Das große Modell der Mamba-Architektur hat Transformer erneut herausgefordert.
Wird sich das Mamba-Architekturmodell dieses Mal endlich durchsetzen? Seit seiner Ersteinführung im Dezember 2023 hat sich der Mamba zu einem ernsthaften Konkurrenten des Transformers entwickelt. Seitdem sind weiterhin Modelle erschienen, die die Mamba-Architektur verwenden, wie beispielsweise Codestral 7B, das erste von Mistral veröffentlichte Open-Source-Großmodell auf Basis der Mamba-Architektur. Heute hat das Abu Dhabi Technology Innovation Institute (TII) ein neues Open-Source-Mamba-Modell veröffentlicht – Falcon Mamba 7B. 
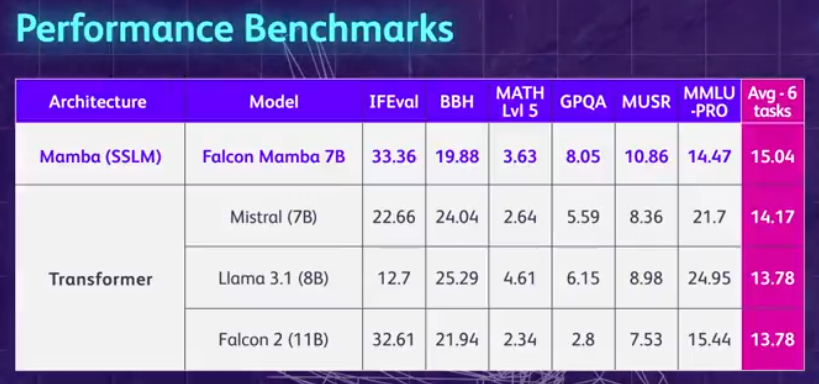
Fassen wir zunächst die Highlights der Falcon Mamba 7B zusammen: Sie kann Sequenzen beliebiger Länge verarbeiten, ohne den Speicher zu erhöhen, und sie kann auf einer einzigen 24-GB-A10-GPU ausgeführt werden. Sie können Falcon Mamba 7B derzeit auf Hugging Face anzeigen und verwenden. Dieses reine Kausal-Decoder-Modell verwendet die neuartige Mamba State Space Language Model (SSLM)-Architektur, um verschiedene Textgenerierungsaufgaben zu bewältigen. Den Ergebnissen zufolge übertrifft die Falcon Mamba 7B in mehreren Benchmarks führende Modelle ihrer Größenklasse, darunter Metas Llama 3 8B, Llama 3.1 8B und Mistral 7B.
Falcon Mamba 7B ist in vier Variantenmodelle unterteilt, nämlich die Basisversion, die Befehls-Feinabstimmungsversion, die 4-Bit-Version und die Befehls-Feinabstimmungs-4-Bit-Version.

Als Open-Source-Modell übernimmt Falcon Mamba 7B die Apache 2.0-basierte Lizenz „Falcon License 2.0“, um Forschungs- und Anwendungszwecke zu unterstützen.
Hugging Face-Adresse: https://huggingface.co/tiiuae/falcon-mamba-7b
Falcon Mamba 7B ist nach Falcon 180B, Falcon 40B und Falcon 2 Four auch der dritte TII Open Source Modelle, und es ist das
erste Mamba SSLM-Architekturmodell.  The first general-purpose large-scale pure Mamba modelFor a long time, Transformer-based models have dominated generative AI. However, researchers have noticed that the Transformer architecture has difficulty processing long text information. Difficulties may be encountered. Essentially, the attention mechanism in Transformer understands the context by comparing each word (or token) with each word in the text, which requires more computing power and memory requirements to handle the growing context window. But if the computing resources are not expanded accordingly, the model inference speed will slow down, and text exceeding a certain length cannot be processed. To overcome these obstacles, the State Space Language Model (SSLM) architecture, which works by continuously updating the state while processing words, has emerged as a promising alternative and is being deployed by many institutions including TII. This kind of architecture. Falcon Mamba 7B uses the Mamba SSM architecture originally proposed in a December 2023 paper by researchers at Carnegie Mellon University and Princeton University. The architecture uses a selection mechanism that allows the model to dynamically adjust its parameters based on the input. In this way, the model can focus on or ignore specific inputs, similar to how the attention mechanism works in Transformer, while providing the ability to process long sequences of text (such as entire books) without requiring additional memory or computing resources. TII noted that this approach makes the model suitable for tasks such as enterprise-level machine translation, text summarization, computer vision and audio processing tasks, and estimation and prediction. Falcon Mamba 7B Training data is up to 5500GT, mainly composed of RefinedWeb dataset, with the addition of high-quality technical data, code data and mathematical data from public sources. All data is tokenized using Falcon-7B/11B tokenizers. Similar to other Falcon series models, Falcon Mamba 7B is trained using a multi-stage training strategy, the context length is increased from 2048 to 8192. In addition, inspired by the concept of course learning, TII carefully selects mixed data throughout the training phase, fully considering the diversity and complexity of the data. In the final training stage, TII uses a small set of high-quality curated data (i.e. samples from Fineweb-edu) to further improve performance. Training process, hyperparameters Most of the training of Falcon Mamba 7B is completed on 256 H100 80GB GPUs, using 3D parallelism (TP=1, PP=1, DP=256) strategy combined with ZeRO. The figure below shows the model hyperparameter details, including accuracy, optimizer, maximum learning rate, weight decay and batch size.
The first general-purpose large-scale pure Mamba modelFor a long time, Transformer-based models have dominated generative AI. However, researchers have noticed that the Transformer architecture has difficulty processing long text information. Difficulties may be encountered. Essentially, the attention mechanism in Transformer understands the context by comparing each word (or token) with each word in the text, which requires more computing power and memory requirements to handle the growing context window. But if the computing resources are not expanded accordingly, the model inference speed will slow down, and text exceeding a certain length cannot be processed. To overcome these obstacles, the State Space Language Model (SSLM) architecture, which works by continuously updating the state while processing words, has emerged as a promising alternative and is being deployed by many institutions including TII. This kind of architecture. Falcon Mamba 7B uses the Mamba SSM architecture originally proposed in a December 2023 paper by researchers at Carnegie Mellon University and Princeton University. The architecture uses a selection mechanism that allows the model to dynamically adjust its parameters based on the input. In this way, the model can focus on or ignore specific inputs, similar to how the attention mechanism works in Transformer, while providing the ability to process long sequences of text (such as entire books) without requiring additional memory or computing resources. TII noted that this approach makes the model suitable for tasks such as enterprise-level machine translation, text summarization, computer vision and audio processing tasks, and estimation and prediction. Falcon Mamba 7B Training data is up to 5500GT, mainly composed of RefinedWeb dataset, with the addition of high-quality technical data, code data and mathematical data from public sources. All data is tokenized using Falcon-7B/11B tokenizers. Similar to other Falcon series models, Falcon Mamba 7B is trained using a multi-stage training strategy, the context length is increased from 2048 to 8192. In addition, inspired by the concept of course learning, TII carefully selects mixed data throughout the training phase, fully considering the diversity and complexity of the data. In the final training stage, TII uses a small set of high-quality curated data (i.e. samples from Fineweb-edu) to further improve performance. Training process, hyperparameters Most of the training of Falcon Mamba 7B is completed on 256 H100 80GB GPUs, using 3D parallelism (TP=1, PP=1, DP=256) strategy combined with ZeRO. The figure below shows the model hyperparameter details, including accuracy, optimizer, maximum learning rate, weight decay and batch size.

Specifically, Falcon Mamba 7B was trained with the AdamW optimizer, WSD (warm-stabilize-decay) learning rate plan, and during the training process of the first 50 GT, the batch size increased from b_min=128 to b_max=2048 . In the stable phase, TII uses the maximum learning rate η_max=6.4×10^−4, and then decays it to the minimum value using an exponential plan over 500GT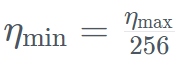 . At the same time, TII uses BatchScaling in the acceleration phase to re-adjust the learning rate η so that the Adam noise temperature
. At the same time, TII uses BatchScaling in the acceleration phase to re-adjust the learning rate η so that the Adam noise temperature 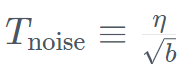 remains constant. The entire model training took about two months. To understand how Falcon Mamba 7B compares to leading Transformer models in its size class, the study conducted a test to determine what the model can handle using a single 24GB A10 GPU Maximum context length. The results show that Falcon Mamba is able to adapt to larger sequences than the current Transformer model, while theoretically able to adapt to unlimited context lengths.
remains constant. The entire model training took about two months. To understand how Falcon Mamba 7B compares to leading Transformer models in its size class, the study conducted a test to determine what the model can handle using a single 24GB A10 GPU Maximum context length. The results show that Falcon Mamba is able to adapt to larger sequences than the current Transformer model, while theoretically able to adapt to unlimited context lengths. 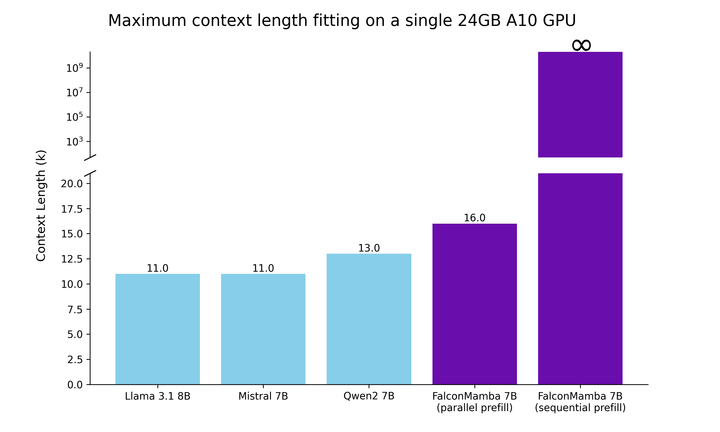
Next, the researchers measured the model generation throughput using a batch size of 1 and a hardware setting of H100 GPU. The results are shown in the figure below, Falcon Mamba generates all tokens at constant throughput without any increase in CUDA peak memory. For Transformer models, peak memory increases and generation speed slows down as the number of tokens generated increases. 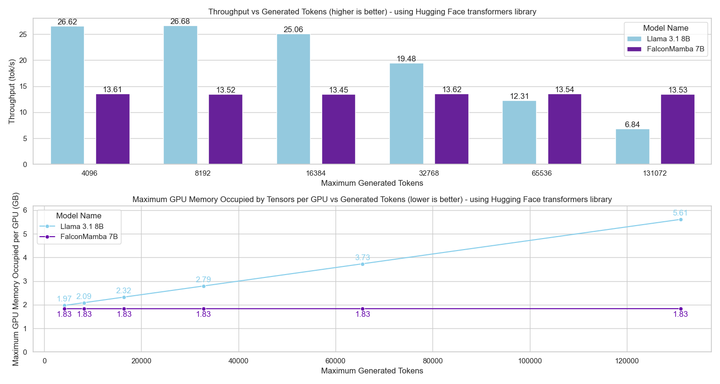
Even on standard industry benchmarks, the new model performs better than or close to popular transformer models as well as pure and hybrid state-space models. For example, in the Arc, TruthfulQA and GSM8K benchmarks, Falcon Mamba 7B scored 62.03%, 53.42% and 52.54% respectively, surpassing Llama 3 8B, Llama 3.1 8B, Gemma 7B and Mistral 7B. However, the Falcon Mamba 7B lags far behind these models in the MMLU and Hellaswag benchmarks. 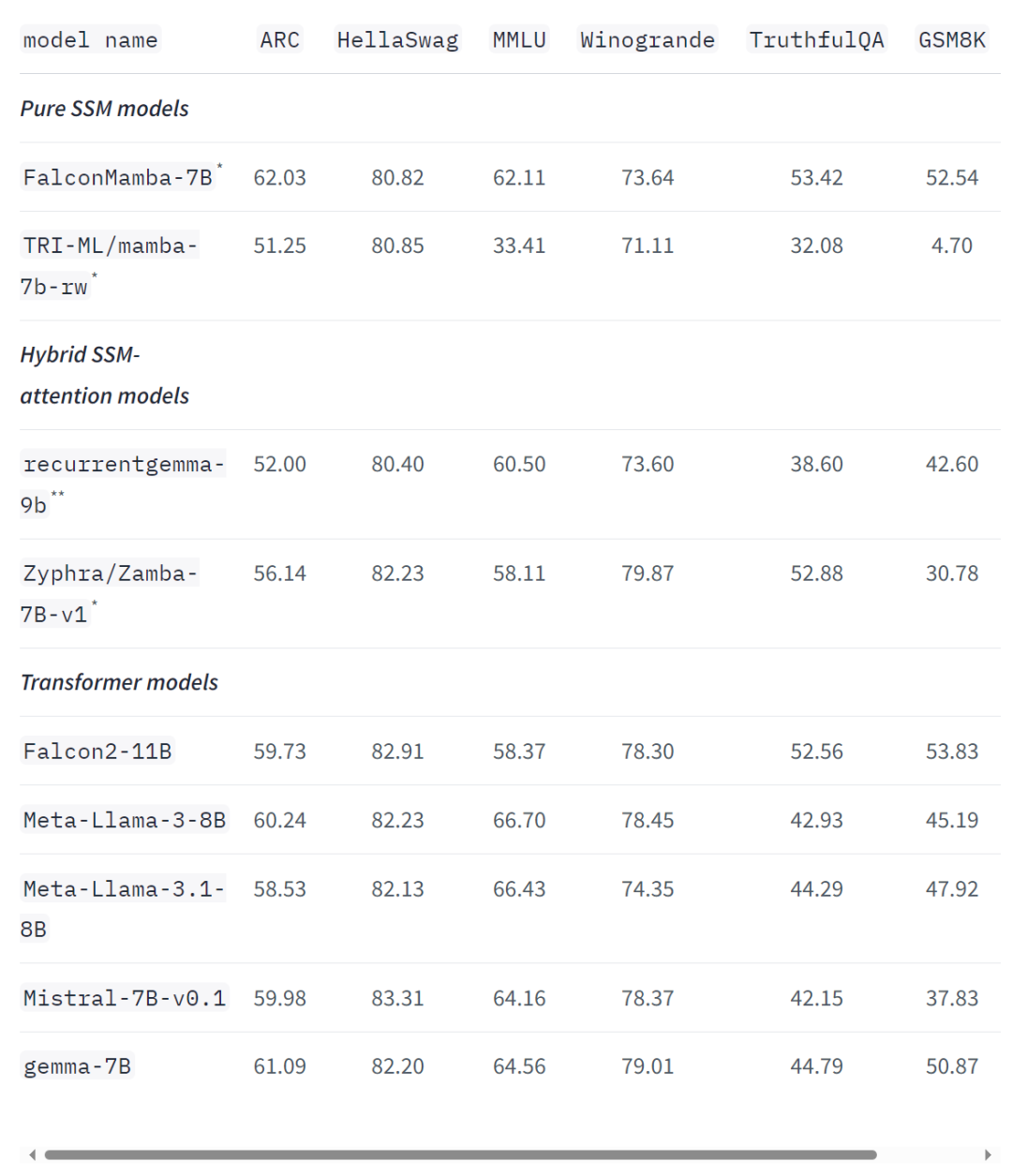

TII principal investigator Hakim Hacid said in a statement: The launch of Falcon Mamba 7B represents a major step forward for the agency, inspiring new perspectives and furthering the push for intelligence Systematic exploration. At TII, they are pushing the boundaries of SSLM and transformer models to inspire further innovation in generative AI. Currently, TII’s Falcon family of language models has been downloaded more than 45 million times – making it one of the most successful LLM versions in the UAE. Falcon Mamba 7B paper will be released soon, you can wait a moment. https://huggingface.co/blog/falconmambahttps://venturebeat.com/ai/falcon-mamba-7bs-powerful -new-ai-architecture-offers-alternative-to-transformer-models/Das obige ist der detaillierte Inhalt vonDie Non-Transformer-Architektur steht auf! Das erste rein aufmerksamkeitsfreie Großmodell, das den Open-Source-Riesen Llama 3.1 übertrifft. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

