
Heim >Backend-Entwicklung >PHP-Tutorial >mysql如何去除两个字段数据相同的记录?
mysql如何去除两个字段数据相同的记录?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-06-17 08:32:151741Durchsuche
比如说有个name列和一个eamil列,如果数据库里面有条记录的这两列的值相同(我说的是这条记录的对应的那两列的值相同,并不是同一条记录里面两列值相同)的话就自动删除其他多余的列而保留最新的那一条(也就是ID最小的那个,ID是一个自增主键)
——————————————————
也就是说表里面有两条记录的name都是admin,email都是abc@163.com,我只想保留其中一条,这该怎么做
回复内容:
其实你会用英文搜索的话。可以很方便在stack overflow上 找到相关的信息 真的学CS的就不要用百度了 用google你会发现一个不一样的世界的随便贴一个
sql - How can I remove duplicate rows?
稍微讲一下其中一个思路(里面有很多很好的答案 你可以自己去看)
就是做一个group by 保留其中id 最大的(你说自增长 id最大的应该就是最新的)就可以了
具体sql query 可以这样写
<span class="k">delete</span> <span class="k">from</span> <span class="n">test</span> <span class="k">where</span> <span class="n">id</span> <span class="k">not</span> <span class="k">in</span><span class="p">(</span>
<span class="k">select</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span><span class="p">,</span><span class="k">max</span><span class="p">(</span><span class="n">id</span><span class="p">)</span> <span class="k">from</span> <span class="n">test</span>
<span class="k">group</span> <span class="k">by</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span> <span class="k">having</span> <span class="n">id</span> <span class="k">is</span> <span class="k">not</span> <span class="k">null</span><span class="p">)</span>
distinct
如果要保留id的最小值,例如:数据:
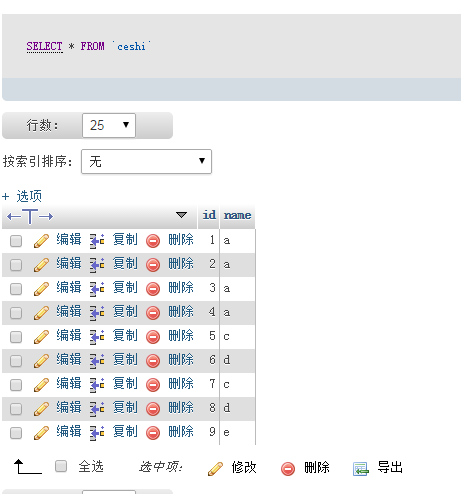

执行sql:select count(*) as count ,name,id from ceshi group by name
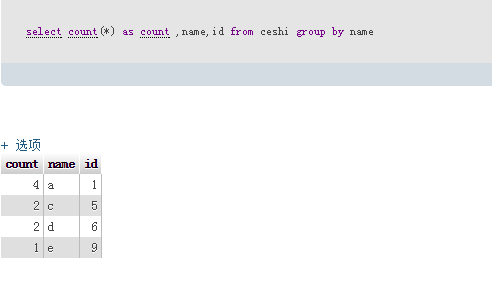 最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)
最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)如果想保留id的最大值:
简单的办法是:delete from ceshi where id not in (select count(*) as count ,name,id from (select * from ceshi order by id desc) group by name) distinct 其实非常的简单,只需要把你这张表当成两张表来处理就行了。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id 这里有个问题,题主说保留最新的那一条(也就是ID最小的那个),既然是递增,最新的不应该是最大的那条吗?
上面的的语句,p1.id '即可。
当然是用group by,count可以更精准控制重复n次的情况。不过目测楼主需求应该只要把重复的删掉,保留最新的就可以了。 DELETE FROM table WHERE id not in ( SELECT
tb.id FROM ( SELECT tmp.* FROM table tmp ) tb GROUP BY tb.field1, tb.field2,… );
table是表名,field是要去重的字段。 新建一个表,设置name,email为唯一索引,然后重新插入旧表数据
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:Symfony2 的优缺点有哪些?Nächster Artikel:学习PHP不如JAVA吗?
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- So verwenden Sie cURL zum Implementieren von Get- und Post-Anfragen in PHP
- Alle Ausdruckssymbole in regulären Ausdrücken (Zusammenfassung)