
Heim >Java >javaLernprogramm >Detaillierte Erläuterung der Quellcodeanalyse des Java-Sammlungsframeworks LinkedHashSet und LinkedHashMap (Bild)
Detaillierte Erläuterung der Quellcodeanalyse des Java-Sammlungsframeworks LinkedHashSet und LinkedHashMap (Bild)

- 黄舟Original
- 2017-03-28 10:57:302879Durchsuche
Allgemeine Einführung
Wenn Sie die vorherigen Artikel über HashSet und HashMap sowie TreeSet und TreeMap gelesen haben Zur Erklärung müssen Sie sich vorstellen können, dass LinkedHashSet und LinkedHashMap, die in diesem Artikel erklärt werden, tatsächlich dasselbe sind. LinkedHashSet und LinkedHashMap haben auch die gleiche Implementierung in Java. Ersteres schließt letzteres nur ein, d. h. innerhalb von LinkedHashSet gibt es ein LinkedHashMap (Adaptermuster) . Daher konzentriert sich dieser Artikel auf die Analyse von LinkedHashMap.
LinkedHashMap implementiert die Map-Schnittstelle, die das Einfügen von Elementen mit key als null und das Einfügen von Elementen mit value als null ermöglicht eingefügt werden. Wie aus dem Namen hervorgeht, ist der Container eine Mischung aus linked list und HashMap, was bedeutet, dass er beide HashMap erfüllt und
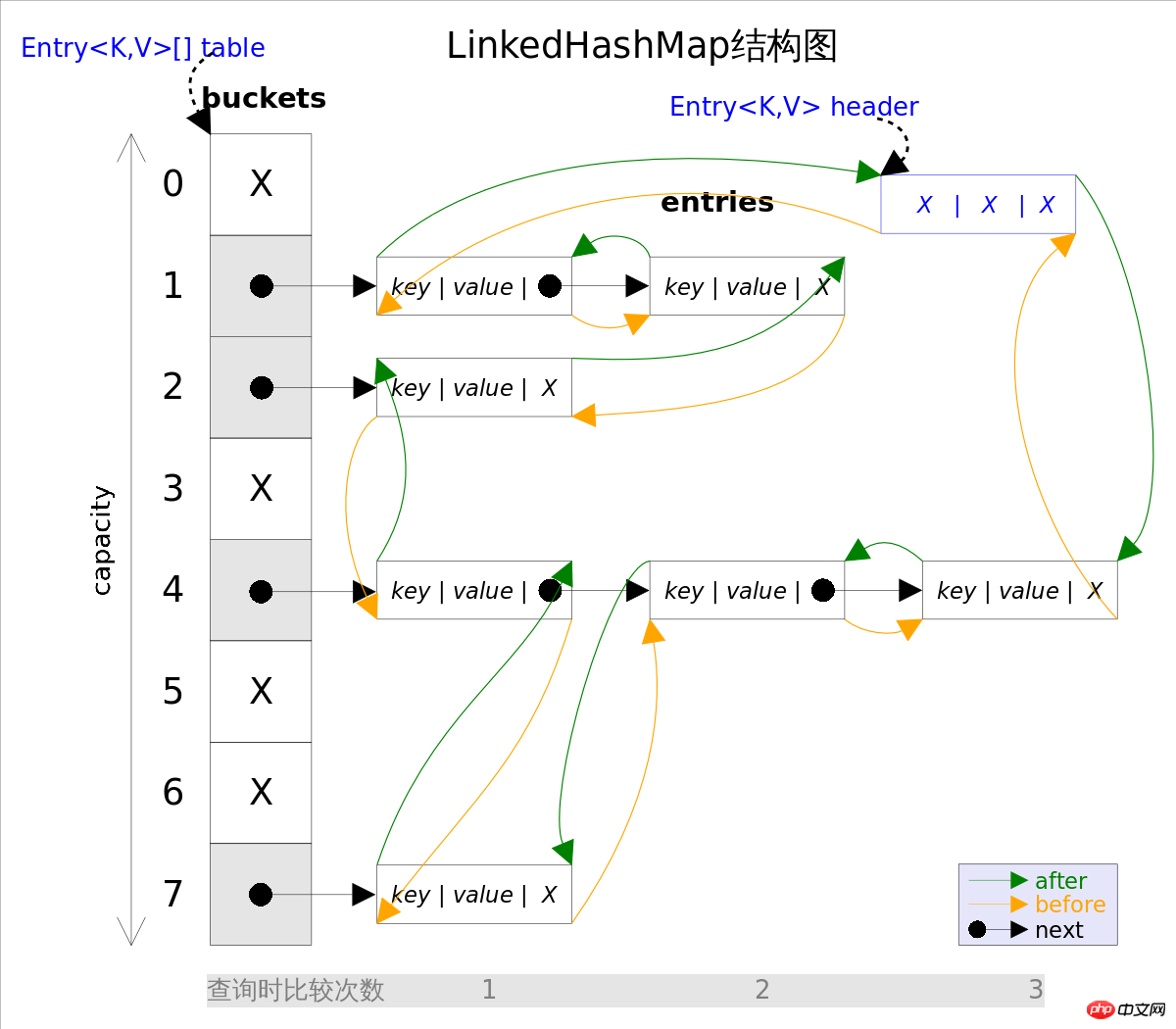
LinkedHashMap eine direkte Unterklasse von HashMap, der einzige Unterschied zwischen den beiden isLinkedHashMap basiert auf HashMap und verwendet eine doppelt verknüpfte Liste, um alle s zu verbinden. Dadurch soll sichergestellt werden, dass die Iterationsreihenfolge der Elemente mit der Einfügereihenfolge übereinstimmt entry. Die obige Abbildung zeigt das Strukturdiagramm von LinkedHashMap. Der Hauptteil ist genau derselbe wie HashMap, mit dem Zusatz , der auf den Kopf der doppelt verknüpften Liste zeigt (was ist ein Dummy-Element) und header Die Iterationsreihenfolge der doppelt verknüpften Liste ist die Einfügereihenfolge von entry.
Die Iteration von LinkedHashMap erfordert nicht das Durchlaufen der gesamten wie HashMap Und Sie müssen nur die doppelt verknüpfte Liste, auf die table header zeigt, direkt durchlaufen, was bedeutet, dass die Iterationszeit von LinkedHashMap nur mit der Anzahl von zusammenhängt und nichts hat mit der Größe von entry zu tun haben. table
LinkedHashMap auswirken können: Anfangskapazität und Auslastungsfaktor. Die Anfangskapazität gibt die Anfangsgröße von an und der Lastfaktor wird verwendet, um den kritischen Wert für die automatische Erweiterung anzugeben. Wenn die Anzahl von table entry überschreitet, wird der Container automatisch erweitert und erneut gehasht. In Szenarien, in denen eine große Anzahl von Elementen eingefügt wird, kann das Festlegen einer größeren Anfangskapazität die Anzahl der erneuten Aufbereitungen verringern. Wenn capacity*load_factor
-Objekt in LinkedHashMap oder LinkedHashSet einfügt, gibt es zwei Methoden, die besondere Aufmerksamkeit erfordern: und hashCode() . Die equals()-Methode bestimmt, in welchem hashCode() das Objekt platziert wird. Wenn die Hashwerte mehrerer Objekte in Konflikt geraten, bestimmt die bucket-Methode, ob diese Objekte das „gleiche Objekt“ equals() sind. Wenn Sie also ein benutzerdefiniertes Objekt in oder LinkedHashMap einfügen möchten, benötigen Sie die Methoden *@Override*LinkedHashSet und hashCode(). equals()
LinkedHashMap erhalten, die mit der Quell-Mapiterationsreihenfolge wie folgt übereinstimmt:
void foo(Map m) {
Map copy = new LinkedHashMap(m);
} Aus Leistungsgründen ist LinkedHashMap asynchron (nicht synchronisiert). Wenn es in einer Multithread-Umgebung verwendet werden muss, müssen Programmierer manuell synchronisieren Methode zum Synchronisieren von LinkedHashMap Eingepackt in Synchronous:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
get (<p>Objekt-Schlüssel)</p>-Methode gibt den entsprechenden get(<a href="http://www.php.cn/wiki/60.html" target="_blank">Object</a> key) basierend auf dem angegebenen key-Wert zurück. Der Vorgang dieser Methode ist fast identisch mit dem der value-Methode. Der Leser kann sich auf den vorherigen Artikel beziehen und wird hier nicht wiederholt. Die Methode HashMap.get()put()
fügt das angegebene put(K key, V value)-Paar zu key, value hinzu. Diese Methode sucht zunächst nach map, um zu sehen, ob es das Tupel enthält. Der Suchvorgang ähnelt der Methode map, wenn es nicht gefunden wird über die Methode get() eingefügt. addEntry(int hash, K key, V value, int bucketIndex)entryBeachten Sie, dass die
:
Aus der Perspektive von
- das neue
Es muss in das entsprechende
tableeingefügt werden. Wenn ein Hash-Konflikt vorliegt, wird die Kopfeinfügungsmethode verwendet, um das neueentryin den Kopf der mit dem Konflikt verknüpften Liste einzufügen.bucket从
header的角度看,新的entry需要插入到双向链表的尾部。
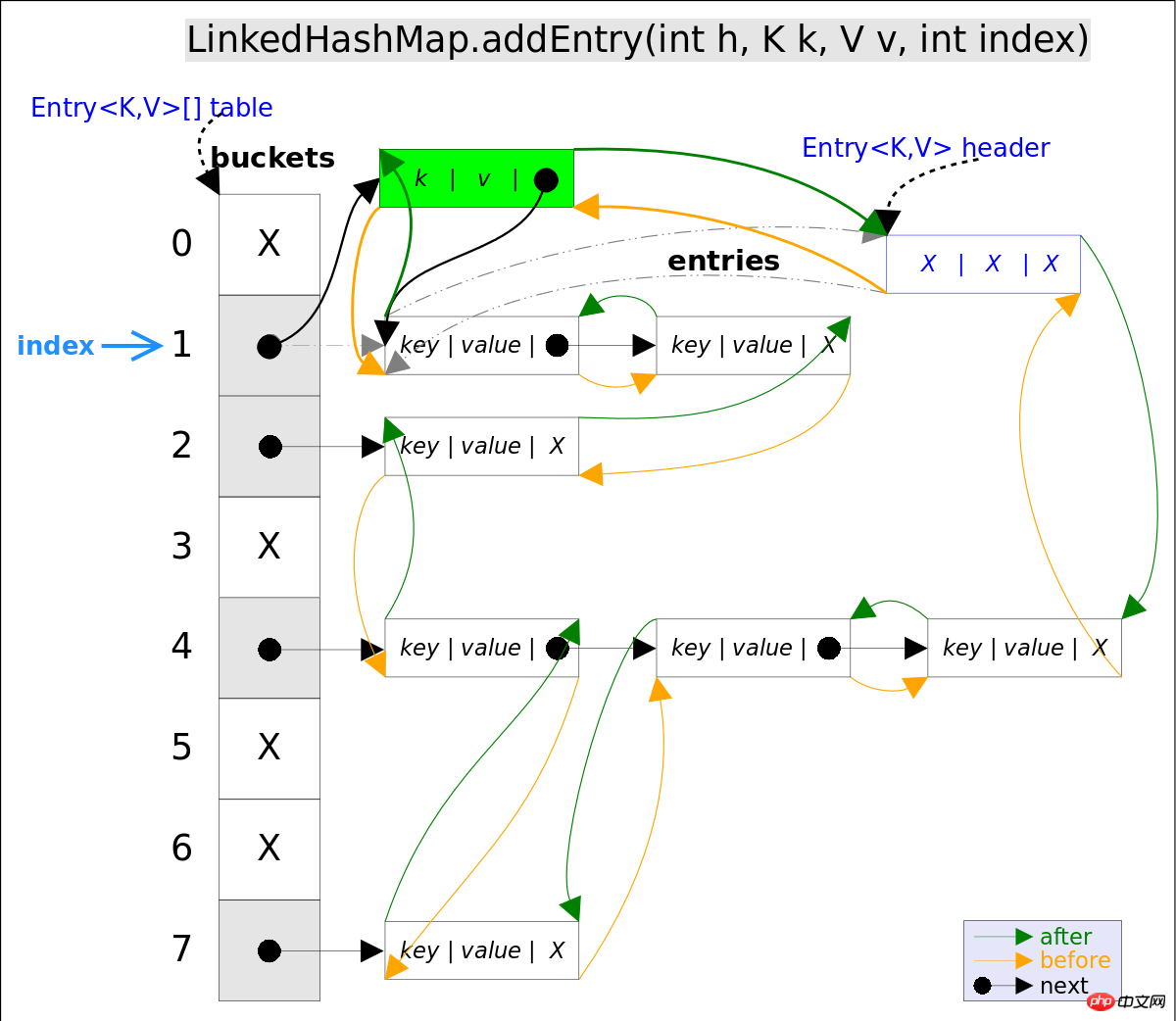
addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}上述代码只是简单修改相关entry的引用而已。
remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的删除也有两重含义:
从
table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。从
header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。

removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}LinkedHashSet
前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
}Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Quellcodeanalyse des Java-Sammlungsframeworks LinkedHashSet und LinkedHashMap (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!