
Heim >Backend-Entwicklung >Python-Tutorial >Beispiel für die gemeinsame Nutzung eines dynamischen Python-Crawlers
Beispiel für die gemeinsame Nutzung eines dynamischen Python-Crawlers

- 小云云Original
- 2018-03-30 16:41:113966Durchsuche
In diesem Artikel werden hauptsächlich Beispiele für dynamische Python-Crawler vorgestellt. Wenn Sie Python zum Crawlen herkömmlicher statischer Webseiten verwenden, wird häufig urllib2 verwendet, um die gesamte HTML-Seite abzurufen, und dann werden die entsprechenden Schlüsselwörter Wort für Wort aus der HTML-Datei durchsucht . Wie unten gezeigt:
#encoding=utf-8
import urllib2 url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1"up=urllib2.urlopen(url)#打开目标页面,存入变量upcont=up.read()#从up中读入该HTML文件key1='<a href="http'#设置关键字1key2="target"#设置关键字2pa=cont.find(key1)#找出关键字1的位置pt=cont.find(key2,pa)#找出关键字2的位置(从字1后面开始查找)urlx=cont[pa:pt]#得到关键字1与关键字2之间的内容(即想要的数据)print urlx
Auf dynamischen Seiten wird der angezeigte Inhalt jedoch häufig nicht über HTML-Seiten dargestellt, sondern Daten werden durch Aufrufen von js und anderen Methoden aus der Datenbank abgerufen und wiedergegeben zur Webseite.
Nehmen Sie als Beispiel die „Registrierungsinformationen“ (http://beian.hndrc.gov.cn/) auf der Website der National Development and Reform Commission. Wir möchten einige der Anmeldeelemente auf dieser Seite erfassen . Zum Beispiel „http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518“.
Öffnen Sie dann diese Seite im Browser:
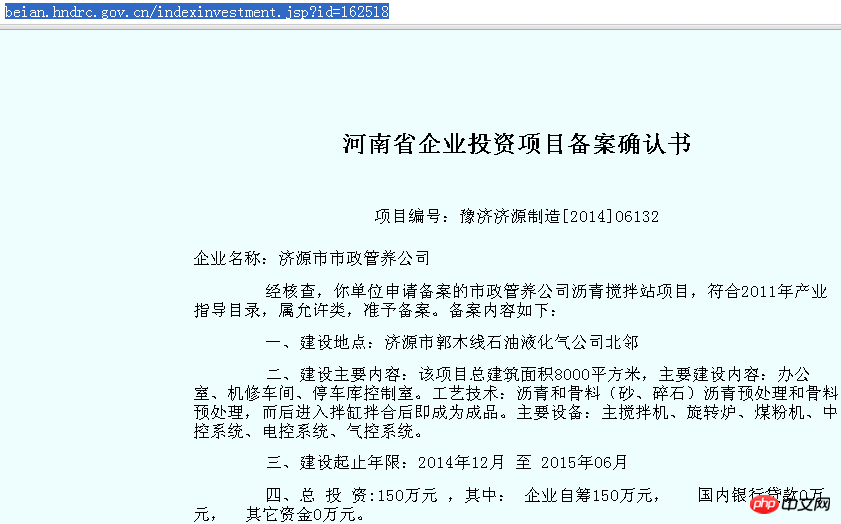
Die relevanten Informationen werden vollständig angezeigt, aber wenn Sie der vorherigen Methode folgen:
up=urllib2.urlopen(url) cont=up.read()
kann den oben genannten Inhalt nicht erfassen.
Sehen wir uns den entsprechenden Quellcode dieser Seite an:

Wie aus dem Quellcode ersichtlich ist, liegt dieses „Einreichungsbestätigungsschreiben“ in der Form vor von „Füllen Sie die Lücken aus“, HTML Es wird eine Textvorlage bereitgestellt, und js stellt verschiedene Variablen entsprechend unterschiedlichen IDs bereit, die in die Textvorlage „ausgefüllt“ werden, um ein spezifisches „Einreichungsbestätigungsschreiben“ zu bilden. Wenn Sie also einfach diesen HTML-Code abrufen, erhalten Sie nur einige Textvorlagen, nicht jedoch den spezifischen Inhalt.
Wie findet man also diese spezifischen Inhalte? Sie können die „Entwicklertools“ von Chrome verwenden, um herauszufinden, wer der eigentliche Inhaltsanbieter ist.
Öffnen Sie den Chrome-Browser und drücken Sie F12 auf der Tastatur, um dieses Tool aufzurufen. Wie unten gezeigt:
Wählen Sie zu diesem Zeitpunkt die Bezeichnung „Netzwerk“ und geben Sie diese Seite ein: „http://beian.hndrc.gov.cn/indexinvestment.jsp?“ „in der Adressleiste. id=162518“ analysiert der Browser den gesamten Prozess dieser Antwort, und die Dateien im roten Feld stellen die gesamte Kommunikation zwischen dem Browser und dem Web-Backend in dieser Antwort dar.
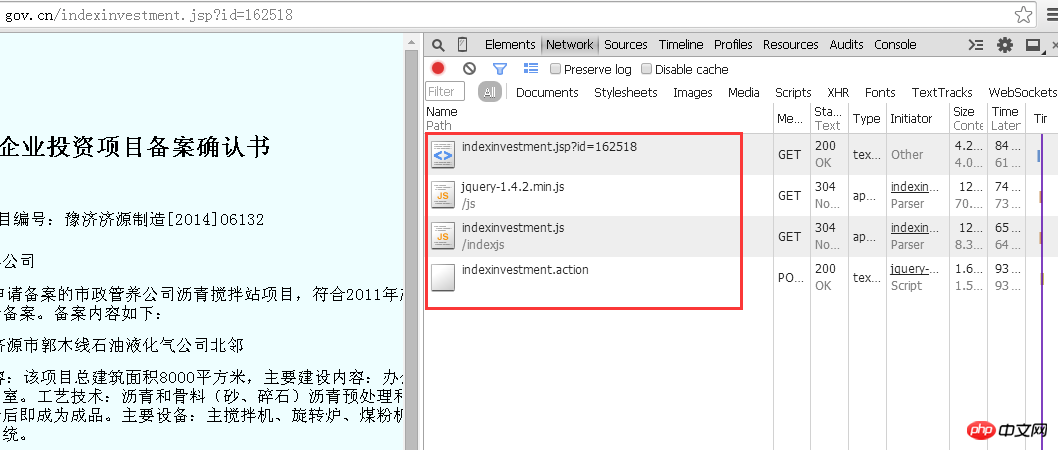
Da Sie unterschiedliche Informationen zu verschiedenen Unternehmen erhalten möchten, muss die vom Browser an den Server gesendete Anfrage einen Parameter enthalten, der sich auf die aktuelle Unternehmens-ID bezieht.
Was sind also die Parameter? Auf der URL steht „jsp?id=162518“. Das Fragezeichen gibt an, dass die Parameter aufgerufen werden sollen, gefolgt von der ID-Nummer, die der aufzurufende Parameter ist. Durch die Analyse dieser Dateien ist es offensichtlich, dass Unternehmensinformationen in der Datei „indexinvestment.action“ vorhanden sind.
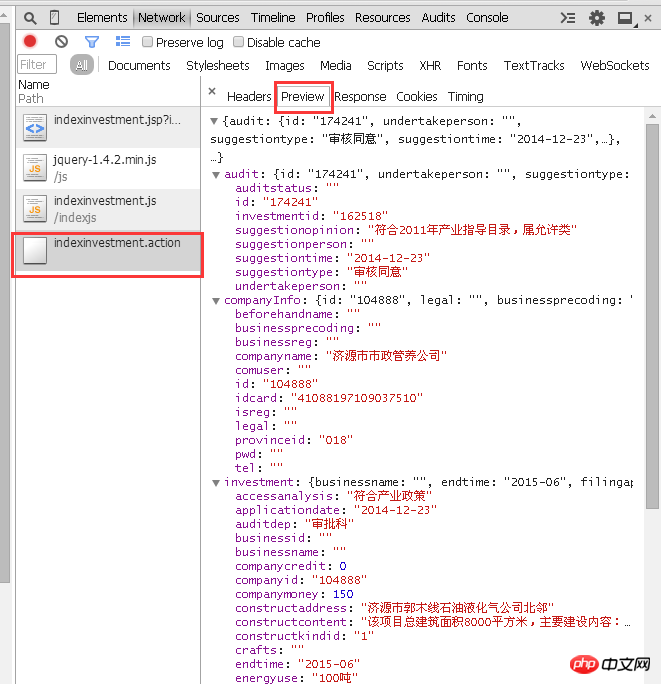
Ein Doppelklick zum Öffnen dieser Datei erhält jedoch keine Unternehmensinformationen, sondern eine Menge Code. Weil es keinen entsprechenden Parameter gibt, der angibt, welche Anzahl von Informationen angezeigt werden sollen. Wie im Bild gezeigt:

Wie sollten Sie also Parameter daran übergeben? Zu diesem Zeitpunkt schauen wir noch auf das F12-Fenster:
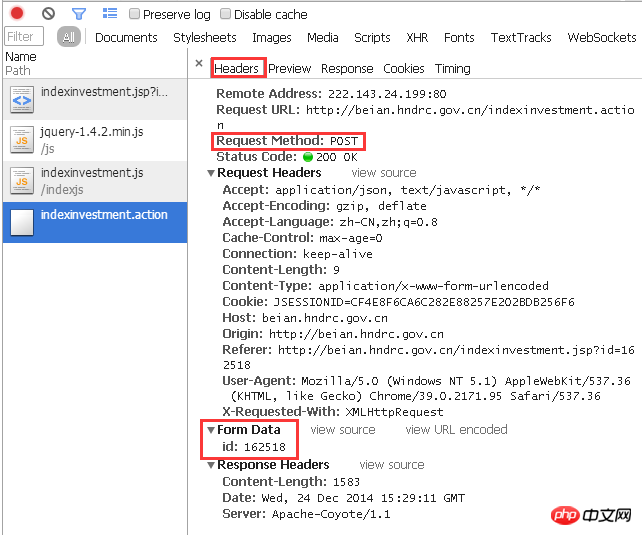
Die Spalte „Header“ zeigt deutlich den Ablauf dieser Antwort:
Für die Ziel-URL Mit POST wird ein Parameter mit der ID 162518 übergeben.
Machen wir es zuerst manuell. Wie ruft js Parameter auf? Ja, wie oben erwähnt: Fragezeichen + Variablenname + Gleichheitszeichen + Nummer, die der Variablen entspricht. Mit anderen Worten: Wenn Sie den Parameter mit der ID 162518 an die Seite „http://beian.hndrc.gov.cn/indexinvestment.action“ übermitteln, sollten Sie nach der URL
“?id=162518“ hinzufügen , nämlich
"http://beian.hndrc.gov.cn/indexinvestment.action?id=162518".
Fügen wir diese URL in den Browser ein, um Folgendes zu sehen:

Es scheint, dass es einige Inhalte gibt, aber alles ist verstümmelt. Wie kann man es unterbrechen? Vertraute Freunde erkennen möglicherweise auf den ersten Blick, dass es sich um ein Codierungsproblem handelt. Dies liegt daran, dass der als Antwort zurückgegebene Inhalt sich von der Standardcodierung des Browsers unterscheidet. Gehen Sie einfach zum Menü in der oberen rechten Ecke von Chrome – Weitere Tools – Codierung – „Automatische Erkennung“. (Eigentlich handelt es sich dabei um die UTF-8-Kodierung und Chrome verwendet standardmäßig vereinfachtes Chinesisch.) Wie unten gezeigt:
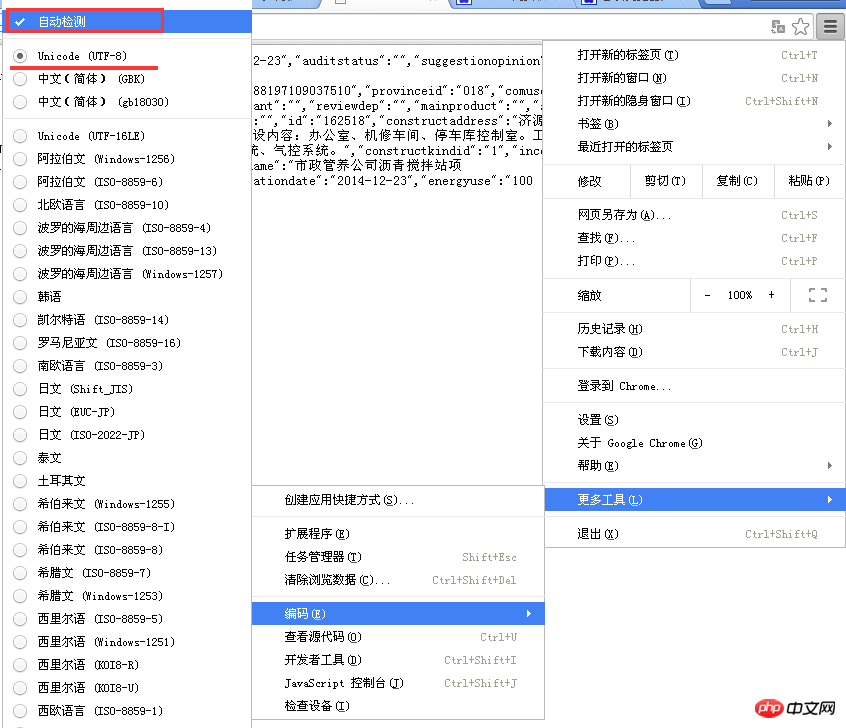
Nun, die eigentliche Informationsquelle wurde ausgegraben. Jetzt müssen wir nur noch Python verwenden, um die Zeichenfolgen auf diesen Seiten zu verarbeiten und dann zu schneiden und zu verbinden ihnen wurde ein neues „Project Filing Document“ neu organisiert.
Verwenden Sie dann for, while und andere Schleifen, um diese „Registrierungsdokumente“ stapelweise abzurufen.
So wie „Ob es sich um eine statische Webseite, eine dynamische Webseite, eine simulierte Anmeldung usw. handelt, müssen Sie zunächst die Logik analysieren und verstehen, bevor Sie den Code schreiben“, ist die Programmiersprache nur ein Werkzeug Wichtig ist die Idee, das Problem zu lösen. Sobald Sie eine Idee haben, können Sie die Tools finden, die Sie zur Lösung benötigen, und schon kann es losgehen.
Das obige ist der detaillierte Inhalt vonBeispiel für die gemeinsame Nutzung eines dynamischen Python-Crawlers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!