
Heim >Technologie-Peripheriegeräte >KI >Korrekturlappen (Crag) in Aktion
Korrekturlappen (Crag) in Aktion

- 尊渡假赌尊渡假赌尊渡假赌Original
- 2025-03-13 10:37:08402Durchsuche
RAGUVAL-AUGmented Generation (RAG) ermöglicht große Sprachmodelle (LLMs) durch Einbeziehung von Informationsabruf. Auf diese Weise können LLMs auf externe Wissensbasis zugreifen, was zu genaueren, aktuelleren und kontextbezogenen Antworten führt. Corrective RAG (CRAG), eine fortschrittliche RAG-Technik, verbessert die Genauigkeit weiter durch Einführung von Selbstreflexions- und Selbsteinschätzungen für abgerufene Dokumente.
Wichtige Lernziele
Dieser Artikel deckt:
- Crags Kernmechanismus und seine Integration in die Websuche.
- Die Relevanzbewertung der Dokumentenrelevanz von CRAG unter Verwendung von Binärbewertungen und Umschreiben von Abfragen.
- Wichtige Unterscheidungen zwischen Crag und traditionellem Lappen.
- Praxis-Anfänger-Implementierung mit Python, Langchain und Tavily.
- Praktische Fähigkeiten bei der Konfiguration von Evaluatoren, Abfragen -Umschreibern und Websuch -Tools zur Optimierung des Abrufs und der Reaktionsgenauigkeit.
Veröffentlicht als Teil des Data Science Blogathon.
Inhaltsverzeichnis
- Crags zugrunde liegender Mechanismus
- Crag vs. traditioneller Lappen
- Praktische Crag -Implementierung
- Crags Herausforderungen
- Abschluss
- Häufig gestellte Fragen
Crags zugrunde liegender Mechanismus
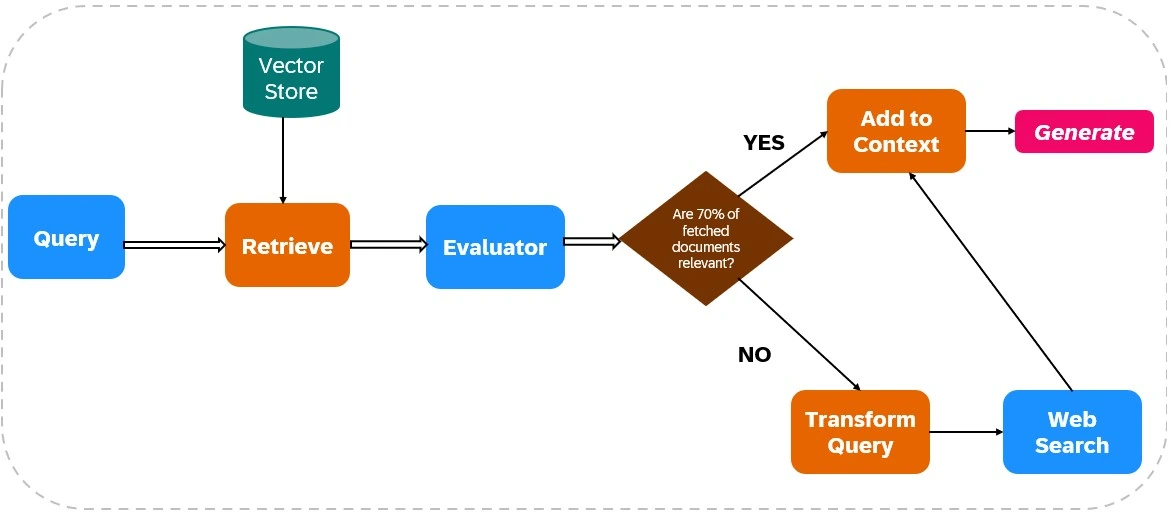
CRAG verbessert die Zuverlässigkeit von LLM -Ausgängen, indem die Websuche in seine Abruf- und Erzeugungsprozesse integriert wird (siehe Abbildung 1).
Dokumentenabruf:
- Datenaufnahme: Relevante Daten werden indiziert, und Web-Search-Tools (wie Tavily AI) werden für das Abrufen von Daten in Echtzeit konfiguriert.
- Erstes Abrufen: Dokumente werden von einer statischen Wissensbasis basierend auf der Abfrage des Benutzers abgerufen.
Relevanzbewertung:
Ein Evaluator bewertet die abgerufene Dokumentenrelevanz. Wenn über 70% der Dokumente als irrelevant eingestuft werden, werden Korrekturmaßnahmen eingeleitet. Andernfalls geht die Reaktionsgenerierung fort.
Web -Search -Integration:
Wenn die Relevanz von Dokumenten nicht ausreicht, verwendet CRAG die Web -Suche:
- Abfrageverfeinerung: Die ursprüngliche Abfrage wird geändert, um die Web -Suchergebnisse zu optimieren.
- Web -Search -Ausführung: Tools wie Tavily AI holen zusätzliche Daten, um den Zugriff auf aktuelle und verschiedene Informationen zu gewährleisten.
Antwortgenerierung:
Crag synthetisiert Daten sowohl von der ersten Abruf als auch von Websuche, um eine kohärente, genaue Antwort zu erstellen.
Crag vs. traditioneller Lappen
CRAG überprüft und verfeinert abgerufene Informationen im Gegensatz zu herkömmlichen Lappen, die auf abgerufenen Dokumenten ohne Überprüfung beruhen. CRag beinhaltet häufig in Echtzeit-Websuche und bietet den Zugriff auf die aktuellsten Informationen, im Gegensatz zu herkömmlichen Rags Vertrauen in statische Wissensbasis. Dies macht Crag ideal für Anwendungen, die eine hohe Genauigkeit und Echtzeitdatenintegration erfordern.
Praktische Crag -Implementierung
In diesem Abschnitt wird eine Crag -Implementierung unter Verwendung von Python, Langchain und Tavily beschrieben.
Schritt 1: Bibliotheksinstallation
Installieren Sie die erforderlichen Bibliotheken:
! ! PIP install -qu PYPDF Langchain_Community
Schritt 2: API -Schlüsselkonfiguration
Stellen Sie Ihre API -Schlüssel ein:
OS importieren OS.Environ ["tavily_api_key"] = "" " Os.Environ ["openai_api_key"] = ""
Schritt 3: Bibliotheksinporte
Importieren Sie die erforderlichen Bibliotheken (Code für Kürze weggelassen, jedoch ähnlich wie beim ursprünglichen Beispiel).
Schritt 4: Dokument Chunking und Retriever -Erstellung
(Code für die Kürze weggelassen, aber ähnlich wie das ursprüngliche Beispiel unter Verwendung von PYPDFLOADER, recursivecharactertextSplitter, OpenAiembeddings und Chroma).
Schritt 5: Lappenketten -Setup
(Code für Kürze weggelassen, jedoch ähnlich wie beim ursprünglichen Beispiel mit hub.pull("rlm/rag-prompt") und ChatOpenAI ).
Schritt 6: Evaluator -Setup
(Code für die Kürze weggelassen, jedoch ähnlich wie beim ursprünglichen Beispiel, die Definieren der Evaluator -Klasse und die Verwendung von ChatOpenAI zur Bewertung).
Schritt 7: Abfrage -Rewriter -Setup
(Code für Kürze weggelassen, aber ähnlich wie beim ursprünglichen Beispiel, indem Sie ChatOpenAI für die Umschreibung von Abfragen verwenden).
Schritt 8: Web -Search -Setup
von Langchain_Community.tools.tavily_search importieren tavilysearchResults web_search_tool = tavilySearchResults (k = 3)
Schritt 9-12: Langgraph Workflow Setup und Ausführung
(Code für Kürze, aber konzeptionell dem ursprünglichen Beispiel, das Definieren der GraphState , Funktionsknoten ( retrieve , generate , bewerten, evaluate_documents , transform_query , web_search ) und verbinden sie mit StateGraph .) Die endgültige Ausgabe und Vergleich mit traditionellem RAG sind auch konzeptionell ähnlich.
Crags Herausforderungen
Die Wirksamkeit von Crag hängt stark von der Genauigkeit des Bewerters ab. Ein schwacher Bewerter kann Fehler einführen. Skalierbarkeit und Anpassungsfähigkeit sind ebenfalls Bedenken, die kontinuierliche Aktualisierungen und Schulungen erfordern. Die Integration der Websuche führt das Risiko von voreingenommenen oder unzuverlässigen Informationen ein und erfordert robuste Filtermechanismen.
Abschluss
CRAG verbessert die Genauigkeit und Zuverlässigkeit von LLM -Output erheblich. Die Fähigkeit, abgerufene Informationen mit Echtzeit-Webdaten zu bewerten und zu ergänzen, macht es für Anwendungen, die hohe Präzision und aktuelle Informationen fordern, wertvoll. Die kontinuierliche Verfeinerung ist jedoch von entscheidender Bedeutung, um die Herausforderungen im Zusammenhang mit der Genauigkeit der Bewerter und der Zuverlässigkeit von Webdaten zu bewältigen.
Wichtige Imbissbuden (ähnlich wie das Original, aber für die Übersicht übernommen)
- CRAG verbessert die LLM -Antworten mithilfe der Websuche nach aktuellen, relevanten Informationen.
- Sein Bewerter sorgt für qualitativ hochwertige Informationen für die Reaktionsgenerierung.
- Abfragentransformation optimiert die Web -Suchergebnisse.
- Crag integriert dynamisch Echtzeit-Webdaten, im Gegensatz zu herkömmlichen Lappen.
- CRag überprüft aktiv Informationen und reduziert Fehler.
- Crag ist für Anwendungen von Vorteil, die hohe Genauigkeit und Echtzeitdaten benötigen.
Häufig gestellte Fragen (ähnlich wie das Original, aber für die Übersicht umformuliert)
- F1: Was ist Crag? A: Ein erweitertes RAG -Framework, das die Websuche für eine verbesserte Genauigkeit und Zuverlässigkeit integriert.
- F2: Crag vs. traditionelles Lappen? A: CRAG überprüft und verfeinert abgerufene Informationen aktiv.
- F3: Die Rolle des Bewerters? A: Bewertung der Relevanz der Dokumente und Auslösen von Korrekturen.
- F4: Unzureichende Dokumente? A: Zeugende Nahrungsergänzungsmittel mit Websuche.
- F5: Umgang mit unzuverlässigen Webinhalten? A: Erweiterte Filtermethoden sind erforderlich.
(Hinweis: Das Bild bleibt unverändert und ist wie in der ursprünglichen Eingabe enthalten.)
Das obige ist der detaillierte Inhalt vonKorrekturlappen (Crag) in Aktion. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr