
Heim >Datenbank >MySQL-Tutorial >Unfall mit langsamer Online-Abfrage durch falsche Indexauswahl in MySQL verursacht
Unfall mit langsamer Online-Abfrage durch falsche Indexauswahl in MySQL verursacht

- coldplay.xixinach vorne
- 2020-10-19 17:24:192560Durchsuche
MySQL-Video-Tutorial Die Kolumne stellt Ihnen den Unfall mit langsamen Online-Abfragen vor, der durch eine falsche Indexauswahl in MySQL verursacht wird

Vorwort
Wir sehen uns wieder! Wieder sind zwei Wochen vergangen und ich habe noch ein paar halbgeschriebene Artikelentwürfe in meinen Cloud-Notizen. Einige sind bereit, weitere Inhalte hinzuzufügen, weil die Qualität nicht den Erwartungen entspricht, während andere nur eine Inspiration sind und überhaupt keinen Inhalt haben. Ich beneide viele große Leute, die fünf oder sechs Artikel pro Woche produzieren können. Selbst wenn sie mir zwei Lebern geben, reicht das nicht. Okay, kein Unsinn mehr ...
Kürzlich bin ich auf einen Datenbankfehler gestoßen, der durch eine langsame SQL-Abfrage in der Online-Umgebung verursacht wurde und sich auf das Online-Geschäft ausgewirkt hat. Nach einer Untersuchung wurde festgestellt, dass der Grund darin lag, dass der MySQL-Optimierer bei der Ausführung von SQL den falschen Index ausgewählt hatte (dies sollte nicht als „Fehler“ bezeichnet werden, sondern ein Index ausgewählt werden, dessen Ausführung tatsächlich länger dauerte). Während des Untersuchungsprozesses habe ich viele Informationen konsultiert und die grundlegenden Richtlinien für die Indexauswahl durch den MySQL-Optimierer kennengelernt. In diesem Artikel teile ich Ideen zur Lösung des Problems. Mein Verständnis von MySQL ist begrenzt. Wenn ich Fehler mache, freue ich mich über rationale Diskussionen und Korrekturen.
Bei diesem Unfall können wir auch voll und ganz erkennen, wie wichtig ein tiefes Verständnis der Funktionsprinzipien von MySQL ist. Dies ist der Schlüssel, um Probleme unabhängig lösen zu können.Stellen Sie sich vor, dass in einer dunklen und stürmischen Nacht die Online-Leitung des Unternehmens plötzlich ausfällt und Ihre Kollegen nicht online sind. Zu diesem Zeitpunkt sind Sie der Einzige, der das Problem lösen kann Fähigkeiten eines Ingenieurs, fragen Sie einfach: Ist es Ihnen peinlich? Text
FehlerbeschreibungAm 24. Juli um 11 Uhr empfing eine bestimmte Datenbank plötzlich eine große Anzahl von Alarmen online. Die Anzahl der langsamen Abfragen überstieg den Standard und verursachte einen plötzlichen Anstieg der Anzahl der Verbindungen Die Datenbank reagierte langsam und beeinträchtigte das Geschäft. Betrachtet man das Diagramm, erreichten langsame Abfragen in der Spitze 14.000 Mal pro Minute. Unter normalen Umständen liegt die Anzahl langsamer Abfragen nur unter zwei Ziffern, wie unten gezeigt:
- Überprüfen Sie schnell die langsamen SQL-Datensätze und stellen Sie fest, dass sie vorhanden sind werden alle durch die gleiche Art von Anweisungen verursacht (private Daten wie Tabellennamen, ich habe sie ausgeblendet):
select * from sample_table where 1 = 1 and (city_id = 565) and (type = 13) order by id desc limit 0, 1复制代码
Es scheint, dass die Anweisung sehr einfach ist, nichts Besonderes. Aber die Abfragezeit für jede Ausführung erreichte erstaunliche 44 Sekunden. - Es ist einfach sensationell, das kann man nicht mehr als „langsam“ bezeichnen...
Sie können sehen, dass das Tabellendatenvolumen beträgt groß und die geschätzten Zeilen Die Zahl beträgt 83683240, was etwa 80 Millionen entspricht,
eine Tabelle mit zig Millionen Daten. 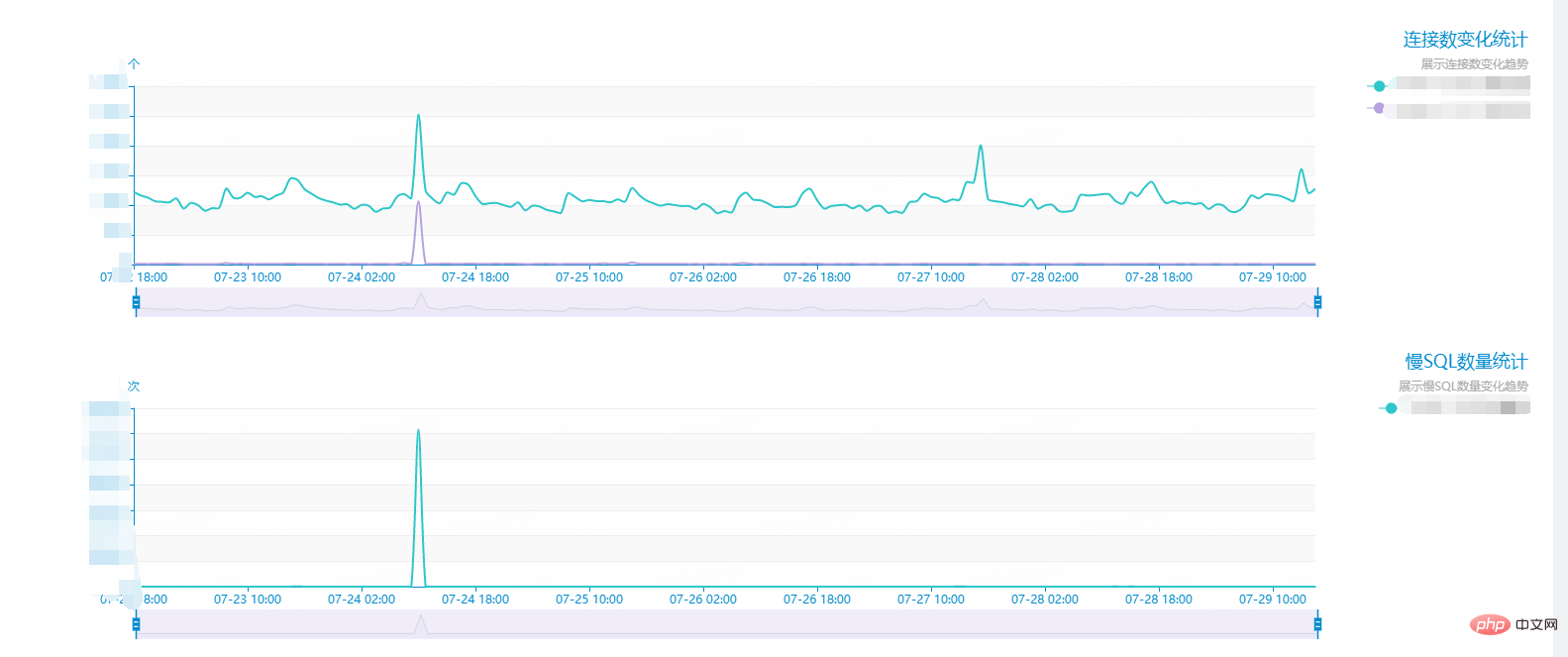
KEY `idx_1` (`city_id`,`type`,`rank`), KEY `idx_log_dt_city_id_rank` (`log_dt`,`city_id`,`rank`), KEY `idx_city_id_type` (`city_id`,`type`)复制代码
 Bitte ignorieren Sie die Duplikate der beiden Indizes idx_1 und idx_city_id_type , das sind alles Überbleibsel der Geschichte. Sie können sehen, dass es die Indizes idx_city_id_type und idx_1 gibt
Bitte ignorieren Sie die Duplikate der beiden Indizes idx_1 und idx_city_id_type , das sind alles Überbleibsel der Geschichte. Sie können sehen, dass es die Indizes idx_city_id_type und idx_1 gibtUnsere Abfragebedingungen sind city_id und type, und beide Indizes können erreicht werden.
Aber müssen unsere Abfragebedingungen wirklich nur city_id und type berücksichtigen? (Kluge Freunde sollten das Problem bemerkt haben. Machen wir weiter und überlassen es jedem, darüber nachzudenken.) 
Die wichtigeren Felder von Explain sind:
select_type: Abfragetyp, einschließlich einfacher Abfrage, gemeinsamer Abfrage, Unterabfrage usw.
key: verwendeter Index
rows: geschätzte Anzahl der zu scannenden Zeilen
Weitere Details für Eine Einführung in Explain finden Sie unter: MySQL-Leistungsoptimierungsartefakt. Explain-Nutzungsanalyse Am Ende wurde der Primärschlüsselindex verwendet. Die Tabelle ist mehrere zehn Millionen groß und die Abfragebedingung gibt am Ende tatsächlich leere Daten zurück. Das heißt, MySQL braucht tatsächlich viel Zeit, um den Primärschlüsselindex abzurufen, was zu einer langsamen Abfrage führt.Wir können Force Index (idx_city_id_type) verwenden, um die Anweisung den von uns festgelegten gemeinsamen Index auswählen zu lassen:
select * from sample_table where city_id = 565 and type = 13 order by id desc limit 0,1复制代码Dieses Mal wird es offensichtlich sehr schnell ausgeführt. Analysieren Sie die Anweisung:

实际执行时间0.00175714s,走了联合索引后,不再是慢查询了。
问题找到了,总结下来就是:MySQL优化器认为在limit 1的情况下,走主键索引能够更快的找到那一条数据,并且如果走联合索引需要扫描索引后进行排序,而主键索引天生有序,所以优化器综合考虑,走了主键索引。实际上,MySQL遍历了8000w条数据也没找到那个天选之人(符合条件的数据),所以浪费了很多时间。
MySQL索引选择原理
优化器索引选择的准则
MySQL一条语句的执行流程大致如下图,而查询优化器则是选择索引的地方:
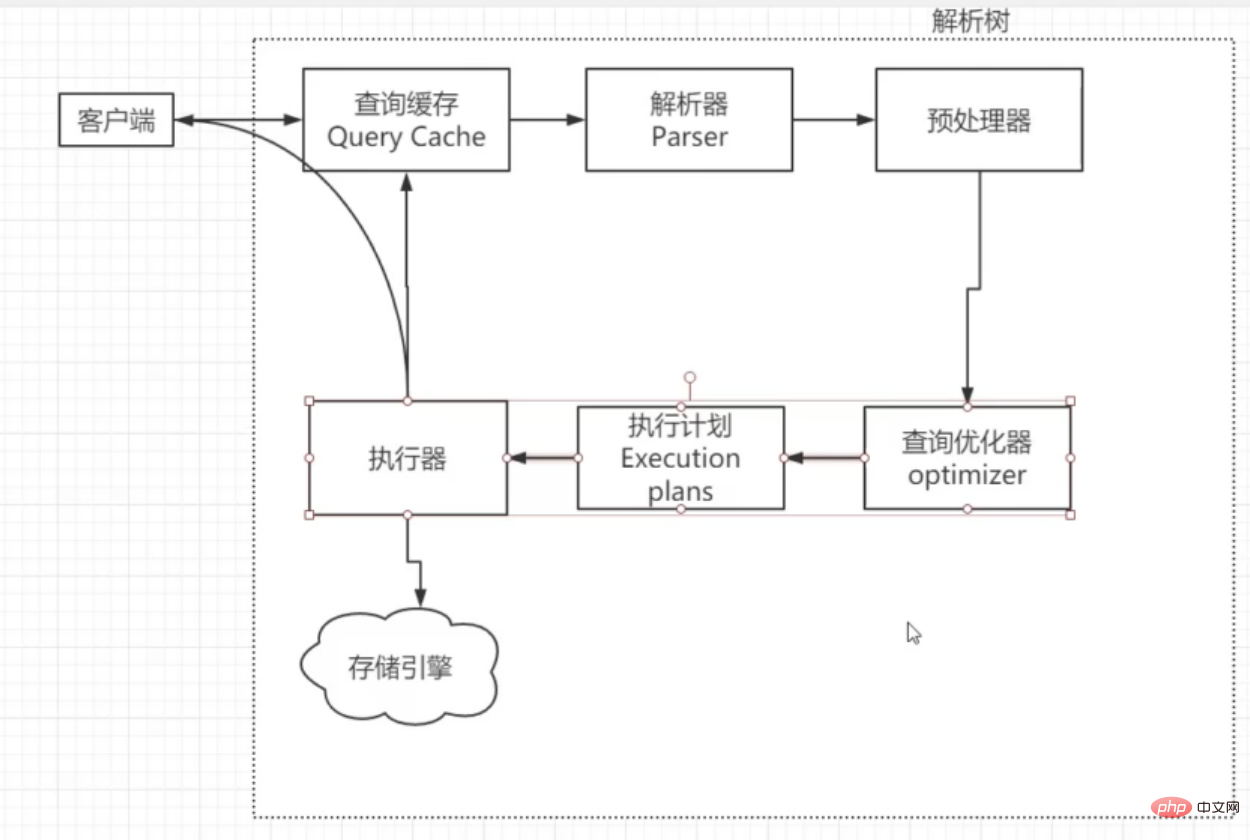
引用参考文献一段解释:
首先要知道,选择索引是MySQL优化器的工作。
而优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的CPU资源越少。
当然,扫描行数并不是唯一的判断标准,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。
总结下来,优化器选择有许多考虑的因素:扫描行数、是否使用临时表、是否排序等等
我们回头看刚才的两个explain截图:


走了主键索引的查询语句,rows预估行数1833,而强制走联合索引行数是45640,并且Extra信息中,显示需要Using filesort进行额外的排序。所以在不加强制索引的情况下,优化器选择了主键索引,因为它觉得主键索引扫描行数少,而且不需要额外的排序操作,主键索引天生有序。
rows是怎么预估出来的
同学们就要问了,为什么rows只有1833,明明实际扫描了整个主键索引啊,行数远远不止几千行。实际上explain的rows是MySQL预估的行数,是根据查询条件、索引和limit综合考虑出来的预估行数。
MySQL是怎样得到索引的基数的呢?这里,我给你简单介绍一下MySQL采样统计的方法。 为什么要采样统计呢?因为把整张表取出来一行行统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。 采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。 而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。 在MySQL中,有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent的值来选择: 设置为on的时候,表示统计信息会持久化存储。这时,默认的N是20,M是10。 设置为off的时候,表示统计信息只存储在内存中。这时,默认的N是8,M是16。 由于是采样统计,所以不管N是20还是8,这个基数都是很容易不准的。复制代码
我们可以使用analyze table t 命令,可以用来重新统计索引信息。但是这条命令生产环境需要联系DBA,所以我就不做实验了,大家可以自行实验。
索引要考虑 order by 的字段
为什么这么说?因为如果我这个表中的索引是city_id,type和id的联合索引,那优化器就会走这个联合索引,因为索引已经做好了排序。
更改limit大小能解决问题?
把limit数量调大会影响预估行数rows,进而影响优化器索引的选择吗?
答案是会。
我们执行limit 10
select * from sample_table where city_id = 565 and type = 13 order by id desc limit 0,10复制代码

图中rows变为了18211,增长了10倍。如果使用limit 100,会发生什么?

优化器选择了联合索引。初步估计是rows还会翻倍,所以优化器放弃了主键索引。宁愿用联合索引后排序,也不愿意用主键索引了。
为何突然出现异常慢查询
问:这个查询语句已经在线上稳定运行了非常长的时间,为何这次突然出现了慢查询?
答:以前的语句查询条件返回结果都不为空,limit1很快就能找到那条数据,返回结果。而这次代码中查询条件实际结果为空,导致了扫描了全部的主键索引。
解决方案
知道了MySQL为何选择这个索引的原因后,我们就可以根据上面的思路来列举出解决办法了。
主要有两个大方向:
- 强制指定索引
- 干涉优化器选择
强制选择索引:force index
就像上面我最开始的操作那样,我们直接使用force index,让语句走我们想要走的索引。
select * from sample_table force index(idx_city_id_type) where ( ( (1 = 1) and (city_id = 565) ) and (type = 13) ) order by id desc limit 0, 1复制代码
这样做的优点是见效快,问题马上就能解决。
缺点也很明显:
- 高耦合,这种语句写在代码里,会变得难以维护,如果索引名变化了,或者没有这个索引了,代码就要反复修改。属于硬编码。
- 很多代码用框架封装了SQL,
force index()并不容易加进去。
我们换一种办法,我们去引导优化器选择联合索引。
干涉优化器选择:增大limit
通过增大limit,我们可以让预估扫描行数快速增加,比如改成下面的limit 0, 1000
SELECT * FROM sample_table where city_id = 565 and type = 13 order by id desc LIMIT 0,1000复制代码
这样就会走上联合索引,然后排序,但是这样强行增长limit,其实总有种面向黑盒调参的感觉。我们还有更优美的解决方案吗?
干涉优化器选择:增加包含order by id字段的联合索引
我们这句慢查询使用的是order by id,但是我们却没有在联合索引中加入id字段,导致了优化器认为联合索引后还要排序,干脆就不太想走这个联合索引了。
我们可以新建city_id,type和id的联合索引,来解决这个问题。
这样也有一定的弊端,比如我这个表到了8000w数据,建立索引非常耗时,而且通常索引就有3.4个g,如果无限制的用索引解决问题,可能会带来新的问题。表中的索引不宜过多。
干涉优化器选择:写成子查询
还有什么办法?我们可以用子查询,在子查询里先走city_id和type的联合索引,得到结果集后在limit1选出第一条。
但是子查询使用有风险,一版DBA也不建议使用子查询,会建议大家在代码逻辑中完成复杂的查询。当然我们这句并不复杂啦~
Select * From sample_table Where id in (Select id From `newhome_db`.`af_hot_price_region` where (city_id = 565 and type = 13)) limit 0, 1复制代码
还有很多解决办法...
SQL优化是个很大的工程,我们还有非常多的办法能够解决这句慢查询问题,这里就不一一展开了。留给大家做为思考题了。
总结
本文带大家回顾了一次MySQL优化器选错索引导致的线上慢查询事故,可以看出MySQL优化器对于索引的选择并不单单依靠某一个标准,而是一个综合选择的结果。我自己也对这方面了解不深入,还需要多多学习,争取能够好好的做一个索引选择的总结(挖坑)。不说了,拿起巨厚的《高性能MySQL》,开始...
压住我的泡面...
最后做个文章总结:
- 该慢查询语句中使用order by id导致优化器在主键索引和city_id和type的联合索引中有所取舍,最终导致选择了更慢的索引。
- 可以通过强制指定索引,建立包含id的联合索引,增大limit等方式解决问题。
- 平时开发时,尤其是对于特大数据量的表,要注意SQL语句的规范和索引的建立,避免事故的发生。
相关免费学习推荐:mysql视频教程
Das obige ist der detaillierte Inhalt vonUnfall mit langsamer Online-Abfrage durch falsche Indexauswahl in MySQL verursacht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!