
Heim >Backend-Entwicklung >Python-Tutorial >Aufbau eines NBA Data Lake mit AWS: Ein umfassender Leitfaden
Aufbau eines NBA Data Lake mit AWS: Ein umfassender Leitfaden

- Susan SarandonOriginal
- 2025-01-12 08:31:42662Durchsuche
Der Aufbau eines Cloud-nativen Datensees für NBA-Analysen mit AWS ist dank der umfassenden Service-Suite von AWS jetzt einfacher denn je. In diesem Leitfaden wird die Erstellung eines NBA-Datensees mit Amazon S3, AWS Glue und Amazon Athena veranschaulicht und die Einrichtung mit einem Python-Skript für eine effiziente Datenspeicherung, Abfrage und Analyse automatisiert.
Data Lakes verstehen
Ein Data Lake ist ein zentrales Repository zum Speichern strukturierter und unstrukturierter Daten jeder Größenordnung. Daten werden im Rohformat gespeichert, nach Bedarf verarbeitet und für Analysen, Berichte oder maschinelles Lernen verwendet. AWS bietet robuste Tools für die effiziente Erstellung und Verwaltung von Data Lakes.
NBA Data Lake-Übersicht
Dieses Projekt verwendet ein Python-Skript (setup_nba_data_lake.py), um Folgendes zu automatisieren:
- Amazon S3: Erstellt einen Bucket zum Speichern roher und verarbeiteter NBA-Daten.
- AWS Glue: Richtet eine Datenbank und eine externe Tabelle für die Metadaten- und Schemaverwaltung ein.
- Amazon Athena: Konfiguriert die Abfrageausführung für die direkte Datenanalyse aus S3.
Diese Architektur ermöglicht die nahtlose Integration von Echtzeit-NBA-Daten von SportsData.io für erweiterte Analysen und Berichte.
AWS-Dienste genutzt
1. Amazon S3 (einfacher Speicherdienst):
- Funktion: Skalierbarer Objektspeicher; die Grundlage des Data Lake, in dem rohe und verarbeitete NBA-Daten gespeichert werden.
-
Implementierung: Erstellt den
sports-analytics-data-lake-Bucket. Daten werden in Ordnern organisiert (z. B.raw-datafür unverarbeitete JSON-Dateien wienba_player_data.json). S3 gewährleistet hohe Verfügbarkeit, Langlebigkeit und Kosteneffizienz. - Vorteile: Skalierbarkeit, Kosteneffizienz, nahtlose Integration mit AWS Glue und Athena.
2. AWS-Kleber:
- Funktion: Vollständig verwalteter ETL-Dienst (Extrahieren, Transformieren, Laden); verwaltet Metadaten und Schemata für Daten in S3.
-
Implementierung: Erstellt eine Glue-Datenbank und eine externe Tabelle (
nba_players), die das JSON-Datenschema in S3 definiert. Kleben Sie Metadaten in Kataloge und ermöglichen Sie so Athena-Abfragen. - Vorteile: Automatisierte Schemaverwaltung, ETL-Funktionen, Kosteneffizienz.
3. Amazonas Athene:
- Funktion:Interaktiver Abfragedienst zur Analyse von S3-Daten mit Standard-SQL.
-
Implementierung: Liest Metadaten von AWS Glue. Benutzer führen SQL-Abfragen direkt auf S3-JSON-Daten ohne Datenbankserver aus. (Beispielabfrage:
SELECT FirstName, LastName, Position FROM nba_players WHERE Position = 'PG';) - Vorteile: Serverlose Architektur, Geschwindigkeit, Pay-as-you-go-Preise.
Aufbau des NBA Data Lake
Voraussetzungen:
- SportsData.io-API-Schlüssel: Erhalten Sie einen kostenlosen API-Schlüssel von SportsData.io für den NBA-Datenzugriff.
- AWS-Konto: Ein AWS-Konto mit ausreichenden Berechtigungen für S3, Glue und Athena.
- IAM-Berechtigungen: Der Benutzer oder die Rolle erfordert Berechtigungen für S3 (CreateBucket, PutObject, ListBucket), Glue (CreateDatabase, CreateTable) und Athena (StartQueryExecution, GetQueryResults).
Schritte:
1. Greifen Sie auf AWS CloudShell zu: Melden Sie sich bei der AWS Management Console an und öffnen Sie CloudShell.
2. Erstellen und konfigurieren Sie das Python-Skript:
- Führen Sie
nano setup_nba_data_lake.pyin CloudShell aus.
- Kopieren Sie das Python-Skript (aus dem GitHub-Repo) und ersetzen Sie den Platzhalter
api_keydurch Ihren SportsData.io-API-Schlüssel:SPORTS_DATA_API_KEY=your_sportsdata_api_keyNBA_ENDPOINT=https://api.sportsdata.io/v3/nba/scores/json/Players
- Speichern und beenden (Strg X, Y, Eingabetaste).


3. Führen Sie das Skript aus: Führen Sie python3 setup_nba_data_lake.py aus.
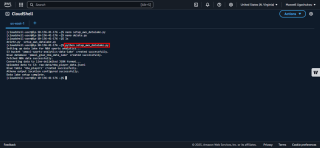
Das Skript erstellt den S3-Bucket, lädt Beispieldaten hoch, richtet die Glue-Datenbank und -Tabelle ein und konfiguriert Athena.
4. Ressourcenüberprüfung:
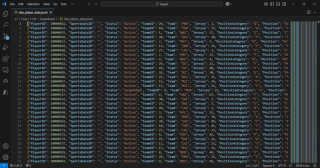
-
Amazon S3: Überprüfen Sie den
sports-analytics-data-lake-Bucket und denraw-data-Ordner, dernba_player_data.jsonenthält.



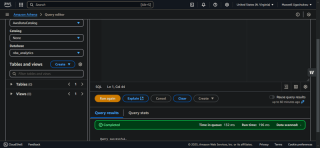
- Amazon Athena:Führen Sie die Beispielabfrage aus und überprüfen Sie die Ergebnisse.

Lernergebnisse:
Dieses Projekt bietet praktische Erfahrung im Cloud-Architekturdesign, Best Practices für die Datenspeicherung, Metadatenverwaltung, SQL-basierter Analyse, API-Integration, Python-Automatisierung und IAM-Sicherheit.
Zukünftige Verbesserungen:
Automatisierte Datenaufnahme (AWS Lambda), Datentransformation (AWS Glue), erweiterte Analysen (AWS QuickSight) und Echtzeitaktualisierungen (AWS Kinesis) sind mögliche zukünftige Verbesserungen. Dieses Projekt demonstriert die Leistungsfähigkeit der serverlosen Architektur für den Aufbau effizienter und skalierbarer Datenseen.
Das obige ist der detaillierte Inhalt vonAufbau eines NBA Data Lake mit AWS: Ein umfassender Leitfaden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!