
Heim >Technologie-Peripheriegeräte >KI >NVIDIA „LongVILA' unterstützt 1024 Bilder und eine Genauigkeit von nahezu 100 % und beginnt mit der Entwicklung langer Videos
NVIDIA „LongVILA' unterstützt 1024 Bilder und eine Genauigkeit von nahezu 100 % und beginnt mit der Entwicklung langer Videos

- 王林Original
- 2024-08-21 16:35:04671Durchsuche
Jetzt verfügt das Long Context Visual Language Model (VLM) über eine neue Full-Stack-Lösung – LongVILA, die System, Modelltraining und Datenentwicklung integriert in eins.

Papieradresse: https://arxiv.org/pdf/2408.10188 Codeadresse: https://github.com/NVlabs/VILA/blob/main/LongVILA.md -
Titel des Papiers: LONGVILA: SCALING LONG-CONTEXT VISUAL LANGUAGE MODELS FOR LONG VIDEOS
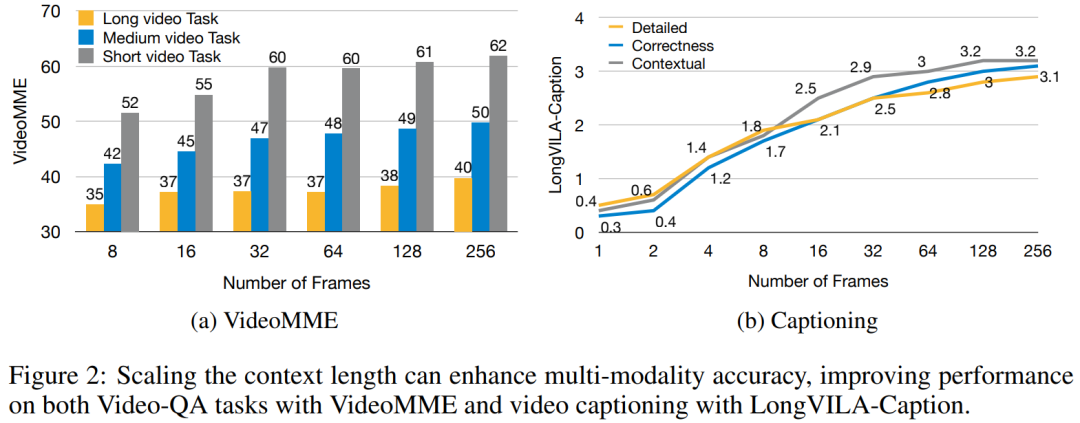

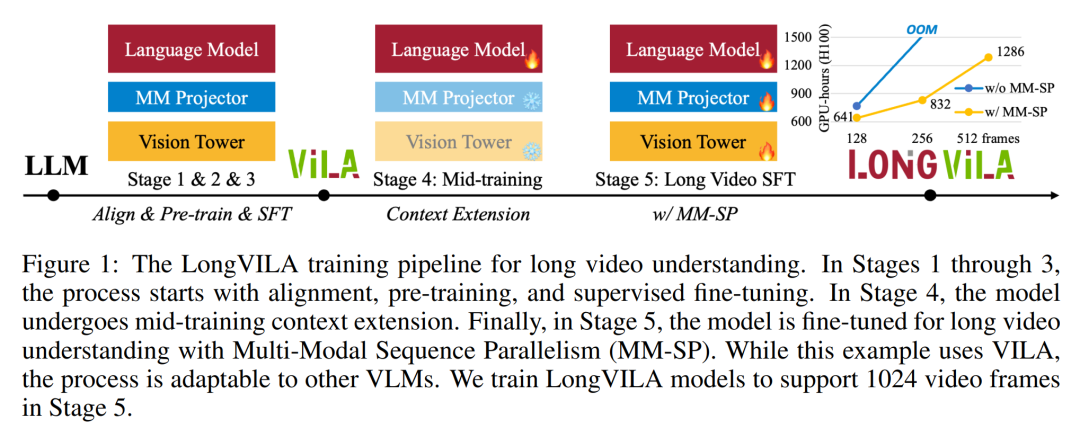
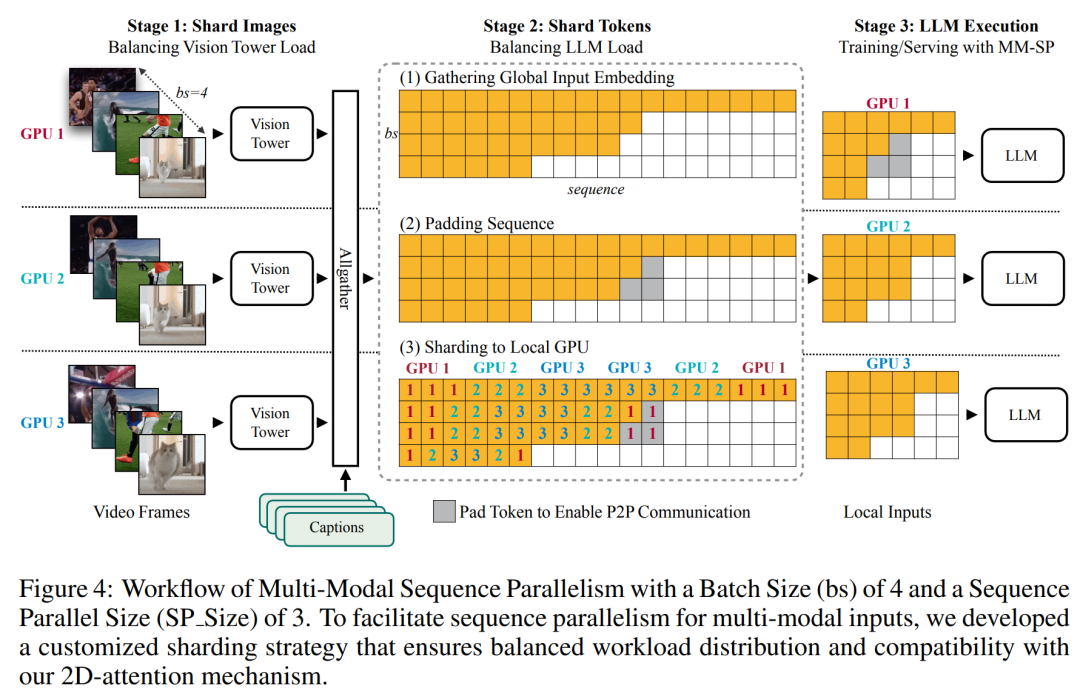

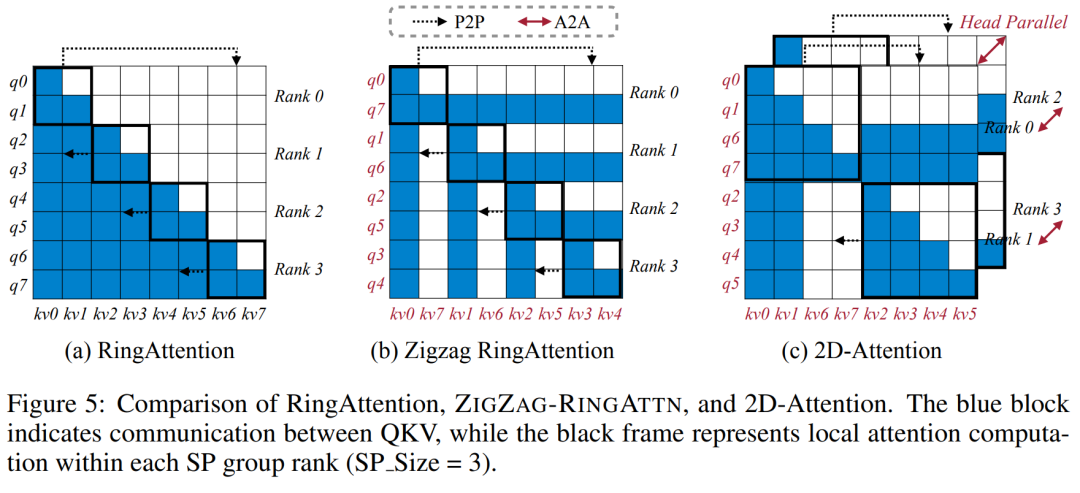
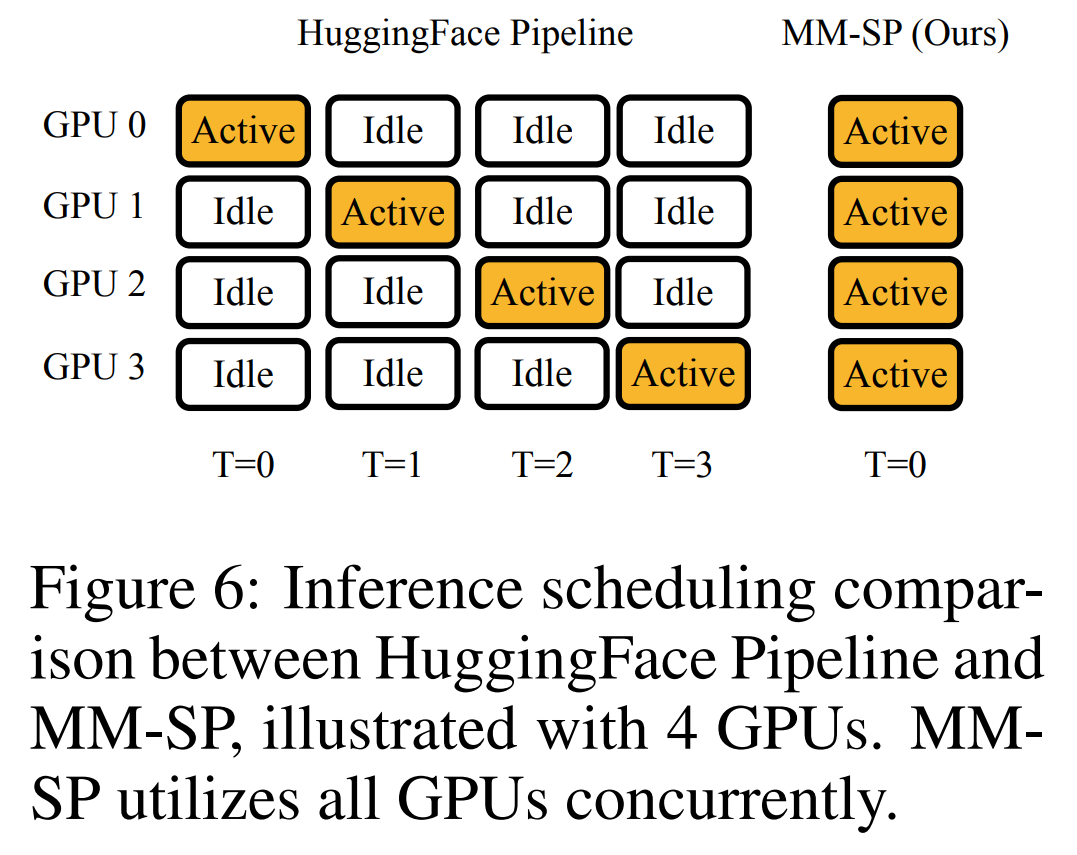
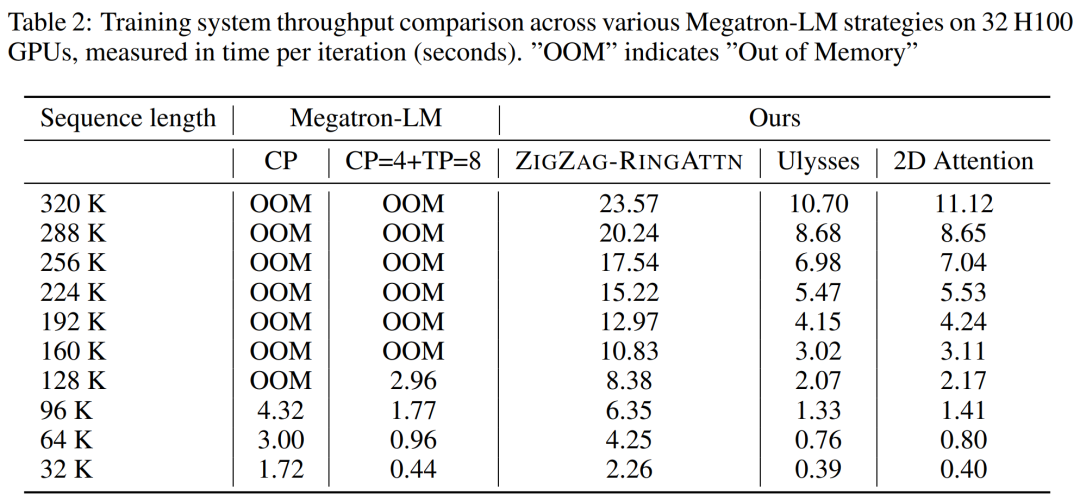
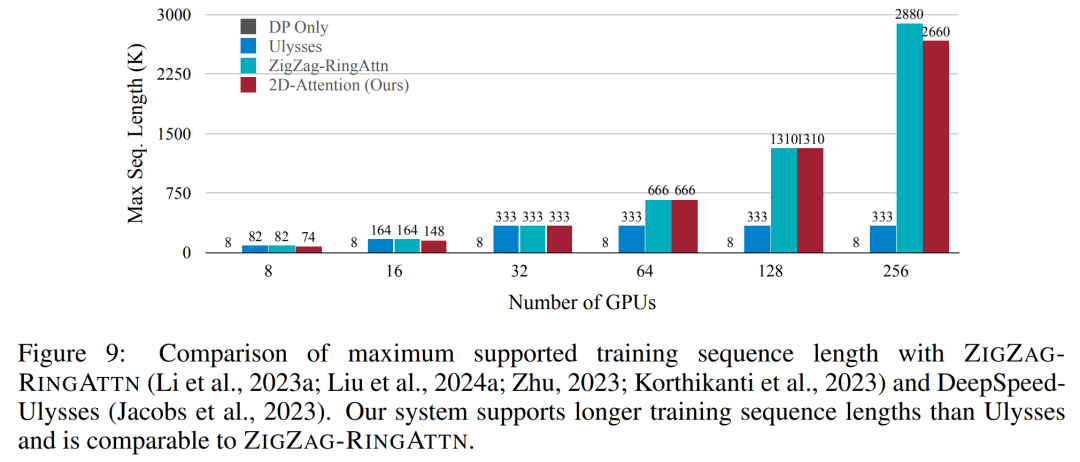

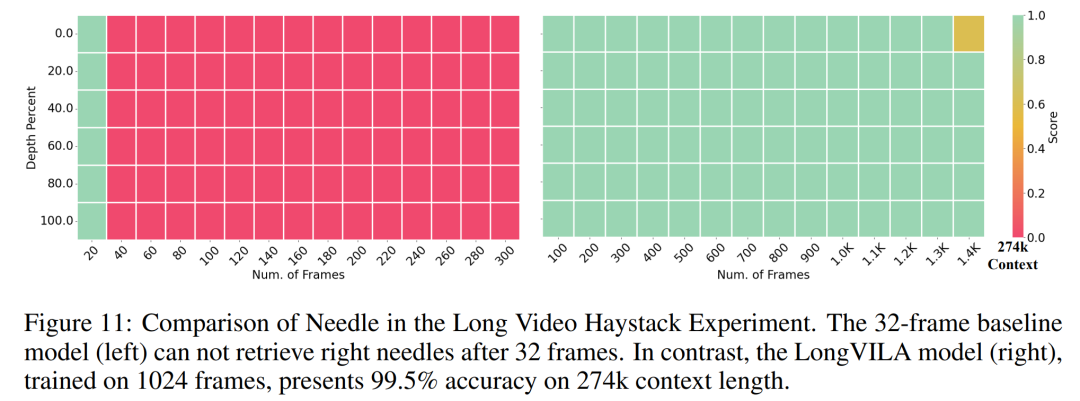
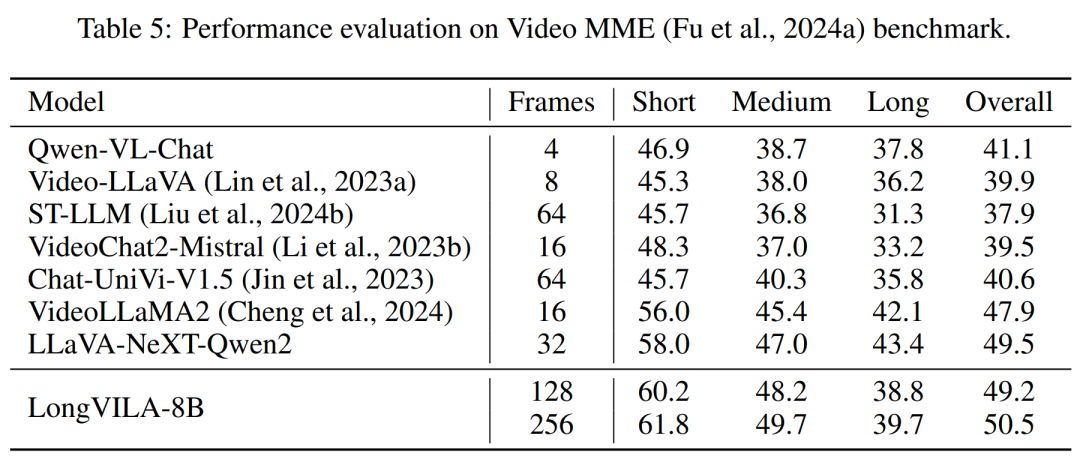
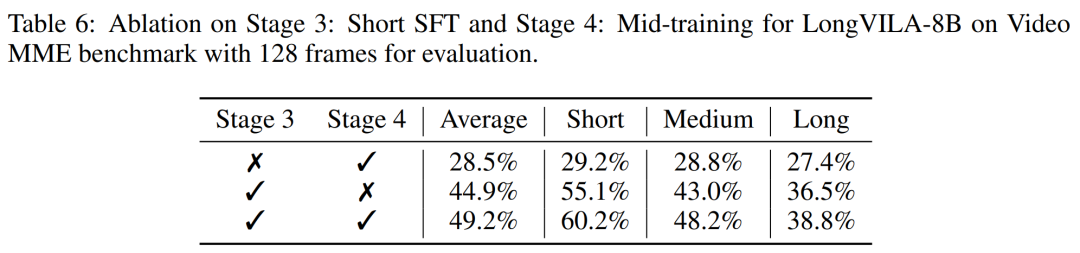
Das obige ist der detaillierte Inhalt vonNVIDIA „LongVILA' unterstützt 1024 Bilder und eine Genauigkeit von nahezu 100 % und beginnt mit der Entwicklung langer Videos. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:Ohne Elsevier kann das MIT jedes Jahr 2 Millionen US-Dollar einsparen.Nächster Artikel:Ohne Elsevier kann das MIT jedes Jahr 2 Millionen US-Dollar einsparen.
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr