
Heim >Backend-Entwicklung >Python-Tutorial >Python lernt, Blogpark-Neuigkeiten zu erfassen
Python lernt, Blogpark-Neuigkeiten zu erfassen

- PHP中文网Original
- 2017-06-20 15:23:221789Durchsuche
前言
说到python,对它有点耳闻的人,第一反应可能都是爬虫~
这两天看了点python的皮毛知识,忍不住想写一个简单的爬虫练练手,JUST DO IT
准备工作
要制作数据抓取的爬虫,对请求的源页面结构需要有特定分析,只有分析正确了,才能更好更快的爬到我们想要的内容。
浏览器访问570973/,右键“查看源代码”,初步只想取一些简单的数据(文章标题、作者、发布时间等),在HTML源码中找到相关数据的部分:
1)标题(url):
2) Autor: Poster itwriter
3) Veröffentlichungszeit: Veröffentlicht am 2017-06-06 14:53
4) Aktuelle Nachrichten-ID:
Wenn Sie dem Beispiel folgen möchten, ist die Struktur der Links „Vorheriger Artikel“ und „Nächster Artikel“ sehr wichtig. Die beiden Tags Inhalt wird über js gerendert, was soll ich tun? Versuchen Sie, Informationen zu finden (Python führt js und dergleichen aus), aber für Python-Neulinge ist es möglicherweise etwas voraus und ich habe vor, eine andere Lösung zu finden.
Obwohl diese beiden Links über js gerendert werden, sollte der Grund, warum js den Inhalt rendern kann, darin bestehen, eine Anfrage zu initiieren und die Antwort zu erhalten. Ist es dann möglich, die Webseite zu überwachen? Ladevorgang, um zu sehen, welche nützlichen Informationen vorhanden sind? Ich möchte ein Lob dafür aussprechen, dass Browser wie Chrome/Firefox Developer Tools/Network den Anforderungs- und Antwortstatus aller Ressourcen klar sehen können.

Ihre Anfrageadressen sind:
1) Vorherige Nachrichten-ID:
2) Nächste Nachrichten-ID:
Der Inhalt der Antwort ist JSON
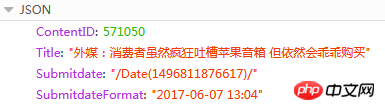
Hier ist ContentID das, was wir brauchen, um den vorherigen oder nächsten Artikel der aktuellen Nachrichten-URL zu erkennen Die Seitenadresse von Pressemitteilungen hat ein festes Format: {{ContentID}}/ (Der rote Inhalt ist die austauschbare ID)
Tools
1) Python 3.6 (gleichzeitig Pip installieren und Umgebungsvariablen hinzufügen)
2) PyCharm 2017.1.3
3) Python-Bibliothek eines Drittanbieters (Installation: cmd -> pip-Installationsname)
a) Pyperclip: wird zum Lesen und Schreiben der Zwischenablage verwendet
b) Anfragen: eine HTTP-Bibliothek, die auf urllib basiert und das Apache2-lizenzierte Open-Source-Protokoll verwendet. Es ist praktischer als urllib und kann uns viel Arbeit ersparen
c) beautifulsoup4: Beautiful Soup bietet einige einfache Funktionen im Python-Stil für die Navigation, Suche, Änderung von Analysebäumen, usw. Funktion. Es handelt sich um eine Toolbox, die Benutzern die Daten bereitstellt, die sie zum Crawlen benötigen, indem sie Dokumente
Quellcode
Ich persönlich finde die Codes sehr einfach und leicht zu verstehen (Neulinge können schließlich keinen fortgeschrittenen Code schreiben. Wenn Sie Fragen oder Anregungen haben, lassen Sie es mich bitte wissen
Führen Sie
aus. Speichern Sie den obigen Quellcode unter D:/get_cnblogs_news.py unter den Fenstern Plattform Öffnen Sie das Befehlszeilentool cmd:
Geben Sie den Befehl ein: py.exe D:/get_cnblogs_news.py Geben Sie
ein. Analyse: py.exe muss nicht erklärt werden, der zweite Parameter ist Python Skriptdatei, der dritte Parameter ist die Quellseite, die gecrawlt werden muss (im Code gibt es noch eine weitere Überlegung. Wenn Sie diese URL in die Systemzwischenablage kopieren, können Sie sie direkt ausführen: py.exe D:/get_cnblogs_news.py
Befehlszeilen-Ausgabeschnittstelle (Drucken)
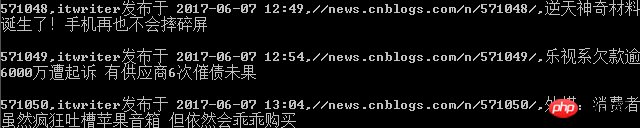
Inhalt in CSV-Datei gespeichert

Empfohlene Python-Lernbuchbox oder Materialien für Anfänger:
1) Liao Xuefengs Python-Tutorial, sehr einfach und leicht zu verstehen:
2 ) Beginnen Sie schnell mit der Python-Programmierung, um mühsame Arbeit zu automatisieren.pdf
Der Artikel ist nur ein Tagebuch für mich selbst, um Python zu lernen. Bitte kritisieren und korrigieren Sie es, wenn es irreführend ist (nein, bitte nicht sprühen). Es wäre mir eine Ehre, wenn es Ihnen helfen würde.
Das obige ist der detaillierte Inhalt vonPython lernt, Blogpark-Neuigkeiten zu erfassen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!