
Heim >Java >javaLernprogramm >Detaillierte Analyse des Quellcodes der Java-Sammlungsframeworks HashSet und HashMap (Bild)
Detaillierte Analyse des Quellcodes der Java-Sammlungsframeworks HashSet und HashMap (Bild)

- 黄舟Original
- 2017-03-28 11:00:381712Durchsuche
Allgemeine Einführung
Der Grund, warum HashSet und HashMap zusammen erklärt werden, liegt darin, dass sie dieselbe Implementierung in Java haben und Ersteres nur für Letzteres gilt ist eine Verpackungsschicht, was bedeutet, dass HashSet eine HashMap (Adaptermodus) enthält. Daher konzentriert sich dieser Artikel auf die Analyse von HashMap.
HashMap implementiert die Map-Schnittstelle, sodass null-Elemente platziert werden können, außer dass diese Klasse keine Synchronisierung implementiert, der Rest ist ungefähr derselbe wie Hashtable und TreeMap garantiert dieser Container nicht die Reihenfolge der Elemente. Der Container kann die Elemente nach Bedarf erneut hashen, und die Reihenfolge der Elemente wird ebenfalls neu gemischt, also das Gleiche 🎜>HashMap wird zu unterschiedlichen Zeiten iteriert. Die Reihenfolge kann variieren. Je nach unterschiedlicher Art der Konfliktbehandlung gibt es zwei Möglichkeiten, Hash-Tabellen zu implementieren: Eine ist die offene Adressierungsmethode (Offene Adressierung) und die andere ist die Konflikt-Linked-List-Methode (Separate Verkettung mit verknüpftem
s). Java HashMap verwendet die Konflikt-Linked-List-Methode .
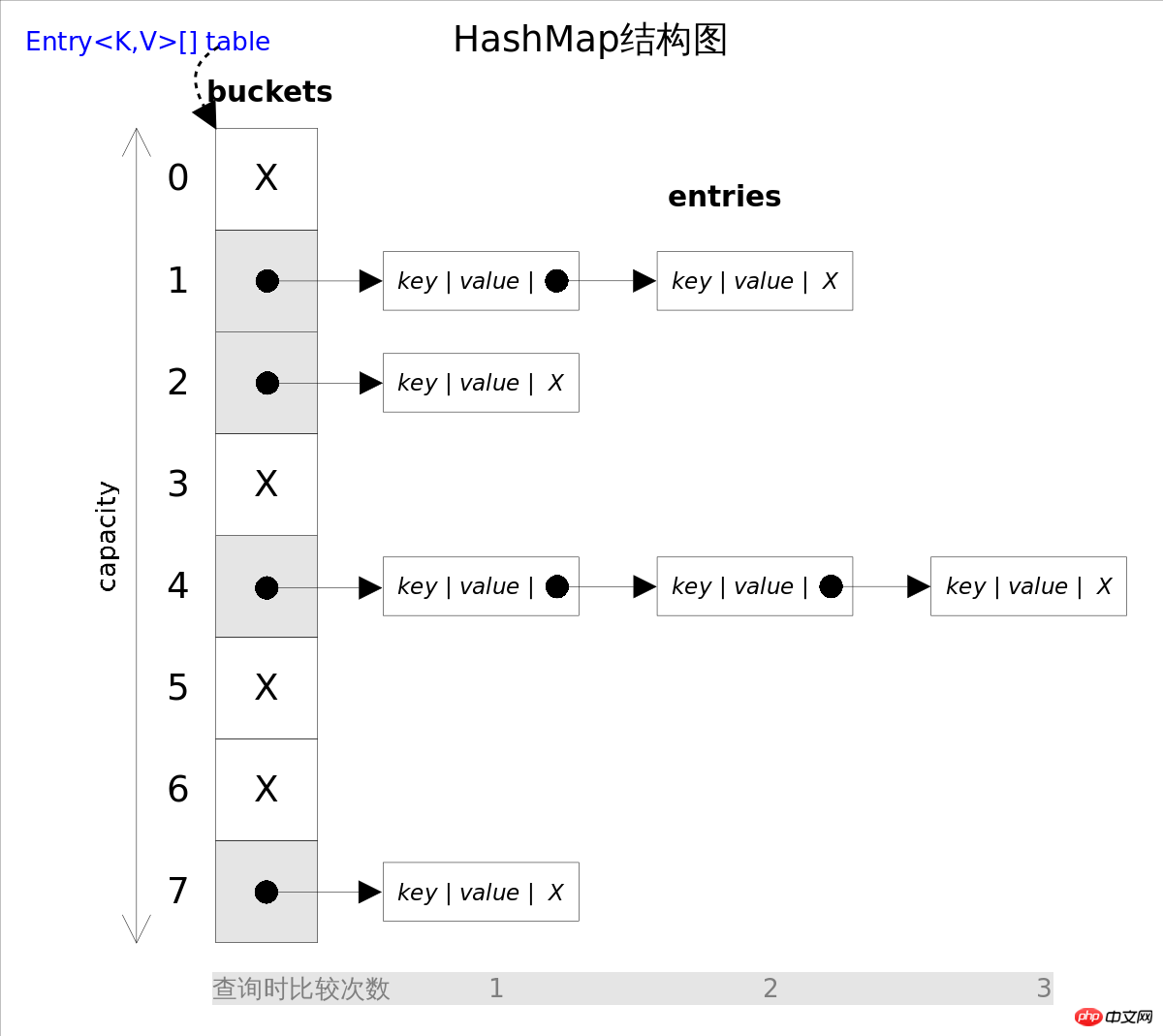 Aus der obigen Abbildung ist leicht ersichtlich, dass die Methoden
Aus der obigen Abbildung ist leicht ersichtlich, dass die Methoden
verwendet werden können, wenn Sie die entsprechende Hashing--Funktion auswählen in konstanter Zeit abgeschlossen. Wenn Sie jedoch über put()HashMapget() iterieren, müssen Sie die gesamte Tabelle und die folgende verknüpfte Konfliktliste durchlaufen. Daher ist es für Szenarien mit häufigen Iterationen nicht angebracht, die Anfangsgröße von HashMap zu groß festzulegen. hat zwei Parameter, die sich auf die Leistung von
auswirken können: Anfangskapazität und Auslastungsfaktor. Die Anfangskapazität gibt die Anfangsgröße von an und der Lastfaktor wird verwendet, um den kritischen Wert für die automatische Erweiterung anzugeben. Wenn die Anzahl von table überschreitet, wird der Container automatisch erweitert und erneut gehasht. In Szenarien, in denen eine große Anzahl von Elementen eingefügt wird, kann das Festlegen einer größeren Anfangskapazität die Anzahl der erneuten Aufbereitungen verringern. Wenn entrycapacity*load_factor in
oder HashSet eingefügt wird, gibt es zwei Methoden, die besondere Aufmerksamkeit erfordern: und . Die hashCode()equals()-Methode bestimmt, in welchem das hashCode()-Objekt platziert wird. Wenn die Hashwerte mehrerer Objekte in Konflikt geraten, bestimmt die -Methode, ob diese Objekte „gleich“ sind eins". Objekt“bucket. Wenn Sie also ein benutzerdefiniertes Objekt in equals() oder einfügen möchten, benötigen Sie die @Override-Methoden HashMap und HashSet. hashCode()equals()Methodenanalyse
get()
get(
Object
-Algorithmus besteht darin, zuerst den hash() entsprechenden Index über die Funktion bucket zu erhalten, dann die konfliktverknüpfte Liste nacheinander zu durchlaufen und mithilfe der key.equals(k)-Methode zu bestimmen, ob Es ist das entry, das Sie suchen.
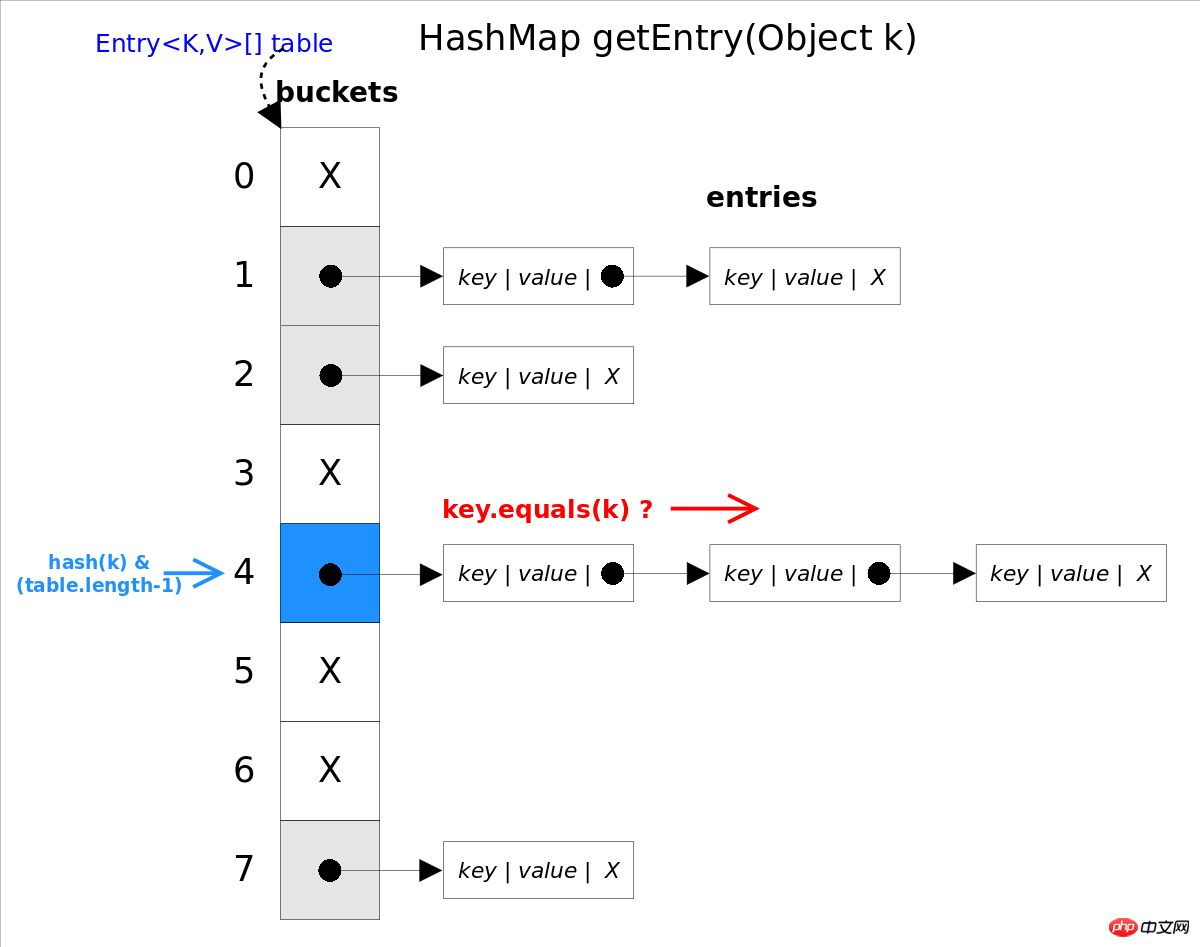
In der obigen Abbildung entspricht hash(k)&(table.length-1) hash(k)%table.length. Der Grund dafür ist, dass HashMap erfordert, dass table.length ein Exponent sein muss von 2, also table.length-1Das heißt, die niederwertigen Bits des Binärsystems sind alle 1. Das UND mit hash(k) löscht alle höherwertigen Bits des Hash-Werts und der Rest ist der Rest. Die Methode
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[hash&(table.length-1)];//得到冲突链表
e != null; e = e.next) {//依次遍历冲突链表中的每个entry
Object k;
//依据equals()方法判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}put()
put(K key, V value) fügt das angegebene key, value-Paar zu map hinzu. Diese Methode sucht zunächst nach map, um zu sehen, ob es das Tupel enthält. Der Suchvorgang ähnelt der Methode getEntry(), wenn es nicht gefunden wird Eingefügt durch die addEntry(int hash, K key, V value, int bucketIndex)-Methode 🎜>, die Einfügemethode ist entry Kopfeinfügungsmethode .
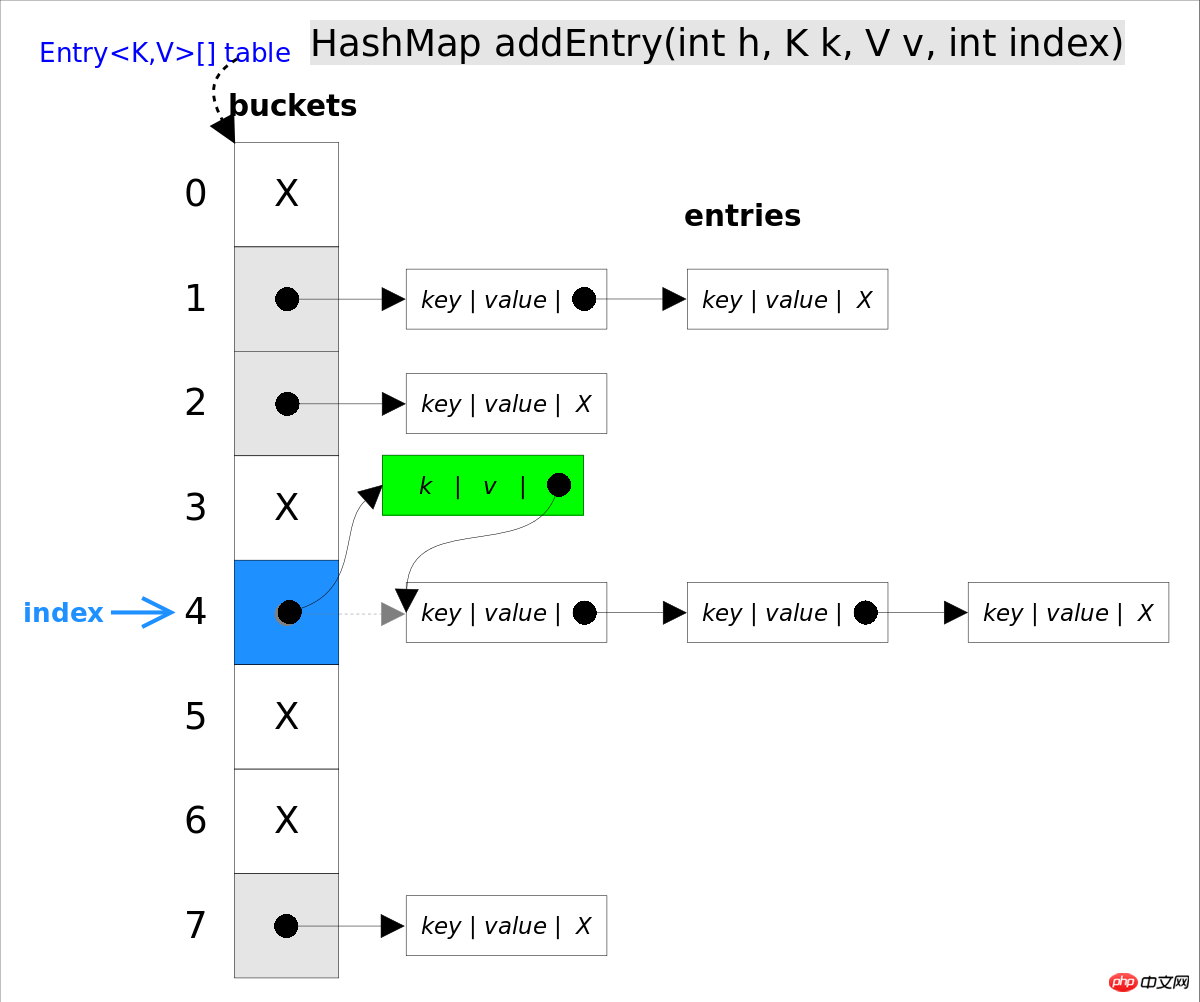
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}remove()
wird verwendet, um den remove(Object key) entsprechend dem key-Wert zu löschen Diese Methode ist in entry implementiert. Die removeEntryForKey(Object key)-Methode findet zuerst das removeEntryForKey(), das dem key-Wert entspricht, und löscht dann das entry (ändert den entsprechenden Zeiger der verknüpften Liste). Der Suchvorgang ähnelt dem entry-Vorgang. getEntry()

//removeEntryForKey()
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);//hash&(table.length-1)
Entry<K,V> prev = table[i];//得到冲突链表
Entry<K,V> e = prev;
while (e != null) {//遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {//找到要删除的entry
modCount++; size--;
if (prev == e) table[i] = next;//删除的是冲突链表的第一个entry
else prev.next = next;
return e;
}
prev = e; e = next;
}
return e;
}HashSet
前面已经说过HashSet是对HashMap的简单包装,对HashSet的函数调用都会转换成合适的HashMap方法,因此HashSet的实现非常简单,只有不到300行代码。这里不再赘述。
//HashSet是对HashMap的简单包装
public class HashSet<E>
{
......
private transient HashMap<E,Object> map;//HashSet里面有一个HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}Das obige ist der detaillierte Inhalt vonDetaillierte Analyse des Quellcodes der Java-Sammlungsframeworks HashSet und HashMap (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie kann ich eine WAR-Datei bereitstellen und darauf zugreifen, nachdem ich sie im Webapps-Verzeichnis von Tomcat 7 abgelegt habe?
- Warum wirft GSON beim Parsen von JSON „Erwartetes BEGIN_OBJECT, war aber BEGIN_ARRAY' aus?
- Warum gibt „getResourceAsStream' beim Zugriff auf Ressourcen in einer JAR Null zurück und wie kann ich das Problem beheben?
- Wie analysiere ich Doubles mit Komma als Dezimaltrennzeichen in Java?
- Wie kann ich Java-Objekte basierend auf mehreren Feldern effizient vergleichen?