
Heim >Backend-Entwicklung >Python-Tutorial >Eine kurze Einführung in Python NLP
Eine kurze Einführung in Python NLP

- 小云云Original
- 2017-12-26 09:16:242506Durchsuche
In diesem Artikel werden hauptsächlich das Einführungs-Tutorial von Python NLP, die Verarbeitung natürlicher Sprache (NLP) in Python und die Verwendung der NLTK-Bibliothek von Python vorgestellt. NLTK ist Pythons Toolkit zur Verarbeitung natürlicher Sprache. Es ist die am häufigsten verwendete Python-Bibliothek im Bereich NLP. Der Herausgeber findet es ziemlich gut, deshalb möchte ich es jetzt mit Ihnen teilen und es als Referenz für alle zur Verfügung stellen. Folgen wir dem Herausgeber und schauen wir uns das an. Ich hoffe, es kann allen helfen.
Was ist NLP?
Einfach ausgedrückt ist Natural Language Processing (NLP) die Entwicklung von Anwendungen oder Diensten, die menschliche Sprache verstehen können.
Hier werden einige praktische Anwendungsbeispiele der Verarbeitung natürlicher Sprache (NLP) besprochen, wie z. B. Spracherkennung, Sprachübersetzung, Verstehen vollständiger Sätze, Verstehen von Synonymen passender Wörter und Generieren grammatikalisch korrekter vollständiger Sätze und Absätze.
Das ist nicht alles, was NLP tun kann.
NLP-Implementierung
Suchmaschinen: wie Google, Yahoo usw. Die Google-Suchmaschine weiß, dass Sie ein Technikfreak sind, und zeigt daher technikbezogene Ergebnisse an.
Social Feed: wie Facebook News Feed. Wenn der Newsfeed-Algorithmus weiß, dass Ihre Interessen an der Verarbeitung natürlicher Sprache liegen, zeigt er relevante Anzeigen und Beiträge an.
Sprachmaschine: wie Apples Siri.
Spam-Filterung: z. B. Google Spam-Filter. Anders als beim gewöhnlichen Spam-Filter wird festgestellt, ob es sich bei einer E-Mail um Spam handelt, indem die tiefere Bedeutung des E-Mail-Inhalts verstanden wird.
NLP-Bibliothek
Im Folgenden sind einige Open-Source-Bibliotheken zur Verarbeitung natürlicher Sprache (NLP) aufgeführt:
Toolkit für natürliche Sprache ( NLTK );
Apache OpenNLP;
Stanford NLP Suite;
Gate NLP-Bibliothek
Unter diesen ist das Natural Language Toolkit (NLTK) die beliebteste Bibliothek zur Verarbeitung natürlicher Sprache (NLP). Sie ist in Python geschrieben und verfügt über eine sehr starke Community-Unterstützung.
Der Einstieg in NLTK ist ebenfalls einfach, es handelt sich tatsächlich um die einfachste NLP-Bibliothek (Natural Language Processing).
In diesem NLP-Tutorial verwenden wir die Python NLTK-Bibliothek.
NLTK installieren
Wenn Sie Windows/Linux/Mac verwenden, können Sie pip verwenden, um NLTK zu installieren:
pip install nltk
Öffnen Sie das Python-Terminal und importieren Sie NLTK, um zu überprüfen, ob NLTK korrekt installiert ist:
import nltk
Wenn alles gut geht, ist es bedeutet, dass Sie die NLTK-Bibliothek erfolgreich installiert haben. Nachdem Sie NLTK zum ersten Mal installiert haben, müssen Sie das NLTK-Erweiterungspaket installieren, indem Sie den folgenden Code ausführen:
import nltk nltk.download()
Dadurch wird der NLTK-Download angezeigt Fenster, um auszuwählen, welche Pakete installiert werden müssen:
Sie können alle Pakete problemlos installieren, da sie klein sind.
Mit Python Text tokenisieren
Zuerst crawlen wir den Inhalt einer Webseite und analysieren dann den Text, um den Inhalt der Seite zu verstehen.
Wir werden das urllib-Modul verwenden, um Webseiten zu crawlen:
import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() print (html)
Wie Sie den gedruckten Ergebnissen entnehmen können, enthalten die Ergebnisse Viele benötigen saubere HTML-Tags.
Dann bereinigt das BeautifulSoup-Modul den Text wie folgt:
from bs4 import BeautifulSoup import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") # 这需要安装html5lib模块 text = soup.get_text(strip=True) print (text)
Jetzt erhalten wir einen Clean-Text.
Im nächsten Schritt wandeln Sie den Text wie folgt in Token um:
from bs4 import BeautifulSoup import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = text.split() print (tokens)
Worthäufigkeit zählen
Der Text wurde verarbeitet. Verwenden Sie nun Python NLTK, um die Häufigkeitsverteilung von Token zu zählen.
kann durch Aufrufen der FreqDist()-Methode in NLTK erreicht werden:
from bs4 import BeautifulSoup import urllib.request import nltk response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = text.split() freq = nltk.FreqDist(tokens) for key,val in freq.items(): print (str(key) + ':' + str(val))
Wenn Sie die Ausgabeergebnisse durchsuchen, können Sie finden Die häufigsten Token sind PHP.
Sie können die Plotfunktion aufrufen, um ein Häufigkeitsverteilungsdiagramm zu erstellen:
freq.plot(20, cumulative=False) # 需要安装matplotlib库
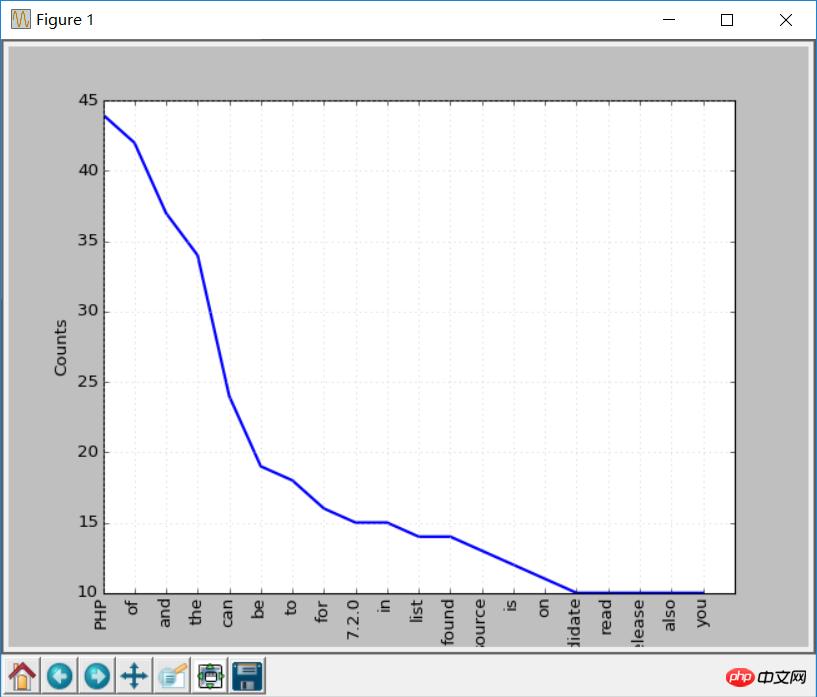
Diese Worte oben. Beispielsweise sind diese Wörter Stoppwörter, a, an usw.
Im Allgemeinen sollten Stoppwörter entfernt werden, um zu verhindern, dass sie die Analyseergebnisse beeinflussen.
Umgang mit Stoppwörtern
NLTK enthält Stoppwortlisten in vielen Sprachen. Wenn Sie englische Stoppwörter erhalten:
from nltk.corpus import stopwords stopwords.words('english')
Ändern Sie nun den Code, um einige ungültige Token vor dem Zeichnen zu löschen:
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if token not in sr:
clean_tokens.append(token) Der endgültige Code sollte so aussehen :
from bs4 import BeautifulSoup
import urllib.request
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = text.split()
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if not token in sr:
clean_tokens.append(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val)) Machen Sie nun noch einmal die Worthäufigkeitstabelle, der Effekt wird besser sein als zuvor, da Stoppwörter eliminiert wurden:
freq.plot(20,cumulative=False)
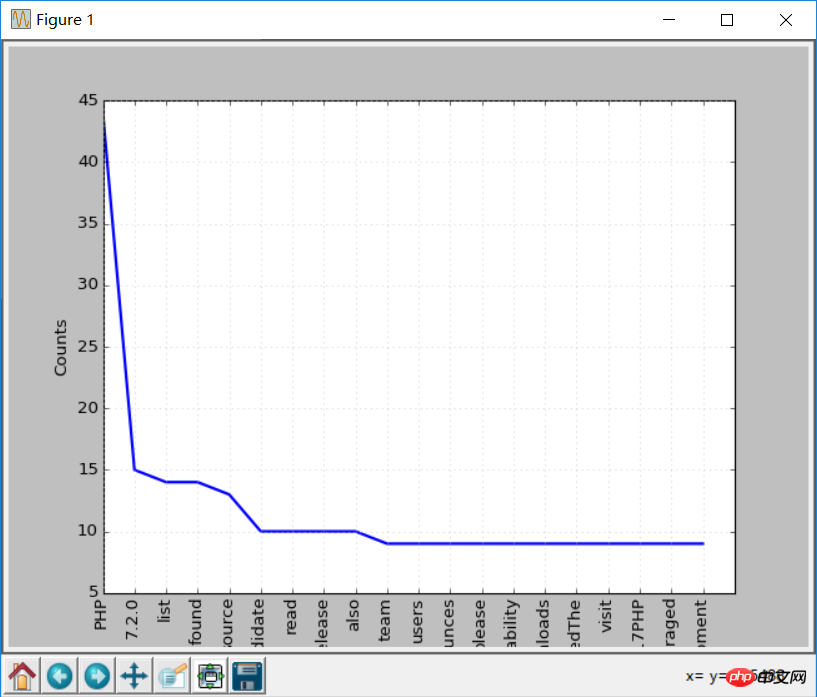
Verwendung von NLTK-Tokenisieren von Text
Vor der Verwendung der Split-Methode wird der Text geteilt Jetzt verwenden wir NLTK, um den Text zu tokenisieren.
Text kann nicht ohne Tokenisierung verarbeitet werden, daher ist es sehr wichtig, den Text zu tokenisieren. Der Prozess der Tokenisierung bedeutet die Aufteilung großer Teile in kleinere Teile.
你可以将段落tokenize成句子,将句子tokenize成单个词,NLTK分别提供了句子tokenizer和单词tokenizer。
假如有这样这段文本:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
使用句子tokenizer将文本tokenize成句子:
from nltk.tokenize import sent_tokenize mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))
输出如下:
['Hello Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
这是你可能会想,这也太简单了,不需要使用NLTK的tokenizer都可以,直接使用正则表达式来拆分句子就行,因为每个句子都有标点和空格。
那么再来看下面的文本:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
这样如果使用标点符号拆分,Hello Mr将会被认为是一个句子,如果使用NLTK:
from nltk.tokenize import sent_tokenize mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))
输出如下:
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
这才是正确的拆分。
接下来试试单词tokenizer:
from nltk.tokenize import word_tokenize mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(word_tokenize(mytext))
输出如下:
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going', 'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']
Mr.这个词也没有被分开。NLTK使用的是punkt模块的PunktSentenceTokenizer,它是NLTK.tokenize的一部分。而且这个tokenizer经过训练,可以适用于多种语言。
非英文Tokenize
Tokenize时可以指定语言:
from nltk.tokenize import sent_tokenize mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour." print(sent_tokenize(mytext,"french"))
输出结果如下:
['Bonjour M. Adam, comment allez-vous?', "J'espère que tout va bien.", "Aujourd'hui est un bon jour."]
同义词处理
使用nltk.download()安装界面,其中一个包是WordNet。
WordNet是一个为自然语言处理而建立的数据库。它包括一些同义词组和一些简短的定义。
您可以这样获取某个给定单词的定义和示例:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain")
print(syn[0].definition())
print(syn[0].examples())输出结果是:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']
WordNet包含了很多定义:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP")
print(syn[0].definition())
syn = wordnet.synsets("Python")
print(syn[0].definition())结果如下:
the branch of information science that deals with natural language information
large Old World boas
可以像这样使用WordNet来获取同义词:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)输出:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
反义词处理
也可以用同样的方法得到反义词:
from nltk.corpus import wordnet
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)输出:
['large', 'big', 'big']
词干提取
语言形态学和信息检索里,词干提取是去除词缀得到词根的过程,例如working的词干为work。
搜索引擎在索引页面时就会使用这种技术,所以很多人为相同的单词写出不同的版本。
有很多种算法可以避免这种情况,最常见的是波特词干算法。NLTK有一个名为PorterStemmer的类,就是这个算法的实现:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem('working')) print(stemmer.stem('worked'))
输出结果是:
work
work
还有其他的一些词干提取算法,比如 Lancaster词干算法。
非英文词干提取
除了英文之外,SnowballStemmer还支持13种语言。
支持的语言:
from nltk.stem import SnowballStemmer print(SnowballStemmer.languages) 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'
你可以使用SnowballStemmer类的stem函数来提取像这样的非英文单词:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("French word"))单词变体还原
单词变体还原类似于词干,但不同的是,变体还原的结果是一个真实的单词。不同于词干,当你试图提取某些词时,它会产生类似的词:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem('increases'))
结果:
increas
现在,如果用NLTK的WordNet来对同一个单词进行变体还原,才是正确的结果:
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('increases'))
结果:
increase
结果可能会是一个同义词或同一个意思的不同单词。
有时候将一个单词做变体还原时,总是得到相同的词。
这是因为语言的默认部分是名词。要得到动词,可以这样指定:
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('playing', pos="v"))
结果:
play
实际上,这也是一种很好的文本压缩方式,最终得到文本只有原先的50%到60%。
结果还可以是动词(v)、名词(n)、形容词(a)或副词(r):
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))输出:
play
playing
playing
playing
词干和变体的区别
通过下面例子来观察:
from nltk.stem import WordNetLemmatizer from nltk.stem import PorterStemmer stemmer = PorterStemmer() lemmatizer = WordNetLemmatizer() print(stemmer.stem('stones')) print(stemmer.stem('speaking')) print(stemmer.stem('bedroom')) print(stemmer.stem('jokes')) print(stemmer.stem('lisa')) print(stemmer.stem('purple')) print('----------------------') print(lemmatizer.lemmatize('stones')) print(lemmatizer.lemmatize('speaking')) print(lemmatizer.lemmatize('bedroom')) print(lemmatizer.lemmatize('jokes')) print(lemmatizer.lemmatize('lisa')) print(lemmatizer.lemmatize('purple'))
输出:
stone
speak
bedroom
joke
lisa
purpl
---------------------
stone
speaking
bedroom
joke
lisa
purple
词干提取不会考虑语境,这也是为什么词干提取比变体还原快且准确度低的原因。
个人认为,变体还原比词干提取更好。单词变体还原返回一个真实的单词,即使它不是同一个单词,也是同义词,但至少它是一个真实存在的单词。
如果你只关心速度,不在意准确度,这时你可以选用词干提取。
在此NLP教程中讨论的所有步骤都只是文本预处理。在以后的文章中,将会使用Python NLTK来实现文本分析。
相关推荐:
Das obige ist der detaillierte Inhalt vonEine kurze Einführung in Python NLP. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!