
Heim >Backend-Entwicklung >Python-Tutorial >Crawler-Parsing-Methode fünf: XPath
Crawler-Parsing-Methode fünf: XPath

- 爱喝马黛茶的安东尼nach vorne
- 2019-06-05 15:36:242775Durchsuche
Viele Sprachen können zum Crawlen verwendet werden, aber Crawler, die auf Python basieren, sind prägnanter und bequemer. Crawler sind auch zu einem wesentlichen Bestandteil der Python-Sprache geworden. Es gibt auch verschiedene Möglichkeiten, Crawler zu analysieren. Im vorherigen Artikel wurde Ihnen die vierte Crawler-Parsing-Methode vorgestellt: PyQuery Heute stelle ich Ihnen eine weitere Methode vor, XPath.

Grundlegende Verwendung von xpath im Python-Crawler
1. Einführung
XPath ist eine Sprache zum Auffinden von Informationen in XML-Dokumenten. XPath kann zum Durchlaufen von Elementen und Attributen in XML-Dokumenten verwendet werden. XPath ist ein Hauptelement des W3C XSLT-Standards und sowohl XQuery als auch XPointer basieren auf XPath-Ausdrücken.2. Installation
pip3 install lxml
3. Verwendung
1 , importierenfrom lxml import etree2. Grundlegende Verwendung
from lxml import etree
wb_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(wb_data)
print(html)
result = etree.tostring(html)
print(result.decode("utf-8")) Aus den folgenden Ergebnissen geht hervor, dass unser Drucker-HTML tatsächlich ein Python-Objekt ist und etree.tostring(html) die grundlegende Schreibmethode von HTML in Buquanli ist vervollständigt die Tags, denen Arme und Beine fehlen. <Element html at 0x39e58f0>
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html> 3. Holen Sie sich den Inhalt eines bestimmten Tags (grundlegende Verwendung). Beachten Sie, dass zum Abrufen des gesamten Inhalts eines Tags kein Schrägstrich nach a eingefügt werden muss, da sonst ein Fehler auftritt gemeldet. Schreibmethode eins
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a')
print(html)
for i in html_data:
print(i.text) <Element html at 0x12fe4b8> first item second item third item fourth item fifth item
Schreibmethode zwei
(direkt im Tag wo Sie müssen den Inhalt finden. Fügen Sie einfach ein /text() dahinter ein
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/text()')
print(html)
for i in html_data:
print(i) <Element html at 0x138e4b8> first item second item third item fourth item fifth itemDrucken:
#使用parse打开html的文件
html = etree.parse('test.html')
html_data = html.xpath('//*')<br>#打印是一个列表,需要遍历
print(html_data)
for i in html_data:
print(i.text) 5. Drucken Sie die Attribute des aus ein Tag unter dem angegebenen Pfad (Sie können einen bestimmten Wert eines Attributs abrufen und den Inhalt des Tags finden) html = etree.parse('test.html') html_data = etree.tostring(html,pretty_print=True) res = html_data.decode('utf-8') print(res)Drucken:
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div> 6. Wir Beachten Sie, dass wir xpath verwenden, um ElementTree-Objekte einzeln abzurufen. Wenn Sie also Inhalte finden müssen, müssen Sie auch die Datenliste durchsuchen. Suchen Sie unter dem absoluten Pfad den Inhalt, dessen Tag-Attribut „link2.html“ entspricht. html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/@href')
for i in html_data:
print(i) Drucken: ['zweiter Artikel']zweiter Artikel 7. Oben finden wir alle absoluten Pfade (jeder wird von der Wurzel aus durchsucht), unten finden wir relative Pfade, zum Beispiel finden wir den a-Tag-Inhalt unter allen li-Tags.
link1.html link2.html link3.html link4.html link5.htmlDrucken:
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a[@href="link2.html"]/text()')
print(html_data)
for i in html_data:
print(i) 8. Oben verwenden wir den absoluten Pfad, um die Attribute aller a-Tags zu finden, die dem href entsprechen Attributwert, mit Es ist /---absoluter Pfad, um den Wert des href-Attributs unter dem a-Tag unter dem li-Tag unter dem l-relativen Pfad zu finden Etikett. html = etree.HTML(wb_data)
html_data = html.xpath('//li/a/text()')
print(html_data)
for i in html_data:
print(i)Drucken: ['first item', 'second item', 'third item', 'fourth item', 'fifth item'] first item second item third item fourth item fifth item
9. Die Methode zur Überprüfung spezifischer Attribute unter relativen Pfaden ähnelt der unter absoluten Pfaden. Man kann auch sagen, dass sie dieselbe ist.
html = etree.HTML(wb_data)
html_data = html.xpath('//li/a//@href')
print(html_data)
for i in html_data:
print(i)Drucken:
[<Element a at 0x216e468>] second item
10、查找最后一个li标签里的a标签的href属性
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()]/a/text()')
print(html_data)
for i in html_data:
print(i)
打印:
['fifth item'] fifth item
11、查找倒数第二个li标签里的a标签的href属性
html = etree.HTML(wb_data)
html_data = html.xpath('//li[last()-1]/a/text()')
print(html_data)
for i in html_data:
print(i)
打印:
['fourth item'] fourth item
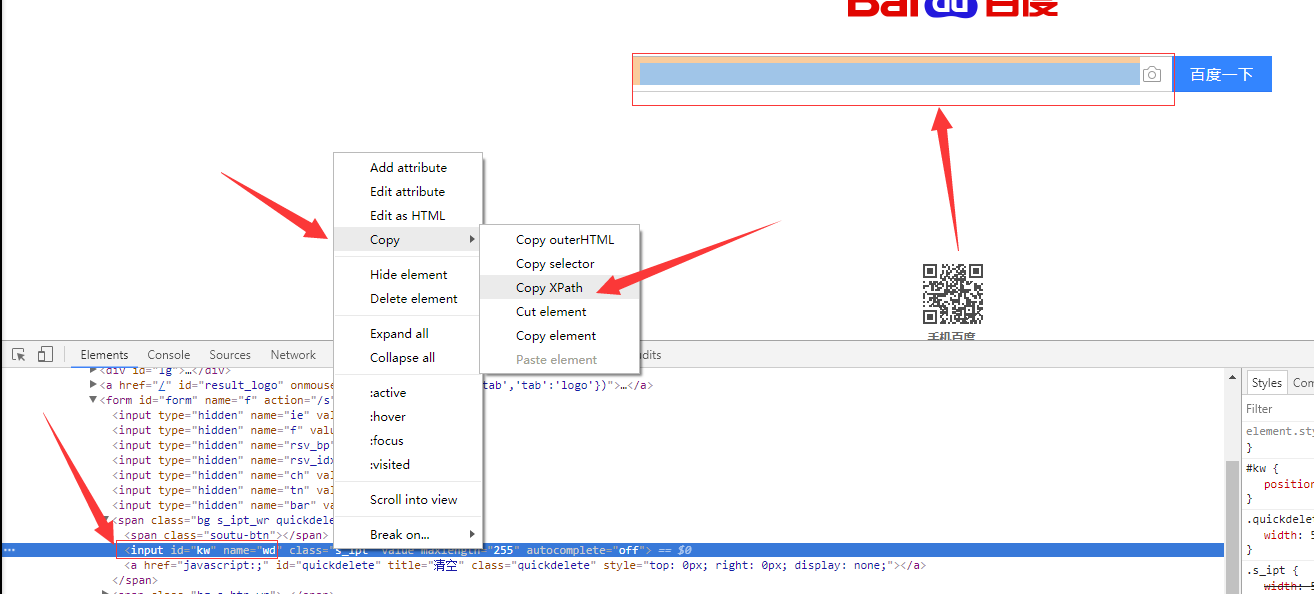
12、如果在提取某个页面的某个标签的xpath路径的话,可以如下图:
//*[@id="kw"]
解释:使用相对路径查找所有的标签,属性id等于kw的标签。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.selector import Selector, HtmlXPathSelector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
<li><a id='i1' href="link.html">first item</a></li>
<li><a id='i2' href="llink.html">first item</a></li>
<li><a href="llink2.html">second item<span>vv</span></a></li>
</ul>
<div><a href="llink2.html">second item</a></div>
</body>
</html>
"""
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
# hxs = HtmlXPathSelector(response)
# print(hxs)
# hxs = Selector(response=response).xpath('//a')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[2]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[contains(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first()
# print(hxs)
# ul_list = Selector(response=response).xpath('//body/ul/li')
# for item in ul_list:
# v = item.xpath('./a/span')
# # 或
# # v = item.xpath('a/span')
# # 或
# # v = item.xpath('*/a/span')
# print(v)Das obige ist der detaillierte Inhalt vonCrawler-Parsing-Methode fünf: XPath. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!