Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail zur Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Der erste Autor dieses Artikels ist Cai Wenxiao, ein Doktorand an der Stanford University die Punktzahl der ersten Klasse. Zu seinen Forschungsinteressen zählen multimodale Großmodelle und verkörperte Intelligenz. Diese Arbeit wurde während seines Besuchs an der Shanghai Jiao Tong University und seines Praktikums am Beijing Zhiyuan Artificial Intelligence Research Institute abgeschlossen. Sein Betreuer war Professor Zhao Bo, der korrespondierende Autor dieses Artikels. Zuvor schlug Lehrer Li Feifei das Konzept der räumlichen Intelligenz vor. Als Reaktion darauf schlugen Forscher der Shanghai Jiao Tong University, der Stanford University, der Zhiyuan University, der Peking University, der Oxford University und der Dongda University das große räumliche Modell SpatialBot vor. Außerdem wurden die Trainingsdaten SpatialQA und die Testliste SpatialBench vorgeschlagen, um multimodalen großen Modellen das Verständnis von Tiefe und Raum in allgemeinen Szenarien und verkörperten Szenarien zu ermöglichen. 
- Papiertitel: SpatialBot: Precise Depth Understanding with Vision Language Models
- Papierlink: https://arxiv.org/abs/2406.13642
- Projekthomepage: https://github. com/BAAI-DCAI/SpatialBot
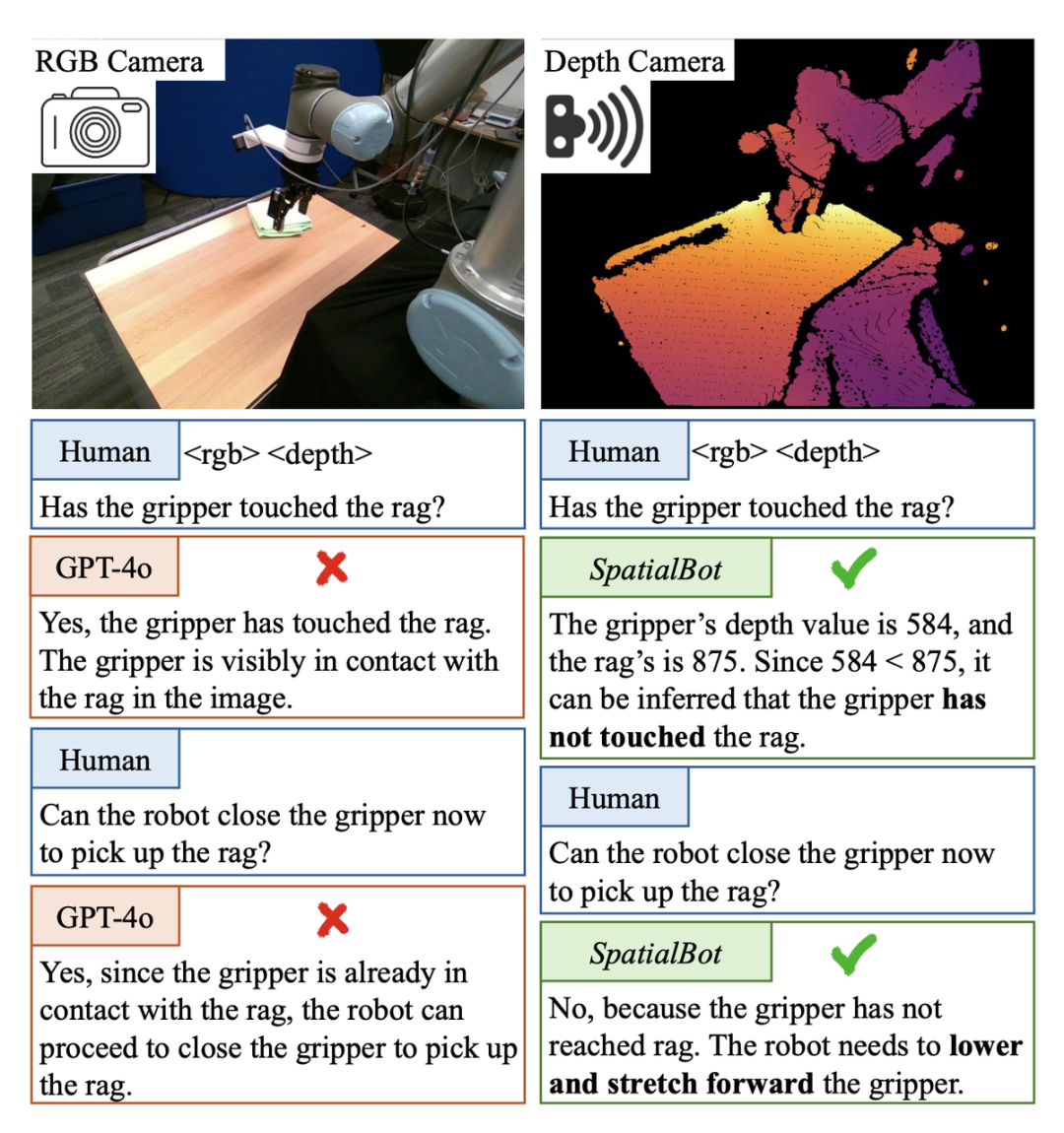
Bei der Pick-and-Place-Aufgabe der verkörperten Intelligenz muss festgestellt werden, ob die mechanische Klaue das Zielobjekt berührt hat. Wenn Sie darauf stoßen, können Sie Ihre Krallen schließen und es ergreifen. In dieser Berkerly UR5-Demonstrationsdatensatzszene können jedoch nicht einmal GPT-4o oder Menschen anhand eines einzelnen RGB-Bildes feststellen, ob die mechanische Klaue das Zielobjekt berührt hat. Mithilfe von Tiefeninformationen kann beispielsweise die Tiefenkarte direkt ermittelt werden Wenn ja, kann es nicht beurteilt werden, da es die Tiefenkarte nicht verstehen kann. SpatialBot kann durch sein Verständnis der RGB-Tiefe den Tiefenwert der mechanischen Klaue und des Zielobjekts genau ermitteln und so ein Verständnis für räumliche Konzepte generieren.
SpatialBot Demo der verkörperten Szene: 1. Schnappen Sie sich aus der menschlichen (Kamera-)Perspektive die Teetasse rechts 2. Schnappen Sie sich die mittlere Teetasse Wie kann man große Modelle als notwendigen Weg zur verkörperten Intelligenz dazu bringen, den Raum zu verstehen? Punktwolken sind relativ teuer und Fernglaskameras erfordern während des Gebrauchs eine häufige Kalibrierung. Im Gegensatz dazu sind Tiefenkameras erschwinglich und weit verbreitet. In allgemeinen Szenarien können groß angelegte unbeaufsichtigte Trainingstiefenschätzungsmodelle auch ohne solche Hardwareausrüstung bereits relativ genaue Tiefeninformationen liefern. Daher schlagen die Autoren vor, RGBD als Eingabe für räumlich große Modelle zu verwenden. Welche Probleme gibt es bei der aktuellen technischen Route?
- Bestehende Modelle können die Tiefenkarteneingabe nicht direkt verstehen. Beispielsweise wird der Bildencoder CLIP/SigLIP auf RGB-Bilder trainiert, ohne jemals Tiefenkarten zu sehen.
- Die meisten der vorhandenen großen Modelldatensätze können nur mit RGB analysiert und beantwortet werden. Wenn daher die vorhandenen Daten einfach in RGBD-Eingaben geändert werden, indiziert das Modell das Wissen nicht aktiv in der Tiefenkarte. Es sind speziell entwickelte Aufgaben und Qualitätssicherung erforderlich, um das Modell dabei zu unterstützen, die Tiefenkarte zu verstehen und Tiefeninformationen zu verwenden.
S Drei Ebenen von SpatialQA führen das Modell schrittweise zum Verständnis der Tiefenkarte und zur Verwendung von Tiefeninformationen.
Der Autor schlägt einen SpatialQA-Datensatz mit drei Ebenen vor.
Leiten Sie das Modell auf der unteren Ebene, um die Tiefenkarte zu verstehen, und leiten Sie die Informationen direkt aus der Tiefenkarte.
Lassen Sie das Modell auf der mittleren Ebene die Tiefe an RGB ausrichten
Entwerfen Sie mehrere Tiefen auf hoher Ebene. Für verwandte Aufgaben werden 50.000 Daten mit Anmerkungen versehen, sodass das Modell Tiefeninformationen verwenden kann, um die Aufgabe basierend auf dem Verständnis der Tiefenkarte abzuschließen. Zu den Aufgaben gehören: räumliche Positionsbeziehung, Objektgröße, ob Objekte in Kontakt sind, Verständnis der Roboterszene usw.
- Beispieldialog bei Was enthält Spatialbot?
-
1. Basierend auf den Ideen im Agenten kann SpatialBot bei Bedarf genaue Tiefeninformationen über die API erhalten. Bei Aufgaben wie der Erfassung von Tiefeninformationen und dem Entfernungsvergleich kann eine Genauigkeit von über 99 % erreicht werden.
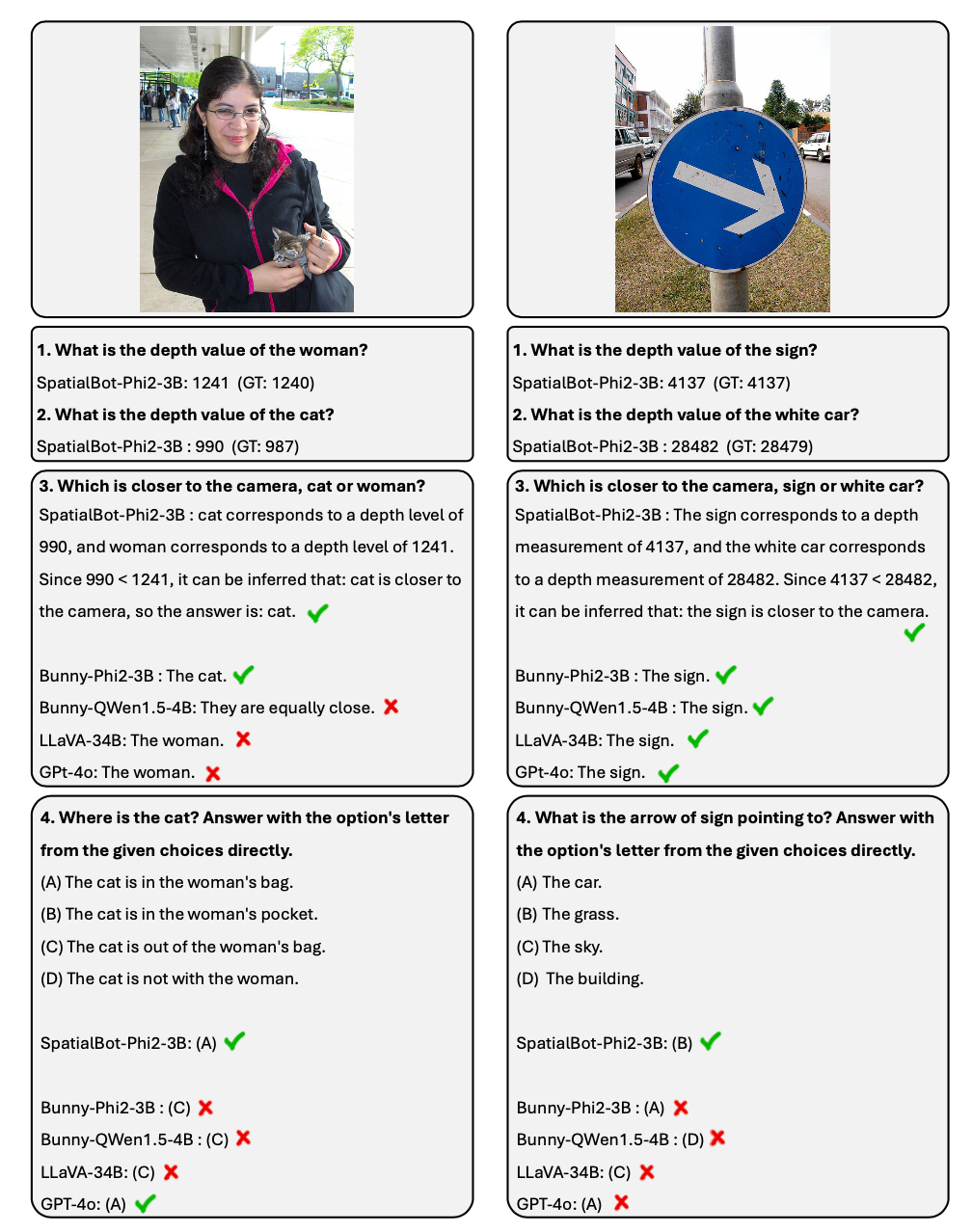
2. Für räumliche Verständnisaufgaben hat der Autor die SpatialBench-Liste angekündigt. Testen Sie die umfassenden Verständnisfähigkeiten des Modells durch eine sorgfältig konzipierte und kommentierte Qualitätssicherung. SpatialBot zeigt in der Liste Funktionen an, die GPT-4o nahekommen.
Wie versteht das Modell die Tiefenkarte? 1. Geben Sie die Tiefenkarte des Modells ein: Um Innen- und Außenaufgaben zu berücksichtigen, ist eine einheitliche Methode zur Tiefenkartenkodierung erforderlich. Bei Greif- und Navigationsaufgaben in Innenräumen ist möglicherweise eine Genauigkeit im Millimeterbereich erforderlich. Bei Szenen im Freien ist möglicherweise eine Tiefenwertreichweite von mehr als 100 Metern erforderlich. Die Ordinalkodierung wird für die Kodierung bei herkömmlichen Sehaufgaben verwendet, der Wert der Ordinalzahl kann jedoch nicht addiert oder subtrahiert werden. Um alle Tiefeninformationen so weit wie möglich beizubehalten, verwendet SpatialBot direkt die metrische Tiefe in Millimetern im Bereich von 1 mm bis 131 m und verwendet uint24 oder den dreikanaligen uint8, um diese Werte beizubehalten.
2. Um genaue Tiefeninformationen zu erhalten, ruft SpatialBot DepthAPI in Form von Punkten auf, um bei Bedarf genaue Tiefenwerte zu erhalten. Wenn Sie die Tiefe eines Objekts ermitteln möchten, denkt SpatialBot zunächst an den Begrenzungsrahmen des Objekts und ruft dann die API unter Verwendung des Mittelpunkts des Begrenzungsrahmens auf. 3. SpatialBot verwendet den Mittelpunkt des Objekts, den Tiefendurchschnitt, das Maximum und das Minimum, um die Tiefe zu beschreiben.
in in, in,
1. SpatialBot basiert auf mehreren Basis-LLMs von 3B bis 8B. Durch das Erlernen räumlicher Kenntnisse in SpatialQA zeigt SpatialBot auch erhebliche Leistungsverbesserungen bei häufig verwendeten MLLM-Datensätzen (MME, MMBench usw.).
2. SpatialBot zeigte auch erstaunliche Ergebnisse bei bestimmten Aufgaben wie Open X-Embodiment und den vom Autor gesammelten Roboter-Crawling-Daten. B Bagaimana untuk menandakan data Spatialbot General Scenaries
Bagaimana untuk menandakan data? Soalan yang direka dengan teliti tentang pemahaman spatial, seperti kedalaman, hubungan jarak, atas dan bawah, hubungan kedudukan depan dan belakang kiri dan kanan, hubungan saiz dan termasuk isu penting dalam penjelmaan, seperti sama ada dua objek berada dalam kenalan.
Dalam set ujian SpatialBench, soalan, pilihan dan jawapan terlebih dahulu difikirkan secara manual. Untuk mengembangkan saiz set ujian, GPT juga digunakan untuk anotasi dengan proses yang sama.
Set latihan SpatialQA merangkumi tiga aspek:
Memahami peta kedalaman secara langsung, biarkan model melihat peta kedalaman, menganalisis taburan kedalaman, dan meneka objek yang mungkin disertakan; Pemahaman dan Penaakulan perhubungan ruang; daripada robot itu.
Terbuka Apabila menggunakan GPT untuk menganotasi bahagian data ini, GPT akan melihat peta kedalaman, menerangkan peta kedalaman dan menaakul tentang pemandangan dan objek yang mungkin terkandung di dalamnya, kemudian ia akan melihat peta RGB dan menapis penerangan dan alasan yang betul .
Das obige ist der detaillierte Inhalt vonNach Li Feifeis „räumlicher Intelligenz' schlugen die Shanghai Jiao Tong University, die Zhiyuan University, die Peking University usw. das große räumliche Modell SpatialBot vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn




 2. Schnappen Sie sich die mittlere Teetasse
2. Schnappen Sie sich die mittlere Teetasse