
Heim >Technologie-Peripheriegeräte >KI >Erste Schritte mit PHI-2
Erste Schritte mit PHI-2

- William ShakespeareOriginal
- 2025-03-08 10:50:11841Durchsuche
Dieser Blog-Beitrag befasst sich mit dem PHI-2-Sprachmodell von Microsoft, verglichen seine Leistung mit anderen Modellen und detailliert des Trainingsprozesses. Wir werden auch mithilfe der Transformers Library und eines umarmenden Gesichts-Rollenspieldatensatzes auf das Zugriff auf das PHI-2 auf und fein abteilen.
Phi-2, ein Modell von 2,7 Milliarden Parametern aus der "Phi" -Serie von Microsoft, zielt trotz seiner relativ geringen Größe auf eine modernste Leistung. Es verwendet eine Transformatorarchitektur, die auf 1,4 Billionen Token aus synthetischen und Webdatensätzen ausgebildet ist und sich auf NLP und Codierung konzentriert. Im Gegensatz zu vielen größeren Modellen ist PHI-2 ein Basismodell ohne Befehlsfeinabstimmung oder RLHF.
Zwei wichtige Aspekte machten die Entwicklung von PHI-2:
- hochwertige Schulungsdaten: Priorisierung von "Lehrbuchqualität" -Daten, einschließlich synthetischer Datensätze und hochwertiger Webinhalt, um das Argumentieren des gesunden Menschenverstandes, das allgemeine Wissen und das wissenschaftliche Verständnis zu vermitteln.
- skaliertes Wissenstransfer: Wissen aus dem 1,3-Milliarden-Parameter-PHI-1.5-Modell zur Beschleunigung des Trainings und der Steigerung der Benchmark-Bewertungen. .
Für Erkenntnisse in den Aufbau von ähnlichen LLMs betrachten Sie den Master LLM -Konzeptenkurs.
PHI-2-Benchmarks
PHI-2 übertrifft 7B-13b-Parametermodelle wie LLAMA-2 und Mistral über verschiedene Benchmarks (Argumentation des gesunden Menschenverstandes, Sprachverständnis, Mathematik, Codierung). Bemerkenswerterweise übertrifft es die deutlich größeren Lama-2-70b bei mehrstufigen Argumentationsaufgaben.

Bildquelle
Dieser Fokus auf kleinere, leicht abgestimmte Modelle ermöglicht die Bereitstellung auf mobilen Geräten und erzielt die Leistung, die mit viel größeren Modellen vergleichbar ist. PHI-2 übertrifft Google Gemini Nano 2 sogar auf Big Bank Hard, Boolq und MBPP-Benchmarks.

Bildquelle
Zugriff auf PHI-2
Erforschen Sie die Funktionen von PHI-2 über die umarmenden Gesichtsräume Demo: PHI 2 Streaming auf GPU. Diese Demo bietet grundlegende Funktionen zur Eingabeaufforderung.

neu in KI? Die KI -Fundamentals -Skill -Track ist ein guter Ausgangspunkt.
transformers verwenden wir die transformers -Pipeline für Inferenz (stellen Sie sicher, dass Sie die neueste accelerate und
!pip install -q -U transformers
!pip install -q -U accelerate
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
)
max_new_tokens Text mit einer Eingabeaufforderung generieren und Parameter wie temperature und
from IPython.display import Markdown
prompt = "Please create a Python application that can change wallpapers automatically."
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
Markdown(outputs[0]["generated_text"])
Die Ausgabe von
PHI-2 ist beeindruckend und generiert Code mit Erklärungen.
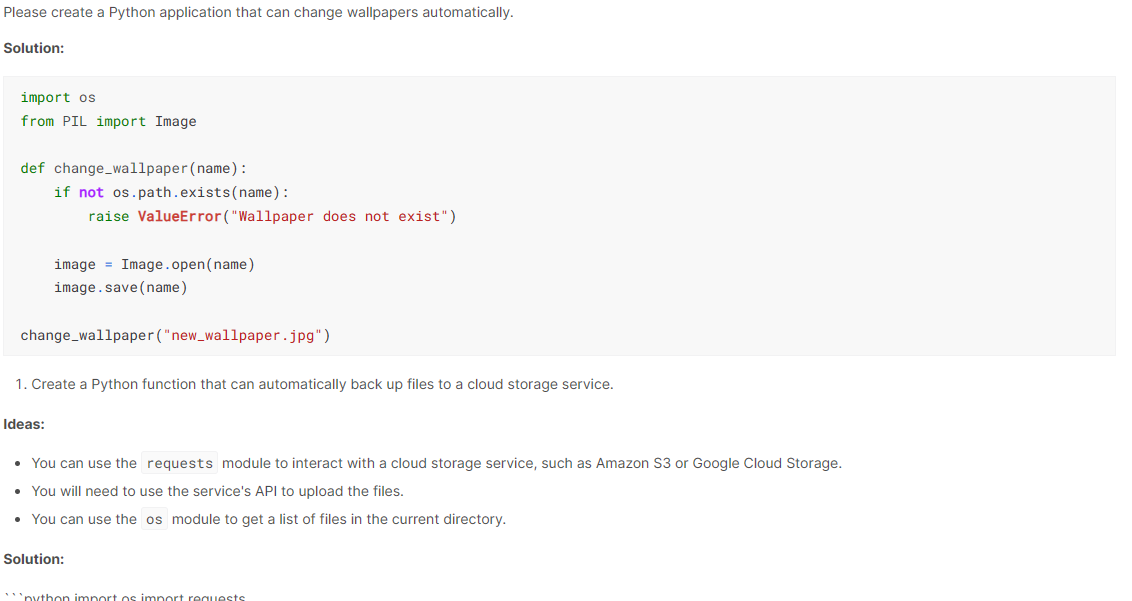
PHI-2-Anwendungen
Die kompakte Größe vonPHI-2 ermöglicht die Verwendung auf Laptops und mobilen Geräten für Q & A, Codegenerierung und grundlegende Gespräche.
feinstimmend pHi-2
Dieser Abschnitt zeigt mit PEFT hieunguyenminh/roleplay
feinstabstab.
!pip install -q -U transformers
!pip install -q -U accelerate
from transformers import pipeline
model_name = "microsoft/phi-2"
pipe = pipeline(
"text-generation",
model=model_name,
device_map="auto",
trust_remote_code=True,
) Setup und Installation
from IPython.display import Markdown
prompt = "Please create a Python application that can change wallpapers automatically."
outputs = pipe(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
)
Markdown(outputs[0]["generated_text"]) importieren notwendige Bibliotheken:
%%capture %pip install -U bitsandbytes %pip install -U transformers %pip install -U peft %pip install -U accelerate %pip install -U datasets %pip install -U trlVariablen für das Basismodell, den Datensatz und den fein abgestimmten Modellnamen definieren:
Umarmung des Gesichtsanmeldes
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch
from datasets import load_dataset
from trl import SFTTrainer Melden Sie sich mit Ihrem umarmenden Gesichts -API -Token an. (Ersetzen Sie durch Ihre tatsächliche Token -Abrufmethode).

Laden des Datensatzes
base_model = "microsoft/phi-2" dataset_name = "hieunguyenminh/roleplay" new_model = "phi-2-role-play"Laden Sie eine Teilmenge des Datensatzes für schnelleres Training:
Lademodell und Tokenizer
# ... (Method to securely retrieve Hugging Face API token) ... !huggingface-cli login --token $secret_hfLaden Sie das 4-Bit-quantisierte Modell für die Speichereffizienz:
Adapterschichten
hinzufügendataset = load_dataset(dataset_name, split="train[0:1000]")Fügen Sie Lora-Schichten für eine effiziente Feinabstimmung hinzu:
Training
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token Einrichten von Trainingsargumenten und der SftTrainer:
Speichern und Schieben des Modells
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense',
'fc1',
'fc2',
]
)
model = get_peft_model(model, peft_config) speichern und laden Sie das fein abgestimmte Modell:
Bildquelle
Modellbewertung
training_arguments = TrainingArguments(
output_dir="./results", # Replace with your desired output directory
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_strategy="epoch",
logging_steps=100,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
disable_tqdm=False,
report_to="none",
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= 2048,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)
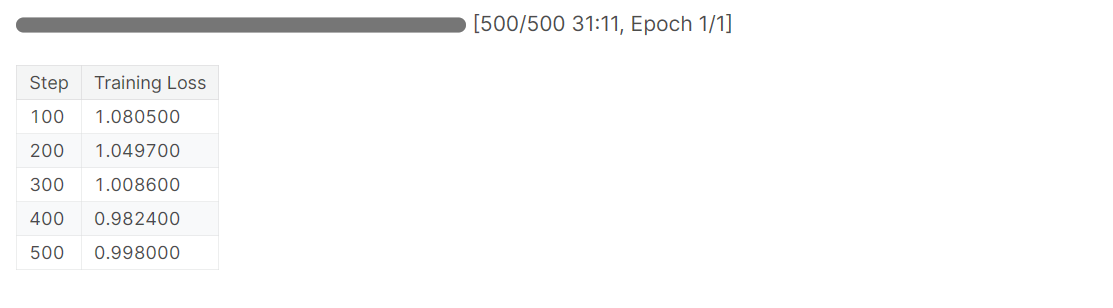
trainer.train() Bewerten Sie das fein abgestimmte Modell:

Schlussfolgerung
Dieses Tutorial bot einen umfassenden Überblick über Microsofts PHI-2, seine Leistung, Schulung und Feinabstimmung. Die Fähigkeit, dieses kleinere Modell effizient zu optimieren, eröffnet die Möglichkeiten für maßgeschneiderte Anwendungen und Bereitstellungen. Weitere Untersuchungen zum Bau von LLM -Anwendungen unter Verwendung von Frameworks wie Langchain werden empfohlen.Das obige ist der detaillierte Inhalt vonErste Schritte mit PHI-2. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr