
Heim >Backend-Entwicklung >Python-Tutorial >Crawler-Parsing-Methode vier: PyQuery
Crawler-Parsing-Methode vier: PyQuery

- 爱喝马黛茶的安东尼nach vorne
- 2019-06-05 15:14:533495Durchsuche
Viele Sprachen können crawlen, aber Crawler, die auf Python basieren, sind prägnanter und bequemer. Crawler sind auch zu einem wesentlichen Bestandteil der Python-Sprache geworden. Es gibt auch verschiedene Möglichkeiten, Crawler zu analysieren. Im vorherigen Artikel wurde Ihnen die dritte Methode zum Parsen von Crawlern vorgestellt: reguläre Ausdrücke . Heute stelle ich Ihnen eine weitere Methode vor: PyQuery.

PyQuery
Die PyQuery-Bibliothek ist auch eine sehr leistungsstarke und flexible Webseiten-Parsing-Bibliothek, wenn Sie über Front-End-Entwicklung verfügen Wenn Sie Erfahrung mit jQuery haben, ist PyQuery eine sehr gute Wahl für Sie. Die Syntax ist nahezu identisch mit der von jQuery, sodass Sie sich keine seltsamen Methoden mehr merken müssen.
Im Allgemeinen gibt es drei Möglichkeiten, während der Initialisierung zu übergeben: Zeichenfolge übergeben, URL übergeben, Datei übergeben.
String-Initialisierung
html =
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
from pyquery
import PyQuery as pq
doc = pq(html)print(doc)
print(type(doc))
print(doc('li'))Die Ergebnisse sind wie folgt:
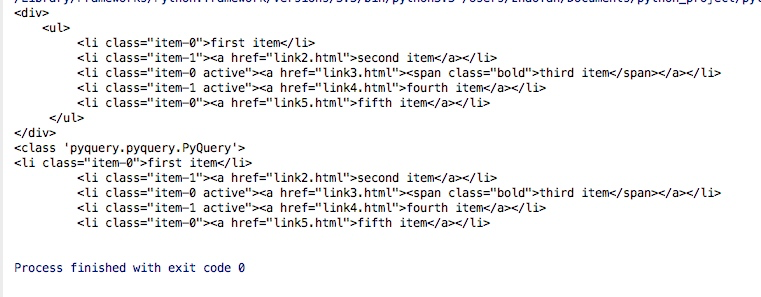
Da PyQuery schwieriger zu schreiben ist, Wir importieren den Alias, wenn er hinzugefügt wird:
from pyquery import PyQuery as pq
Hier können wir erkennen, dass das Dokument im obigen Code tatsächlich ein Pyquery-Objekt ist. Tatsächlich ist dies der Fall ein CSS-Selektor, daher können alle CSS-Selektorregeln direkt verwendet werden, um den gesamten Inhalt des Tags abzurufen, dann doc('.class_name'). die ID, dann doc('#id_name') ....
URL-Initialisierung
from pyquery import PyQuery as pq doc = pq(url="http://www.baidu.com",encoding='utf-8')print(doc('head'))
Dateiinitialisierung
Wir können URL-Parameter übergeben oder Dateiparameter hier in pq() , natürlich ist die Datei hier normalerweise eine HTML-Datei, zum Beispiel: pq(filename='index.html')
Basic CSS Selector
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))One Worauf wir hier achten müssen, ist das Dokument („#container .list li“). Die drei hier müssen nicht nebeneinander liegen, solange eine hierarchische Beziehung besteht. Das Folgende ist das häufig verwendete CSS Auswahlmethode:
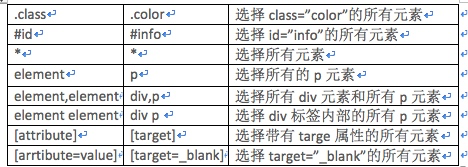
Element suchen
Untergeordnetes Element
Kinder, finden
Code Beispiel:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis)Die laufenden Ergebnisse lauten wie folgt
Aus den Ergebnissen können wir auch ersehen, dass es sich bei dem durch Pyquery gefundenen Ergebnis tatsächlich um ein Pyquery-Objekt handelt, und Sie können mit der Suche nach items.find fortfahren ('li') im obigen Code bedeutet, alle li im ul-Tag zu finden
Natürlich kann der gleiche Effekt durch Kinder erzielt werden, und das durch die .children-Methode erhaltene Ergebnis ist auch ein Pyquery-Objekt
li = items.children() print(type(li)) print(li)
. Gleichzeitig kann der CSS-Selektor
li2 = items.children('.active') print(li2)
auch in untergeordneten Elementen Parent, Parents-Methode
html = '''<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)Sie können den Vorfahrenknoten durch .parents finden. Der Inhalt von In ähnlicher Weise, wenn wir durch .parents suchen, Wir können auch CSS-Selektoren hinzufügen, um den Inhalt zu filtern
Geschwisterelemente
Geschwisterhtml = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents) Im Code .tem-0 und .active in doc(' .list .item-0.active') liegen nebeneinander, stehen also in einer zusammengeführten Beziehung, sodass nur noch eines übrig ist, das die Bedingungen erfüllt: das dritte Element Dieses Tag
Auf diese Weise können Sie es erhalten Alle Geschwister-Tags über .siblings sind hier natürlich nicht enthalten
Traverse
Einzelnes Element
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())Die laufenden Ergebnisse sind wie folgt: Aus den Ergebnissen können wir ersehen, dass ein Generator über items() erhalten werden kann. Und jedes Element, das wir erhalten durch die for-Schleife ist immer noch ein Pyquery-Objekt.
Informationen abrufenAttribute abrufen
pyquery object.attr(attribute name)pyquery object.attr.attribute namehtml = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
lis = doc('li').items()
print(type(lis))for li in lis:
print(type(li))
print(li)Hier können wir also auch wissen, dass wir beim Abrufen des Attributwerts direkt a.attr (Attributname) oder a.attr.attribute name
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))
print(a.attr.href)Die Ergebnisse sind wie folgt:  HTML abrufen
HTML abrufen
Wir können die im aktuellen Tag enthaltenen HTML-Informationen über .html() abrufen . Das Beispiel lautet wie folgt:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())Die Ergebnisse sind wie folgt:
addClass、removeClass
熟悉前端操作的话,通过这两个操作可以添加和删除属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.css('font-size', '14px')
print(li)结果如下:

remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
html = '''<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>'''from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())结果如下:

Das obige ist der detaillierte Inhalt vonCrawler-Parsing-Methode vier: PyQuery. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!