
Heim >Backend-Entwicklung >Python-Tutorial >Zusammenfassung von acht Sortieralgorithmen in Python (Teil 2)
Zusammenfassung von acht Sortieralgorithmen in Python (Teil 2)
- 巴扎黑Original
- 2017-09-16 10:14:441641Durchsuche
Dieser Artikel stellt hauptsächlich den zweiten Teil von acht in Python implementierten Sortieralgorithmen vor. Er hat einen bestimmten Referenzwert.
Dieser Artikel ist eine Fortsetzung des vorherigen Python-Blogs Die acht implementierten Sortieralgorithmen verwenden weiterhin Python, um die verbleibenden vier der acht Sortieralgorithmen zu implementieren: schnelle Sortierung, Heap-Sortierung, Zusammenführungssortierung, Radix-Sortierung
5, schnelle Sortierung
Schnellsortierung gilt im Allgemeinen als die Methode mit der besten durchschnittlichen Leistung unter den Sortiermethoden derselben Größenordnung (O(nlog2n)).
Algorithmusidee:
Wir kennen einen Satz ungeordneter Daten a[1], a[2],...a[n], die in aufsteigender Reihenfolge angeordnet werden müssen. Zunächst werden alle Daten a[x] als Benchmark verwendet. Vergleichen Sie a[x] mit anderen Daten und sortieren Sie es so, dass a[x] an der k-ten Position der Daten steht, und machen Sie alle Daten in a[1]~a[k-1] a[x] und dann die Divide-and-Conquer-Strategie verwenden, um a[1]~a[k-1] bzw. a[k+1]~a zu erhalten [n]Sortieren Sie schnell zwei Datensätze.
Vorteile: extrem schnell, weniger Datenbewegung;
Nachteile: instabil.
Python-Code-Implementierung:
def quick_sort(list):
little = []
pivotList = []
large = []
# 递归出口
if len(list) <= 1:
return list
else:
# 将第一个值做为基准
pivot = list[0]
for i in list:
# 将比基准小的值放到less数列
if i < pivot:
little.append(i)
# 将比基准大的值放到more数列
elif i > pivot:
large.append(i)
# 将和基准相同的值保存在基准数列
else:
pivotList.append(i)
# 对less数列和more数列继续进行快速排序
little = quick_sort(little)
large = quick_sort(large)
return little + pivotList + largeDer folgende Code stammt aus den drei Zeilen von „Python Cookbook Second Edition“, um die Python-Schnellsortierung zu implementieren.
#!/usr/bin/env python
#coding:utf-8
'''
file:python-8sort.py
date:9/1/17 9:03 AM
author:lockey
email:lockey@123.com
desc:python实现八大排序算法
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def quick_sort(list):
if len(list) <= 1:
return list
else:
pivot = list[0]
return quick_sort([x for x in list[1:] if x < pivot]) + \
[pivot] + \
quick_sort([x for x in list[1:] if x >= pivot])Screenshot der laufenden Testergebnisse:
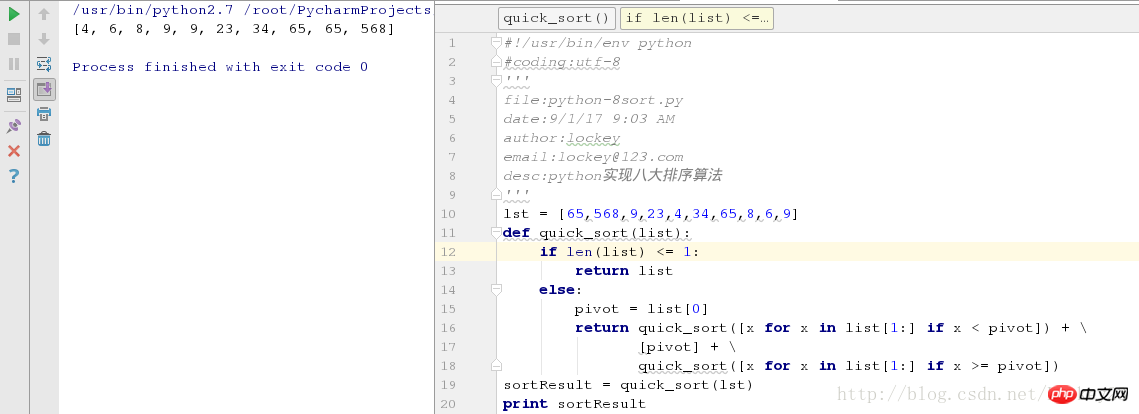
Okay, es gibt einen optimierteren syntaktischen Zucker, eine Zeile Fertig:
quick_sort = lambda xs : ( (len(xs) = xs[0]] ) ] )[0]
Wenn die Anfangssequenz nach Schlüssel oder grundsätzlich geordnet ist, degeneriert die Schnellsortierung zur Blasensortierung. Um es zu verbessern, wird normalerweise die „Drei-in-Eins-Methode“ zur Auswahl des Benchmark-Datensatzes verwendet, dh die drei Datensatzschlüssel, die auf den beiden Endpunkten zentriert sind, und der Mittelpunkt des Sortierintervalls werden als Drehpunktdatensatz angepasst. Quicksort ist eine instabile Sortiermethode.
Im verbesserten Algorithmus rufen wir die Schnellsortierung rekursiv nur für Teilsequenzen mit einer Länge größer als k auf, um die ursprüngliche Sequenz grundsätzlich zu ordnen, und verwenden dann den Einfügungssortierungsalgorithmus, um die gesamte grundlegende geordnete Sequenz zu sortieren. Die Praxis hat gezeigt, dass die zeitliche Komplexität des verbesserten Algorithmus verringert wurde und der verbesserte Algorithmus die beste Leistung aufweist, wenn der Wert von k etwa 8 beträgt.
6. Heap-Sortierung
Heap-Sortierung ist eine Baumauswahlsortierung, die eine wirksame Verbesserung gegenüber der Direktauswahlsortierung darstellt.
Vorteile: Hohe Effizienz
Nachteile: Instabilität
Unter der Definition von Heap: eine Folge von n Elementen (h1, h2,...,hn), wenn Und Es wird nur aufgerufen, wenn es (hi>=h2i,hi>=2i+1) oder (hi
Algorithmusidee:
Zunächst wird die zu sortierende Zahlenfolge als sequentiell gespeicherter Binärbaum betrachtet und ihre Speicherreihenfolge so angepasst, dass daraus ein Heap entsteht Die Anzahl der Wurzelknoten im Heap ist am größten. Tauschen Sie dann den Wurzelknoten mit dem letzten Knoten des Heaps aus. Passen Sie dann die vorherigen (n-1) Zahlen erneut an, um einen Heap zu bilden. Und so weiter, bis es einen Heap mit nur zwei Knoten gibt, diese ausgetauscht werden und schließlich eine geordnete Folge von n Knoten erhalten wird. Aus der Beschreibung des Algorithmus geht hervor, dass die Heap-Sortierung zwei Prozesse erfordert: Der erste besteht darin, den Heap einzurichten, und der andere besteht darin, Positionen zwischen der Oberseite des Heaps und dem letzten Element des Heaps auszutauschen. Die Heap-Sortierung besteht also aus zwei Funktionen. Eine davon ist die Penetrationsfunktion zum Aufbau des Heaps, die andere ist die Funktion zum wiederholten Aufrufen der Penetrationsfunktion zur Implementierung der Sortierung.
Python-Code-Implementierung:
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def adjust_heap(lists, i, size):# 调整堆
lchild = 2 * i + 1;rchild = 2 * i + 2
max = i
if i < size / 2:
if lchild < size and lists[lchild] > lists[max]:
max = lchild
if rchild < size and lists[rchild] > lists[max]:
max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max]
adjust_heap(lists, max, size)
def build_heap(lists, size):# 创建堆
halfsize = int(size/2)
for i in range(0, halfsize)[::-1]:
adjust_heap(lists, i, size)
def heap_sort(lists):# 堆排序
size = len(lists)
build_heap(lists, size)
for i in range(0, size)[::-1]:
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)
print(lists)Ergebnisbeispiel:

7. Zusammenführungssortierung
Algorithmusidee:
Zusammenführungssortierung ist ein effektiver Sortieralgorithmus, der auf der Zusammenführungsoperation basiert. Eine sehr typische Anwendung. Führen Sie die bereits geordneten Teilsequenzen zusammen, um eine vollständig geordnete Sequenz zu erhalten. Ordnen Sie also zuerst jede Teilsequenz und dann die Teilsequenzsegmente. Wenn zwei geordnete Listen zu einer geordneten Liste zusammengeführt werden, spricht man von einer bidirektionalen Zusammenführung.
Der Zusammenführungsprozess ist: Vergleichen Sie die Größen von a[i] und a[j], wenn a[i]≤a[j], kopieren Sie das Element a[i] in der ersten geordneten Liste nach r [k] und addiere 1 zu i bzw. k; andernfalls kopiere das Element a[j] in der zweiten geordneten Liste nach r[k] und addiere 1 zu j bzw. k. Dieser Zyklus wird fortgesetzt, bis eines der geordneten Listen werden abgerufen, und dann werden die verbleibenden Elemente in der anderen geordneten Liste in die Zellen in r vom Index k bis zum Index t kopiert. Normalerweise verwenden wir Rekursion, um den Zusammenführungssortierungsalgorithmus zu implementieren. Zuerst wird das zu sortierende Intervall [s, t] durch den Mittelpunkt in zwei Teile geteilt, dann wird der linke Teilbereich sortiert, dann wird der rechte Teilbereich sortiert Schließlich werden das linke Intervall und das rechte Intervall zu geordneten Intervallen [s,t] zusammengeführt.
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def merge(left, right):
i, j = 0, 0
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
print(result)
return result
def merge_sort(lists):# 归并排序
if len(lists) <= 1:
return lists
num = int(len(lists) / 2)
left = merge_sort(lists[:num])
right = merge_sort(lists[num:])
return merge(left, right)Beispiel für Programmergebnisse:

8、桶排序/基数排序(Radix Sort)
优点:快,效率最好能达到O(1)
缺点:
1.首先是空间复杂度比较高,需要的额外开销大。排序有两个数组的空间开销,一个存放待排序数组,一个就是所谓的桶,比如待排序值是从0到m-1,那就需要m个桶,这个桶数组就要至少m个空间。
2.其次待排序的元素都要在一定的范围内等等。
算法思想:
是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。
简单来说,就是把数据分组,放在一个个的桶中,然后对每个桶里面的在进行排序。
例如要对大小为[1..1000]范围内的n个整数A[1..n]排序
首先,可以把桶大小设为10,这样就有100个桶了,具体而言,设集合B[1]存储[1..10]的整数,集合B[2]存储 (10..20]的整数,……集合B[i]存储( (i-1)*10, i*10]的整数,i = 1,2,..100。总共有 100个桶。
然后,对A[1..n]从头到尾扫描一遍,把每个A[i]放入对应的桶B[j]中。 再对这100个桶中每个桶里的数字排序,这时可用冒泡,选择,乃至快排,一般来说任 何排序法都可以。
最后,依次输出每个桶里面的数字,且每个桶中的数字从小到大输出,这 样就得到所有数字排好序的一个序列了。
假设有n个数字,有m个桶,如果数字是平均分布的,则每个桶里面平均有n/m个数字。如果
对每个桶中的数字采用快速排序,那么整个算法的复杂度是
O(n + m * n/m*log(n/m)) = O(n + nlogn - nlogm)
从上式看出,当m接近n的时候,桶排序复杂度接近O(n)
当然,以上复杂度的计算是基于输入的n个数字是平均分布这个假设的。这个假设是很强的 ,实际应用中效果并没有这么好。如果所有的数字都落在同一个桶中,那就退化成一般的排序了。
python代码实现:
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
import math
lst = [65,56,9,23,84,34,8,6,9,54,11]
#因为列表数据范围在100以内,所以将使用十个桶来进行排序
def radix_sort(lists, radix=10):
k = int(math.ceil(math.log(max(lists), radix)))
bucket = [[] for i in range(radix)]
for i in range(1, k+1):
for j in lists:
gg = int(j/(radix**(i-1))) % (radix**i)
bucket[gg].append(j)
del lists[:]
for z in bucket:
lists += z
del z[:]
print(lists)
return lists程序运行测试结果:
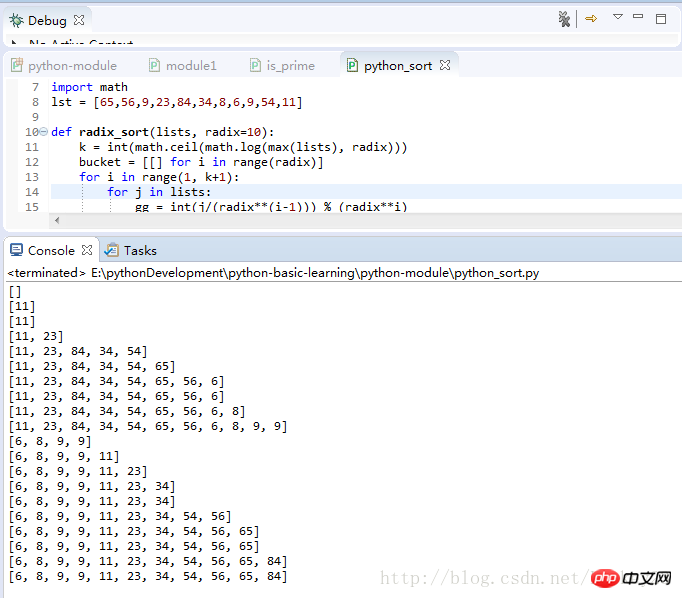
Das obige ist der detaillierte Inhalt vonZusammenfassung von acht Sortieralgorithmen in Python (Teil 2). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!