
Heim >Technologie-Peripheriegeräte >KI >ACM MM2024 | Die multimodale Forschung von NetEase Fuxi erlangte erneut internationale Anerkennung und förderte neue Durchbrüche im modalübergreifenden Verständnis in bestimmten Bereichen
ACM MM2024 | Die multimodale Forschung von NetEase Fuxi erlangte erneut internationale Anerkennung und förderte neue Durchbrüche im modalübergreifenden Verständnis in bestimmten Bereichen

- 王林Original
- 2024-08-07 20:16:121207Durchsuche

- Die Forschungsrichtung dieses Artikels umfasst visuelles Sprachvortraining (VLP), modalübergreifendes Bild- und Textabrufen (CMITR) und andere Bereiche. Diese Auswahl markiert die erneute internationale Anerkennung der multimodalen Fähigkeiten von NetEase Fuxi Lab. Derzeit wurde die entsprechende Technologie auf den selbst entwickelten multimodalen intelligenten Assistenten „Dan Qing Yue“ angewendet.
- ACM MM wurde von der Association for Computing Machinery (ACM) initiiert und ist die einflussreichste internationale Spitzenkonferenz im Bereich Multimedia-Verarbeitung, -Analyse und -Computing. Außerdem wird sie als erstklassige internationale akademische Konferenz im Bereich Multimedia empfohlen von der China Computer Federation. Als führende Konferenz auf diesem Gebiet hat die ACM MM große Aufmerksamkeit von namhaften Herstellern und Wissenschaftlern im In- und Ausland erhalten. Beim diesjährigen ACM MM gingen insgesamt 4385 gültige Manuskripte ein, von denen 1149 von der Konferenz angenommen wurden, mit einer Annahmequote von 26,20 %.
Als führende Forschungseinrichtung für künstliche Intelligenz in China verfügt NetEase Fuxi über fast sechs Jahre Erfahrung in der groß angelegten Modellforschung, verfügt über umfassende Algorithmen- und Ingenieurserfahrung und hat Dutzende Text- und multimodale Pre-Training-Modelle erstellt Dazu gehören große Modelle für das Textverständnis und die Generierung, große Modelle für das Bild- und Textverständnis, große Modelle für die Bild- und Textgenerierung usw. Diese Erfolge fördern nicht nur effektiv die Anwendung großer Modelle im Spielbereich, sondern legen auch eine solide Grundlage für die Entwicklung modalübergreifender Verständnisfähigkeiten. Cross-modale Verständnisfunktionen tragen dazu bei, das Wissen mehrerer Domänen besser zu integrieren und umfangreiche Datenmodalitäten und Informationen aufeinander abzustimmen.
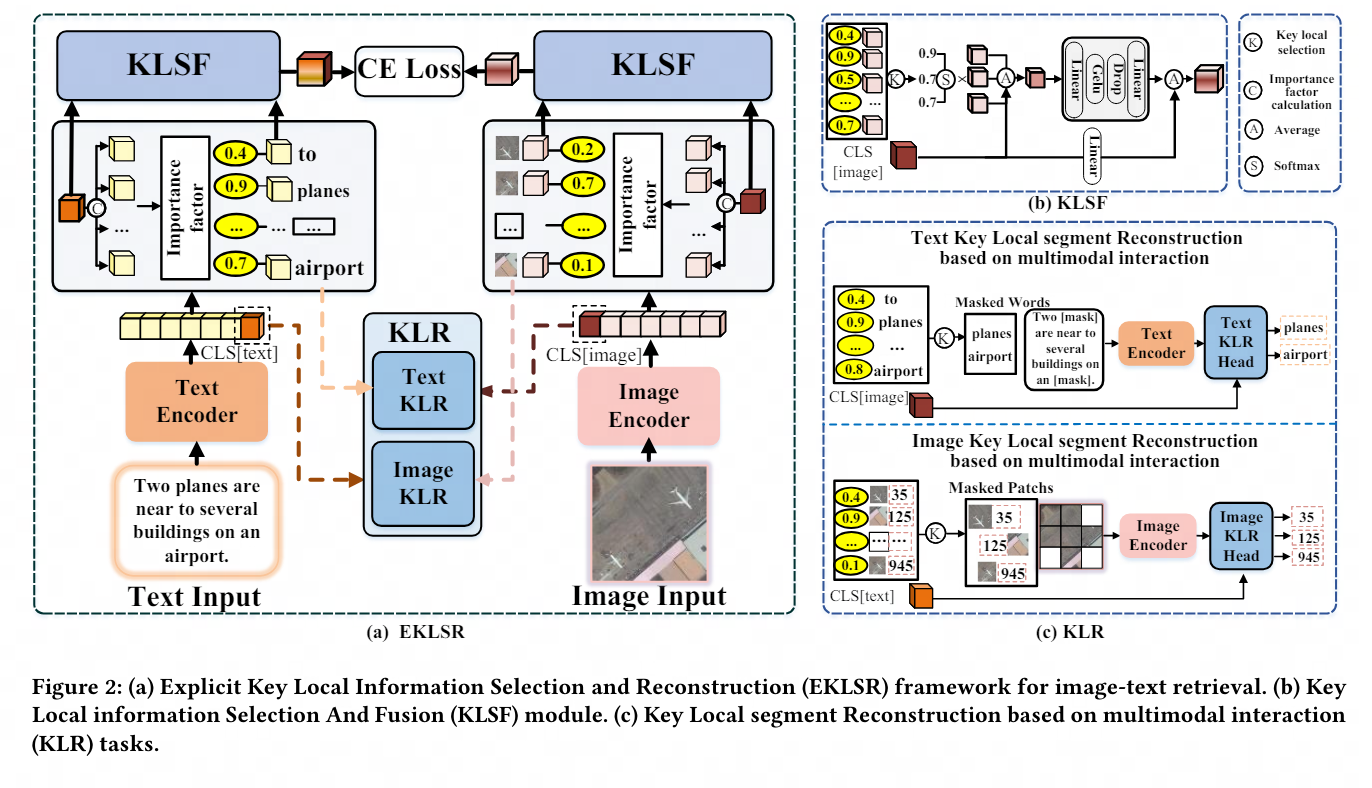
Auf dieser Grundlage hat NetEase Fuxi basierend auf dem großen Modell des Bild- und Textverständnisses weitere Innovationen entwickelt und eine modalübergreifende Abrufmethode vorgeschlagen, die auf der Auswahl und Rekonstruktion wichtiger lokaler Informationen basiert, um das Problem des Bildtextes in bestimmten Feldern zu lösen Für multimodale Agenten bilden Interaktionsfragen die technische Grundlage.
Das Folgende ist eine Zusammenfassung der ausgewählten Beiträge:
„Selection and Reconstruction of Key Locals: A Novel Specific Domain Image-Text Retrieval Method“
Selection and Reconstruction of Key Local Information: A Novel Specific Domain Image and Text Retrieval Methode
Schlüsselwörter: wichtige lokale Informationen, feinkörnig, interpretierbar
Beteiligte Bereiche: Visual Language Pre-Training (VLP), Cross-Modal Image and Text Retrieval (CMITR)
In den letzten Jahren wurde mit der Visual Language Pre- Training (Vision – Mit dem Aufkommen von Language Pretraining (VLP)-Modellen wurden erhebliche Fortschritte im Bereich des Cross-Modal Image-Text Retrieval (CMITR) erzielt. Obwohl VLP-Modelle wie CLIP bei domänenallgemeinen CMITR-Aufgaben eine gute Leistung erbringen, ist ihre Leistung beim Specific Domain Image-Text Retrieval (SDITR) oft unzureichend. Dies liegt daran, dass eine bestimmte Domäne häufig einzigartige Datenmerkmale aufweist, die sie von der allgemeinen Domäne unterscheiden.
In einem bestimmten Bereich können Bilder ein hohes Maß an visueller Ähnlichkeit zwischen ihnen aufweisen, während sich semantische Unterschiede tendenziell auf wichtige lokale Details konzentrieren, wie z. B. bestimmte Objektbereiche im Bild oder bedeutungsvolle Wörter im Text. Selbst kleine Änderungen in diesen lokalen Segmenten können erhebliche Auswirkungen auf den gesamten Inhalt haben und die Bedeutung dieser wichtigen lokalen Informationen unterstreichen. Daher erfordert SDITR, dass sich das Modell auf wichtige lokale Informationsfragmente konzentriert, um den Ausdruck von Bild- und Textmerkmalen in einem gemeinsamen Darstellungsraum zu verbessern und dadurch die Ausrichtungsgenauigkeit zwischen Bildern und Text zu verbessern.
Dieses Thema untersucht die Anwendung von Pre-Training-Modellen für visuelle Sprache bei Bild-Text-Abrufaufgaben in bestimmten Bereichen und untersucht das Problem der lokalen Merkmalsnutzung bei Bild-Text-Abrufaufgaben in bestimmten Bereichen. Der Hauptbeitrag besteht darin, eine Methode zur Nutzung diskriminierender, feinkörniger lokaler Informationen vorzuschlagen, um die Ausrichtung von Bildern und Text in einem gemeinsamen Darstellungsraum zu optimieren.
Zu diesem Zweck entwerfen wir einen expliziten Rahmen für die Auswahl und Rekonstruktion wichtiger lokaler Informationen sowie eine Strategie für die Rekonstruktion wichtiger lokaler Segmente, die auf multimodaler Interaktion basiert. Diese Methoden nutzen diskriminierende, feinkörnige lokale Informationen effektiv und verbessern dadurch das Bild erheblich und sind umfassend und ausreichend Experimente zur Qualität der Textausrichtung im gemeinsamen Raum zeigen den Fortschritt und die Wirksamkeit der vorgeschlagenen Strategie.
Besonderer Dank geht an das IPIU-Labor der Xi'an University of Electronic Science and Technology für seine starke Unterstützung und seinen wichtigen Forschungsbeitrag zu diesem Papier.
Pada masa ini, keupayaan pemahaman pelbagai mod NetEase Fuxi telah digunakan secara meluas dalam pelbagai jabatan perniagaan Kumpulan NetEase, termasuk NetEase Leihuo, NetEase Cloud Music, NetEase Yuanqi, dll. Aplikasi ini meliputi pelbagai senario seperti permainan cubitan muka berasaskan teks inovatif dalam permainan, carian sumber silang modal, pengesyoran kandungan yang diperibadikan, dsb., yang menunjukkan nilai perniagaan yang besar.
Pada masa hadapan, dengan peningkatan penyelidikan dan kemajuan teknologi, pencapaian ini dijangka menggalakkan aplikasi meluas teknologi kecerdasan buatan dalam pendidikan, penjagaan perubatan, e-dagang dan industri lain, memberikan pengguna pengalaman perkhidmatan yang lebih peribadi dan pintar . NetEase Fuxi juga akan terus memperdalam pertukaran dan kerjasama dengan institusi akademik terkemuka di dalam dan luar negara, menjalankan penerokaan mendalam dalam bidang penyelidikan yang lebih canggih, bersama-sama mempromosikan pembangunan teknologi kecerdasan buatan, dan menyumbang kepada pembinaan yang lebih cekap dan bijak. masyarakat.
Imbas kod QR di bawah untuk mengalami "Temujanji Gambar" dengan segera dan nikmati pengalaman interaktif berbilang modal dengan gambar dan teks yang "memahami anda dengan lebih baik"!

Das obige ist der detaillierte Inhalt vonACM MM2024 | Die multimodale Forschung von NetEase Fuxi erlangte erneut internationale Anerkennung und förderte neue Durchbrüche im modalübergreifenden Verständnis in bestimmten Bereichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr