
Heim >Technologie-Peripheriegeräte >KI >KI-betriebene Informationsextraktion und Matchmaking
KI-betriebene Informationsextraktion und Matchmaking

- 王林Original
- 2025-02-25 19:27:13273Durchsuche
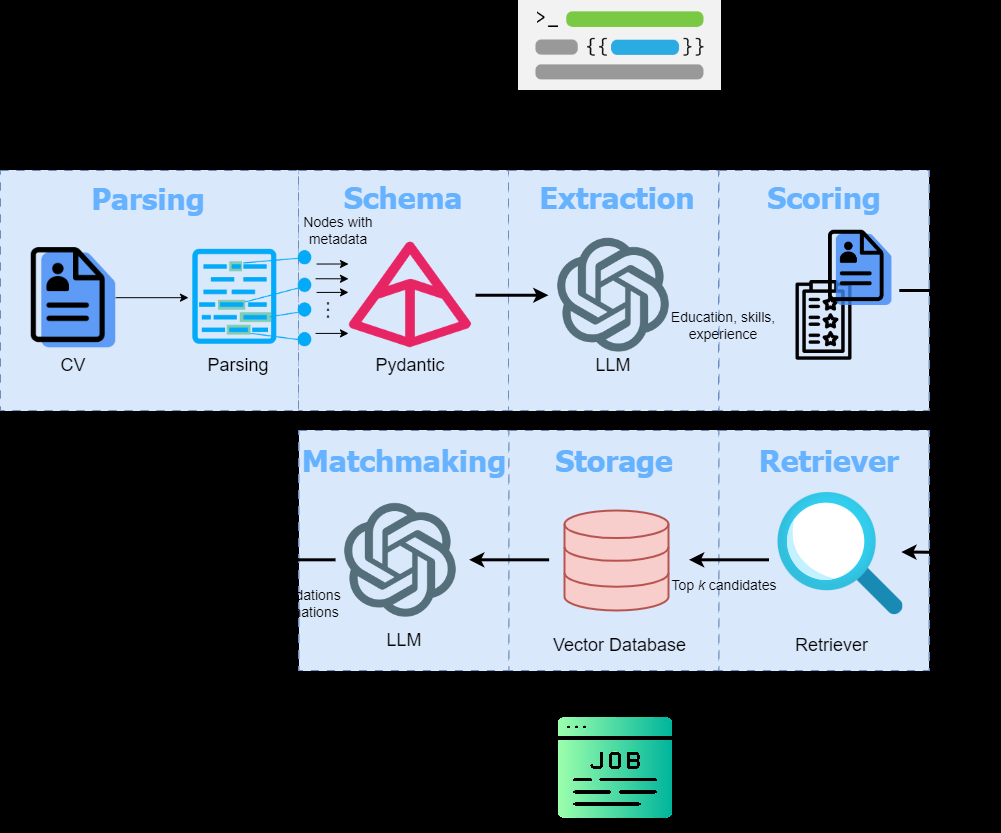
Dieser Artikel untersucht die Verwendung von großsprachigen Modellen (LLMs) für Informationen zur Informationsextraktion von Jobsuchern -CVs und der Empfehlung geeigneter Jobs. Es nutzt Llamaparse für das Dokument an Parsen und Pydantic für strukturierte Datenextraktion und Validierung, wodurch LLM -Halluzinationen minimiert werden. Der Prozess beinhaltet: Extrahieren von Schlüsselinformationen (Bildung, Fähigkeiten, Erfahrung), Bewertungsfähigkeiten auf der Grundlage ihrer Bekanntheit im Lebenslauf, der Erstellung einer Jobvektordatenbank, der Abruf von Top -Job -Übereinstimmungen basierend auf semantischer Ähnlichkeit und generierende Empfehlungen mit Erklärungen unter Verwendung eines LLM.
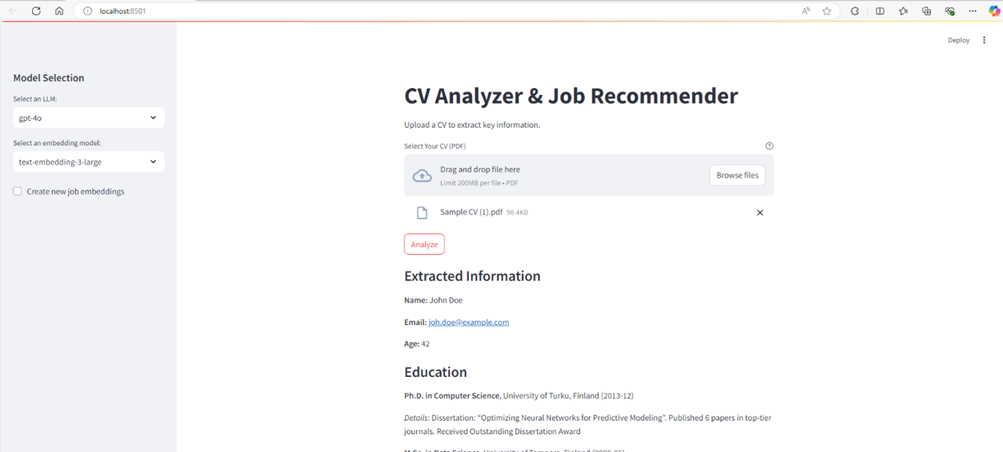
Mit einer streamlit-Anwendung können Benutzer einen CV (PDF) hochladen, LLMs (OpenAIs gpt-4o oder Open-Source-Alternativen) und Embedingde-Modelle auswählen. Die Anwendung extrahiert dann das Profil des Kandidaten, berechnet die Qualifikationsbewertungen (als Sternenbewertung angezeigt) und liefert Top -Jobempfehlungen mit Erklärungen. Der Code verwendet die OpenAI-API für das Einbettungsmodell gpt-4o llm und text-embedding-3-large, bietet jedoch Flexibilität, Open-Source-Alternativen mit einer CUDA-fähigen GPU zu verwenden.
Der Artikel beschreibt die pydantischen Modelle für die strukturierte Datenextraktion, zeigt deren Verwendung bei der Validierung von LLM -Ausgaben und zur Gewährleistung der Datenkonsistenz. Es erläutert den Prozess des Erstellens einer Jobvektor -Datenbank aus einem kuratierten JSON -Datensatz (sample_jobs.json) und der Verwendung von Cosinus -Ähnlichkeit mit Punktzahlfähigkeiten basierend auf ihrer semantischen Relevanz innerhalb des Lebenslaufs. Die endgültigen Auftragsempfehlungen werden unter Verwendung eines RAG-Ansatzes (Abruf-Augmented Generation) generiert, der die extrahierten Profilinformationen mit relevanten Stellenbeschreibungen aus der Vektordatenbank kombiniert.
Die Streamlit -Anwendung zeigt die extrahierten Profilinformationen (Name, E -Mail, Alter, Bildung, Fähigkeiten, Erfahrung) und die Top -Job -Übereinstimmungen an, einschließlich Unternehmensdetails, Jobbeschreibungen, Standort, Beschäftigungstyp, Gehaltsspanne (falls verfügbar), URL und eine kurze Erklärung des Spiels. Die Skill -Scores werden visuell mithilfe eines Sternenbewertungssystems dargestellt.
Der Artikel schließt mit dem Vorschlag von Bereichen zur Verbesserung und Expansion, einschließlich: Verbesserung der Aufnahmepipeline für die Auftragsdatenbank, Erweiterung der aus CVS extrahierten Profilinformationen, Verfeinerung der Methode für die Qualifikation, die Anwendung erweitert, um Job-Anzeigen mit Kandidatenprofilen zu entsprechen, Testen zu testen Die Anwendung mit unterschiedlichen CV -Formaten und Bereitstellung von CV -Verbesserungen und Upskillempfehlungen. Der komplette Code ist auf GitHub verfügbar. Der Autor ermutigt die Leser, sie auf Medium und LinkedIn zu klatschen, zu kommentieren und zu folgen.
Das obige ist der detaillierte Inhalt vonKI-betriebene Informationsextraktion und Matchmaking. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr