festplatte geleert?
Woher bekommt Checkpoint jedes Mal schmutzige Seiten?
Wann wird Checkpoint ausgelöst?
Angesichts der oben genannten Probleme stellt uns die InnoDB-Speicher-Engine intern zwei Arten von Checkpoints zur Verfügung:
- Sharp Checkpoint
-
tritt auf, wenn die Datenbank heruntergefahren wird und alle fehlerhaften Seiten zurück auf die Festplatte geleert werden ist der Standardjob. Methode, Parameter innodb_fast_shutdown=1
Fuzzy Checkpoint -
InnoDB-Speicher-Engine verwendet diesen Modus intern und löscht nur einen Teil der schmutzigen Seiten, anstatt alle schmutzigen Seiten zurück auf die Festplatte zu leeren. Was passiert? an FuzzyCheckpoint
schreibt fast jede Sekunde oder alle zehn Sekunden einen bestimmten Anteil der Seiten aus der Liste der schmutzigen Seiten im Pufferpool zurück auf die Festplatte.
Dieser Prozess ist asynchron, das heißt, die InnoDB-Speicher-Engine kann zu diesem Zeitpunkt andere Vorgänge ausführen und der Benutzerabfrage-Thread wird nicht blockiert- FLUSH_LRU_LIST PrüfpunktDa die LRU-Liste sicherstellen muss, dass eine bestimmte Anzahl von Es können freie Seiten verwendet werden. Wenn die Seite nicht ausreicht, wird die Seite aus dem Ende entfernt. Wenn die entfernte Seite fehlerhafte Seiten enthält, wird dieser Prüfpunkt durchgeführt. Nach Version 5.6 wird dieser Checkpoint in einem separaten Page Cleaner-Thread platziert und Benutzer können die Anzahl der verfügbaren Seiten in der LRU-Liste über den Parameter innodb_lru_scan_ Depth steuern. Der Standardwert ist 1024
-
Async/Sync Flush Checkpoint
Bezieht sich auf die Situation, in der die Redo-Log-Datei nicht verfügbar ist. Zu diesem Zeitpunkt müssen die fehlerhaften Seiten aus der Liste der fehlerhaften Seiten ausgewählt werden 5.6, Benutzeranfragen werden nicht blockiert - Dirty Page too much Checkpoint Das heißt, die Anzahl der fehlerhaften Seiten ist zu groß, was dazu führt, dass die InnoDB-Speicher-Engine einen Prüfpunkt erzwingt. Der übergeordnete Zweck besteht darin, sicherzustellen, dass im Pufferpool genügend Seiten verfügbar sind. Es kann durch den Parameter innodb_max_dirty_pages_pct gesteuert werden. Der Wert beträgt beispielsweise 75, was bedeutet, dass CheckPoint gezwungen wird, Pufferpool-Datenseiten auszuführen, um die Datenbank-DML zu beschleunigen Operationen
- Aufgrund des Konsistenzproblems zwischen Pufferpool-Datenseiten und Festplattendaten erscheint die WAL-Strategie (der Kern ist das Redo-Log). Technologie InnoDB Um die Ausführungseffizienz zu verbessern, interagiert nicht jeder DML-Vorgang mit der Festplatte. Schreiben Sie stattdessen zuerst das Redo-Protokoll über Write Ahead Log, um die Persistenz der Dinge sicherzustellen. Für in Transaktionen geänderte Dirty-Puffer-Pool-Seiten wird die Festplatte asynchron geleert und die Verfügbarkeit freier Speicherseiten und Redo-Logs wird durch die Checkpoint-Technologie garantiert.
MySQL-Tutorial
- (Video)
Das obige ist der detaillierte Inhalt vonVerstehen Sie die Checkpoint-Technologie von InnoDB. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!