Hybrid-Experten verfügen auch über Spezialisierungen im Bereich Chirurgie.
Für das aktuelle Basismodell mit gemischter Modalität besteht das übliche Architekturdesign darin, den Encoder oder Decoder einer bestimmten Modalität zu verschmelzen. Diese Methode weist jedoch Einschränkungen auf: Sie kann keine Informationen aus verschiedenen Modalitäten integrieren und ist schwierig zur Ausgabe. Enthält Inhalte in mehreren Modalitäten. Um diese Einschränkung zu überwinden, hat das Chameleon-Team von Meta FAIR in der kürzlich erschienenen Arbeit „Chameleon: Mixed-modal Early-Fusion Foundation Models“ eine neue Single-Transformer-Architektur vorgeschlagen, die auf dem nächsten Token basieren kann. Das Vorhersageziel besteht darin, gemischtmodale Sequenzen zu modellieren, die aus diskreten Bild- und Text-Tokens bestehen und eine nahtlose Schlussfolgerung und Generierung zwischen verschiedenen Modalitäten ermöglichen. 
Nach Abschluss des Vortrainings auf etwa 10 Billionen gemischtmodalen Token hat Chameleon ein breites Spektrum an visuellen und sprachlichen Fähigkeiten unter Beweis gestellt und kann eine Vielzahl verschiedener nachgelagerter Aufgaben gut bewältigen. Besonders beeindruckend ist die Leistung von Chameleon bei der Generierung gemischtmodaler langer Antworten. Es übertrifft sogar kommerzielle Modelle wie Gemini 1.0 Pro und GPT-4V. Bei einem Modell wie Chameleon, bei dem in den frühen Phasen des Modelltrainings verschiedene Modalitäten gemischt werden, erfordert die Erweiterung seiner Fähigkeiten jedoch die Investition einer großen Rechenleistung. Basierend auf den oben genannten Problemen führte das Meta FAIR-Team einige Untersuchungen und Untersuchungen zur gerouteten Sparse-Architektur durch und schlug MoMa vor: Modalitätsbewusste Experten-Hybridarchitektur.
- Papiertitel: MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
- Papieradresse: https://arxiv.org/pdf/2407.21770
Vorherige Forschung hat gezeigt, dass diese Art von Architektur die Fähigkeiten einmodaler Basismodelle effektiv erweitern und die Leistung multimodaler kontrastiver Lernmodelle verbessern kann. Allerdings ist der Einsatz für das frühe Modelltraining, das verschiedene Modalitäten integriert, immer noch ein Thema mit Chancen und Herausforderungen, und nur wenige Menschen haben sich damit befasst. Die Forschung des Teams basiert auf der Erkenntnis, dass verschiedene Modalitäten von Natur aus heterogen sind – Text- und Bild-Tokens weisen unterschiedliche Informationsdichten und Redundanzmuster auf. Während der Integration dieser Token in eine einheitliche Fusionsarchitektur schlug das Team auch vor, das Framework durch die Integration von Modulen für bestimmte Modalitäten weiter zu optimieren. Das Team nennt dieses Konzept Modality-Aware Sparsity, kurz MaS; es ermöglicht dem Modell, die Eigenschaften jeder Modalität besser zu erfassen und gleichzeitig partielle Parameterfreigabe und Aufmerksamkeitsmechanismen zu nutzen. Frühere Forschungen wie VLMo, BEiT-3 und VL-MoE haben die Methode der gemischten Modalitätsexperten (MoME/Mixture-of-Modality-Experts) übernommen, um den visuellen Sprachcodierer und die maskierte Sprachkonstruktion zu trainieren. Das Forschungsteam von FAIR hat den nutzbaren Umfang von MoE noch einen Schritt weiter vorangetrieben. „Modellarchitektur“ Transformer Eine Reihe diskreter Token. Im Kern ist Chameleon ein Transformer-basiertes Modell, das einen Selbstaufmerksamkeitsmechanismus auf eine kombinierte Sequenz von Bild- und Text-Tokens anwendet. Dadurch kann das Modell komplexe Zusammenhänge innerhalb und zwischen Modalitäten erfassen. Das Modell wird mit dem Ziel der Vorhersage des nächsten Tokens trainiert, wobei Text- und Bild-Tokens auf autoregressive Weise generiert werden. In Chameleon verwendet das Bild-Tokenisierungsschema einen lernenden Bild-Tokenizer, der ein 512 × 512-Bild basierend auf einem Codebuch der Größe 8192 in 1024 diskrete Token kodiert. Für die Textsegmentierung wird ein BPE-Tokenizer mit einer Vokabulargröße von 65.536 verwendet, der Bildtoken enthält. Diese einheitliche Wortsegmentierungsmethode ermöglicht es dem Modell, jede Sequenz miteinander verflochtener Bild- und Text-Tokens nahtlos zu verarbeiten.
Mit dieser Methode erbt das neue Modell die Vorteile einer einheitlichen Darstellung, guter Flexibilität, hoher Skalierbarkeit und Unterstützung für End-to-End-Lernen. Auf dieser Grundlage (Abbildung 1a) führte das Team außerdem eine modalitätsbewusste Sparsity-Technologie ein, um die Effizienz und Leistung des frühen Fusionsmodells weiter zu verbessern. Breitenskalierung: Modalitätsbewusste Hybridexperten .
Diese Methode basiert auf der Erkenntnis, dass Token in verschiedenen Modi unterschiedliche Eigenschaften und Informationsdichten aufweisen.
Durch die Bildung unterschiedlicher Expertengruppen für jede Modalität kann das Modell spezialisierte Verarbeitungspfade entwickeln und gleichzeitig die Fähigkeit zur modalübergreifenden Informationsintegration beibehalten.
Abbildung 1b veranschaulicht die Schlüsselkomponenten dieser modalitätsbewussten Expertenmischung (MoMa). Vereinfacht ausgedrückt werden zunächst Experten für jede spezifische Modalität gruppiert, dann wird hierarchisches Routing implementiert (unterteilt in modalitätsbewusstes Routing und intramodales Routing) und schließlich werden Experten ausgewählt. Den detaillierten Ablauf entnehmen Sie bitte dem Originalpapier.
Im Allgemeinen lautet die formale Definition des MoMa-Moduls für ein Eingabetoken x:

Nach der MoMa-Berechnung verwendete das Team weiterhin die Restverbindung und die Swin-Transformer-Normalisierung. Frühere Forscher haben auch die Einführung von Sparsity in die Tiefendimension untersucht. Ihr Ansatz bestand darin, entweder bestimmte Ebenen zufällig zu verwerfen oder verfügbare Learning-Router zu verwenden . Konkret besteht der Ansatz des Teams, wie in der folgenden Abbildung dargestellt, darin, MoD vor dem Hybrid-Experten-Routing (MoE) in jede MoD-Schicht zu integrieren und so sicherzustellen, dass der gesamte Datenstapel von MoD verwendet werden kann. In der Inferenzphase können wir das Expertenauswahl-Routing von MoE oder das Layer-Auswahlrouting von MoD nicht direkt verwenden, da Top-K (Auswahl des Top-K) in einem Datenstapel durchgeführt wird ) Selektion zerstört die Kausalität. Um den Kausalzusammenhang der Argumentation sicherzustellen, führte das Forschungsteam, inspiriert durch das oben erwähnte MoD-Papier, einen Hilfsrouter (Auxiliary Router) ein, dessen Aufgabe darin besteht, vorherzusagen, dass das Token von einem bestimmten Gerät ausgewählt wird Experte oder Schicht basierend nur auf der verborgenen Darstellung der Token-Möglichkeit. Es gibt eine einzigartige Schwierigkeit für eine von Grund auf trainierte MoE-Architektur im Hinblick auf die Optimierung des Darstellungsraums und des Routing-Mechanismus. Das Team stellte fest, dass der MoE-Router für die Aufteilung des Repräsentationsraums für jeden Experten verantwortlich ist. In den frühen Phasen des Modelltrainings ist dieser Darstellungsraum jedoch nicht optimal, was dazu führt, dass die durch das Training erhaltene Routing-Funktion nicht optimal ist. Um diese Einschränkung zu überwinden, schlugen sie eine Upgrade-Methode vor, die auf dem Papier „Sparse upcycling: Training mix-of-experts from Dense Checkpoints“ von Komatsuzaki et al. basiert. 
Konkret trainieren Sie zunächst eine Architektur mit einem FFN-Experten pro Modalität. Nach einigen voreingestellten Schritten wird das Modell aktualisiert und transformiert. Die spezifische Methode besteht darin, die FFN jeder spezifischen Modalität in ein vom Experten ausgewähltes MoE-Modul umzuwandeln und jeden Experten für die erste Stufe der Expertenschulung zu initialisieren. Dadurch wird der Lernratenplaner zurückgesetzt, während der Datenladestatus der vorherigen Phase beibehalten wird, um sicherzustellen, dass die aktualisierten Daten in der zweiten Trainingsphase verwendet werden können. Um die Spezialisierung von Experten zu fördern, nutzte das Team auch Gumbel-Rauschen, um die MoE-Routing-Funktion zu verbessern, sodass der neue Router Experten auf differenzierbare Weise abfragen kann. Diese Upgrade-Methode in Verbindung mit der Gumbel-Sigmoid-Technologie kann die Einschränkungen des erlernten Routers überwinden und dadurch die Leistung der neu vorgeschlagenen modalitätsbewussten Sparse-Architektur verbessern. Um das verteilte Training von MoMa zu fördern, hat das Team Fully Sharded Data Parallel (FSDP/Fully Sharded Data Parallel) eingeführt. Im Vergleich zu herkömmlichem MoE weist diese Methode jedoch einige einzigartige Effizienzherausforderungen auf, darunter Probleme beim Lastausgleich und Effizienzprobleme bei der fachmännischen Ausführung. Für das Lastausgleichsproblem entwickelte das Team eine ausgewogene Datenmischmethode, die das Text-zu-Bild-Datenverhältnis auf jeder GPU im Einklang mit dem Expertenverhältnis hält. In Bezug auf die Effizienz der Expertenausführung hat das Team einige Strategien untersucht, die dazu beitragen können, die Ausführungseffizienz von Experten in verschiedenen Modalitäten zu verbessern:
- Beschränken Sie Experten in jeder Modalität auf homogene Experten und verbieten Sie sie Leiten Sie Text-Tokens an Bildexperten weiter und umgekehrt.
- Verwenden Sie Blocksparsity, um die Ausführungseffizienz zu verbessern.
- Wenn die Anzahl der Modalitäten begrenzt ist, führen Sie verschiedene Modalitäten in Sequenzexperten aus.
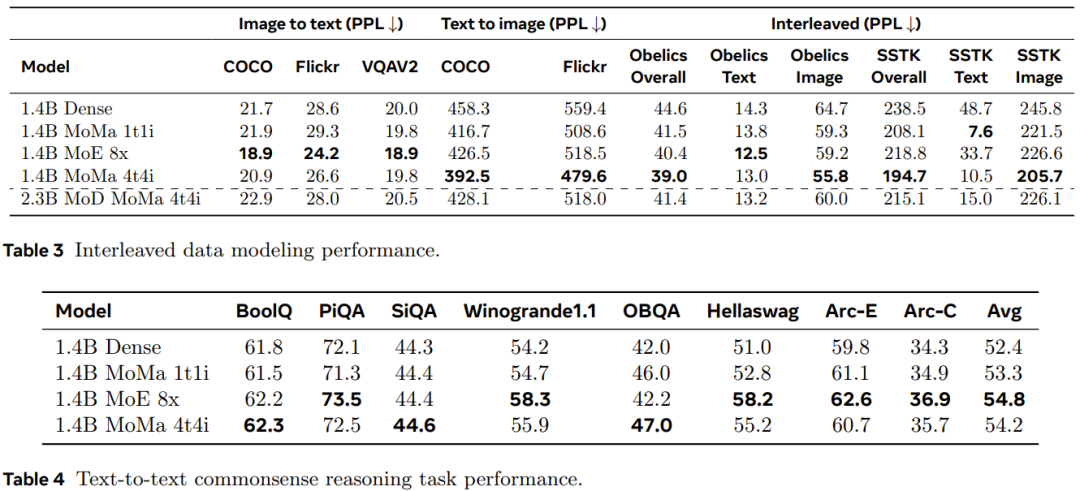
Da jede GPU im Experiment genügend Token verarbeitete, stellt die Hardwareauslastung kein großes Problem dar, selbst wenn mehrere Batch-Matrixmultiplikationen verwendet werden. Daher ist das Team davon überzeugt, dass die sequentielle Ausführungsmethode für den aktuellen Umfang der experimentellen Umgebung die bessere Wahl ist. Um den Durchsatz weiter zu verbessern, hat das Team auch einige andere Optimierungstechniken übernommen. Dazu gehören allgemeine Optimierungsvorgänge wie die Reduzierung des Gradientenkommunikationsvolumens und die automatisierte GPU-Kernfusion. Das Forschungsteam implementierte auch die Diagrammoptimierung durch Torch.compile. Darüber hinaus haben sie einige Optimierungstechniken für MoMa entwickelt, darunter die Wiederverwendung modaler Token-Indizes über verschiedene Ebenen hinweg, um Geräte zwischen CPU und GPU möglichst effizient zu synchronisieren. Der im Experiment verwendete Vortrainingsdatensatz und der Vorverarbeitungsprozess sind die gleichen wie bei Chameleon. Um die Skalierungsleistung zu bewerten, trainierten sie das Modell mit mehr als einer Billion Token. Tabelle 1 enthält die detaillierte Konfiguration dichter und spärlicher Modelle. Skalierungsleistung auf verschiedenen RechenebenenDas Team analysierte die Skalierungsleistung verschiedener Modelle auf verschiedenen Rechenebenen (FLOPs) entsprechen drei Größen dichter Modelle: 90M, 435M und 1,4B. Experimentelle Ergebnisse zeigen, dass ein spärliches Modell den Verlust eines dichten Modells vor dem Training mit äquivalenten FLOPs abgleichen kann, indem es nur 1/η der gesamten FLOPs verwendet (η stellt den Beschleunigungsfaktor vor dem Training dar). Die Einführung einer modalitätsspezifischen Expertengruppierung kann die Effizienz vor dem Training von Modellen unterschiedlicher Größe verbessern, was besonders für Bildmodalitäten von Vorteil ist. Wie in Abbildung 3 dargestellt, übertrifft die moe_1t1i-Konfiguration mit 1 Bildexperten und 1 Textexperten das entsprechende dichte Modell deutlich. Durch die Erweiterung der Anzahl der Experten in jeder Modalgruppe kann die Modellleistung weiter verbessert werden. Hybride Tiefe mit Experten Das Team beobachtete, dass die Konvergenzgeschwindigkeit des Trainingsverlusts verbessert wird, wenn MoE und MoD und ihre kombinierte Form verwendet werden. Wie in Abbildung 4 dargestellt, verbessert das Hinzufügen von MoD (mod_moe_1t1i) zur moe_1t1i-Architektur die Modellleistung über verschiedene Modellgrößen hinweg erheblich. Darüber hinaus kann mod_moe_1t1i in verschiedenen Modellgrößen und -modi moe_4t4i erreichen oder sogar übertreffen, was zeigt, dass die Einführung von Sparsity in der Tiefendimension auch die Trainingseffizienz effektiv verbessern kann. Andererseits können Sie auch erkennen, dass die Vorteile des Stapelns von MoD und MoE allmählich abnehmen. Ausweitung der ExpertenzahlUm die Auswirkungen der Ausweitung der Expertenzahl zu untersuchen, führte das Team weitere Ablationsexperimente durch. Sie untersuchten zwei Szenarien: die Zuweisung einer gleichen Anzahl von Experten zu jeder Modalität (ausgewogen) und die Zuweisung einer unterschiedlichen Anzahl von Experten zu jeder Modalität (unausgewogen). Die Ergebnisse sind in Abbildung 5 dargestellt. Für die ausgewogene Einstellung ist aus Abbildung 5a ersichtlich, dass mit zunehmender Anzahl an Experten der Schulungsverlust deutlich sinkt. Text- und Bildverluste weisen jedoch unterschiedliche Skalierungsmuster auf. Dies deutet darauf hin, dass die inhärenten Merkmale jeder Modalität zu unterschiedlichen Verhaltensweisen bei der spärlichen Modellierung führen. Für die unausgeglichene Einstellung vergleicht Abbildung 5b drei verschiedene Konfigurationen mit der entsprechenden Gesamtzahl von Experten (8). Es ist ersichtlich, dass das Modell im Allgemeinen bei dieser Modalität umso besser abschneidet, je mehr Experten es für eine Modalität gibt. Upgrade und TransformationDas Team hat natürlich die Wirkung des oben genannten Upgrades und der Transformation überprüft. Abbildung 6 vergleicht die Trainingskurven verschiedener Modellvarianten. Die Ergebnisse zeigen, dass ein Upgrade das Modelltraining tatsächlich weiter verbessern kann: Wenn die erste Stufe 10.000 Schritte hat, kann ein Upgrade den 1,2-fachen FLOP-Vorteil bringen, und wenn die Anzahl der Schritte 20.000 beträgt, sind es auch 1,16x FLOPs kehren zurück. Darüber hinaus ist zu beobachten, dass mit fortschreitendem Training der Leistungsunterschied zwischen dem aktualisierten Modell und dem von Grund auf neu trainierten Modell weiter zunimmt. Sparse-Modelle bringen oft keine unmittelbaren Leistungssteigerungen, da spärliche Modelle die Dynamik und damit verbundene Datenausgleichsprobleme erhöhen. Um den Einfluss der neu vorgeschlagenen Methode auf die Trainingseffizienz zu quantifizieren, verglich das Team den Trainingsdurchsatz verschiedener Architekturen in Experimenten mit üblicherweise kontrollierten Variablen. Die Ergebnisse sind in Tabelle 2 dargestellt. Es ist ersichtlich, dass die modalbasierte Sparse-Leistung im Vergleich zum dichten Modell einen besseren Kompromiss zwischen Qualität und Durchsatz erzielt und mit zunehmender Anzahl von Experten eine angemessene Skalierbarkeit aufweisen kann. Andererseits erzielen die MoD-Varianten zwar die besten absoluten Verluste, sind aber aufgrund zusätzlicher Dynamik und Ungleichgewichte tendenziell auch rechenintensiver. Das Team bewertete auch die Leistung des Modells anhand gespeicherter Sprachmodellierungsdaten und nachgelagerter Aufgaben. Die Ergebnisse sind in den Tabellen 3 und 4 dargestellt. Wie in Tabelle 3 gezeigt, übertrifft das 1,4B MoMa 1t1i-Modell durch die Verwendung mehrerer Bildexperten das entsprechende dichte Modell in den meisten Metriken, mit Ausnahme der bedingten Bild-zu-Text-Perplexitätsmetrik bei COCO und Flickr-Ausnahme. Eine weitere Skalierung der Anzahl der Experten verbessert auch die Leistung, wobei 1,4 Milliarden MoE 8x die beste Bild-zu-Text-Leistung erzielen. Darüber hinaus eignet sich das 1,4B MoE 8x-Modell, wie in Tabelle 4 gezeigt, auch sehr gut für Text-zu-Text-Aufgaben. 1,4B MoMa 4t4i schneidet bei allen bedingten Bild-Ratlosigkeitsmetriken am besten ab, während die Text-Ratlosigkeit bei den meisten Benchmarks ebenfalls sehr nahe bei 1,4B MoE 8x liegt. Insgesamt erzielt das 1.4B MoMa 4t4i-Modell die besten Modellierungsergebnisse bei gemischten Text- und Bildmodalitäten. Für weitere Einzelheiten lesen Sie bitte das Originalpapier. Das obige ist der detaillierte Inhalt vonHybridexperten sind durchsetzungsfähiger und können mehrere Modalitäten wahrnehmen und je nach Situation handeln. Meta schlägt modalitätsbewusste Expertenhybride vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn