Da die Iterationsgeschwindigkeit großer Modelle immer schneller wird, wird der Umfang der Trainingscluster immer größer und hochfrequente Software- und Hardwarefehler sind zu Schwachstellen geworden, die die weitere Verbesserung der Trainingseffizienz behindern ist für den Status während des Trainingsprozesses verantwortlich. Speicherung und Wiederherstellung sind zum Schlüssel zur Überwindung von Trainingsfehlern, zur Sicherstellung des Trainingsfortschritts und zur Verbesserung der Trainingseffizienz geworden.
Kürzlich haben das ByteDance Beanbao-Modellteam und die Universität Hongkong gemeinsam ByteCheckpoint vorgeschlagen. Dabei handelt es sich um ein natives PyTorch-Checkpointing-System für große Modelle, das mit mehreren Trainings-Frameworks kompatibel ist und das effiziente Lesen und Schreiben von Checkpoints sowie die automatische Neusegmentierung unterstützt. Im Vergleich zu bestehenden Methoden weist es erhebliche Leistungsverbesserungen und Benutzerfreundlichkeitsvorteile auf. In diesem Artikel werden die Herausforderungen vorgestellt, mit denen Checkpoint bei der Verbesserung der Trainingseffizienz großer Modelle konfrontiert ist, und die Lösungsideen, das Systemdesign, die I/O-Leistungsoptimierungstechnologie von ByteCheckpoint sowie experimentelle Ergebnisse bei Speicherleistungs- und Leseleistungstests zusammengefasst.
Meta-Beamte haben kürzlich die Ausfallrate des Llama3 405B-Trainings auf 16384 H100 80GB-Trainingsclustern bekannt gegeben – in nur 54 Tagen kam es zu 419 Unterbrechungen, mit einem durchschnittlichen Absturz alle drei Stunden, was die Aufmerksamkeit vieler Praktiker auf sich zog.
Wie ein gängiges Sprichwort in der Branche sagt, ist die einzige Gewissheit für groß angelegte Schulungssysteme ein Software- und Hardwarefehler. Mit zunehmendem Trainingsumfang und zunehmender Modellgröße sind die Überwindung von Software- und Hardwarefehlern und die Verbesserung der Trainingseffizienz zu wichtigen Einflussfaktoren für große Modelliterationen geworden.
Checkpoint ist zum Schlüssel zur Verbesserung der Trainingseffizienz geworden. Im Llama-Trainingsbericht erwähnte das technische Team, dass zur Bekämpfung der hohen Fehlerrate während des Trainingsprozesses häufige Kontrollpunkte durchgeführt werden müssen, um den Status des Modells, des Optimierers und des Datenlesers während des Trainings zu speichern und den Verlust von zu reduzieren Trainingsfortschritt.
Das große Modellteam von ByteDance Beanbao und die Universität von Hongkong haben kürzlich die Ergebnisse veröffentlicht – ByteCheckpoint, ein PyTorch-nativer, kompatibel mit mehreren Trainings-Frameworks und ein großes Modell-Checkpointing-System, das das effiziente Lesen und Schreiben von Checkpoint und die automatische Aktualisierung unterstützt. Segmentierung.
Im Vergleich zur Basismethode verbessert ByteCheckpoint die Leistung beim Checkpoint-Speichern um das bis zu 529,22-fache und beim Laden um das bis zu 3,51-fache. Die minimalistische Benutzeroberfläche und die automatische Neusegmentierungsfunktion von Checkpoint reduzieren die Benutzerakquise- und Nutzungskosten erheblich und verbessern die Benutzerfreundlichkeit des Systems.
Die Ergebnisse der Arbeit wurden nun veröffentlicht. 
- ByteCheckpoint: Ein einheitliches Checkpointing-System für die LLM-Entwicklung
- Papierlink: https://team.doubao.com/zh/publication/bytecheckpoint-a-unified-checkpointing-system-for-llm-development?view_from =Forschung
Technische Herausforderungen der Checkpoint-Technologie beim Training großer Modelle Aktuelle Checkpoint-Technologien stehen bei der Unterstützung der Effizienz des Trainings großer Modelle vor insgesamt vier Herausforderungen:
- Das vorhandene Systemdesign weist Mängel auf, die den zusätzlichen E/A-Aufwand des Trainings erheblich erhöhen
Beim Training großer Sprachmodelle (LLM) auf industrieller Ebene muss der Trainingsstatus die Checkpoint-Technologie bestehen ( Checkpointing) für Speicherung und Persistenz. Typischerweise besteht ein Checkpoint aus 5 Teilen (Modell, Optimierer, Datenleser, Zufallszahl und benutzerdefinierte Konfiguration). Dieser Prozess führt häufig zu einer Blockade auf Minutenebene im Training, was die Trainingseffizienz erheblich beeinträchtigt.
In umfangreichen Trainingsszenarien mit Remote-Persistent-Speichersystemen nutzt das vorhandene Checkpointing-System die GPU-zu-CPU-Speicherkopie (D2H-Kopie), die Serialisierung, die lokale Speicherung und das Hochladen in den Speicher während des Checkpoint-Speichervorgangs nicht vollständig aus . Ausführungsunabhängigkeit jeder Stufe des Systems.
Darüber hinaus wurde das parallele Verarbeitungspotenzial verschiedener Schulungsprozesse, die sich Checkpoint-Zugriffsaufgaben teilen, noch nicht vollständig erforscht. Diese Systemdesignmängel erhöhen den zusätzlichen I/O-Overhead, der durch das Checkpoint-Training verursacht wird.
- Checkpoint ist schwer neu zu segmentieren und der Entwicklungs- und Wartungsaufwand für manuelle Segmentierungsskripte ist zu hoch
In verschiedenen Trainingsphasen von LLM (Vorschulung zu SFT oder RLHF) und verschiedene Aufgaben (von Bei der Migration von Checkpoints zwischen Trainingsaufgaben (Pulling von Checkpoints aus verschiedenen Phasen zur automatischen Auswertung) ist es normalerweise erforderlich, die im persistenten Speichersystem gespeicherten Checkpoints neu zu segmentieren (Checkpoint Resharding), um sie an die neue Parallelität anzupassen Konfiguration der Downstream-Aufgaben und Kontingente für verfügbare GPU-Ressourcen.
Bestehende Checkpointing-Systeme [1, 2, 3, 4] gehen alle davon aus, dass die Parallelitätskonfiguration und die GPU-Ressourcen während der Speicherung und des Ladens unverändert bleiben, und können die Notwendigkeit einer Checkpoint-Neusegmentierung nicht bewältigen. Eine derzeit in der Branche gängige Lösung besteht darin, Skripte zum Zusammenführen oder erneuten Aufteilen von Checkpoints für verschiedene Modelle anzupassen. Diese Methode bringt einen hohen Entwicklungs- und Wartungsaufwand mit sich und weist eine schlechte Skalierbarkeit auf. Die Checkpoint-Module verschiedener Schulungsrahmen sind fragmentiert, was die einheitliche Verwaltung und Leistungsoptimierung von Checkpoint vor Herausforderungen stellt Arbeiten Sie basierend auf den Aufgabenmerkmalen zusammen, wählen Sie das geeignete Framework (Megatron-LM [5], FSDP [6], DeepSpeed [7], veScale [8, 9]) für das Training aus und speichern Sie den Checkpoint im Speichersystem. Diese unterschiedlichen Trainingsrahmen verfügen jedoch über ihre eigenen unabhängigen Checkpoint-Formate sowie Lese- und Schreibmodule. Die Checkpoint-Moduldesigns verschiedener Trainings-Frameworks sind unterschiedlich, was Herausforderungen für die einheitliche Checkpoint-Verwaltung und Leistungsoptimierung des zugrunde liegenden Systems mit sich bringt.
- Benutzer verteilter Trainingssysteme stehen vor mehreren Problemen
Aus der Sicht der Benutzer von Trainingssystemen (KI-Forscher oder Ingenieure) ist die Checkpoint-Richtung, wenn Benutzer verteilte Trainingssysteme verwenden wird oft von drei Problemen geplagt:
1) Wie man Checkpoints effizient speichert und Checkpoints speichert, ohne die Trainingseffizienz zu beeinträchtigen.
- 2) So segmentieren Sie den Checkpoint neu und lesen ihn entsprechend der neuen Parallelität für den Checkpoint, die unter einem Parallelitätsgrad gespeichert ist. 3) So laden Sie die trainierten Produkte in ein Cloud-Speichersystem (HDFS, S3 usw.) hoch und verwalten mehrere Speichersysteme manuell, was für Benutzer kostspielig zu erlernen und zu verwenden ist.
Als Reaktion auf die oben genannten Probleme haben das ByteDance Beanbao-Modellteam und das Labor von Professor Wu Chuan von der Universität Hongkong gemeinsam ByteCheckpoint ins Leben gerufen. ByteCheckpoint ist ein leistungsstarkes verteiltes Checkpointing-System, das mit mehreren Trainings-Frameworks vereinheitlicht ist, mehrere Speicher-Backends unterstützt und über die Möglichkeit verfügt, Checkpoints automatisch neu zu segmentieren. ByteCheckpoint bietet eine einfache und benutzerfreundliche Benutzeroberfläche, implementiert eine große Anzahl von Technologien zur Optimierung der E/A-Leistung, um die Leistung von Speicher- und Leseprüfpunkten zu verbessern, und unterstützt die flexible Migration von Prüfpunkten in Aufgaben mit unterschiedlichen Parallelitätskonfigurationen.
Systemdesign
Speicherarchitektur
ByteCheckpoint verwendet eine durch Metadaten/Tensordaten getrennte Speicherarchitektur, um die Entkopplung von Checkpoint-Management- und Trainingsframework und Parallelität zu realisieren.다양한 교육 프레임워크 및 최적화 프로그램에 있는 모델의 Tensor 슬라이스(Tensor Shard)는 저장소 파일에 저장되고, 메타 정보(TensorMeta, ShardMeta, ByteMeta)는 전역적으로 고유한 메타데이터 파일에 저장됩니다. 
체크포인트를 읽기 위해 다양한 병렬성 구성을 사용하는 경우 아래 그림과 같이 각 교육 프로세스에서는 프로세스에 필요한 텐서의 저장 위치를 얻기 위해 현재 병렬성에 따라 쿼리 메타 정보만 설정하면 됩니다. 그런 다음 위치에 따라 직접 읽어 자동 체크포인트 재분할을 실현합니다. 
다양한 훈련 프레임워크가 실행될 때 종종 모델이나 옵티마이저의 텐서 모양을 1차원으로 평면화하여 집합 통신 성능을 향상시킵니다. 이 평탄화 작업은 불규칙한 텐서 샤딩(불규칙한 텐서 샤딩) 문제를 체크포인트 스토리지에 가져옵니다. 아래 그림과 같이 Megatron-LM(NVIDIA에서 개발한 분산형 대형 모델 훈련 프레임워크)과 veScale(ByteDance에서 개발한 PyTorch 네이티브 분산형 대형 모델 훈련 프레임워크)에서 모델 매개변수는 옵티마이저 상태에 해당합니다. 하나의 차원으로 평면화하고 병합한 다음 데이터 병렬성에 따라 분할합니다. 이로 인해 텐서는 서로 다른 프로세스로 불규칙하게 분할되고, 텐서 슬라이스의 메타 정보는 오프셋 및 길이 튜플을 사용하여 표현할 수 없으므로 저장 및 읽기가 어려워집니다. 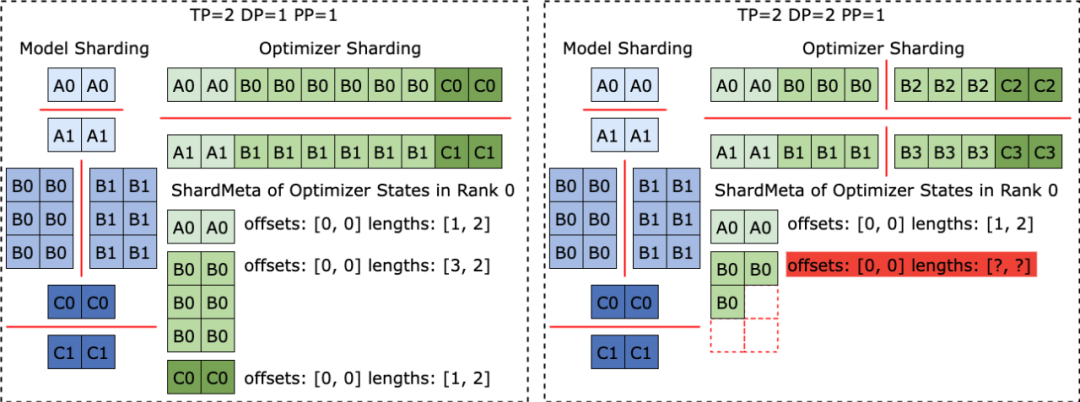
불규칙한 텐서 분할 문제는 FSDP 프레임워크에도 존재합니다. 불규칙하게 절단된 텐서 슬라이스를 제거하기 위해 FSDP 프레임워크는 체크포인트를 저장하기 전에 모든 프로세스의 1차원 텐서 슬라이스에 대해 전체 수집 세트 통신 및 D2H 복사 작업을 수행하여 완전한 불규칙 분할 텐서를 얻습니다. 이 솔루션은 대규모 통신과 빈번한 GPU-CPU 동기화 오버헤드를 가져오며 이는 Checkpoint 스토리지 성능에 심각한 영향을 미칩니다. 이 문제를 해결하기 위해 ByteCheckpoint는 Asynchronous Tensor Merging 기술을 제안했습니다. ByteCheckpoint는 먼저 여러 프로세스에서 불규칙하게 분할된 텐서를 찾은 다음 비동기 P2P 통신을 사용하여 이러한 불규칙한 텐서를 여러 프로세스에 배포하여 병합합니다. 이러한 불규칙한 텐서에 대한 모든 P2P 통신 대기(Wait) 및 텐서 D2H 복사 작업은 직렬화 단계에 진입할 때까지 연기되므로 빈번한 동기화 오버헤드가 제거되고 다른 체크포인트 스토리지 프로세스와의 통신이 중복됩니다. 다음 그림은 ByteCheckpoint의 시스템 아키텍처를 보여줍니다. API 계층은 다양한 교육 프레임워크에 대해 간단하고 사용하기 쉬운 통합 읽기 및 쓰기를 제공합니다( 저장) 및 읽기(로드) 인터페이스입니다. Planner 계층은 액세스 개체를 기반으로 다양한 교육 프로세스에 대한 액세스 계획을 생성하고 이를 실행 계층에 넘겨 실제 I/O 작업을 수행합니다. 실행 계층은 고성능 체크포인트 액세스를 위해 다양한 I/O 최적화 기술을 사용하여 I/O 작업을 수행하고 스토리지 계층과 상호 작용합니다. 스토리지 계층은 다양한 스토리지 백엔드를 관리하고 I/O 작업 중에 다양한 스토리지 백엔드에 따라 해당 최적화를 수행합니다. 계층형 디자인은 시스템의 확장성을 향상시켜 향후 더 많은 교육 프레임워크와 스토리지 백엔드를 지원할 수 있습니다. 
ByteCheckpoint의 API 사용 사례는 다음과 같습니다. 
ByteCheckpoint bietet eine minimalistische API, wodurch die Einstiegskosten für den Benutzer gesenkt werden. Beim Speichern und Lesen von Checkpoints müssen Benutzer lediglich die Speicher- und Ladefunktionen aufrufen und dabei den zu speichernden und zu lesenden Inhalt, den Dateisystempfad und verschiedene Optionen zur Leistungsoptimierung übergeben. I/O-Leistungsoptimierungstechnologie Entwarf eine vollständig asynchrone Speicherpipeline ( Save Pipeline) teilt die verschiedenen Phasen der Checkpoint-Speicherung (P2P-Tensor-Übertragung, D2H-Replikation, Serialisierung, Speichern lokaler und Hochladen von Dateisystemen) auf, um eine effiziente Pipeline-Ausführung zu erreichen. Vermeiden Sie wiederholte Speicherzuweisungen
Im D2H-Kopiervorgang verwendet ByteCheckpoint einen angehefteten Speicherpool (Pinned Memory Pool), der den Zeitaufwand für wiederholte Speicherzuweisungen reduziert. Um den zusätzlichen Zeitaufwand zu reduzieren, der durch das synchrone Warten auf das Recycling des festen Speicherpools in Hochfrequenzspeicherszenarien entsteht, fügt ByteCheckpoint außerdem einen Ping-Pong-Puffermechanismus hinzu, der auf dem festen Speicherpool basiert. Zwei unabhängige Speicherpools übernehmen abwechselnd die Rolle von Lese- und Schreibpuffern und interagieren mit der GPU und den I/O-Workern, die nachfolgende I/O-Vorgänge ausführen, wodurch die Speichereffizienz weiter verbessert wird.
Lastausgleich
Beim datenparallelen (Data-Parallel oder DP) Training wird das Modell redundant zwischen verschiedenen datenparallelen Prozessgruppen (DP-Gruppe) verwendet, um die Redundanz gleichmäßig zu verteilen Modellieren Sie Tensoren für verschiedene Prozessgruppen für die Speicherung und verbessern Sie so effektiv die Speichereffizienz von Checkpoint. „Checkpoint-Leseoptimierung“: Original Lies einen Teil davon aus einem Tensor-Slice.

ByteCheckpoint nutzt die On-Demand-Technologie zum teilweisen Lesen von Dateien (Partial File Reading), um die erforderlichen Dateifragmente direkt aus dem Remote-Speicher zu lesen und so das Herunterladen und Lesen unnötiger Daten zu vermeiden.
Beim datenparallelen (Data-Parallel oder DP) Training ist das Modell zwischen verschiedenen datenparallelen Prozessgruppen (DP-Gruppe) redundant und verschiedene Prozessgruppen lesen wiederholt denselben Tensor-Slice. In groß angelegten Trainingsszenarien senden verschiedene Prozessgruppen gleichzeitig eine große Anzahl von Anforderungen an entfernte persistente Speichersysteme (z. B. HDFS), was einen enormen Druck auf das Speichersystem ausübt.
Um das wiederholte Lesen von Daten zu vermeiden, die vom Trainingsprozess an HDFS gesendeten Anforderungen zu reduzieren und die Ladeleistung zu optimieren, verteilt ByteCheckpoint dieselben Tensor-Slice-Leseaufgaben gleichmäßig auf verschiedene Prozesse und liest die Remote-Dateien beim Abrufen , wird die Leerlaufbandbreite zwischen GPUs für die Tensor-Slice-Übertragung verwendet. „Experimentelle Ergebnisse“ und anders Trainings-Frameworks Die Checkpoint-Zugriffskorrektheit, Speicherleistung und Leseleistung von ByteCheckpoint wurden in Trainingsaufgaben unterschiedlicher Größe bewertet. Weitere Einzelheiten zur experimentellen Konfiguration und zum Korrektheitstest finden Sie im vollständigen Dokument.

Im Speicherleistungstest verglich das Team verschiedene Modellgrößen und Trainingsframeworks, alle 50 bzw. 100 Schritte wurden Checkpoint-, Bytecheckpoint- und Baseline-Methoden gespeichert Trainingsbedingte Blockierzeiten (Checkpoint-Stände). Dank der tiefgreifenden Optimierung der Schreibleistung hat ByteCheckpoint in verschiedenen experimentellen Szenarien eine hohe Leistung erzielt. In der 576-Karten-Trainingsaufgabe SparseGPT 110B – Megatron-LM wurde eine um 10 % höhere Leistung als bei der Basislinie erzielt Die Leistungsverbesserung beträgt das 66,65- bis 74,55-fache und kann bei der 256-Karten-DenseGPT-10B-FSDP-Trainingsaufgabe sogar eine Leistungsverbesserung um das 529,22-fache erreichen. 
Im Leseleistungstest verglich das Team die Ladezeit verschiedener Methoden zum Lesen von Prüfpunkten basierend auf der Parallelität nachgelagerter Aufgaben. ByteCheckpoint erreicht eine Leistungsverbesserung um das 1,55- bis 3,37-fache im Vergleich zur Baseline-Methode. Das Team stellte fest, dass die Leistungsverbesserung von ByteCheckpoint im Vergleich zur Megatron-LM-Basismethode signifikanter ist. Dies liegt daran, dass Megatron-LM ein Offline-Skript ausführen muss, um den verteilten Prüfpunkt erneut zu teilen, bevor der Prüfpunkt in die neue Parallelitätskonfiguration eingelesen wird. Im Gegensatz dazu kann ByteCheckpoint direkt eine automatische Checkpoint-Neusegmentierung durchführen, ohne Offline-Skripte ausführen zu müssen, und das Lesen effizient abschließen. 
Abschließend möchte das Team in Bezug auf die zukünftige Planung von ByteCheckpoint von zwei Aspekten ausgehen: Erstens das langfristige Ziel erreichen, effizientes Checkpointing für extrem große GPU-Cluster-Trainingsaufgaben zu unterstützen. Zweitens: Realisieren Sie das Checkpoint-Management für den gesamten Lebenszyklus des Trainings großer Modelle und unterstützen Sie Checkpoints in allen Szenarien, vom Pre-Training (Pre-Training) über die überwachte Feinabstimmung (SFT) bis zum Reinforcement Learning (RLHF). ) und Bewertung (Bewertung) und andere Szenarien. Das ByteDance Beanbao Big Model Team wurde 2023 gegründet. Es hat sich zum Ziel gesetzt, die fortschrittlichste KI-Big-Model-Technologie der Branche zu entwickeln und ein erstklassiges Forschungsteam für die zu werden Leisten Sie einen Beitrag zur Entwicklung von Technik und Gesellschaft. Aktuell ist das Team weiterhin darum bemüht, herausragende Talente für sich zu gewinnen. Hartnäckig, offen und voller Innovationsgeist sind die Schlüsselwörter der Teamatmosphäre, die darauf abzielt, ein positives Arbeitsumfeld zu schaffen und die Teammitglieder zu fördern weiterhin zu lernen und zu wachsen, keine Angst vor Herausforderungen zu haben und nach Exzellenz zu streben. Ich hoffe, mit technischen Talenten mit Innovationsgeist und Verantwortungsbewusstsein zusammenzuarbeiten, um die Effizienzsteigerung des Trainings für große Modelle voranzutreiben und mehr Fortschritte und Ergebnisse zu erzielen. [1] Mohan, Jayashree, Amar Phanishayee und Vijay Chidambaram Datei- und Speichertechnologien (FAST 21). [2] Eisenman, Assaf, et al zum Design und zur Implementierung vernetzter Systeme (NSDI 22). [3] zu Betriebssystemprinzipien. [4] Gupta, Tanmaey, et al Systems. 2024.[5] Shoeybi, Mohammad, et al. „Megatron-lm: Training von Multimilliarden-Parameter-Sprachmodellen mit Modellparallelität.“ [6] Zhao, Yanli, et al. „Pytorch fsdp: Erfahrungen zur Skalierung vollständig geshardter Daten arXiv:2304.11277 (2023).[7] Rasley, Jeff, et al. „Deepspeed: Systemoptimierungen ermöglichen das Training von Deep-Learning-Modellen mit über 100 Milliarden Parametern.“ Tagungsband der 26. ACM SIGKDD International Conference on Knowledge Discovery & Data Mining 2020.[8] Jiang, Ziheng, et al. „{MegaScale}: Skalierung des Trainings großer Sprachmodelle auf mehr als 10.000 {GPUs}.“ 21. USENIX-Symposium zum Design und zur Implementierung vernetzter Systeme (NSDI 24). Trainingsrahmen https://github.com/volcengine/veScale[10] Brown, Tom, et al. „Fortschritte in neuronalen Informationsverarbeitungssystemen“ 33 (2020) : 1877-1901.Das obige ist der detaillierte Inhalt vonDas Llama3-Training stürzt alle 3 Stunden ab? Big Bean Bag-Modell und HKU-Team verbessern das knusprige Wanka-Training. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

