
Heim >Technologie-Peripheriegeräte >KI >ECCV2024 |. Das Harvard-Team entwickelt FairDomain, um Fairness bei der domänenübergreifenden Segmentierung und Klassifizierung medizinischer Bilder zu erreichen
ECCV2024 |. Das Harvard-Team entwickelt FairDomain, um Fairness bei der domänenübergreifenden Segmentierung und Klassifizierung medizinischer Bilder zu erreichen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-08-05 20:04:361358Durchsuche

Herausgeber |. ScienceAI
Im Bereich der künstlichen Intelligenz (KI), insbesondere der medizinischen KI, ist die Auseinandersetzung mit Fairness-Fragen von entscheidender Bedeutung, um faire medizinische Ergebnisse sicherzustellen.
Vor kurzem wurden im Rahmen der Bemühungen zur Verbesserung der Fairness neue Methoden und Datensätze eingeführt. Allerdings wurde die Frage der Fairness im Zusammenhang mit der Domänenübertragung kaum untersucht, obwohl Kliniken bei der Patientendiagnose häufig auf unterschiedliche Bildgebungstechnologien (z. B. unterschiedliche Bildgebungsmodalitäten der Netzhaut) zurückgreifen.
In diesem Artikel wird FairDomain vorgeschlagen, die erste systematische Studie zur Fairness von Algorithmen bei der Domänenübertragung. Wir testen die hochmodernen Algorithmen zur Domänenanpassung (DA) und Domänengeneralisierung (DG) für die Segmentierung und Klassifizierung medizinischer Bilder Aufgaben, die darauf abzielen, zu verstehen, wie Vorurteile zwischen verschiedenen Bereichen übertragen werden.
Wir schlagen außerdem ein neues Plug-and-Play-Modul „Fair Identity Attention“ (FIA) vor, um die Fairness verschiedener DA- und DG-Algorithmen zu verbessern, indem ein Selbstaufmerksamkeitsmechanismus verwendet wird, um die Bedeutung von Merkmalen basierend auf demografischen Attributen Geschlecht anzupassen.
Darüber hinaus haben wir den ersten Domain-Shift-Datensatz mit Schwerpunkt auf Fairness organisiert und veröffentlicht, der medizinische Segmentierungs- und Klassifizierungsaufgaben zweier gepaarter Bildgebungsmodalitäten derselben Patientenpopulation enthält, um Domain-Shift-Fairness rigoros zu bewerten. Der Ausschluss der verwirrenden Auswirkungen von Unterschieden in der Populationsverteilung zwischen Quell- und Zieldomänen wird eine klarere Quantifizierung der Leistung des Domänentransfermodells ermöglichen.
Unsere umfassende Bewertung zeigt, dass die vorgeschlagene FIA die Modellgerechtigkeit und Leistung unter verschiedenen Bevölkerungsgruppen bei allen Domänenübertragungsaufgaben (d. h. DA und DG) erheblich verbessert und den Stand der Technik sowohl bei Segmentierungs- als auch bei Klassifizierungsaufgaben übertrifft Weg.
Teilen Sie hier die Arbeit des endgültigen Entwurfs des ECCV 2024 „FairDomain: Achieving Fairness in Cross-Domain Medical Image Segmentation and Classification“

Artikeladresse: https://arxiv.org/abs/2407.08813
Code-Adresse: https://github.com/Harvard-Ophthalmology-AI-Lab/FairDomain
Datensatz-Website: https://ophai.hms.harvard.edu/datasets/harvard-fairdomain20k
Link zum Herunterladen des Datensatzes: https://drive.google.com/drive/folders/1huH93JVeXMj9rK6p1OZRub868vv0UK0O?usp=sharing
Harvard-Ophthalmology-AI-Lab ist bestrebt, qualitativ hochwertige Fairness-Datensätze und weitere Fairness-Datensätze bereitzustellen Klicken Sie auf die Datensatz-Homepage des Labors: https://ophai.hms.harvard.edu/datasets/
Hintergrund
In den letzten Jahren hat die Weiterentwicklung des Deep Learning im Bereich der medizinischen Bildgebung die Klassifizierung und verbessert Segmentierungsaufgaben Wirkung. Diese Technologien tragen dazu bei, die Diagnosegenauigkeit zu verbessern, die Behandlungsplanung zu vereinfachen und letztendlich die Gesundheit der Patienten zu verbessern. Eine große Herausforderung beim Einsatz von Deep-Learning-Modellen in verschiedenen medizinischen Umgebungen ist jedoch die dem Algorithmus innewohnende Voreingenommenheit und Diskriminierung bestimmter demografischer Gruppen, die die Fairness der medizinischen Diagnose und Behandlung beeinträchtigen kann.
Einige neuere Forschungsarbeiten haben begonnen, das Problem der Algorithmusverzerrung in der medizinischen Bildgebung zu lösen, und einige Methoden entwickelt, um die Fairness von Deep-Learning-Modellen zu verbessern. Allerdings gehen diese Methoden in der Regel davon aus, dass die Datenverteilung während der Trainings- und Testphasen unverändert bleibt, was in tatsächlichen medizinischen Szenarien oft nicht der Fall ist.
Zum Beispiel können verschiedene Kliniken für Grundversorgung und Spezialkrankenhäuser für die Diagnose auf unterschiedliche Bildgebungstechnologien (z. B. unterschiedliche Netzhautbildgebungsmodalitäten) zurückgreifen, was zu erheblichen Domänenverschiebungen führt, die sich wiederum auf die Leistung und Fairness des Modells auswirken.
Daher muss bei der tatsächlichen Bereitstellung die Domänenübertragung berücksichtigt und Modelle erlernt werden, die die Fairness in domänenübergreifenden Szenarien aufrechterhalten können.
Obwohl Domänenanpassung und Domänengeneralisierung in der Literatur ausführlich untersucht wurden, konzentrierten sich diese Studien hauptsächlich auf die Verbesserung der Modellgenauigkeit und ignorierten dabei die Wichtigkeit, sicherzustellen, dass Modelle faire Vorhersagen für verschiedene Bevölkerungsgruppen liefern. Insbesondere im medizinischen Bereich wirken sich Entscheidungsmodelle direkt auf die menschliche Gesundheit und Sicherheit aus, weshalb die Untersuchung domänenübergreifender Fairness von großer Bedeutung ist.
Allerdings gibt es derzeit nur wenige Studien, die begonnen haben, sich mit der Frage der domänenübergreifenden Fairness zu befassen, und diesen Studien mangelt es an systematischer und umfassender Untersuchung und sie konzentrieren sich in der Regel nur auf die Domänenanpassung oder -verallgemeinerung, selten jedoch auf beides gleichzeitig. Darüber hinaus löst die bestehende Forschung hauptsächlich medizinische Klassifizierungsprobleme und ignoriert dabei die ebenso wichtige medizinische Segmentierungsaufgabe im Rahmen der Domänenübertragung.
Um diese Probleme zu lösen, stellen wir FairDomain vor, die erste Studie im Bereich der medizinischen Bildgebung, die systematisch die Fairness von Algorithmen beim Domänentransfer untersucht.
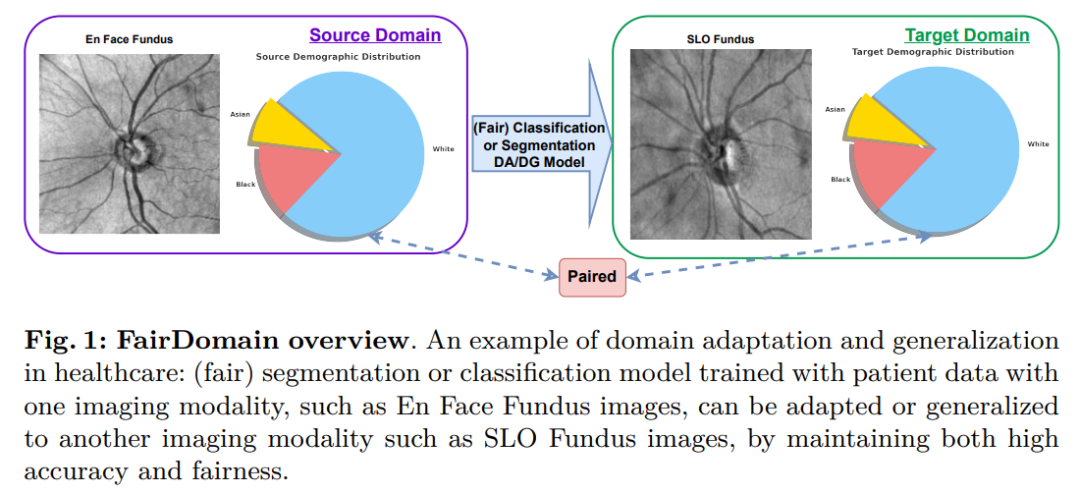
Wir führen umfangreiche Experimente mit mehreren hochmodernen Domänenanpassungs- und Generalisierungsalgorithmen durch, um deren Genauigkeit und Fairness unter verschiedenen demografischen Attributen zu bewerten und zu verstehen, wie sich Fairness über verschiedene Domänen hinweg überträgt.
Unsere Beobachtungen zeigen, dass sich die Gruppenleistungsunterschiede zwischen Quell- und Zieldomänen bei verschiedenen medizinischen Klassifizierungs- und Segmentierungsaufgaben deutlich verschärfen. Dies zeigt die Notwendigkeit, fairnessorientierte Algorithmen zu entwickeln, um dieses dringende Problem wirksam anzugehen.

Um die Mängel bestehender Bemühungen zur Verzerrungsminderung auszugleichen, führen wir einen neuen vielseitigen Fair Identity Attention (FIA)-Mechanismus ein, der nahtlos in verschiedene Domänenanpassungs- und Generalisierungsstrategien integriert werden kann von demografischen Merkmalen (z. B. Rassengruppe) zur Förderung der Fairness.
Eine zentrale Herausforderung bei der Entwicklung des FairDomain-Benchmarks ist das Fehlen eines medizinischen Bildgebungsdatensatzes, der Domänenverschiebungen in realen medizinischen Bereichen, die oft durch unterschiedliche Bildgebungstechnologien verursacht werden, wirklich widerspiegelt.
In vorhandenen medizinischen Datensätzen führen Unterschiede in der Patientendemografie zwischen Quell- und Zieldomänen zu Verwirrungen, was es schwierig macht zu unterscheiden, ob beobachtete algorithmische Verzerrungen auf Änderungen der demografischen Verteilung oder inhärente Domänenverschiebungen zurückzuführen sind.
Um dieses Problem zu lösen, haben wir einen einzigartigen Datensatz kuratiert, der aus gepaarten Netzhautfundusbildern derselben Patientenkohorte besteht und dabei zwei verschiedene Bildgebungsmodalitäten (En-Face- und SLO-Fundusbilder) verwendet, speziell für die Analyse der algorithmischen Verzerrung von Domänenübertragungsszenarien.
Zusammenfassung unserer Beiträge:
2. Die Technologie zur fairen Identitätsaufmerksamkeit wird eingeführt, um die Genauigkeit und Fairness bei der Domänenanpassung und -verallgemeinerung zu verbessern.
3. Erstellung eines umfangreichen gepaarten medizinischen Segmentierungs- und Klassifizierungsdatensatzes für die Fairness-Forschung, insbesondere zur Untersuchung von Fairness-Fragen bei Domänenübertragungen.
Datenerfassung und Qualitätskontrolle
Die Probanden wurden zwischen 2010 und 2021 aus einer großen akademischen Augenklinik der Harvard Medical School ausgewählt. In dieser Studie werden zwei domänenübergreifende Aufgaben untersucht, nämlich medizinische Segmentierungs- und medizinische Klassifizierungsaufgaben. Für die medizinische Segmentierungsaufgabe umfassen die Daten:
4
5. Anmerkung zu Tassen- und Tellermasken. Konkret wird zunächst die Pixelanmerkung des Bereichs zwischen Becher und Bandscheibe durch das OCT-Gerät erfasst, und die Software des OCT-Herstellers segmentiert den Bandscheibenrand im 3D-OCT in die Öffnungen der Bruchschen Membran und erkennt den Becherrand als innere Begrenzungsmembran (ILM). ) die Ebene schneiden Der Schnittpunkt der minimalen Oberfläche. Aufgrund des hohen Kontrasts der Bruchschen Membranöffnungen und inneren Grenzmembranen zum Hintergrund können diese Grenzen leicht segmentiert werden. Da die Software des OCT-Herstellers 3D-Informationen nutzt, ist die Tassen-Scheiben-Segmentierung im Allgemeinen zuverlässig. Angesichts der begrenzten Verfügbarkeit und der hohen Kosten von OCT-Geräten in der Primärversorgung schlagen wir eine Methode zur Übertragung von 3D-OCT-Anmerkungen auf 2D-SLO-Fundusbilder vor, um die Effizienz des frühen Glaukom-Screenings zu verbessern. Wir verwenden das NiftyReg-Tool, um SLO-Fundusbilder präzise mit OCT-abgeleiteten Pixelanmerkungen auszurichten und so eine große Anzahl hochwertiger SLO-Fundusmaskenanmerkungen zu generieren. Dieser Prozess wurde von einem Team medizinischer Experten mit einer Erfolgsquote bei der Registrierung von 80 % validiert, wodurch der Anmerkungsprozess für eine breitere Verwendung in der Grundversorgung optimiert wurde. Wir nutzen diese ausgerichteten und manuell überprüften Anmerkungen in Kombination mit SLO- und En-face-Fundusbildern, um die algorithmische Fairness von Segmentierungsmodellen unter Domänenverschiebung zu untersuchen. Für die medizinische Klassifizierungsaufgabe umfassen die Daten die folgenden vier Arten: 1. SLO-Fundusbildscan; 4 . Die Probanden im medizinischen Klassifizierungsdatensatz werden basierend auf den Ergebnissen der Gesichtsfeldtests in zwei Kategorien unterteilt: normal und Glaukom.Datenfunktionen
Der medizinische Segmentierungsdatensatz enthält 10.000 Proben von 10.000 Probanden. Wir teilen die Daten in einen Trainingssatz mit 8000 Proben und einen Testsatz mit 2000 Proben auf. Das Durchschnittsalter der Patienten betrug 60,3 ± 16,5 Jahre. Der Datensatz enthält sechs demografische Attribute, darunter Alter, Geschlecht, Rasse, ethnische Zugehörigkeit, bevorzugte Sprache und Familienstand. Die demografische Verteilung ist wie folgt: Geschlecht: 58,5 % weiblich, 41,5 % männlich;Rasse: 9,2 % asiatisch, 14,7 % schwarz, 76,1 % weiß;
Ethnizität: 90,6 % nicht-hispanisch, 3,7 % hispanisch 5,7 % entfielen auf Unbekannt; Bevorzugte Sprache: 92,4 % auf Englisch, 1,5 % auf Spanisch, 1 % auf andere Sprachen, 5,1 % auf Unbekannt. Familienstand: verheiratet oder verpartnert 57,7 %, ledig 27,1 %, geschieden 6,8 %, rechtskräftig getrennt 0,8 %, verwitwet 5,2 %, unbekannt 2,4 %. Ebenso enthält der medizinische Klassifizierungsdatensatz 10.000 Proben von 10.000 Probanden mit einem Durchschnittsalter von 60,9 ± 16,1 Jahren. Wir teilen die Daten in einen Trainingssatz mit 8000 Proben und einen Testsatz mit 2000 Proben auf. Die demografische Verteilung ist wie folgt: Geschlecht: 72,5 % weiblich, 27,5 % männlich; Rasse: 8,7 % asiatisch, 14,5 % schwarz, 76,8 % weiß; Ethnizität: 96,0 % Nicht-Hispanoamerikaner, 4,0 % sind Hispanoamerikaner. ;Bevorzugte Sprache: 92,6 % Englisch, 1,7 % Spanisch, 3,6 % andere Sprachen, 2,1 % unbekannt;
Familienstand: 58,5 % verheiratet oder in einer Partnerschaft, 26,1 % ledig, 6,9 % geschieden, 0,8 % davon sind verwitwet 1,9 %, auf „Unbekannt“ entfielen 5,8 %.
Diese detaillierten demografischen Informationen bieten eine reichhaltige Datengrundlage für eingehende Untersuchungen zur Fairness bei domänenübergreifenden Aufgaben.
Methoden zur Verbesserung der Fairness domänenübergreifender KI-Modelle Fair Identity Attention (FIA)

Problemdefinition
Domänenanpassung (DA) und Domänengeneralisierung (DG) Es handelt sich um eine Schlüsseltechnik in Die Entwicklung von Modellen für maschinelles Lernen ist darauf ausgelegt, die Variabilität zu bewältigen, die auftreten kann, wenn ein Modell von einem bestimmten Bereich auf einen anderen angewendet wird.
Im Bereich der medizinischen Bildgebung sind DA- und DG-Techniken von entscheidender Bedeutung für die Erstellung von Modellen, die Schwankungen zwischen verschiedenen medizinischen Einrichtungen, Bildgebungsgeräten und Patientenpopulationen zuverlässig bewältigen können. Ziel dieses Artikels ist es, die Fairness-Dynamik im Kontext der Domänenübertragung zu untersuchen und Methoden zu entwickeln, um sicherzustellen, dass Modelle bei der Anpassung oder Verallgemeinerung an neue Domänen fair und zuverlässig bleiben.
Unser Ziel ist es, eine Methodenfunktion f zu entwickeln, die die häufige Verschlechterung der Fairness abmildert, wenn ein Modell von der Quelldomäne in die Zieldomäne übertragen wird. Solche Verschärfungen sind in erster Linie auf die Möglichkeit zurückzuführen, dass Domänenverschiebungen bestehende Verzerrungen im Datensatz verstärken, insbesondere solche im Zusammenhang mit demografischen Merkmalen wie Geschlecht, Rasse oder ethnischer Zugehörigkeit.
Um dieses Problem anzugehen, schlagen wir einen auf Aufmerksamkeitsmechanismen basierenden Ansatz vor, der darauf abzielt, Bildmerkmale zu identifizieren und zu nutzen, die für nachgelagerte Aufgaben wie Segmentierung und Klassifizierung relevant sind, und dabei demografische Attribute zu berücksichtigen.
Abbildung 3 zeigt die Architektur des vorgeschlagenen Fair-Identity-Aufmerksamkeitsmoduls. Dieses Modul erhält zunächst die Eingabebild-Einbettung E_i und die Attribut-Einbettung E_a durch Verarbeitung des Eingabebildes und der eingegebenen statistischen Attributbeschriftungen. Diese Einbettungen werden dann zur Positionseinbettung E_p hinzugefügt. Die detaillierte Berechnungsformel lautet wie folgt:
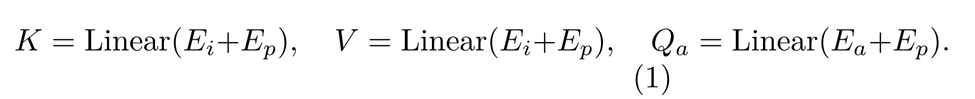
Durch Berechnung des Skalarprodukts von Abfrage und Schlüssel extrahieren wir die Ähnlichkeitsmatrix, die sich auf das aktuelle Merkmalsattribut bezieht. Das Skalarprodukt aus dieser Matrix und diesem Wert wird dann verwendet, um Features zu extrahieren, die in nachgelagerten Aufgaben für jedes Feature-Attribut von Bedeutung sind. Dieser Prozess wird durch die folgende Formel dargestellt:

wobei D ein Skalierungsfaktor ist, um übermäßig große Werte in der Softmax-Funktion zu vermeiden.
Anschließend fügt eine Restverbindung E_i zur Ausgabe der Aufmerksamkeit hinzu, um die Integrität der Eingabeinformationen aufrechtzuerhalten. Schließlich extrahieren eine Normalisierungsschicht und eine mehrschichtige Perzeptronschicht (MLP) weitere Merkmale. Nach einer weiteren Restoperation an den Ausgaben dieser beiden Schichten erhalten wir die endgültige Ausgabe des Fair-Attention-Moduls.
Der Fair Identity Attention Mechanism ist ein leistungsstarkes und vielseitiges Tool, das entwickelt wurde, um die Modellleistung zu verbessern und gleichzeitig Fairnessprobleme zu lösen. Durch die explizite Berücksichtigung demografischer Merkmale wie Geschlecht, Rasse oder ethnischer Zugehörigkeit wird sichergestellt, dass erlernte Darstellungen nicht unbeabsichtigt die in den Daten vorhandenen Vorurteile verstärken.
Durch seine Architektur lässt es sich als Plug-in-Komponente nahtlos in jedes bestehende Netzwerk integrieren. Dieser modulare Charakter ermöglicht es Forschern und Praktikern, faire Identitätsaufmerksamkeit in ihre Modelle zu integrieren, ohne dass umfangreiche Änderungen an der zugrunde liegenden Architektur erforderlich sind.
Daher trägt das Modul „Fair Identity Attention“ nicht nur zur Verbesserung der Modellgenauigkeit und Fairness bei Segmentierungs- und Klassifizierungsaufgaben bei, sondern fördert auch die Implementierung vertrauenswürdiger KI, indem es die faire Behandlung verschiedener Gruppen im Datensatz fördert.
Experimente
Algorithmusgerechtigkeit beim Domänentransfer
In unseren Experimenten analysieren wir zunächst die Fairness im Kontext des Domänentransfers und konzentrieren uns dabei insbesondere auf die Aufgabe der Tassen- und Tellersegmentierung. Unter Cup-to-Disc-Segmentierung versteht man den Prozess der genauen Abgrenzung von Augenhöhle und Papille in Fundusbildern, der für die Berechnung des Cup-to-Disc-Verhältnisses (CDR) von entscheidender Bedeutung ist, einem Schlüsselparameter bei der Beurteilung des Fortschreitens und Risikos eines Glaukoms.
Diese Aufgabe ist im Bereich der medizinischen Bildgebung besonders wichtig, insbesondere bei der Diagnose und Behandlung von Augenerkrankungen wie dem Glaukom. Da es sich bei der Augenhöhle um einen wichtigen Teilbereich der Papille handelt, formulieren wir die Segmentierungsaufgabe in eine Segmentierung von Augenhöhle und Rand (der Gewebebereich zwischen der Augenhöhle und dem Rand der Papille) um, um Fehler aufgrund der großen Überlappung zwischen Augenhöhle und Papille zu vermeiden optische Disc. Dies führt zu Leistungsverzerrungen.
Wir haben die Fairness-Leistung in drei verschiedenen Bevölkerungsgruppen (Geschlecht, Rasse und ethnische Zugehörigkeit) in zwei verschiedenen Bereichen untersucht: En-face-Fundusbilder, die mit der optischen Kohärenztomographie (OCT) aufgenommen wurden, und Scanning-Laser-Fundusbilder (SLO).
In nachfolgenden Experimenten haben wir das En-Face-Fundusbild als Quelldomäne und das SLO-Fundusbild als Zieldomäne ausgewählt. Der Grund dafür ist, dass En-face-Fundusbilder im Vergleich zu SLO-Fundusbildern in der Augenheilkunde häufiger anzutreffen sind und daher die Datenverfügbarkeit deutlich höher ist.
Daher entscheiden wir uns dafür, das En-face-Fundusbild als Quelldomäne und das SLO-Fundusbild als Zieldomäne zu verwenden. Für die Klassifizierungsaufgabe verwenden wir die Fundusbilder dieser beiden Domänen als Quell- und Zieldomänen, klassifiziert in zwei Kategorien: normal und Glaukom.
Bewertungsmetriken
Wir verwenden Dice- und IoU-Metriken, um die Segmentierungsleistung zu bewerten, und AUC, um die Leistung von Klassifizierungsaufgaben zu bewerten. Diese traditionellen Segmentierungs- und Klassifizierungsmetriken spiegeln zwar die Modellleistung wider, berücksichtigen jedoch nicht grundsätzlich die Fairness zwischen demografischen Gruppen.
Um den potenziellen Kompromiss zwischen Modellleistung und Fairness in der medizinischen Bildgebung anzugehen, verwenden wir die neuartige Equity Scaled Performance (ESP)-Metrik, um Leistung und Fairness bei Segmentierungs- und Klassifizierungsaufgaben zu bewerten.
Lassen Sie ∈{Dice,IoU,AUC,...}M in {Dice,IoU, AUC, .}M∈{Dice,IoU,AUC,...} eine allgemeine Leistung darstellen, die für die Segmentierung oder den Klassifizierungsindex geeignet ist . Herkömmliche Bewertungen ignorieren häufig demografische Identitätsmerkmale und verfehlen dadurch kritische Fairness-Bewertungen. Um die Fairness einzubeziehen, berechnen wir zunächst den Leistungsunterschied Δ, definiert als die kollektive Abweichung der Kennzahlen jeder demografischen Gruppe von der Gesamtleistung, die wie folgt formuliert wird:

Wenn Leistungsgerechtigkeit zwischen den Gruppen erreicht wird, liegt Δ nahe bei Null , spiegelt den kleinsten Unterschied wider. Dann kann die ESP-Metrik wie folgt formuliert werden:
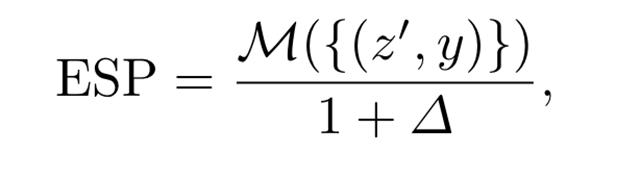
Diese einheitliche Metrik hilft bei der umfassenden Bewertung von Deep-Learning-Modellen, wobei der Schwerpunkt nicht nur auf deren Genauigkeit liegt (z. B. durch Messungen wie Dice, IoU und AUC), sondern auch auch auf ihre Leistung in unterschiedlicher Gerechtigkeit zwischen Bevölkerungsgruppen.
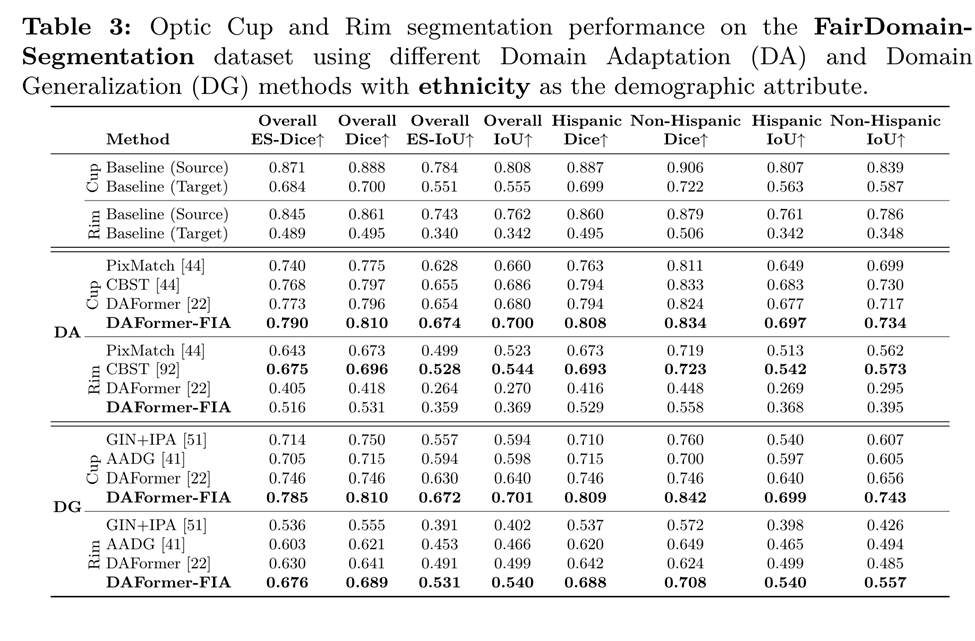
Cup-Rim-Segmentierungsergebnisse unter Domänenverschiebungen


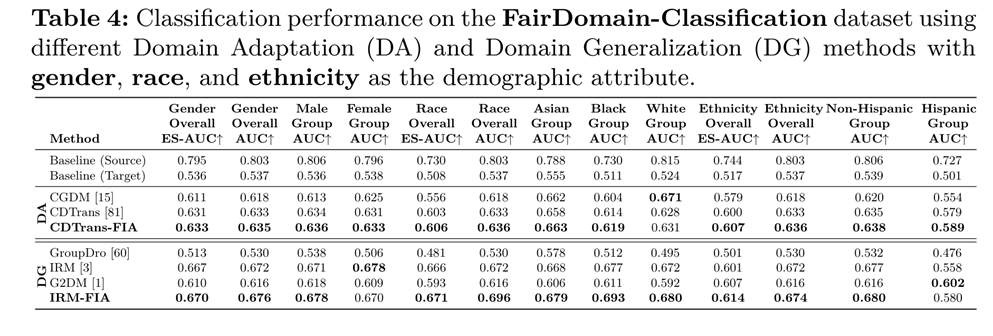
Glaukom-Klassifizierungsergebnisse unter Domänenverschiebungen
Zusammenfassung
Dieser Artikel konzentriert sich auf künstliche Intelligenz (insbesondere medizinische). Fairnessfragen in der KI), die für eine gerechte Gesundheitsversorgung von entscheidender Bedeutung sind.
Da Kliniken möglicherweise unterschiedliche Bildgebungstechnologien verwenden, bleibt die Frage der Fairness bei der Domänenübertragung weitgehend unerforscht. Unsere Arbeit stellt FairDomain vor, eine umfassende Studie zur algorithmischen Fairness bei Domänenübertragungsaufgaben, einschließlich Domänenanpassung und -verallgemeinerung, die zwei gemeinsame Aufgaben der medizinischen Segmentierung und Klassifizierung umfasst.
Wir schlagen ein neuartiges Plug-and-Play-Modul „Fair Identity Attention“ (FIA) vor, um die Korrelation von Merkmalen basierend auf demografischen Attributen durch einen Aufmerksamkeitsmechanismus zu erlernen und so die Fairness bei Domänenübertragungsaufgaben zu verbessern.
Wir haben außerdem den ersten fairnessfokussierten domänenübergreifenden Datensatz erstellt, der zwei gepaarte Bildgebungsbilder derselben Patientenkohorte enthält, um die verwirrenden Auswirkungen von Änderungen der demografischen Verteilung auf die Modellgerechtigkeit auszuschließen und eine präzise Bewertung der Auswirkungen des Domänentransfers auf die Modellgerechtigkeit zu ermöglichen.
Unser Fair-Identity-Attention-Modell kann bestehende Domänenanpassungs- und Generalisierungsmethoden verbessern, sodass die Modellleistung unter Berücksichtigung der Fairness verbessert werden kann.
Hinweis: Das Titelbild wird von KI generiert.
Das obige ist der detaillierte Inhalt vonECCV2024 |. Das Harvard-Team entwickelt FairDomain, um Fairness bei der domänenübergreifenden Segmentierung und Klassifizierung medizinischer Bilder zu erreichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr