
Heim >Technologie-Peripheriegeräte >KI >LLM RAG: Erstellen eines AIS-Assistenten mit KI-betriebener Datei-Leser
LLM RAG: Erstellen eines AIS-Assistenten mit KI-betriebener Datei-Leser

- Linda HamiltonOriginal
- 2025-03-04 10:40:11509Durchsuche
Einführung
ai ist überall.
Es ist schwierig, nicht mindestens einmal am Tag mit einem großen Sprachmodell (LLM) zu interagieren. Die Chatbots sind hier, um zu bleiben. Sie sind in Ihren Apps, sie helfen Ihnen, besser zu schreiben, sie komponieren E -Mails, sie lesen E -Mails ... nun, sie tun viel.
Und ich denke nicht, dass das schlecht ist. In der Tat ist meine Meinung umgekehrt - zumindest bisher. Ich verteidige und befürworte den Einsatz von KI in unserem täglichen Leben, weil es zustimmen, dass es alles viel einfacher macht.
Ich muss keine Zeit mit dem Doppel-Lesen eines Dokuments verbringen, um Interpunktionsprobleme oder Typen zu finden. KI macht das für mich. Ich verschwende keine Zeit damit, diese Follow-up-E-Mail jeden Montag zu schreiben. KI macht das für mich. Ich muss keinen riesigen und langweiligen Vertrag lesen, wenn ich eine KI habe, um die wichtigsten Imbissbuden und Aktionspunkte für mich zusammenzufassen!
Dies sind nur einige der großen Verwendungen von AI. Wenn Sie mehr Anwendungsfälle von LLMs wissen möchten, um unser Leben einfacher zu machen, habe ich ein ganzes Buch darüber geschrieben.
Jetzt denken Sie als Datenwissenschaftler und betrachten Sie die technische Seite, nicht alles ist so hell und glänzend.
llms eignen sich hervorragend für mehrere allgemeine Anwendungsfälle, die für Personen oder ein beliebiges Unternehmen gelten. Zum Beispiel Codierung, Zusammenfassung oder Beantwortung von Fragen zu allgemeinen Inhalten, die bis zum Datum des Trainingsabschlusses erstellt wurden. Wenn es jedoch um bestimmte Geschäftsanwendungen, für einen einzelnen Zweck oder etwas Neues geht, das das Cutoff-Datum nicht ermöglichte, sind die Modelle nicht so nützlich, wenn sie aus dem Box verwendet werden. Dies bedeutet, dass sie die Antwort nicht kennen. Somit müssen Anpassungen erforderlich sind.
Training Ein LLM -Modell kann Monate und Millionen von Dollar dauern. Noch schlimmer ist, dass es unbefriedigende Ergebnisse oder Halluzinationen gibt, wenn wir das Modell nicht anpassen und auf unseren Zweck einstellen (wenn die Reaktion des Modells angesichts unserer Abfrage nicht sinnvoll ist).
Was ist dann die Lösung? Viel Geld ausgeben, das das Modell umnimmt, um unsere Daten einzuschließen?nicht wirklich. In diesem Moment wird die retrieval-aus-generierte Generation (LAG) nützlich.
RAG ist ein Rahmen, das Informationen aus einer externen Wissensbasis mit großartigen Modellen (LLMs) kombiniert. Es hilft AI -Modellen, genauere und relevantere Antworten zu erzeugen.
Erfahren wir als nächstes mehr über Rag.Was ist RAG?
Lassen Sie mich Ihnen eine Geschichte erzählen, um das Konzept zu veranschaulichen.
Ich liebe Filme. In der Vergangenheit wusste ich einige Zeit, welche Filme um die beste Filmkategorie der Oscars oder der besten Schauspieler und Schauspielerinnen konkurrierten. Und ich würde auf jeden Fall wissen, welche die Statue für dieses Jahr bekommen hat. Aber jetzt bin ich in diesem Thema alle verrostet. Wenn Sie mich fragen, wer an Wettkämpfen teilgenommen hat, würde ich es nicht wissen. Und selbst wenn ich versuchte, dir zu antworten, würde ich dir eine schwache Antwort geben.
Um Ihnen also eine Qualitätsantwort zu geben, werde ich tun, was alle anderen tun: suchen Sie online nach Informationen, erhalten Sie sie und geben Sie sie dann Ihnen. Was ich gerade getan habe, ist die gleiche Idee wie der Lappen: Ich habe Daten aus einer externen Datenbank erhalten, um Ihnen eine Antwort zu geben.
Wenn wir das LLM mit einem Content Store verbessern, wo es gehen kann, und Daten abrufen, um zu (erhöhen) seine Wissensbasis, das ist das RAG -Framework in Aktion.
Lag ist wie das Erstellen eines Inhaltsspeichers, in dem das Modell sein Wissen verbessern und genauer reagieren kann.
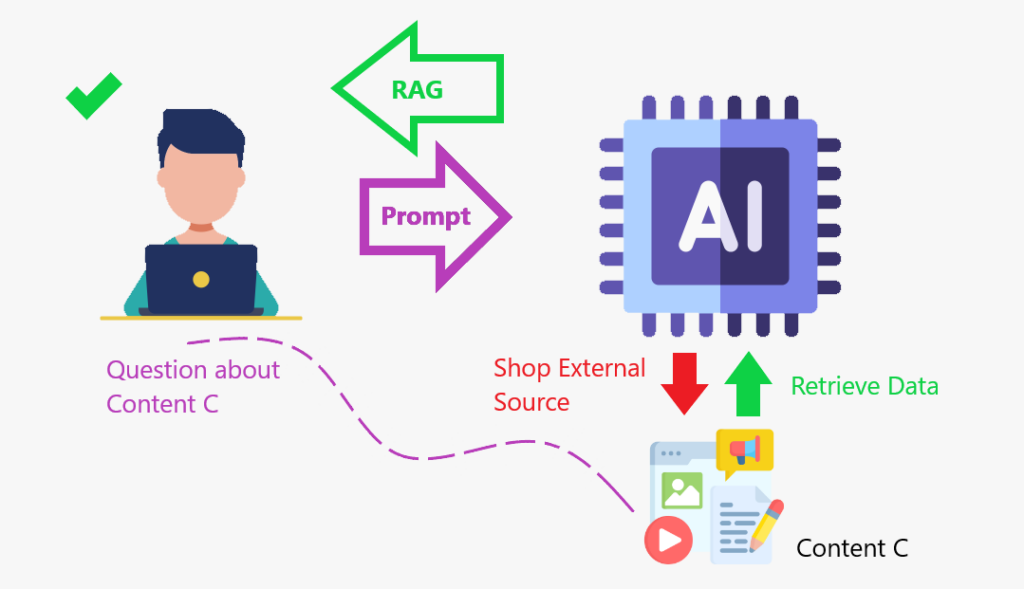
Zusammenfassung:
- verwendet Suchalgorithmen, um externe Datenquellen wie Datenbanken, Wissensbasis und Webseiten abzufragen.
- Vorbereitet die abgerufenen Informationen.
- enthält die vorverarbeiteten Informationen in die LLM.
Warum Rag verwenden?
Jetzt, da wir wissen, was das RAG -Framework ist, lassen Sie uns verstehen, warum wir es verwenden sollten.
Hier sind einige der Vorteile:
- verbessert die sachliche Genauigkeit, indem reale Daten verweist.
- RAG kann LLMS beim Prozess helfen und das Wissen konsolidieren, um relevantere Antworten zu erstellen
- RAG kann LLMs helfen, zusätzliche Wissensbasis wie interne organisatorische Daten zuzugreifen
- RAG kann LLMs helfen, genauere domänenspezifische Inhalte zu erstellen
- Lappen kann dazu beitragen, Wissenslücken und KI -Halluzination zu verringern
Wie bereits erläutert, sage ich gerne, dass wir mit dem RAG -Framework eine interne Suchmaschine für den Inhalt geben, von dem wir die Wissensbasis hinzufügen sollen.
Nun. All das ist sehr interessant. Aber lassen Sie uns eine Anwendung von Lappen sehen. Wir werden lernen, wie man einen AI-betriebenen PDF-Reader-Assistenten erstellt.
Projekt
Dies ist eine Anwendung, mit der Benutzer ein PDF-Dokument hochladen und Fragen zu ihren Inhalten mithilfe von NLP-Tools (natürlicher Sprache) mit AI-betriebenen Sprachverarbeitung stellen können.
- Die App verwendet Streamlit als Frontend.
- Langchain, OpenAIs GPT-4-Modell und FAISS (Facebook AI-Ähnlichkeitssuche) zum Abrufen von Dokumenten und der Beantwortung des Backends.
Lassen Sie uns die Schritte zum besseren Verständnis aufschlüsseln:
- Laden Sie eine PDF -Datei und teilen Sie sie in Textbrocken auf.
- Dies macht die Daten zum Abrufen optimiert
- Präsentieren Sie die Stücke einem Einbettungswerkzeug.
- Einbettungen sind numerische Vektordarstellungen von Daten, die zur Erfassung von Beziehungen, Ähnlichkeiten und Bedeutungen so verwendet werden, dass Maschinen verstehen können. Sie werden in der natürlichen Sprachverarbeitung (NLP), Empfehlungssysteme und Suchmaschinen häufig verwendet.
- Als nächstes setzen wir diese Textbrocken und Einbettungen zum Abrufen in die gleiche dB.
- Schließlich stellen wir es dem LLM zur Verfügung.
Datenvorbereitung
Vorbereitung eines Content Store für das LLM macht einige Schritte, wie wir gerade gesehen haben. Beginnen wir also zunächst eine Funktion, mit der eine Datei geladen und in Textbrocken zum effizienten Abrufen aufgeteilt werden kann.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
Als nächstes werden wir unsere Streamlit -App erstellen und diese Funktion im nächsten Skript verwenden.
Webanwendung
Wir werden mit dem Importieren der notwendigen Module in Python beginnen. Die meisten davon werden aus den Langchain -Paketen kommen.
faiss wird zum Abrufen von Dokumenten verwendet; OpenAiembeddings verwandelt die Textbrocken in numerische Bewertungen für eine bessere Berechnung der Ähnlichkeit durch das LLM; Chatopenai ermöglicht es uns, mit der OpenAI -API zu interagieren. create_retrieval_chain ist das, was der Lappen tatsächlich tut, um das LLM mit diesen Daten zu rufen und zu erweitern. create_stuff_documents_chain streift das Modell und das ChatpromptTemplate.
Hinweis: Sie müssen einen OpenAI -Schlüssel erstellen , um dieses Skript auszuführen. Wenn Sie Ihr Konto zum ersten Mal erstellen, erhalten Sie einige kostenlose Credits. Wenn Sie es jedoch für einige Zeit haben, müssen Sie 5 Dollar an Credits hinzufügen, um auf OpenAIs API zugreifen zu können. Eine Option ist die Einbettung von Umarmungen.
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st
Dieser erste Code -Snippet erstellt den App -Titel, erstellt ein Feld für das Hochladen von Dateien und erstellt die Datei, die zur Funktion load_document () hinzugefügt werden soll.
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")
Maschinen verstehen Zahlen besser als Text. Letztendlich müssen wir dem Modell eine Datenbank von Zahlen bereitstellen, die es bei der Ausführung einer Abfrage vergleichen und auf Ähnlichkeit prüfen kann. Hier werden die Einbettungen in diesem nächsten Code nützlich sein, um den Vector_DB zu erstellen.
# Generate embeddings # Embeddings are numerical vector representations of data, typically used to capture relationships, similarities, # and meanings in a way that machines can understand. They are widely used in Natural Language Processing (NLP), # recommender systems, and search engines. embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_KEY, model="text-embedding-ada-002") # Can also use HuggingFaceEmbeddings # from langchain_huggingface.embeddings import HuggingFaceEmbeddings # embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") # Create vector database containing chunks and embeddings vector_db = FAISS.from_documents(chunks, embeddings)
Als nächstes erstellen wir ein Retriever -Objekt, um im Vector_DB zu navigieren.
# Create a document retriever retriever = vector_db.as_retriever() llm = ChatOpenAI(model_name="gpt-4o-mini", openai_api_key=OPENAI_KEY)
Dann erstellen wir das System_Prompt, das eine Reihe von Anweisungen für die LLM zur Beantwortung enthält, und wir erstellen eine Eingabeaufforderungsvorlage, um sie dem Modell hinzuzufügen, sobald wir die Eingabe vom Benutzer erhalten.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
Wenn wir weitergehen, erstellen wir den Kern des Rag -Frameworks und fügen das Retriever -Objekt und die Eingabeaufforderung zusammen. Dieses Objekt fügt relevante Dokumente aus einer Datenquelle (z. B. einer Vektor -Datenbank) hinzu und macht es bereit, mit einem LLM verarbeitet zu werden, um eine Antwort zu generieren.
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st
Schließlich erstellen wir die variable Frage für die Benutzereingabe. Wenn dieses Fragenfeld mit einer Abfrage gefüllt ist, übergeben wir es an die Kette, die das LLM aufruft, um die Antwort zu verarbeiten und zurückzugeben, die auf dem Bildschirm des App gedruckt wird.
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")
Hier ist ein Screenshot des Ergebnisses.
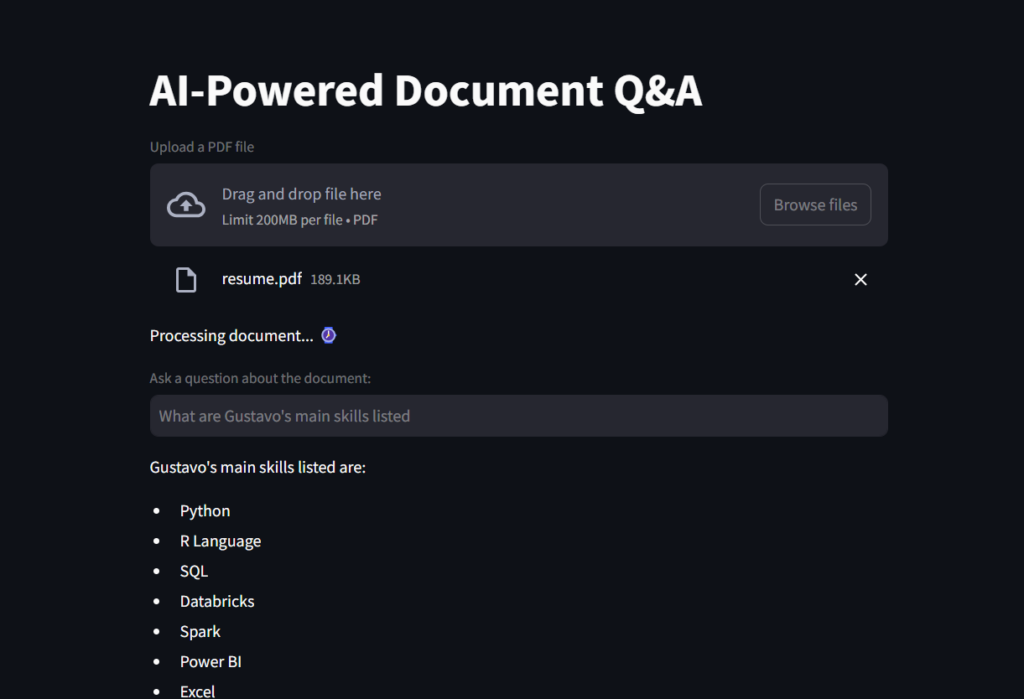
Und dies ist ein GIF, mit dem Sie den Dateileser AI Assistant in Aktion sehen können!

Bevor Sie gehen
In diesem Projekt haben wir gelernt, was das RAG -Framework ist und wie es dem LLM hilft, besser abzuschneiden und auch mit spezifischem Wissen gut abzubauen.
AI kann mit Wissen aus einer Bedienungsanleitung, Datenbanken eines Unternehmens, einigen Finanzdateien oder Verträgen versorgt werden und dann gut abgestimmt werden, um genau auf domänenspezifische Inhaltsabfragen zu reagieren. Die Wissensbasis ist erhöht mit einem Inhaltsspeicher.
Um zusammenzufassen, funktioniert das Framework:
1️⃣ Benutzerabfrage → Eingabetxt wird empfangen.
2️⃣ Relevante Dokumente abrufen → Suchen Sie eine Wissensbasis (z. B. eine Datenbank, Vektorspeicher).
3️⃣ Augment Context → Abgerufene Dokumente werden zur Eingabe hinzugefügt.
4️⃣ Antwort → LLM verarbeitet die kombinierte Eingabe und erzeugt eine Antwort.
Github Repository
https://github.com/gurezende/basic-rag
über mich
Wenn Ihnen dieser Inhalt gefallen hat und mehr über meine Arbeit erfahren möchten, finden Sie hier meine Website, auf der Sie auch alle meine Kontakte finden.
https://gustavorantos.me
referenzen
https://cloud.google.com/use-cases/revalal-augmented-Generation
https://www.ibm.com/think/topics/retrieval-augmented-generation
https://youtu.be/t-d1ofcdw1m?si=g0uwfh5-wznmu0nw
https://python.langchain.com/docs/inTroduction
https://www.geeksforgekks.org/how-to-get-gyour-own-openai-api-key
Das obige ist der detaillierte Inhalt vonLLM RAG: Erstellen eines AIS-Assistenten mit KI-betriebener Datei-Leser. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr