
Heim >Backend-Entwicklung >Python-Tutorial >JIRA Analytics mit Pandas
JIRA Analytics mit Pandas

- 王林Original
- 2024-08-25 06:03:02905Durchsuche
Problem
Es ist schwer zu behaupten, dass Atlassian JIRA eine der beliebtesten Issue-Tracker und Projektmanagement-Lösungen ist. Sie können es lieben, Sie können es hassen, aber wenn Sie als Software-Ingenieur für ein Unternehmen angestellt wurden, besteht eine hohe Wahrscheinlichkeit, JIRA kennenzulernen.
Wenn das Projekt, an dem Sie arbeiten, sehr aktiv ist, kann es Tausende von JIRA-Vorgängen unterschiedlicher Art geben. Wenn Sie ein Team von Ingenieuren leiten, könnten Sie an Analysetools interessiert sein, die Ihnen helfen können, anhand der in JIRA gespeicherten Daten zu verstehen, was im Projekt vor sich geht. In JIRA sind einige Berichtsfunktionen sowie Plugins von Drittanbietern integriert. Aber die meisten davon sind ziemlich einfach. Es ist beispielsweise schwierig, relativ flexible „Prognose“-Tools zu finden.
Je größer das Projekt, desto unzufriedener sind Sie mit den integrierten Reporting-Tools. Irgendwann werden Sie eine API verwenden, um die Daten zu extrahieren, zu bearbeiten und zu visualisieren. Während der letzten 15 Jahre der JIRA-Nutzung habe ich Dutzende solcher Skripte und Dienste in verschiedenen Programmiersprachen in diesem Bereich gesehen.
Viele alltägliche Aufgaben erfordern möglicherweise eine einmalige Datenanalyse, daher lohnt es sich nicht, jedes Mal Dienste zu schreiben. Sie können JIRA als Datenquelle betrachten und einen typischen Werkzeuggürtel für die Datenanalyse verwenden. Sie können beispielsweise Jupyter verwenden, die Liste der letzten Fehler im Projekt abrufen, eine Liste von „Features“ (für die Analyse wertvolle Attribute) erstellen, Pandas zur Berechnung der Statistiken verwenden und versuchen, mithilfe von scikit-learn Trends vorherzusagen. In diesem Artikel möchte ich erklären, wie das geht.
Vorbereitung
JIRA-API-Zugriff
Hier werden wir über die Cloud-Version von JIRA sprechen. Wenn Sie jedoch eine selbst gehostete Version verwenden, sind die Hauptkonzepte fast dieselben.
Zuerst müssen wir einen geheimen Schlüssel erstellen, um über die REST-API auf JIRA zuzugreifen. Gehen Sie dazu zur Profilverwaltung – https://id.atlassian.com/manage-profile/profile-and-visibility. Wenn Sie den Reiter „Sicherheit“ auswählen, finden Sie den Link „API-Token erstellen und verwalten“:
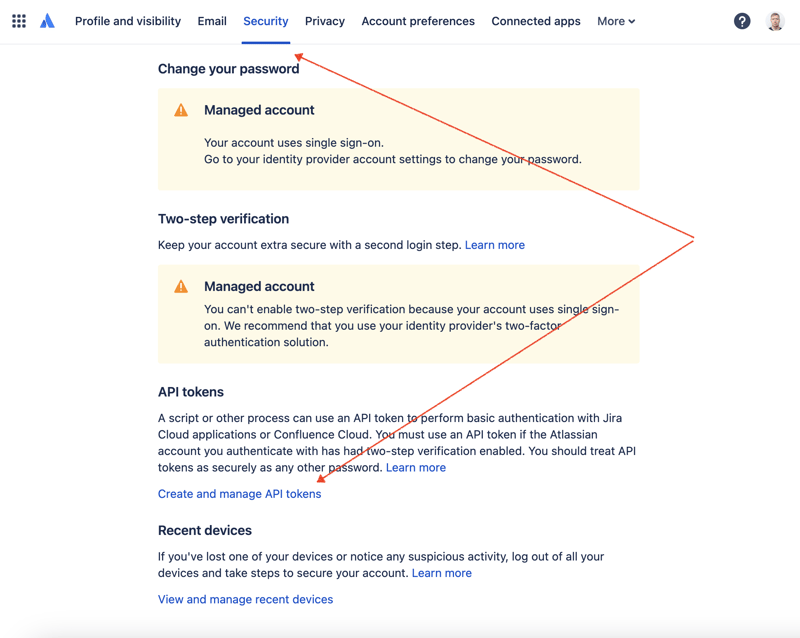
Erstellen Sie hier ein neues API-Token und bewahren Sie es sicher auf. Wir werden diesen Token später verwenden.
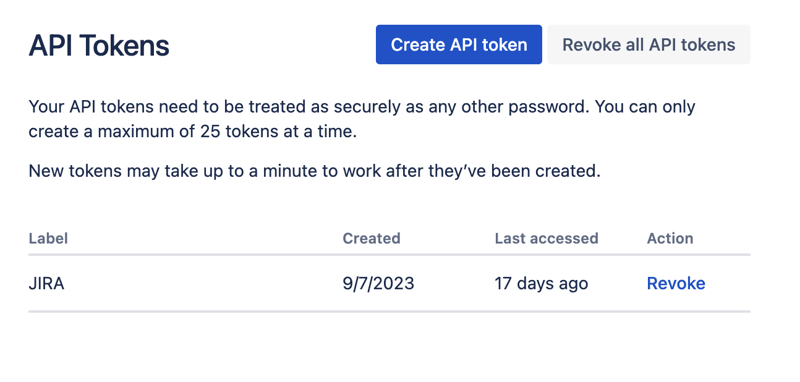
Jupyter-Notizbücher
Eine der bequemsten Möglichkeiten, mit Datensätzen zu spielen, ist die Verwendung von Jupyter. Wenn Sie mit diesem Tool nicht vertraut sind, machen Sie sich keine Sorgen. Ich werde zeigen, wie wir damit unser Problem lösen können. Für lokale Experimente verwende ich gerne DataSpell von JetBrains, es gibt aber auch Dienste, die online und kostenlos verfügbar sind. Einer der bekanntesten Dienste unter Datenwissenschaftlern ist Kaggle. Ihre Notebooks erlauben es Ihnen jedoch nicht, externe Verbindungen herzustellen, um über die API auf JIRA zuzugreifen. Ein weiterer sehr beliebter Dienst ist Colab von Google. Es ermöglicht Ihnen, Remote-Verbindungen herzustellen und zusätzliche Python-Module zu installieren.
JIRA verfügt über eine ziemlich einfach zu verwendende REST-API. Sie können API-Aufrufe mit Ihrer bevorzugten Methode für HTTP-Anfragen durchführen und die Antwort manuell analysieren. Zu diesem Zweck werden wir jedoch ein hervorragendes und sehr beliebtes Jira-Modul verwenden.
Werkzeuge in Aktion
Datenanalyse
Lassen Sie uns alle Teile kombinieren, um die Lösung zu finden.
Gehen Sie zur Google Colab-Benutzeroberfläche und erstellen Sie ein neues Notizbuch. Nach der Erstellung des Notizbuchs müssen wir zuvor erhaltene JIRA-Anmeldeinformationen als „Geheimnisse“ speichern. Klicken Sie auf das „Schlüssel“-Symbol in der linken Symbolleiste, um den entsprechenden Dialog zu öffnen und zwei „Geheimnisse“ mit den folgenden Namen hinzuzufügen: JIRA_USER und JIRA_PASSWORD. Am unteren Bildschirmrand sehen Sie, wie Sie auf diese „Geheimnisse“ zugreifen können:
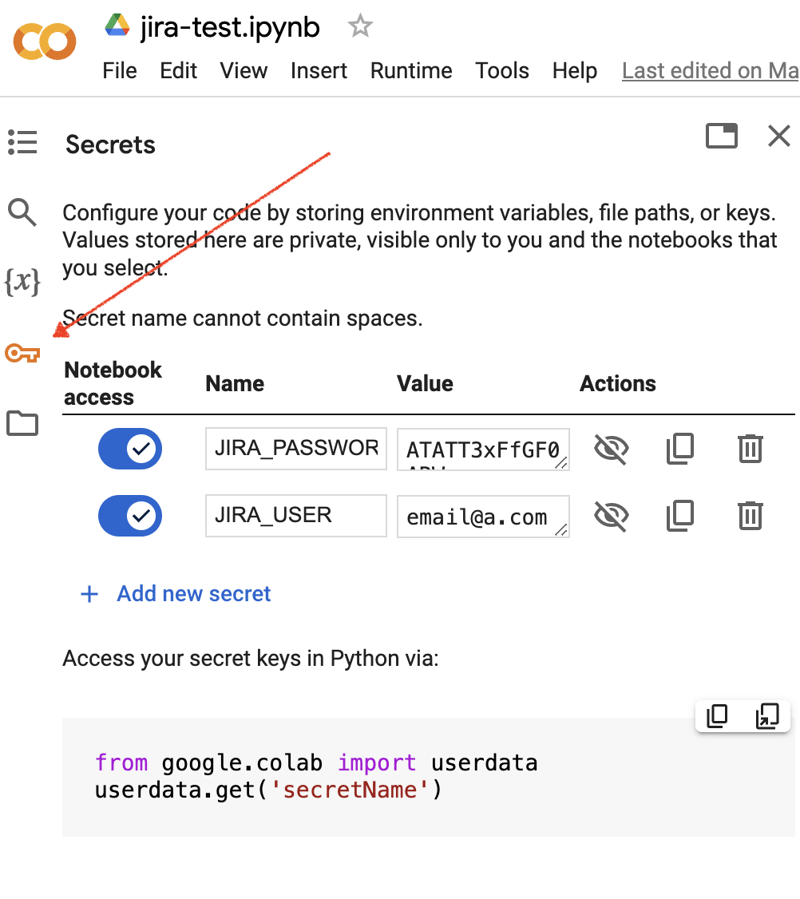
Als nächstes müssen Sie ein zusätzliches Python-Modul für die JIRA-Integration installieren. Wir können dies tun, indem wir den Shell-Befehl im Bereich der Notebook-Zelle ausführen:
!pip install jira
Die Ausgabe sollte etwa wie folgt aussehen:
Collecting jira
Downloading jira-3.8.0-py3-none-any.whl (77 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.5/77.5 kB 1.3 MB/s eta 0:00:00
Requirement already satisfied: defusedxml in /usr/local/lib/python3.10/dist-packages (from jira) (0.7.1)
...
Installing collected packages: requests-toolbelt, jira
Successfully installed jira-3.8.0 requests-toolbelt-1.0.0
Wir müssen die „Geheimnisse“/Anmeldeinformationen abrufen:
from google.colab import userdata
JIRA_URL = 'https://******.atlassian.net'
JIRA_USER = userdata.get('JIRA_USER')
JIRA_PASSWORD = userdata.get('JIRA_PASSWORD')
Und validieren Sie die Verbindung zur JIRA Cloud:
from jira import JIRA jira = JIRA(JIRA_URL, basic_auth=(JIRA_USER, JIRA_PASSWORD)) projects = jira.projects() projects
Wenn die Verbindung in Ordnung ist und die Anmeldeinformationen gültig sind, sollten Sie eine nicht leere Liste Ihrer Projekte sehen:
[<JIRA Project: key='PROJ1', name='Name here..', id='10234'>, <JIRA Project: key='PROJ2', name='Friendly name..', id='10020'>, <JIRA Project: key='PROJ3', name='One more project', id='10045'>, ...
Damit wir eine Verbindung herstellen und Daten von JIRA abrufen können. Der nächste Schritt besteht darin, einige Daten zur Analyse mit Pandas abzurufen. Versuchen wir, die Liste der in den letzten Wochen gelösten Probleme für ein Projekt abzurufen:
JIRA_FILTER = 19762
issues = jira.search_issues(
f'filter={JIRA_FILTER}',
maxResults=False,
fields='summary,issuetype,assignee,reporter,aggregatetimespent',
)
Wir müssen den Datensatz in den Pandas-Datenrahmen umwandeln:
import pandas as pd
df = pd.DataFrame([{
'key': issue.key,
'assignee': issue.fields.assignee and issue.fields.assignee.displayName or issue.fields.reporter.displayName,
'time': issue.fields.aggregatetimespent,
'summary': issue.fields.summary,
} for issue in issues])
df.set_index('key', inplace=True)
df
Die Ausgabe könnte wie folgt aussehen:
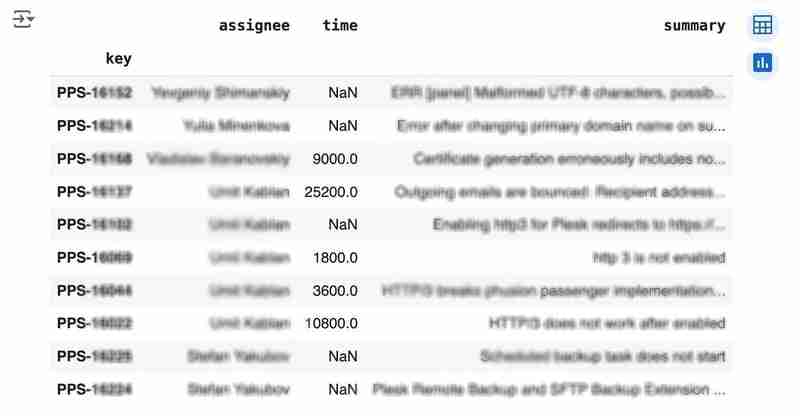
We would like to analyze how much time it usually takes to solve the issue. People are not ideal, so sometimes they forget to log the work. It brings a headache if you try to analyze such data using JIRA built-in tools. But it's not a problem for us to make some adjustments using pandas. For example, we can transform the "time" field from seconds into hours and replace the absent values with the median value (beware, dropna can be more suitable if there are a lot of gaps):
df['time'].fillna(df['time'].median(), inplace=True) df['time'] = df['time'] / 3600
We can easily visualize the distribution to find out anomalies:
df['time'].plot.bar(xlabel='', xticks=[])
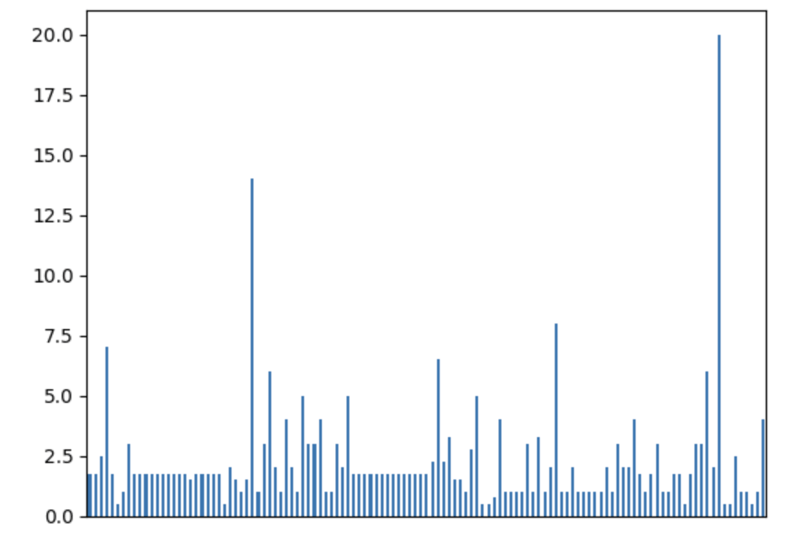
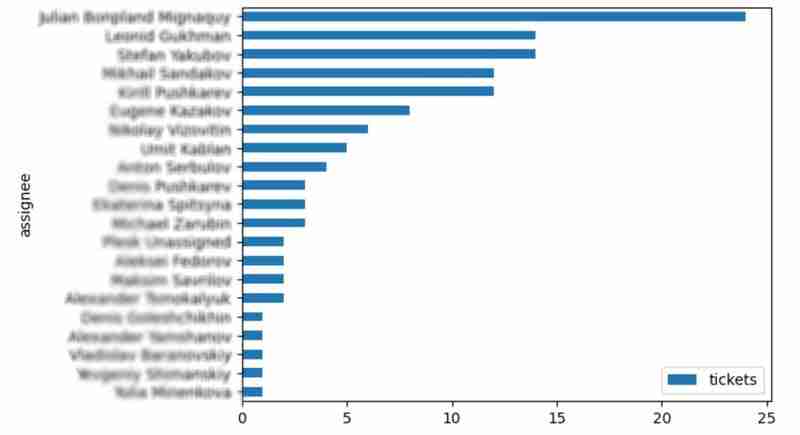
It is also interesting to see the distribution of solved problems by the assignee:
top_solvers = df.groupby('assignee').count()[['time']]
top_solvers.rename(columns={'time': 'tickets'}, inplace=True)
top_solvers.sort_values('tickets', ascending=False, inplace=True)
top_solvers.plot.barh().invert_yaxis()
It may look like the following:
Predictions
Let's try to predict the amount of time required to finish all open issues. Of course, we can do it without machine learning by using simple approximation and the average time to resolve the issue. So the predicted amount of required time is the number of open issues multiplied by the average time to resolve one. For example, the median time to solve one issue is 2 hours, and we have 9 open issues, so the time required to solve them all is 18 hours (approximation). It's a good enough forecast, but we might know the speed of solving depends on the product, team, and other attributes of the issue. If we want to improve the prediction, we can utilize machine learning to solve this task.
The high-level approach looks the following:
- Obtain the dataset for “learning”
- Clean up the data
- Prepare the "features" aka "feature engineering"
- Train the model
- Use the model to predict some value of the target dataset
For the first step, we will use a dataset of tickets for the last 30 weeks. Some parts here are simplified for illustrative purposes. In real life, the amount of data for learning should be big enough to make a useful model (e.g., in our case, we need thousands of issues to be analyzed).
issues = jira.search_issues(
f'project = PPS AND status IN (Resolved) AND created >= -30w',
maxResults=False,
fields='summary,issuetype,customfield_10718,customfield_10674,aggregatetimespent',
)
closed_tickets = pd.DataFrame([{
'key': issue.key,
'team': issue.fields.customfield_10718,
'product': issue.fields.customfield_10674,
'time': issue.fields.aggregatetimespent,
} for issue in issues])
closed_tickets.set_index('key', inplace=True)
closed_tickets['time'].fillna(closed_tickets['time'].median(), inplace=True)
closed_tickets
In my case, it's something around 800 tickets and only two fields for "learning": "team" and "product."
The next step is to obtain our target dataset. Why do I do it so early? I want to clean up and do "feature engineering" in one shot for both datasets. Otherwise, the mismatch between the structures can cause problems.
issues = jira.search_issues(
f'project = PPS AND status IN (Open, Reopened)',
maxResults=False,
fields='summary,issuetype,customfield_10718,customfield_10674',
)
open_tickets = pd.DataFrame([{
'key': issue.key,
'team': issue.fields.customfield_10718,
'product': issue.fields.customfield_10674,
} for issue in issues])
open_tickets.set_index('key', inplace=True)
open_tickets
Please notice we have no "time" column here because we want to predict it. Let's nullify it and combine both datasets to prepare the "features."
open_tickets['time'] = 0 tickets = pd.concat([closed_tickets, open_tickets]) tickets
Columns "team" and "product" contain string values. One of the ways of dealing with that is to transform each value into separate fields with boolean flags.
products = pd.get_dummies(tickets['product'], prefix='product')
tickets = pd.concat([tickets, products], axis=1)
tickets.drop('product', axis=1, inplace=True)
teams = pd.get_dummies(tickets['team'], prefix='team')
tickets = pd.concat([tickets, teams], axis=1)
tickets.drop('team', axis=1, inplace=True)
tickets
The result may look like the following:
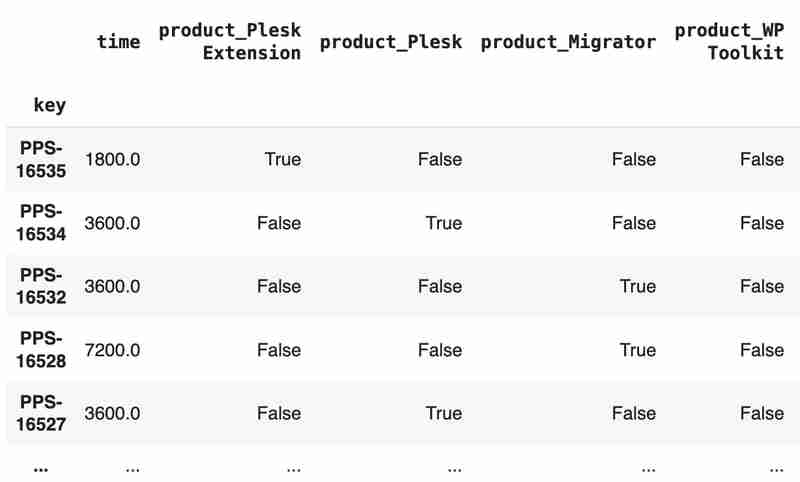
After the combined dataset preparation, we can split it back into two parts:
closed_tickets = tickets[:len(closed_tickets)] open_tickets = tickets[len(closed_tickets):][:]
Now it's time to train our model:
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeRegressor features = closed_tickets.drop(['time'], axis=1) labels = closed_tickets['time'] features_train, features_val, labels_train, labels_val = train_test_split(features, labels, test_size=0.2) model = DecisionTreeRegressor() model.fit(features_train, labels_train) model.score(features_val, labels_val)
And the final step is to use our model to make a prediction:
open_tickets['time'] = model.predict(open_tickets.drop('time', axis=1, errors='ignore'))
open_tickets['time'].sum() / 3600
The final output, in my case, is 25 hours, which is higher than our initial rough estimation. This was a basic example. However, by using ML tools, you can significantly expand your abilities to analyze JIRA data.
Conclusion
Sometimes, JIRA built-in tools and plugins are not sufficient for effective analysis. Moreover, many 3rd party plugins are rather expensive, costing thousands of dollars per year, and you will still struggle to make them work the way you want. However, you can easily utilize well-known data analysis tools by fetching necessary information via JIRA API and go beyond these limitations. I spent so many hours playing with various JIRA plugins in attempts to create good reports for projects, but they often missed some important parts. Building a tool or a full-featured service on top of JIRA API also often looks like overkill. That's why typical data analysis and ML tools like Jupiter, pandas, matplotlib, scikit-learn, and others may work better here.

Das obige ist der detaillierte Inhalt vonJIRA Analytics mit Pandas. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!