
Heim >Datenbank >MySQL-Tutorial >Eisensaft, MySQL-Indexoptimierungsregeln werden Ihnen gegeben! !
Eisensaft, MySQL-Indexoptimierungsregeln werden Ihnen gegeben! !

- coldplay.xixinach vorne
- 2020-10-13 14:06:252515Durchsuche
Die heutige Kolumne „MySQL-Tutorial“ führt Sie in die Indexoptimierungsregeln von MySQL ein.
 Vorwort
Vorwort
- In diesem Artikel werden verschiedene Prinzipien der Indexoptimierung im Detail beschrieben. Solange Sie sie jederzeit in Ihrer Arbeit anwenden können, bin ich der Meinung, dass die SQL, die Sie schreiben, die effizienteste und beeindruckendste sein muss.
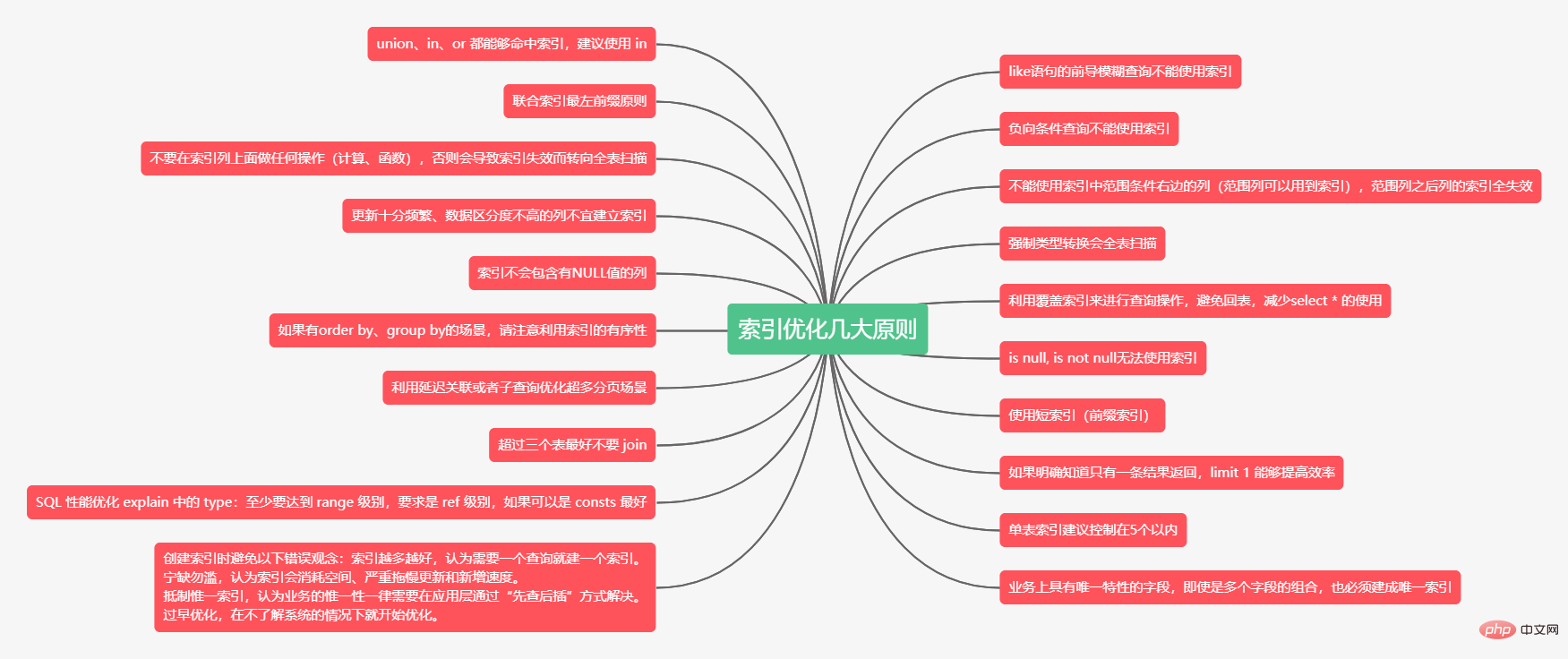
- Die Mindmap des Artikels lautet wie folgt:
 Indexoptimierungsregeln
Indexoptimierungsregeln
1. Die führende Fuzzy-Abfrage der Like-Anweisung kann den Index nicht verwenden
select * from doc where title like '%XX'; --不能使用索引select * from doc where title like 'XX%'; --非前导模糊查询,可以使用索引复制代码Da die Seitensuche strikt verbietet, links Fuzzy oder vollständig zu verwenden, Bei Bedarf können Sie eine Suchmaschine verwenden, um das Problem zu lösen.
- 2, Union, in oder können alle auf den Index zugreifen. Es wird empfohlen, in zu verwenden
union kann auf den Index zugreifen, und MySQL verbraucht am wenigsten CPU. select * from doc where status=1union allselect * from doc where status=2;复制代码
-
inkann den Index treffen, die Abfrageoptimierung verbraucht mehr CPU alsunion all, kann aber ignoriert werden, Generell empfiehlt sich in diesem Fall die Verwendung vonin.union能够命中索引,并且MySQL 耗费的 CPU 最少。
select * from doc where status in (1, 2);复制代码
-
in能够命中索引,查询优化耗费的 CPU 比union all多,但可以忽略不计,一般情况下建议使用in。
select * from doc where status = 1 or status = 2复制代码
-
or新版的 MySQL 能够命中索引,查询优化耗费的 CPU 比in多,不建议频繁用or。
select * from doc where status != 1 and status != 2;复制代码
-
补充:有些地方说在
where条件中使用or,索引会失效,造成全表扫描,这是个误区:
①要求
where子句使用的所有字段,都必须建立索引;②如果数据量太少,mysql制定执行计划时发现全表扫描比索引查找更快,所以会不使用索引;
③确保mysql版本
5.0以上,且查询优化器开启了index_merge_union=on, 也就是变量optimizer_switch里存在index_merge_union且为on。
3、负向条件查询不能使用索引
负向条件有:
!=、、not in、not exists、not like等。例如下面SQL语句:
select * from doc where status in (0,3,4);复制代码
- 可以优化为 in 查询:
select uid, login_time from user where login_name=? andpasswd=?复制代码
4、联合索引最左前缀原则
-
如果在
(a,b,c)三个字段上建立联合索引,那么他会自动建立a|(a,b)|(a,b,c)select uid, login_time from user where passwd=? andlogin_name=?复制代码
oderDie Abfrageoptimierung verbraucht möglicherweise mehr CPU alsinwird nicht empfohlen.
select * from employees.titles where emp_no <ol start="4"><li> <p>Ergänzung</p>: An einigen Stellen heißt es, dass der Index lautet, wenn <code>oder</code> in der <code>where</code>-Bedingung verwendet wird Beim Scannen wird die gesamte Tabelle beschädigt. 🎜</li></ol>🎜🎜🎜① erfordert, dass alle in der <code>where</code>-Klausel verwendeten Felder indiziert werden. 🎜🎜🎜🎜② Wenn Die Datenmenge ist zu gering, MySQL wird implementiert. Bei der Planung wurde festgestellt, dass ein vollständiger Tabellenscan schneller ist als eine Indexsuche, sodass der Index nicht verwendet wird. 🎜🎜🎜🎜③ Stellen Sie sicher, dass die MySQL-Version vorhanden ist <code>5.0</code> oder höher und der Abfrageoptimierer ist <code>index_merge_union=on code> aktiviert, d. h. es gibt <code>index_merge_union</code> in der Variablen <code>optimizer_switch und ist <code>on</code>. 🎜🎜🎜<h3 data-id="heading-4">3. Negative bedingte Abfragen können keine Indizes verwenden🎜🎜🎜🎜Negative Bedingungen umfassen: <code>!=</code>, <code> code>, <code>nicht in</code>, <code>nicht vorhanden</code>, <code>nicht wie</code> usw. 🎜🎜🎜🎜Zum Beispiel kann die folgende SQL-Anweisung: 🎜🎜🎜<pre class="brush:php;toolbar:false">select * from doc where YEAR(create_time) 🎜🎜 in der Abfrage optimiert werden: 🎜🎜<pre class="brush:php;toolbar:false">select * from doc where create_time <h3 data-id="heading-5">4. Das Präfixprinzip ganz links des gemeinsamen Index🎜 🎜🎜🎜Wenn ein gemeinsamer Index für die drei Felder von <code>(a,b,c)</code> erstellt wird, wird automatisch <code>a</code>| erstellt ,b)</h3>|. (a,b,c)Gruppenindex. 🎜🎜🎜🎜Login-Geschäftsanforderungen, die SQL-Anweisung lautet wie folgt: 🎜
select uid, login_time from user where login_name=? andpasswd=?复制代码
- 可以建立
(login_name, passwd)的联合索引。因为业务上几乎没有passwd的单条件查询需求,而有很多login_name的单条件查询需求,所以可以建立(login_name, passwd)的联合索引,而不是(passwd, login_name)。
- 建立联合索引的时候,区分度最高的字段在最左边
- 存在非等号和等号混合判断条件时,在建立索引时,把等号条件的列前置。如
where a>? and b=?,那么即使a的区分度更高,也必须把b放在索引的最前列。
- 最左前缀查询时,并不是指SQL语句的where顺序要和联合索引一致。
- 下面的 SQL 语句也可以命中
(login_name, passwd)这个联合索引:
select uid, login_time from user where passwd=? andlogin_name=?复制代码
- 但还是建议
where后的顺序和联合索引一致,养成好习惯。
- 假如
index(a,b,c),where a=3 and b like 'abc%' and c=4,a能用,b能用,c不能用。
5、不能使用索引中范围条件右边的列(范围列可以用到索引),范围列之后列的索引全失效
- 范围条件有:
、>=、between等。 - 索引最多用于一个范围列,如果查询条件中有两个范围列则无法全用到索引。
- 假如有联合索引
(empno、title、fromdate),那么下面的 SQL 中emp_no可以用到索引,而title和from_date则使用不到索引。
select * from employees.titles where emp_no <h3 data-id="heading-7">6、不要在索引列上面做任何操作(计算、函数),否则会导致索引失效而转向全表扫描</h3>
- 例如下面的 SQL 语句,即使
date上建立了索引,也会全表扫描:
select * from doc where YEAR(create_time)
- 可优化为值计算,如下:
select * from doc where create_time
- 比如下面的 SQL 语句:
select * from order where date
- 可以优化为:
select * from order where date <h3 data-id="heading-8">7、强制类型转换会全表扫描</h3>
- 字符串类型不加单引号会导致索引失效,因为mysql会自己做类型转换,相当于在索引列上进行了操作。
- 如果
phone字段是varchar类型,则下面的 SQL 不能命中索引。
select * from user where phone=13800001234复制代码
- 可以优化为:
select * from user where phone='13800001234';复制代码
8、更新十分频繁、数据区分度不高的列不宜建立索引
更新会变更 B+ 树,更新频繁的字段建立索引会大大降低数据库性能。
“性别”这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性能与全表扫描类似。
一般区分度在80%以上的时候就可以建立索引,区分度可以使用
count(distinct(列名))/count(*)来计算。
9、利用覆盖索引来进行查询操作,避免回表,减少select * 的使用
- 覆盖索引:查询的列和所建立的索引的列个数相同,字段相同。
- 被查询的列,数据能从索引中取得,而不用通过行定位符 row-locator 再到 row 上获取,即“被查询列要被所建的索引覆盖”,这能够加速查询速度。
- 例如登录业务需求,SQL语句如下。
Select uid, login_time from user where login_name=? and passwd=?复制代码
- 可以建立
(login_name, passwd, login_time)的联合索引,由于login_time已经建立在索引中了,被查询的uid和login_time就不用去row上获取数据了,从而加速查询。
10、索引不会包含有NULL值的列
- 只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有
NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时,尽量使用not null约束以及默认值。
11、is null, is not null无法使用索引
12、如果有order by、group by的场景,请注意利用索引的有序性
-
order by最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现file_sort 的情况,影响查询性能。
- 例如对于语句
where a=? and b=? order by c,可以建立联合索引(a,b,c)。
- 如果索引中有范围查找,那么索引有序性无法利用,如
WHERE a>10 ORDER BY b;,索引(a,b)无法排序。
13、使用短索引(前缀索引)
对列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个
CHAR(255)的列,如果该列在前10个或20个字符内,可以做到既使得前缀索引的区分度接近全列索引,那么就不要对整个列进行索引。因为短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作,减少索引文件的维护开销。可以使用count(distinct leftIndex(列名, 索引长度))/count(*)来计算前缀索引的区分度。但缺点是不能用于
ORDER BY和GROUP BY操作,也不能用于覆盖索引。不过很多时候没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
14、利用延迟关联或者子查询优化超多分页场景
- MySQL 并不是跳过
offset行,而是取offset+N行,然后返回放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL 改写。 - 示例如下,先快速定位需要获取的
id段,然后再关联:
selecta.* from 表1 a,(select id from 表1 where 条件 limit100000,20 ) b where a.id=b.id;复制代码
15、如果明确知道只有一条结果返回,limit 1 能够提高效率
- 比如如下 SQL 语句:
select * from user where login_name=?;复制代码
- 可以优化为:
select * from user where login_name=? limit 1复制代码
- 自己明确知道只有一条结果,但数据库并不知道,明确告诉它,让它主动停止游标移动。
16、超过三个表最好不要 join
需要 join 的字段,数据类型必须一致,多表关联查询时,保证被关联的字段需要有索引。
例如:
left join是由左边决定的,左边的数据一定都有,所以右边是我们的关键点,建立索引要建右边的。当然如果索引在左边,可以用right join。
17、单表索引建议控制在5个以内
18、SQL 性能优化 explain 中的 type:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts 最好
consts:单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。ref:使用普通的索引(Normal Index)。range:对索引进行范围检索。当
type=index时,索引物理文件全扫,速度非常慢。
19、业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引
- 不要以为唯一索引影响了
insert速度,这个速度损耗可以忽略,但提高查找速度是明显的。另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
20.创建索引时避免以下错误观念
- 索引越多越好,认为需要一个查询就建一个索引。
- 宁缺勿滥,认为索引会消耗空间、严重拖慢更新和新增速度。
- 抵制惟一索引,认为业务的惟一性一律需要在应用层通过“先查后插”方式解决。
- 过早优化,在不了解系统的情况下就开始优化。
索引选择性与前缀索引
既然索引可以加快查询速度,那么是不是只要是查询语句需要,就建上索引?答案是否定的。因为索引虽然加快了查询速度,但索引也是有代价的:索引文件本身要消耗存储空间,同时索引会加重插入、删除和修改记录时的负担,另外,MySQL在运行时也要消耗资源维护索引,因此索引并不是越多越好。一般两种情况下不建议建索引。
第一种情况是表记录比较少,例如一两千条甚至只有几百条记录的表,没必要建索引,让查询做全表扫描就好了。至于多少条记录才算多,这个个人有个人的看法,我个人的经验是以2000作为分界线,记录数不超过 2000可以考虑不建索引,超过2000条可以酌情考虑索引。
另一种不建议建索引的情况是索引的选择性较低。所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:
Index Selectivity = Cardinality / #T复制代码
- 显然选择性的取值范围为
(0, 1]``,选择性越高的索引价值越大,这是由B+Tree的性质决定的。例如,employees.titles表,如果title`字段经常被单独查询,是否需要建索引,我们看一下它的选择性:
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles; +-------------+| Selectivity | +-------------+| 0.0000 | +-------------+复制代码
title的选择性不足0.0001(精确值为0.00001579),所以实在没有什么必要为其单独建索引。有一种与索引选择性有关的索引优化策略叫做前缀索引,就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。下面以
employees.employees表为例介绍前缀索引的选择和使用。假设employees表只有一个索引
,那么如果我们想按名字搜索一个人,就只能全表扫描了:
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido'; +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+复制代码
- 如果频繁按名字搜索员工,这样显然效率很低,因此我们可以考虑建索引。有两种选择,建
<first_name></first_name>或<first_name last_name></first_name>,看下两个索引的选择性:
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.0042 | +-------------+SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.9313 | +-------------+复制代码
-
<first_name></first_name>显然选择性太低,`<first_name last_name></first_name>选择性很好,但是first_name和last_name加起来长度为30,有没有兼顾长度和选择性的办法?可以考虑用first_name和last_name的前几个字符建立索引,例如<first_name left></first_name>,看看其选择性:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.7879 | +-------------+复制代码
- 选择性还不错,但离0.9313还是有点距离,那么把last_name前缀加到4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.9007 | +-------------+复制代码
- 这时选择性已经很理想了,而这个索引的长度只有
18,比<first_name last_name></first_name>短了接近一半,我们把这个前缀索引建上:
ALTER TABLE employees.employees ADD INDEX `first_name_last_name4` (first_name, last_name(4));复制代码
- 此时再执行一遍按名字查询,比较分析一下与建索引前的结果:
SHOW PROFILES; +----------+------------+---------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------------------------------------------------------+ | 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | | 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | +----------+------------+---------------------------------------------------------------------------------+复制代码
性能的提升是显著的,查询速度提高了120多倍。
前缀索引兼顾索引大小和查询速度,但是其缺点是不能用于
ORDER BY和GROUP BY操作,也不能用于Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)。
总结
- 本文主要讲了索引优化的二十个原则,希望读者喜欢。
本篇文章
脑图和PDF文档已经准备好,有需要的伙伴可以回复关键词索引优化获取。
Weitere verwandte kostenlose Lernempfehlungen: MySQL-Tutorial(Video)
Das obige ist der detaillierte Inhalt vonEisensaft, MySQL-Indexoptimierungsregeln werden Ihnen gegeben! !. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!