
Heim >Java >javaLernprogramm >Ein Artikel, der Ihnen hilft, die Analyse und Verwendung des JDK-Thread-Pools zu verstehen
Ein Artikel, der Ihnen hilft, die Analyse und Verwendung des JDK-Thread-Pools zu verstehen

- 无忌哥哥Original
- 2018-07-20 10:24:121591Durchsuche
1. Warum Thread-Pool verwenden?
Eine sehr wichtige Funktion in der Multithread-Programmierung ist das Ausführen von Aufgaben, und es gibt viele Möglichkeiten, Aufgaben auszuführen. Warum müssen wir einen Thread-Pool verwenden? Im Folgenden verwenden wir die Funktion der Socket-Programmierung, um Anfragen zu verarbeiten und jede Methode zur Ausführung von Aufgaben zu analysieren.
1.1 Serielle Ausführung von Aufgaben
Wenn der Socket erkennt, dass der Client eine Verbindung hat, verarbeitet er jede Clientverbindung nacheinander über die handleSocket-Methode. Wenn die Verarbeitung abgeschlossen ist, lauscht er weiter. Der Code lautet wie folgt:
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
handleSocket(socket);
}Die Mängel dieser Methode liegen auf der Hand: Wenn ich mehrere Client-Anfragen habe und der Server eine Anfrage verarbeitet, müssen andere Anfragen auf die vorherige Anfrage warten verarbeitet werden. Dies ist in Situationen mit hoher Parallelität nahezu nicht verfügbar.
1.2 Erstellen Sie für jede Aufgabe einen Thread Optimieren Sie das obige Problem: Erstellen Sie für jede Clientanforderung einen Thread, um die Anforderung zu verarbeiten. Der Hauptthread muss nur den Thread erstellen, und dann können Sie ihn erstellen Unterstützen Sie weiterhin Kundenanfragen. Das Flussdiagramm lautet wie folgt: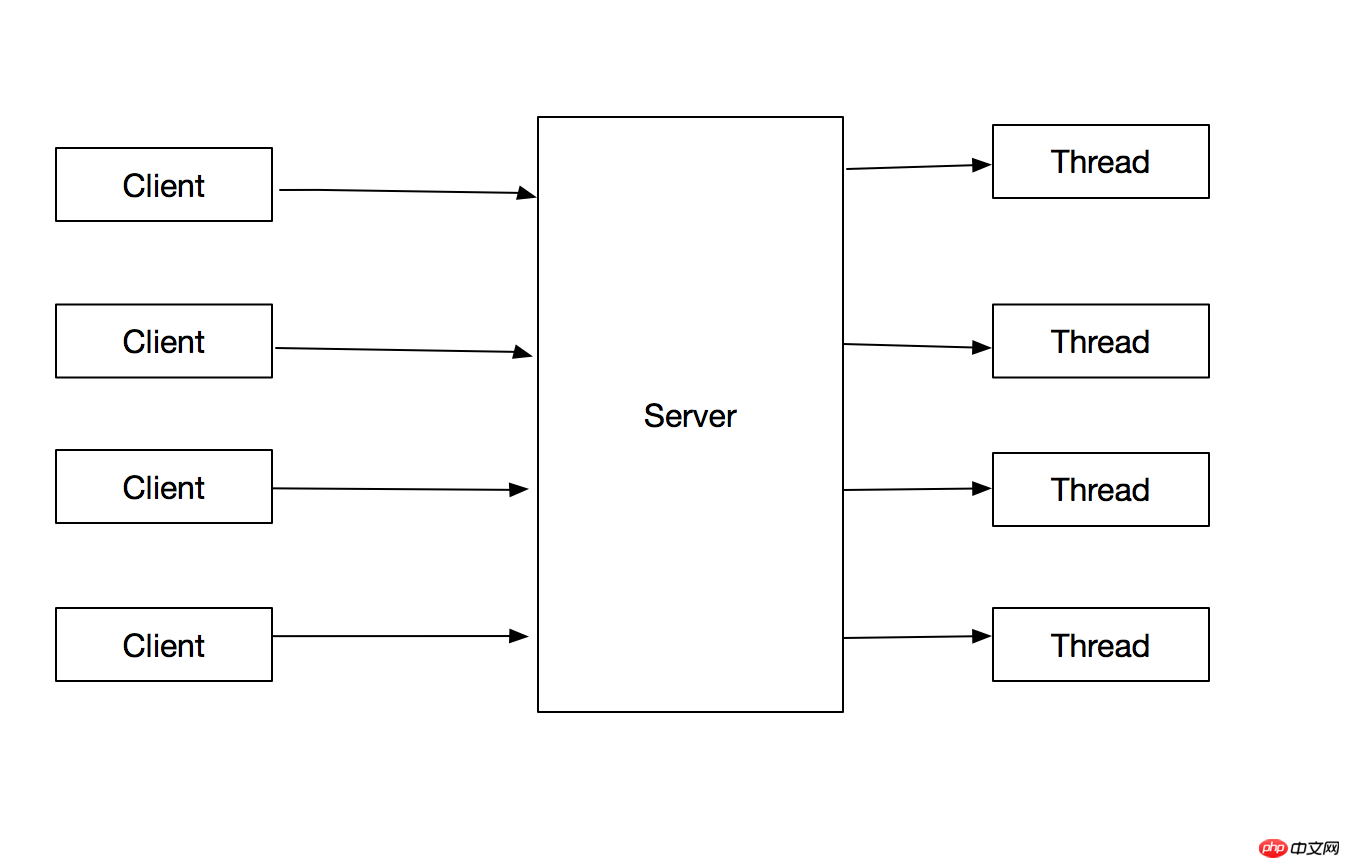
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
new SocketHandler(socket, THREAD_NAME_PREFIX + threadIndex++).start();
}Diese Methode hat die folgenden Vorteile: 1. Trennen Sie die Verarbeitung von Clientverbindungen vom Hauptthread , damit die Hauptschleife schneller auf die nächste Anfrage reagieren kann. 2. Die Verarbeitung von Client-Verbindungen erfolgt parallel, was den Durchsatz des Programms verbessert.
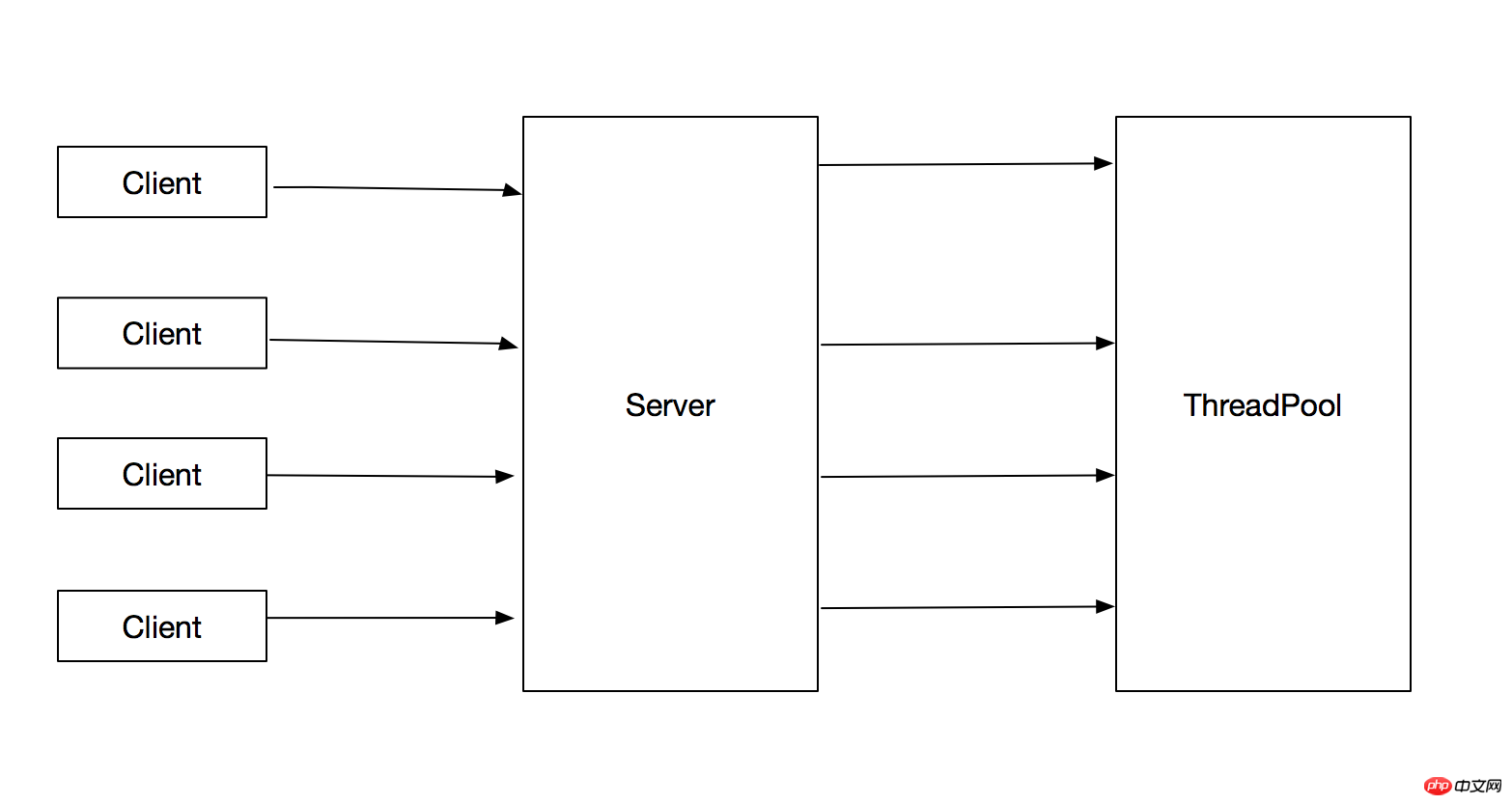
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
executorService.execute(new SocketHandler(socket, THREAD_NAME_PREFIX + threadIndex++));
}Diese Methode hat die folgenden Vorteile: 1 Aufgabenübermittlung und Aufgabenausführung Öffnen 2. Der Thread, der die Aufgabe ausführt, kann wiederverwendet werden, wodurch der Aufwand für die Thread-Erstellung und -Zerstörung verringert wird. Gleichzeitig kann der erstellte Thread direkt beim Eintreffen der Aufgabe ausgeführt werden wird zur Ausführung der Aufgabe verwendet, was auch die Reaktionsgeschwindigkeit des Programms verbessert. 2. Einführung in den Thread-Pool in Java Die Implementierung des Thread-Pools in Java basiert auf dem Producer-Consumer-Modell Die Funktion des Thread-Pools kombiniert die Übermittlung von Aufgaben und Die Ausführungstrennung, der Prozess der Aufgabenübermittlung ist der Produzent und der Prozess der Ausführung der Aufgabe ist der Konsumentenprozess . Eine spezifische Analyse finden Sie unter Quellcode-Analyse. Die Schnittstelle der obersten Ebene des Java-Thread-Pools ist Executor, und der Quellcode lautet wie folgt:
public interface Executor {
void execute(Runnable command);
} Diese Schnittstelle ist die Schnittstelle der obersten Ebene, die von allen Thread-Pools implementiert wird. Sie legt fest, dass der akzeptable Aufgabentyp ist die ausführbare Implementierungsklasse, aber die spezifische Ausführungslogik der Aufgabe wird durch die Thread-Pool-Implementierungsklasse selbst definiert: kann den Hauptthread verwenden, um Aufgaben seriell auszuführen Neuer Thread für jede Aufgabe oder erstellen Sie im Voraus eine Gruppe von Threads. Jedes Mal, wenn eine Aufgabe ausgeführt wird, wird sie aus einer Gruppe von Threads usw. entnommen.
Die Ausführungsstrategie des Thread-Pools hat hauptsächlich die folgenden Aspekte:
In welcher Reihenfolge werden Aufgaben ausgeführt (FIFO, LIFO, Priorität?)3 gleichzeitig ausgeführt
4. Wie viele Aufgaben können maximal auf die Ausführung in der Warteschlange warten
5. Wie werden neu übermittelte Aufgaben abgelehnt, wenn die Warteschlange den Maximalwert erreicht?
Welche Vorgänge müssen ausgeführt werden? vor oder nach der Ausführung einer Aufgabe erledigt?
Sie sollten je nach Geschäft unterschiedliche Ausführungsstrategien wählen. Die Executors-Toolklasse wird in der Java-Klassenbibliothek bereitgestellt, um den Standardstrategie-Thread-Pool zu verwenden. Es gibt hauptsächlich die folgenden Schnittstellen:
public static ExecutorService newFixedThreadPool(int nThreads) 将会创建一个固定大小的线程池,每当有新任务提交的时候,当线程总数没有达到核心线程数的时候,为每个任务创建一个新线程,当线程的个数到达最大值后,重用之前创建的线程,当线程因为未知异常而停止时候,将会重现创建一个线程作为补充。 public static ExecutorService newCachedThreadPool() 根据需求创建线程的个数,当线程数大于任务数的时候,将会注销多余的线程 public static ExecutorService newSingleThreadExecutor() 创建一个单线程的线程池 public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) 创建一个可执行定时任务的线程池
Im obigen Beispiel ist der Ausführungsstatus aller übermittelten Aufgaben nach der Übermittlung an den Thread-Pool unsichtbar, dh der Hauptthread kann nicht wissen, ob die übermittelten Aufgaben beendet wurden oder nicht. Ausführungsergebnisse. Um dieses Problem zu lösen, stellt Java die Aufgabenschnittstellen Future und Callable bereit, die Daten zurückgeben können.
Die Callable-Schnittstelle bietet die Funktion, Daten von der Aufgabe zurückzugeben und Ausnahmen auszulösen, und ist wie folgt definiert:public interface Callable<V> {
V call() throws Exception;
}Alle Submit-Methoden in ExecutorService geben ein Future-Objekt zurück und ihre Schnittstelle ist wie folgt definiert :
public interface Future<V> {
取消任务执行,当mayInterruptIfRunning为true,interruptedthisthread
boolean cancel(boolean mayInterruptIfRunning);
返回此任务是否在执行完毕之前被取消执行
boolean isCancelled();
返回此任务是否已经完成,包括正常结束,异常结束以及被cancel
boolean isDone();
返回执行结果,当任务没有执行结束的时候,等待
V get() throws InterruptedException, ExecutionException;
}3.使用线程池可能出现的问题
1.线程饥饿死锁
在单线程的Executor中,如果Executor中执行的一个任务中,再次提交任务到同一个Executor中,并且等待这个任务执行完毕,那么就会发生死锁问题。如下demo中所示:
public class ThreadDeadLock {
private static final ExecutorService EXECUTOR_SERVICE = Executors.newSingleThreadExecutor();
public static void main(String[] args) throws Exception {
System.out.println("Main Thread start.");
EXECUTOR_SERVICE.submit(new DeadLockThread());
System.out.println("Main Thread finished.");
}
private static class DeadLockThread extends Thread{
@Override
public void run() {
try {
System.out.println("DeadLockThread start.");
Future future = EXECUTOR_SERVICE.submit(new DeadLockThread2());
future.get();
System.out.println("DeadLockThread finished.");
} catch (Exception e) {
}
}
}
private static class DeadLockThread2 extends Thread {
@Override
public void run() {
try {
System.out.println("DeadLockThread2 start.");
Thread.sleep(1000 * 10);
System.out.println("DeadLockThread2 finished.");
} catch (Exception e) {
}
}
}
}输出结果为:
Main Thread start. Main Thread finished. DeadLockThread start.
对于多个线程的线程池,如果所有正在执行的线程都因为等待处于工作队列中的任务执行而阻塞,那么就会发生线程饥饿死锁。
当往线程池中提交有依赖的任务时,应清楚的知道可能会出现的线程饥饿死锁风险。==应考虑是否将依赖的task提交到不同的线程池中==
或者使用无界的线程池。
==只有当任务相对独立时,设置线程池大小和工作队列的大小才是合理的,否则有可能会出现线程饥饿死锁==
2.任务运行时间过长
任务执行时间过长会影响线程池的响应时间,当运行时间长的任务远大于线程池线程的个数时,会出现所有线程都在执行运行时间长的任务,从而影响对其他任务的响应。
解决办法:
1.通过限定任务等待的时长,而不要无限期等待下去,当等待超时的时候,可以将任务标记为失败,或者重新放到线程池中。
2.当线程池中阻塞任务过多的时,应该考虑扩大线程池的大小
4.线程池大小的设置
线程池的大小依赖于提交任务的类型以及服务器的可用资源,线程池的大小应该避免设置过大或者过小,当线程设置过打的时候可能会有资源耗尽的风险,线程池设置过小会有可用cpu空闲从而影响系统吞吐量。
影响线程池大小的资源有很多,比如CPU、内存、数据库链接池等,只需要计算资源可用总资源 / 每个任务需要的资源,取最小值,即可得出线程池的上限。
线程池的最小值应该大于可用的CPU数量。
4.java中常用线程池源码分析-ThreadPoolExecutor
ThreadPoolExecutor线程池是比较常用的一个线程池实现类,通过Executors工具类创建的线程池中,其具体实现类是ThreadPoolExecutor。首先我们可以看下ThreadPoolExecutor的构造函数如下:
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)下面分别对构造函数中的各个参数对应的策略进行分析:
1.线程的创建与销毁
首先构造函数中corePoolSize、maximumPoolSize、keepAliveTime和unit参数影响线程的创建和销毁。其中corePoolSize为核心线程数,当第一次提交任务的时候如果正在执行的线程数小于corePoolSize,则新建一个线程执行task,如果已经超过corePoolSize,则将任务放到任务队列中等待执行。当任务队列的个数到达上限的时候,并且工作线程数量小于maximumPoolSize,则继续创建线程执行工作队列中的任务。当任务的个数小于maximumPoolSize的时候,将会把空闲的线程标记为可回收的垃圾线程。对于以下代码段测试此功能:
public class ThreadPoolTest {
private static ThreadPoolExecutor executorService = new ThreadPoolExecutor(3, 6,100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(3));
public static void main(String[] args) throws Exception {
for (int i = 0; i< 9; i++) {
executorService.submit(new Task());
System.out.println("Active thread:" + executorService.getActiveCount() + ".Task count:" + executorService.getTaskCount() + ".TaskQueue size:" + executorService.getQueue().size());
}
}
private static class Task extends Thread {
@Override
public void run() {
try {
Thread.sleep(1000 * 100);
} catch (Exception e) {
}
}
}
}输出结果为:
Active thread:1.Task count:1.TaskQueue size:0 Active thread:2.Task count:2.TaskQueue size:0 Active thread:3.Task count:3.TaskQueue size:0 Active thread:3.Task count:4.TaskQueue size:1 Active thread:3.Task count:5.TaskQueue size:2 Active thread:3.Task count:6.TaskQueue size:3 Active thread:4.Task count:7.TaskQueue size:3 Active thread:5.Task count:8.TaskQueue size:3 Active thread:6.Task count:9.TaskQueue size:3
2.任务队列
在ThreadPoolExecutor的构造函数中可以传入保存任务的队列,当新提交的任务没有空闲线程执行时候,会将task保存到此队列中。保存的顺序是根据插入的顺序或者Comparator来排序的。
3.饱和策略
ThreadPoolExecutor.AbortPolicy 抛出RejectedExecutionException ThreadPoolExecutor.CallerRunsPolicy 将任务的执行交给调用者,即将本该异步执行的任务变成同步执行。
4.线程工厂
当线程池需要创建线程的时候,默认是使用线程工厂方法来创建线程的,通常情况下我们通过指定线程工厂的方式来为线程命名,便于出现线程安全问题时候来定位问题。
5.线程池最佳实现
1.项目中所有的线程应该都有线程池来提供,不允许自行创建线程
2.尽量不要用Executors来创建线程,而是使用ThreadPoolExecutor来创建
Executors有以下问题:
1)FixedThreadPool 和 SingleThreadPool: 允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。 2)CachedThreadPool 和 ScheduledThreadPool: 允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
Das obige ist der detaillierte Inhalt vonEin Artikel, der Ihnen hilft, die Analyse und Verwendung des JDK-Thread-Pools zu verstehen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie aktualisiere ich ein JLabel kontinuierlich mit Swing Timer und SwingWorker?
- Wie gruppiere ich verschachtelte Java 8-Objekte mithilfe von Collectors nach mehreren Schlüsseln?
- Warum und wie sollten Sie String-Objekte in Java synchronisieren?
- Warum liefert der Moduloperator von Java ein negatives Ergebnis für negative Zahlen?
- Hier sind einige Titeloptionen unter Beibehaltung des Fragenformats: * So integrieren Sie Java nahtlos in Python: Ein umfassender Leitfaden zur Auswahl des richtigen Ansatzes * Python ruft Java auf: Welche Methode