
Heim >Backend-Entwicklung >Python-Tutorial >So implementieren Sie „pivot()' in pandas.DataFrame, um Zeilen in Spalten zu konvertieren (Code)
So implementieren Sie „pivot()' in pandas.DataFrame, um Zeilen in Spalten zu konvertieren (Code)

- 不言nach vorne
- 2018-10-13 14:34:006472Durchsuche
Der Inhalt dieses Artikels handelt davon, wie „pivot()“ in pandas.DataFrame die Zeilenkonvertierung (Code) implementiert. Ich hoffe, dass er Ihnen helfen wird.
Beispiel:
Die folgende Tabelle muss zwischen Zeilen konvertiert werden und Spalten:
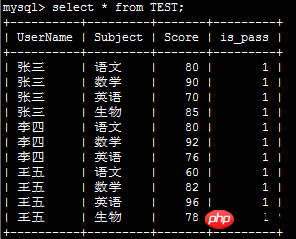
Der Code lautet wie folgt:
# -*- coding:utf-8 -*-
import pandas as pd
import MySQLdb
from warnings import filterwarnings
# 由于create table if not exists总会抛出warning,因此使用filterwarnings消除
filterwarnings('ignore', category = MySQLdb.Warning)
from sqlalchemy import create_engine
import sys
if sys.version_info.major<3:
reload(sys)
sys.setdefaultencoding("utf-8")
# 此脚本适用于python2和python3
host,port,user,passwd,db,charset="192.168.1.193",3306,"leo","mysql","test","utf8"
def get_df():
global host,port,user,passwd,db,charset
conn_config={"host":host, "port":port, "user":user, "passwd":passwd, "db":db,"charset":charset}
conn = MySQLdb.connect(**conn_config)
result_df=pd.read_sql('select UserName,Subject,Score from TEST',conn)
return result_df
def pivot(result_df):
df_pivoted_init=result_df.pivot('UserName','Subject','Score')
df_pivoted = df_pivoted_init.reset_index() # 将行索引也作为DataFrame值的一部分,以方便存储数据库
return df_pivoted_init,df_pivoted
# 返回的两个DataFrame,一个是以姓名作index的,一个是以数字序列作index,前者用于unpivot,后者用于save_to_mysql
def unpivot(df_pivoted_init):
# unpivot需要进行df_pivoted_init二维表格的行、列索引遍历,需要拼SQL因此不能使用save_to_mysql存数据,这里使用SQL和MySQLdb接口存
insert_sql="insert into test_unpivot(UserName,Subject,Score) values "
# 处理值为NaN的情况
df_pivoted_init=df_pivoted_init.add(0,fill_value=0)
for col in df_pivoted_init.columns:
for index in df_pivoted_init.index:
value=df_pivoted_init.at[index,col]
if value!=0:
insert_sql=insert_sql+"('%s','%s',%s)" %(index,col,value)+','
insert_sql = insert_sql.strip(',')
global host, port, user, passwd, db, charset
conn_config = {"host": host, "port": port, "user": user, "passwd": passwd, "db": db, "charset": charset}
conn = MySQLdb.connect(**conn_config)
cur=conn.cursor()
cur.execute("create table if not exists test_unpivot like TEST")
cur.execute(insert_sql)
conn.commit()
conn.close()
def save_to_mysql(df_pivoted,tablename):
global host, port, user, passwd, db, charset
"""
只有使用sqllite时才能指定con=connection实例,其他数据库需要使用sqlalchemy生成engine,engine的定义可以添加?来设置字符集和其他属性
"""
conn="mysql://%s:%s@%s:%d/%s?charset=%s" %(user,passwd,host,port,db,charset)
mysql_engine = create_engine(conn)
df_pivoted.to_sql(name=tablename, con=mysql_engine, if_exists='replace', index=False)
# 从TEST表读取源数据至DataFrame结构
result_df=get_df()
# 将源数据行转列为二维表格形式
df_pivoted_init,df_pivoted=pivot(result_df)
# 将二维表格形式的数据存到新表test中
save_to_mysql(df_pivoted,'test')
# 将被行转列的数据unpivot,存入test_unpivot表中
unpivot(df_pivoted_init)Das Ergebnis lautet wie folgt:
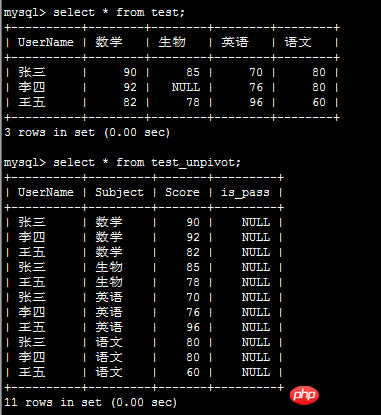
Über die Pivot-Methode, die mit der Pandas DataFrame-Klasse geliefert wird:
DataFrame.pivot(index=Keine, Spalten=Keine, Werte=Keine):
Gibt den umgeformten DataFrame zurück, organisiert nach angegebenen Index-/Spaltenwerten.
Hier gibt es nur 3 Parameter, weil Pivot Das nachfolgende Ergebnis muss eine zweidimensionale Tabelle sein, die nur Zeilen und Spalten und die entsprechenden Werte erfordert. Und da es sich um eine zweidimensionale Tabelle handelt, geht die Spalte is_pass danach definitiv verloren unpivot, daher habe ich diese Spalte am Anfang nicht überprüft.
Das obige ist der detaillierte Inhalt vonSo implementieren Sie „pivot()' in pandas.DataFrame, um Zeilen in Spalten zu konvertieren (Code). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Erläuterung des Beispielcodes der pandas.DataFrame-Methode zum Ausschließen bestimmter Zeilen in Python
- Einführung in einfache Betriebsmethoden von pandas.DataFrame (Erstellen, Indizieren, Hinzufügen und Löschen) in Python
- Beispielcode zum Summieren von Zeilen und Spalten und zum Hinzufügen neuer Zeilen und Spalten in pandas.DataFrame in Python
- Über die grundlegenden Operationen von pandas.DataFrame in Python
- Wie verwende ich pandas.DataFrame? Zusammenfassung der pandas.DataFrame-Instanznutzung
- pandas.DataFrame-Methode zum Erstellen neuer Spalten und zum Zuweisen von Werten basierend auf Bedingungen