
Heim >Technologie-Peripheriegeräte >KI >Neue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN
Neue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN

- 王林Original
- 2024-09-02 13:41:301007Durchsuche
Der Schlüssel zum großen Erfolg von Transformer im Bereich Deep Learning ist der Aufmerksamkeitsmechanismus. Der Aufmerksamkeitsmechanismus ermöglicht Transformer-basierten Modellen, sich auf Teile zu konzentrieren, die für die Eingabesequenz relevant sind, und so ein besseres Kontextverständnis zu erreichen. Der Nachteil des Aufmerksamkeitsmechanismus besteht jedoch darin, dass der Rechenaufwand hoch ist, der quadratisch mit der Eingabegröße zunimmt, was es für den Transformer schwierig macht, sehr lange Texte zu verarbeiten.
Vor einiger Zeit hat das Aufkommen von Mamba diese Situation durchbrochen, die mit zunehmender Kontextlänge eine lineare Erweiterung erreichen kann. Mit der Veröffentlichung von Mamba können diese Zustandsraummodelle (SSMs) bereits im kleinen bis mittleren Maßstab mit Transformer mithalten oder diese sogar übertreffen, während gleichzeitig die lineare Skalierbarkeit mit der Sequenzlänge beibehalten wird, was Mamba günstige Bereitstellungseigenschaften verleiht.
Einfach ausgedrückt führt Mamba zunächst einen einfachen, aber effektiven Auswahlmechanismus ein, der SSM entsprechend der Eingabe neu parametrisieren kann, sodass das Modell die erforderlichen Informationen auf unbestimmte Zeit behalten kann, während irrelevante Informationen und zugehörige Daten herausgefiltert werden.
Kürzlich beweist ein Artikel mit dem Titel „The Mamba in the Llama: Distilling and Accelerating Hybrid Models“, dass durch die Wiederverwendung der Gewichte der Aufmerksamkeitsschicht große Transformatoren mit nur minimalem zusätzlichem Rechenaufwand in große hybride lineare RNNs destilliert werden können unter Beibehaltung des größten Teils seiner Verarbeitungsqualität.
Das resultierende Hybridmodell, das ein Viertel der Aufmerksamkeitsebene enthält, erreicht im Chat-Benchmark eine vergleichbare Leistung wie der ursprüngliche Transformer und übertrifft die Daten im Chat-Benchmark und in allgemeinen Benchmarks. Ein Open-Source-Hybrid-Mamba-Modell von Grund auf durch Billionen Token trainiert. Darüber hinaus schlägt die Studie einen hardwarebewussten spekulativen Dekodierungsalgorithmus vor, der die Inferenz für Mamba- und Hybridmodelle beschleunigt.

Papieradresse: https://arxiv.org/pdf/2408.15237
Das leistungsstärkste Modell dieser Studie stammt von Llama3-8B-Instruct Distilled Es erreichte eine längenkontrollierte Gewinnrate von 29,61 bei AlpacaEval 2 im Vergleich zu GPT-4 und eine Gewinnrate von 7,35 bei MT-Bench und übertraf damit das beste anweisungsbereinigte lineare RNN-Modell.
Methoden
Wissensdestillation (KD) ist eine Modellkomprimierungstechnik, mit der Wissen von einem großen Modell (Lehrermodell) auf ein kleineres Modell (Schülermodell) übertragen wird ), deren Ziel es ist, das Schülernetzwerk darin zu trainieren, das Verhalten des Lehrernetzwerks nachzuahmen. Ziel der Forschung ist es, den Transformer so zu destillieren, dass seine Leistung mit dem ursprünglichen Sprachmodell vergleichbar ist.
Diese Studie schlägt eine mehrstufige Destillationsmethode vor, die progressive Destillation, überwachte Feinabstimmung und Richtungspräferenzoptimierung kombiniert. Im Vergleich zur gewöhnlichen Destillation kann diese Methode eine bessere Verwirrung und nachgelagerte Bewertungsergebnisse erzielen.
Die Studie geht davon aus, dass der Großteil des Wissens aus dem Transformer in der vom ursprünglichen Modell übertragenen MLP-Schicht erhalten bleibt, und konzentriert sich auf die Feinabstimmungs- und Ausrichtungsschritte des destillierten LLM. Während dieser Phase bleibt die MLP-Schicht eingefroren und die Mamba-Schicht wird trainiert.
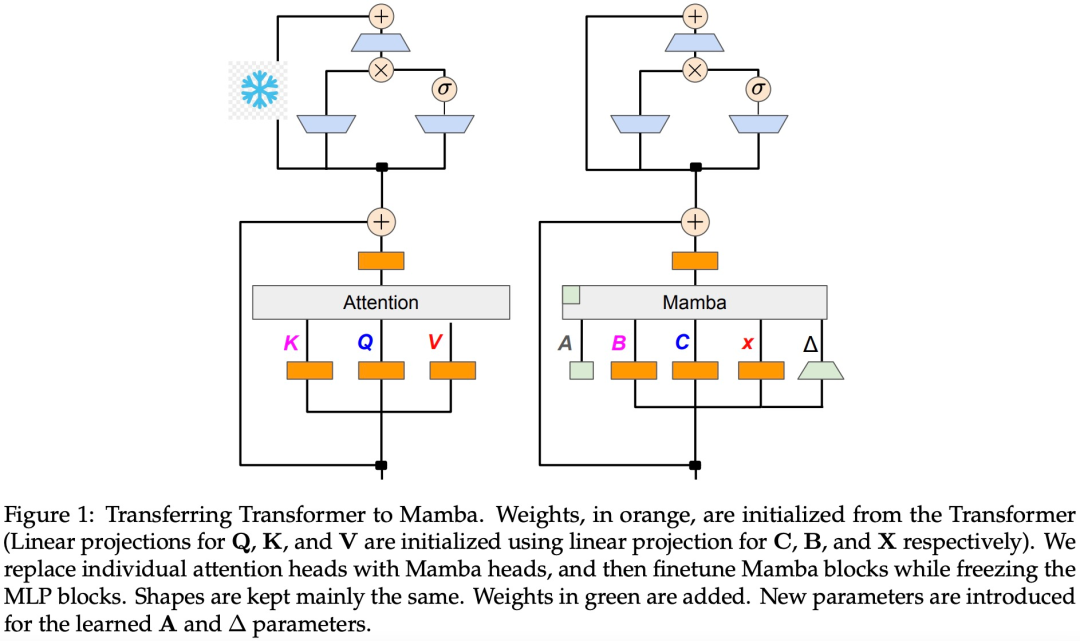
Diese Studie geht davon aus, dass es einige natürliche Zusammenhänge zwischen linearem RNN und Aufmerksamkeitsmechanismus gibt. Die Aufmerksamkeitsformel kann durch Entfernen von Softmax linearisiert werden:
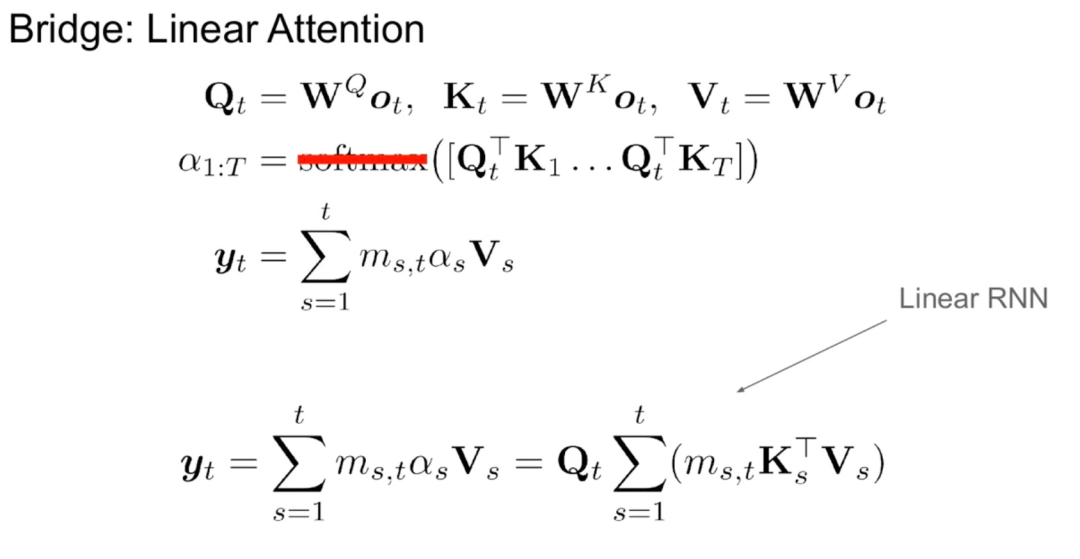
Aber die Linearisierung der Aufmerksamkeit führt zu einer Verschlechterung der Modellfähigkeiten. Um ein effizientes destilliertes lineares RNN zu entwerfen, kommt diese Studie der ursprünglichen Transformer-Parametrisierung so nahe wie möglich und erweitert gleichzeitig die Kapazität des linearen RNN auf effiziente Weise. Diese Studie versucht nicht, das neue Modell die genaue ursprüngliche Aufmerksamkeitsfunktion erfassen zu lassen, sondern verwendet stattdessen eine linearisierte Form als Ausgangspunkt für die Destillation.
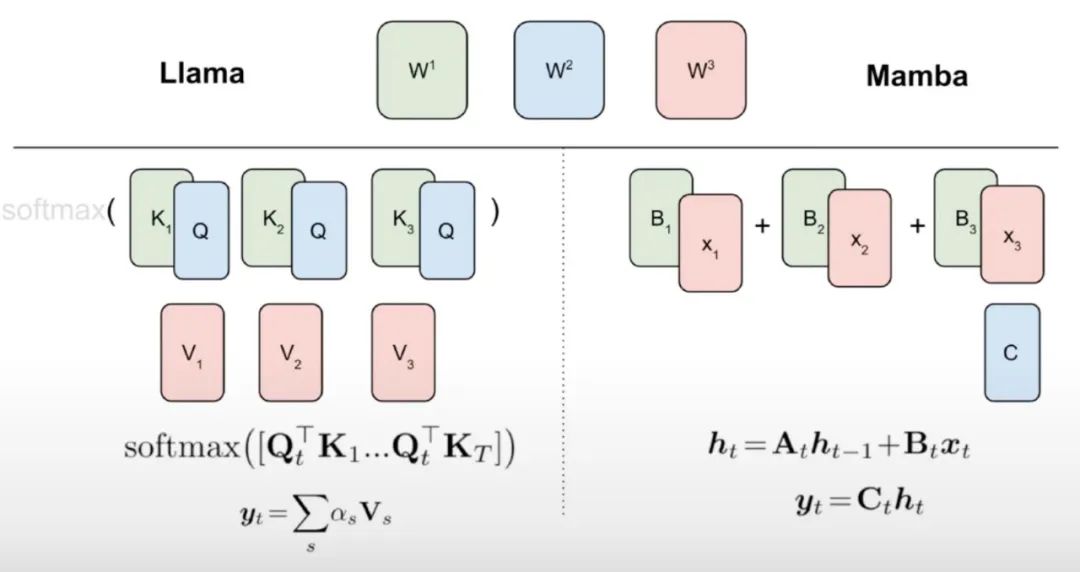
Wie in Algorithmus 1 gezeigt, speist diese Studie die Standard-Q-, K- und V-Köpfe vom Aufmerksamkeitsmechanismus direkt in die Mamba-Diskretisierung ein und wendet dann das resultierende lineare RNN an. Dies kann man sich so vorstellen, dass lineare Aufmerksamkeit für eine grobe Initialisierung verwendet wird und es dem Modell ermöglicht, durch erweiterte verborgene Zustände umfassendere Interaktionen zu lernen.

Diese Studie ersetzt den Transformer-Aufmerksamkeitskopf direkt durch eine fein abgestimmte lineare RNN-Schicht, wobei die Transformer-MLP-Schicht unverändert bleibt und sie nicht trainiert wird. Dieser Ansatz muss auch andere Komponenten verarbeiten, z. B. eine gruppierte Abfrageaufmerksamkeit, die Schlüssel und Werte über mehrere Köpfe hinweg teilt. Das Forschungsteam stellte fest, dass diese Architektur im Gegensatz zu denen, die in vielen Mamba-Systemen verwendet werden, es dieser Initialisierung ermöglicht, alle Aufmerksamkeitsblöcke durch lineare RNN-Blöcke zu ersetzen.
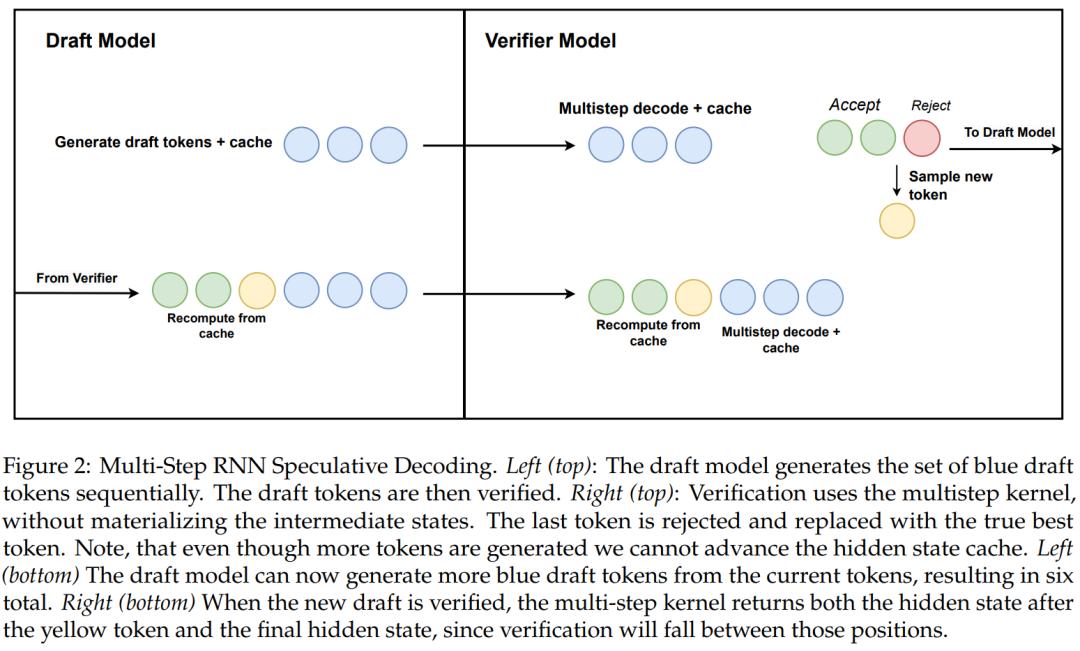
Die Forschung schlägt außerdem einen neuen Algorithmus für die lineare spekulative RNN-Dekodierung unter Verwendung hardwarebewusster mehrstufiger Generierung vor.
Algorithmus 2 und Abbildung 2 zeigen den vollständigen Algorithmus. Dieser Ansatz behält nur einen verborgenen RNN-Zustand zur Überprüfung im Cache und treibt ihn basierend auf dem Erfolg des mehrstufigen Kernels langsam voran. Da das Destillationsmodell Transformatorschichten enthält, erweitert diese Studie die spekulative Dekodierung auch auf eine Attention/RNN-Hybridarchitektur. In diesem Aufbau führt die RNN-Schicht eine Verifizierung gemäß Algorithmus 2 durch, während die Transformer-Schicht nur eine parallele Verifizierung durchführt.

Um die Wirksamkeit dieser Methode zu überprüfen, wurden in der Studie Mamba 7B und Mamba 2.8B als Zielmodelle für Spekulationen verwendet. Die Ergebnisse sind in Tabelle 1 aufgeführt.
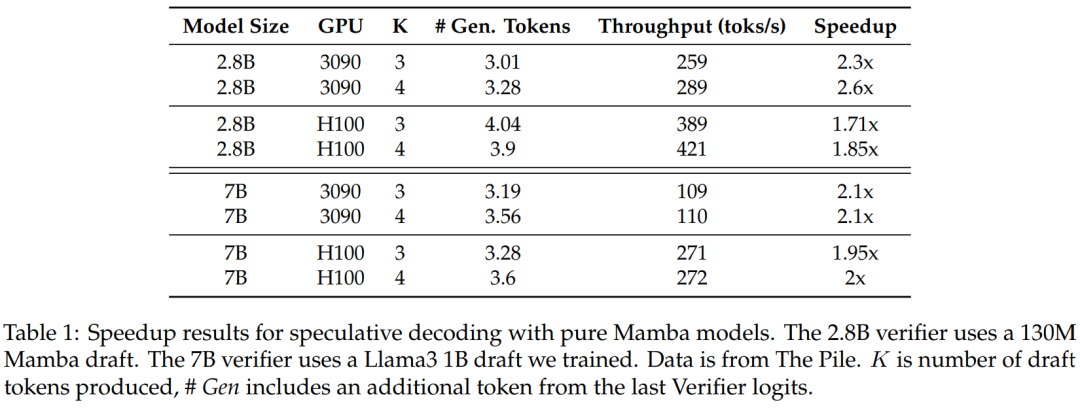
Abbildung 3 zeigt die Leistungsmerkmale des Multi-Step-Kernels selbst.
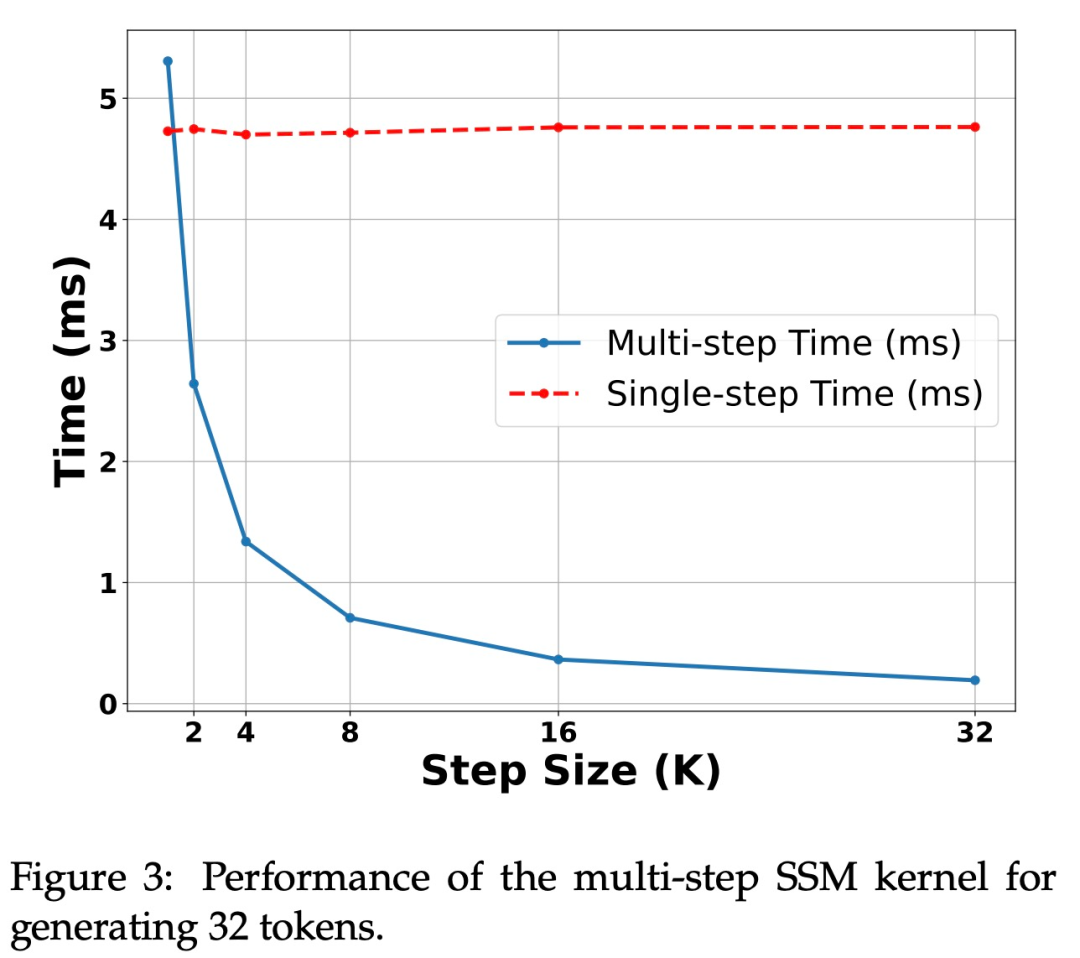
Beschleunigung auf der H100-GPU. Der in dieser Studie vorgeschlagene Algorithmus zeigt eine starke Leistung auf der Ampere-GPU, wie in Tabelle 1 oben gezeigt. Aber es gibt große Herausforderungen für die H100-GPU. Dies liegt hauptsächlich daran, dass GEMM-Operationen zu schnell sind, wodurch der durch Caching- und Neuberechnungsvorgänge verursachte Overhead stärker spürbar wird. Tatsächlich erzielte eine einfache Implementierung des untersuchten Algorithmus (unter Verwendung mehrerer verschiedener Kernel-Aufrufe) eine erhebliche Beschleunigung auf der 3090-GPU, jedoch überhaupt keine Beschleunigung auf der H100.
Experimente und Ergebnisse
Diese Studie verwendet zwei LLM-Chat-Modelle für Experimente: Zephyr-7B basiert auf dem Mistral-7B-Modell und Llama-3 Instruct 8B. Für das lineare RNN-Modell verwendet diese Studie eine Hybridversion von Mamba und Mamba2 mit Aufmerksamkeitsschichten von 50 %, 25 %, 12,5 % bzw. 0 % und nennt 0 % ein reines Mamba-Modell. Mamba2 ist eine Architekturvariante von Mamba, die hauptsächlich für aktuelle GPU-Architekturen entwickelt wurde.
Bewertung beim Chat-Benchmark
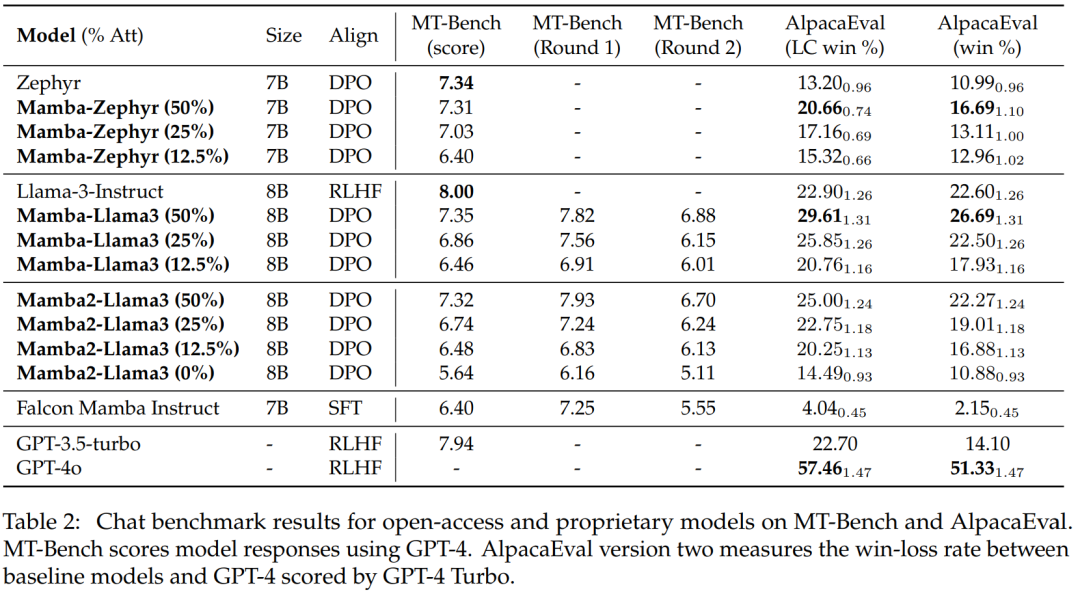
Tabelle 2 zeigt die Leistung des Modells beim Chat-Benchmark. Das wichtigste verglichene Modell ist das große Transformer-Modell. Die Ergebnisse zeigen:
Das destillierte Hybrid-Mamba-Modell (50 %) erzielt ähnliche Ergebnisse wie das Lehrermodell im MT-Benchmark und ist hinsichtlich der LC-Gewinnrate und etwas besser als das Lehrermodell im AlpacaEval-Benchmark Gesamtgewinnquote.
Die Leistung der destillierten Hybrid-Mamba (25 % und 12,5 %) ist etwas schlechter als die des Lehrermodells im MT-Benchmark, aber selbst mit mehr Parametern in AlpcaaEval übertrifft sie immer noch einige große Transformer.
Die Genauigkeit des destillierten reinen (0 %) Mamba-Modells nimmt erheblich ab.
Es ist erwähnenswert, dass das destillierte Hybridmodell eine bessere Leistung erbringt als Falcon Mamba, das von Grund auf mit mehr als 5T-Tokens trainiert wird.
Allgemeine Benchmark-Auswertung
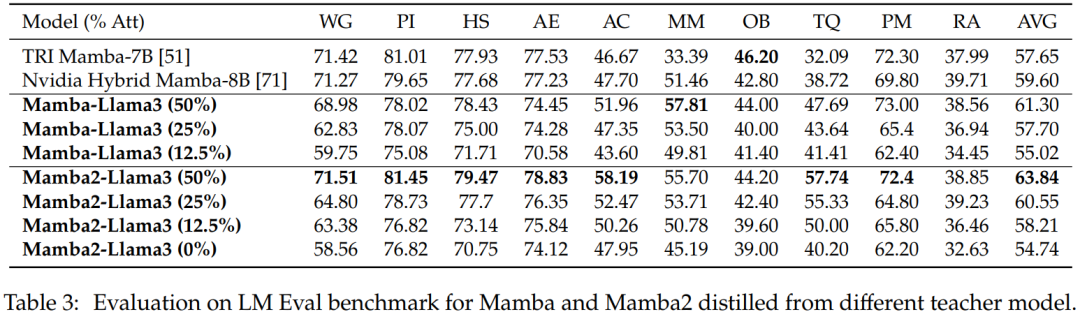
Nullstichprobenauswertung. Tabelle 3 zeigt die Zero-Shot-Leistung von Mamba und Mamba2, destilliert aus verschiedenen Lehrermodellen beim LM Eval-Benchmark. Die aus Llama-3 Instruct 8B destillierten Hybridmodelle Mamba-Llama3 und Mamba2-Llama3 schnitten im Vergleich zu den von Grund auf trainierten Open-Source-Modellen TRI Mamba und Nvidia Mamba besser ab.
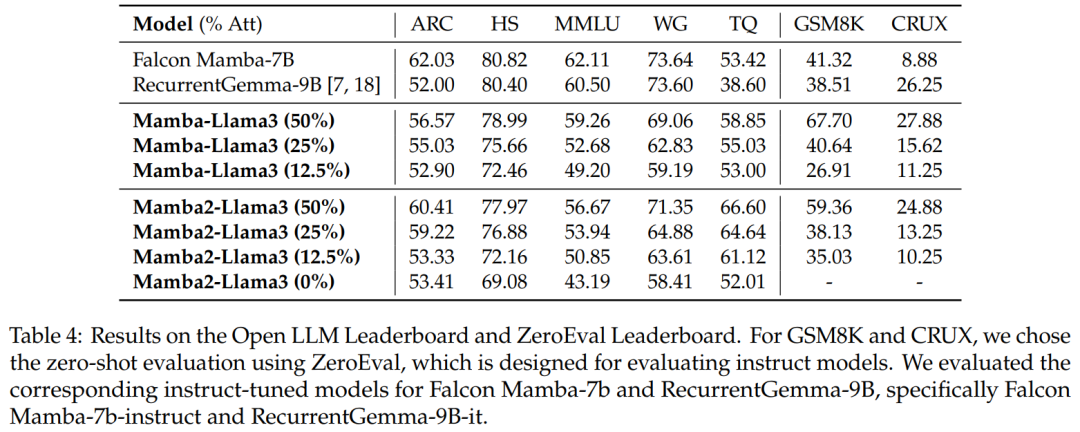
Benchmark-Bewertung. Tabelle 4 zeigt, dass die Leistung des destillierten Hybridmodells mit dem besten linearen Open-Source-RNN-Modell im Open LLM Leaderboard übereinstimmt und gleichzeitig das entsprechende Open-Source-Anweisungsmodell in GSM8K und CRUX übertrifft.
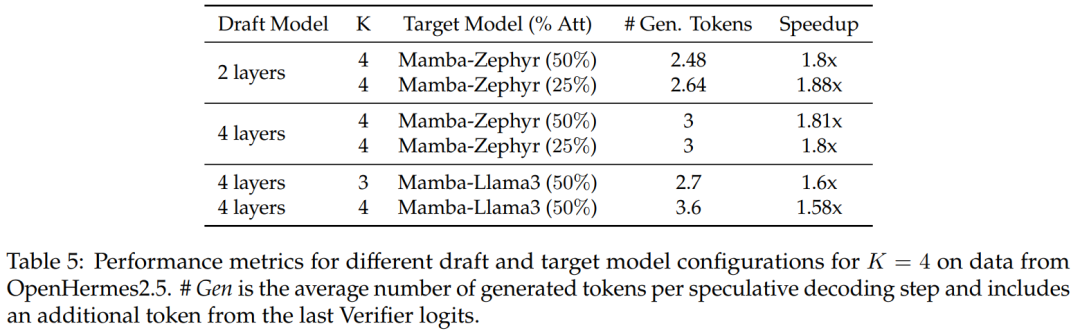
Hybride spekulative Dekodierung
Für die 50 %- und 25 %-Destillationsmodelle im Vergleich zur nicht spekulativen Basislinie, diese Studie Über 1,8-fache Beschleunigung auf Zephyr-Hybrid erreicht.
Experimente zeigen auch, dass das in dieser Studie trainierte 4-Schicht-Entwurfsmodell eine höhere Empfangsrate erreicht, aber aufgrund der Vergrößerung des Entwurfsmodells auch der zusätzliche Overhead größer wird. In der nachfolgenden Arbeit wird sich diese Forschung auf die Verkleinerung dieser Entwurfsmodelle konzentrieren.
Vergleich mit anderen Destillationsmethoden: Tabelle 6 (links) vergleicht die Ratlosigkeit verschiedener Modellvarianten. Die Studie führte eine Destillation innerhalb einer Epoche mit Ultrachat als Samenaufforderung durch und verglich die Verwirrung. Es stellt sich heraus, dass das Entfernen weiterer Schichten die Situation verschlimmert. Die Studie verglich die Destillationsmethode auch mit früheren Basislinien und stellte fest, dass die neue Methode einen geringeren Abbau aufwies, während das Distill Hyena-Modell anhand des WikiText-Datensatzes unter Verwendung eines viel kleineren Modells trainiert wurde und einen größeren Verwirrungsgrad des Abbaus aufwies.
Tabelle 6 (rechts) zeigt, dass die alleinige Verwendung von SFT oder DPO keine große Verbesserung bringt, während die Verwendung von SFT + DPO die beste Punktzahl liefert.
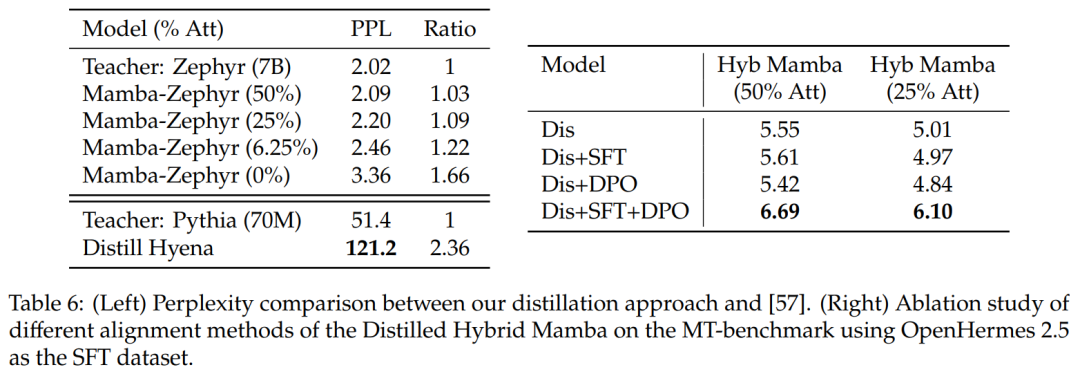
Tabelle 7 vergleicht Ablationsstudien für verschiedene Modelle. Tabelle 7 (links) zeigt die Destillationsergebnisse bei verschiedenen Initialisierungen und Tabelle 7 (rechts) zeigt die kleineren Gewinne durch progressive Destillation und verschachtelte Aufmerksamkeitsschichten mit Mamba.
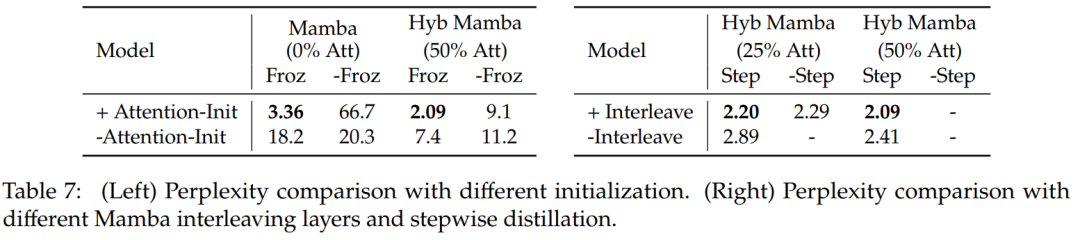
Tabelle 8 vergleicht die Leistung von Hybridmodellen mit zwei verschiedenen Initialisierungsmethoden: Die Ergebnisse bestätigen, dass die Initialisierung von Aufmerksamkeitsgewichten entscheidend ist.

Tabelle 9 vergleicht die Leistung von Modellen mit und ohne Mamba-Blöcke. Modelle mit Mamba-Blöcken schneiden deutlich besser ab als Modelle ohne Mamba-Blöcke. Dies bestätigt, dass das Hinzufügen der Mamba-Schicht von entscheidender Bedeutung ist und dass die Leistungsverbesserung nicht ausschließlich auf den verbleibenden Aufmerksamkeitsmechanismus zurückzuführen ist.

Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonNeue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr