
Heim >Backend-Entwicklung >Python-Tutorial >Analyse des Python-Garbage-Collection-Mechanismus
Analyse des Python-Garbage-Collection-Mechanismus

- coldplay.xixinach vorne
- 2020-10-29 17:23:452311Durchsuche
In der Kolumne „Python-Tutorial“ wird heute der Python-Garbage-Collection-Mechanismus analysiert!
1. Garbage Collection 
Hauptsächlich basierend auf Referenzzählern, ergänzt durch Code-Recycling und Markierungsentfernung
1.1 Big Butler Refchain
Im Python-C-Quellcode gibt es eine zirkuläre doppelt verknüpfte Liste namens Refchain. Diese verknüpfte Liste ist ziemlich beeindruckend, denn sobald ein Objekt in einem Python-Programm erstellt wird, wird das Objekt zur verknüpften Refchain-Liste hinzugefügt. Mit anderen Worten: Er speichert alle Objekte. 1.2 ReferenzzählerIn allen Objekten in der Refchain gibt es einen ob_refcnt, der verwendet wird, um den Referenzzähler des aktuellen Objekts zu speichern, die Anzahl der Referenzen.
- Wenn ein Wert mehrmals referenziert wird, werden die Daten nicht wiederholt im Speicher erstellt, aber der Referenzzähler beträgt +1. Wenn das Objekt zerstört wird, ist der Referenzzähler -1. Wenn der Referenzzähler 0 ist, wird das Objekt aus der Refchain-Liste entfernt und im Speicher zerstört (ohne Berücksichtigung besonderer Umstände wie Caching).
age = 18number = age # 对象18的引用计数器 + 1del age # 对象18的引用计数器 - 1def run(arg): print(arg) run(number) # 刚开始执行函数时,对象18引用计数器 + 1,当函数执行完毕之后,对象18引用计数器 - 1 。num_list = [11,22,number] # 对象18的引用计数器 + 1复制代码
v1 = [11,22,33] # refchain中创建一个列表对象,由于v1=对象,所以列表引对象用计数器为1.v2 = [44,55,66] # refchain中再创建一个列表对象,因v2=对象,所以列表对象引用计数器为1.v1.append(v2) # 把v2追加到v1中,则v2对应的[44,55,66]对象的引用计数器加1,最终为2.v2.append(v1) # 把v1追加到v1中,则v1对应的[11,22,33]对象的引用计数器加1,最终为2.del v1 # 引用计数器-1del v2 # 引用计数器-1复制代码
Für den obigen Code werden Sie feststellen, dass nach dem Ausführen der Löschoperation keine Variablen diese beiden Listenobjekte erneut verwenden. Aufgrund des Zirkelverweisproblems sind ihre Referenzzähler jedoch nicht 0, sodass ihr Status niemals verwendet oder zerstört wird . . Wenn das Projekt zu viele solcher Codes enthält, wird Speicher verbraucht, bis der Speicher erschöpft ist und das Programm abstürzt.
- Um das Problem der Zirkelverweise zu lösen, wurde die Markierungslöschungstechnologie eingeführt, um eine spezielle Verarbeitung für Objekte durchzuführen, die Zirkelverweise haben können. Zu den Typen, die Zirkelverweise haben können, gehören: Listen, Tupel, Wörterbücher, Mengen, benutzerdefinierte Klassen usw . Ein Typ, der Daten verschachteln kann.
- Mark Clear
Generationsrecycling
: Optimieren Sie die verknüpfte Liste beim Markieren und teilen Sie die Objekte, die möglicherweise Zirkelverweise haben, in 3 verknüpfte Listen auf. Die verknüpften Listen heißen: 0/1/2 drei Generationen. Jede Generation kann Objekte und Schwellenwerte speichern. Wenn der Schwellenwert erreicht ist, wird jedes Objekt in der entsprechenden verknüpften Liste gescannt, mit Ausnahme von Zirkelverweisen, jedes wird um 1 dekrementiert und Objekte mit einem Referenzzähler von 0 werden zerstört.// 分代的C源码#define NUM_GENERATIONS 3struct gc_generation generations[NUM_GENERATIONS] = { /* PyGC_Head, threshold, count */
{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代
{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代
{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代};复制代码
Besonderer Hinweis: Schwellenwert und Anzahl haben in Generation 0 und Generation 1 und 2 unterschiedliche Bedeutungen. Generation 0, Anzahl stellt die Anzahl der Objekte in der verknüpften Liste der Generation 0 dar, Schwellenwert stellt den Schwellenwert für die Anzahl der Objekte in der verknüpften Liste der Generation 0 dar. Wenn dieser überschritten wird, wird eine Scanprüfung der Generation 0 durchgeführt.
Generation 1, count stellt die Anzahl der Scans für verknüpfte Listen der Generation 0 dar, und der Schwellenwert stellt den Schwellenwert für die Anzahl der Scans für verknüpfte Listen der Generation 0 dar. Wenn der Schwellenwert überschritten wird, wird eine Scanprüfung der Generation 1 durchgeführt.
Generation 2, count stellt die Anzahl der Scans der verknüpften Liste der 1. Generation dar, und der Schwellenwert stellt den Schwellenwert der Anzahl der Scans der verknüpften Liste der 1. Generation dar. Wenn der Schwellenwert überschritten wird, wird eine Scanprüfung der 2. Generation durchgeführt. 1.4 SzenariosimulationErklären Sie den detaillierten Prozess der Speicherverwaltung und Speicherbereinigung basierend auf der untersten Ebene der C-Sprache und kombiniert mit Diagrammen. Schritt 1: Wenn das Objekt age=19 erstellt wird, wird das Objekt zur Refchain-Liste hinzugefügt.
Schritt 2: Wenn das Objekt num_list = [11,22] erstellt wird, wird das Listenobjekt zur Refchain hinzugefügt und erzeugt 0. 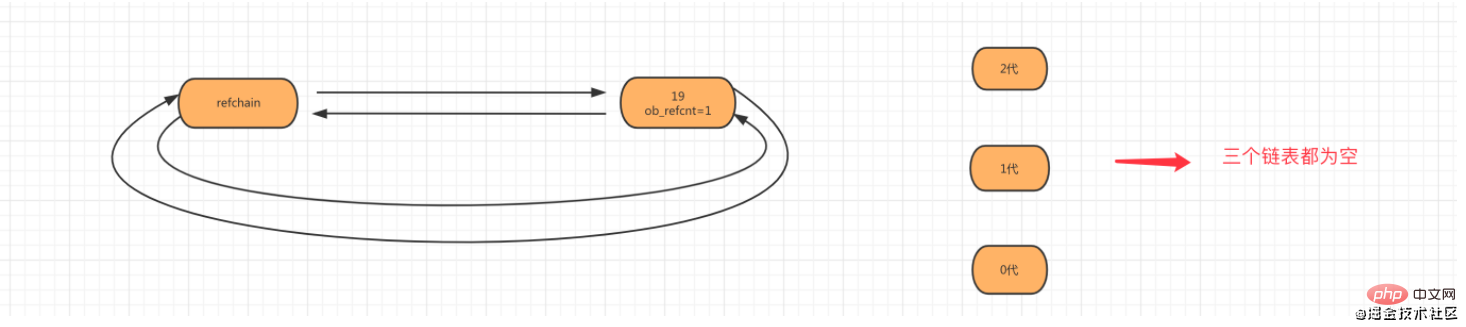
Schritt 3: Wenn neu erstellte Objekte dazu führen, dass die Anzahl der Objekte in der verknüpften Generationsliste der Generation 0 den Schwellenwert von 700 überschreitet, scannen und überprüfen Sie die Objekte in der verknüpften Liste. 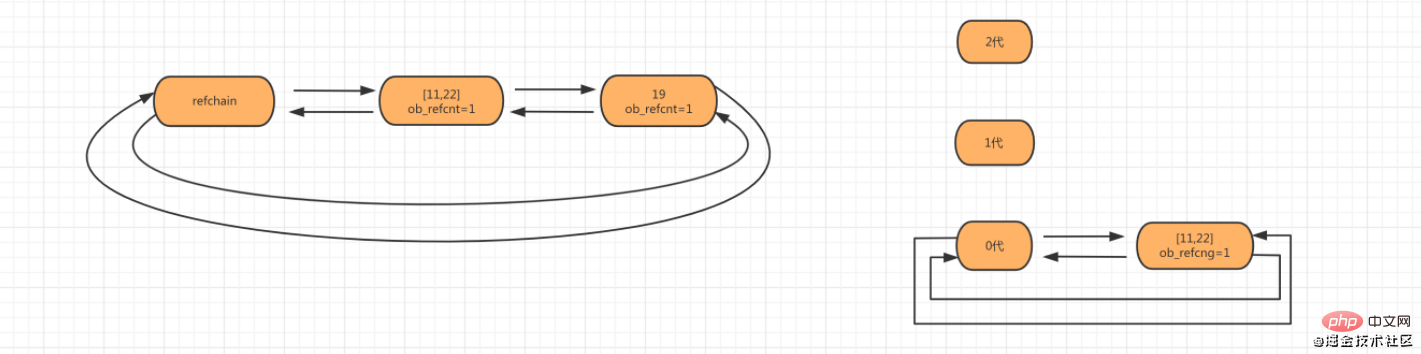
Wenn die Generationen 2 und 1 den Schwellenwert nicht erreichen, scannen Sie Generation 0 und lassen Sie die Generation 1 + 1 zählen.
- Wenn die 2. Generation den Schwellenwert erreicht hat, verketten Sie die drei verknüpften Listen von 2, 1 und 0 für einen vollständigen Scan und setzen Sie die Anzahl von 2, 1 und 0 auf 0 zurück.
- Wenn die 1. Generation den Schwellenwert erreicht hat Wenn der Schwellenwert erreicht ist, sprechen wir über die Verkettung zweier verknüpfter Listen 1 und 0 zum Scannen und setzen die Anzahl aller Generationen 1 und 0 auf 0 zurück Referenzen und Müll zerstören
- 扫描链表,把每个对象的引用计数器拷贝一份并保存到 gc_refs中,保护原引用计数器。
- 再次扫描链表中的每个对象,并检查是否存在循环引用,如果存在则让各自的gc_refs减 1 。
- 再次扫描链表,将 gc_refs 为 0 的对象移动到unreachable链表中;不为0的对象直接升级到下一代链表中。
- 处理unreachable链表中的对象的 析构函数 和 弱引用,不能被销毁的对象升级到下一代链表,能销毁的保留在此链表。析构函数,指的就是那些定义了__del__方法的对象,需要执行之后再进行销毁处理。
- 最后将 unreachable 中的每个对象销毁并在refchain链表中移除(不考虑缓存机制)。
至此,垃圾回收的过程结束。
1.5 缓存机制
从上文大家可以了解到当对象的引用计数器为0时,就会被销毁并释放内存。而实际上他不是这么的简单粗暴,因为反复的创建和销毁会使程序的执行效率变低。Python中引入了“缓存机制”机制。
例如:引用计数器为0时,不会真正销毁对象,而是将他放到一个名为 free_list 的链表中,之后会再创建对象时不会在重新开辟内存,而是在free_list中将之前的对象来并重置内部的值来使用。
- float类型,维护的free_list链表最多可缓存100个float对象。
v1 = 3.14 # 开辟内存来存储float对象,并将对象添加到refchain链表。 print( id(v1) ) # 内存地址:4436033488 del v1 # 引用计数器-1,如果为0则在rechain链表中移除,不销毁对象,而是将对象添加到float的free_list. v2 = 9.999 # 优先去free_list中获取对象,并重置为9.999,如果free_list为空才重新开辟内存。 print( id(v2) ) # 内存地址:4436033488 # 注意:引用计数器为0时,会先判断free_list中缓存个数是否满了,未满则将对象缓存,已满则直接将对象销毁。复制代码
- int类型,不是基于free_list,而是维护一个small_ints链表保存常见数据(小数据池),小数据池范围:-5 <= value < 257。即:重复使用这个范围的整数时,不会重新开辟内存。
v1 = 38 # 去小数据池small_ints中获取38整数对象,将对象添加到refchain并让引用计数器+1。 print( id(v1)) #内存地址:4514343712 v2 = 38 # 去小数据池small_ints中获取38整数对象,将refchain中的对象的引用计数器+1。 print( id(v2) ) #内存地址:4514343712 # 注意:在解释器启动时候-5~256就已经被加入到small_ints链表中且引用计数器初始化为1, # 代码中使用的值时直接去small_ints中拿来用并将引用计数器+1即可。另外,small_ints中的数据引用计数器永远不会为0 # (初始化时就设置为1了),所以也不会被销毁。复制代码
- str类型,维护unicode_latin1[256]链表,内部将所有的ascii字符缓存起来,以后使用时就不再反复创建。
v1 = "A" print( id(v1) ) # 输出:4517720496 del v1 v2 = "A" print( id(v1) ) # 输出:4517720496 # 除此之外,Python内部还对字符串做了驻留机制,针对只含有字母、数字、下划线的字符串(见源码Objects/codeobject.c),如果 # 内存中已存在则不会重新在创建而是使用原来的地址里(不会像free_list那样一直在内存存活,只有内存中有才能被重复利用)。 v1 = "asdfg" v2 = "asdfg" print(id(v1) == id(v2)) # 输出:True复制代码
list类型,维护的free_list数组最多可缓存80个list对象。
v1 = [11,22,33] print( id(v1) ) # 输出:4517628816del v1 v2 = ["你","好"] print( id(v2) ) # 输出:4517628816复制代码
- tuple类型,维护一个free_list数组且数组容量20,数组中元素可以是链表且每个链表最多可以容纳2000个元组对象。元组的free_list数组在存储数据时,是按照元组可以容纳的个数为索引找到free_list数组中对应的链表,并添加到链表中。
v1 = (1,2)
print( id(v1) )del v1 # 因元组的数量为2,所以会把这个对象缓存到free_list[2]的链表中。v2 = ("哈哈哈","Alex") # 不会重新开辟内存,而是去free_list[2]对应的链表中拿到一个对象来使用。print( id(v2) )复制代码
- dict类型,维护的free_list数组最多可缓存80个dict对象
v1 = {"k1":123}
print( id(v1) ) # 输出:4515998128
del v1
v2 = {"name":"哈哈哈","age":18,"gender":"男"}
print( id(v1) ) # 输出:4515998128复制代码
C语言源码底层分析
相关免费学习推荐:python教程(视频)
Das obige ist der detaillierte Inhalt vonAnalyse des Python-Garbage-Collection-Mechanismus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Besprechen Sie den Garbage-Collection-Mechanismus von PHP
- Detaillierte Erläuterung des Tutorials zur automatischen Garbage Collection in Java
- Eine kurze Analyse des Heap- und Garbage-Collection-Mechanismus
- Detaillierte Erläuterung des PHP7-Garbage-Collection-Mechanismus (mit vollständigem Flussdiagramm der GC-Verarbeitung)
- Verstehen Sie den Garbage-Collection-Mechanismus, Speicherlecks und Schließungen der JS-Serie (3) mit einem Blatt Papier