
Heim >Technologie-Peripheriegeräte >KI >Das Team von Jia Jiaya hat sich mit der Cambridge Tsinghua University und anderen zusammengetan, um ein neues Bewertungsparadigma zu fördern, um „hohe Werte und niedrige Energie' in großen Modellen in einer Sekunde zu erkennen
Das Team von Jia Jiaya hat sich mit der Cambridge Tsinghua University und anderen zusammengetan, um ein neues Bewertungsparadigma zu fördern, um „hohe Werte und niedrige Energie' in großen Modellen in einer Sekunde zu erkennen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-07-19 13:55:25577Durchsuche

MR-Ben hat viele in- und ausländische First-Line-Open-Source- und Closed-Source-Modelle sorgfältig evaluiert, wie z. B. GPT4-Turbo, Cluade3.5-Sonnet, Mistral-Large, Zhipu-GLM4, Moonshot-v1, Yi-Large, Qwen2 -70B, Deepseek-V2 usw. und führte eine detaillierte Analyse durch.
Welche scheinbar schönen großen Modelle werden „entfernt“ und welches Modell hat die stärkste Oberfläche? Derzeit sind der gesamte Code und die Daten dieser Arbeit Open Source. Werfen wir einen Blick darauf!
Projektseite: https://randolph-zeng.github.io/Mr-Ben.github.io/
Arxiv-Seite: https://arxiv.org/abs/2406.13975
Github Repo: https://github.com /dvlab-research/Mr-Ben
MR-Ben durchbricht die „hohe Punktzahl und niedrige Energie“ großer Modelle in Sekunden
Nachdem der Bereich der künstlichen Intelligenz in den GPT-Moment eingetreten war, arbeiteten Wissenschaft und Industrie zusammen und alle neuen Modelle wurden veröffentlicht Monat oder sogar jede Woche.
Große Modelle tauchen immer wieder auf. Welche Standards werden verwendet, um die spezifischen Fähigkeiten großer Modelle zu messen? Die aktuelle Mainstream-Richtung besteht darin, menschliche standardisierte Tests zu verwenden – Multiple-Choice-Fragen und Lückentext-Fragen, um umfangreiche Modellbewertungen durchzuführen. Die Verwendung dieser Testmethode bietet viele Vorteile, die sich wie folgt zusammenfassen lassen:
• Standardisierte Tests sind leicht zu quantifizieren und zu bewerten, und die Standards sind klar, und was richtig ist, ist richtig und was falsch ist, ist falsch.
• Die Indikatoren sind intuitiv und es ist einfach, die bei der inländischen Hochschulaufnahmeprüfung oder der amerikanischen Hochschulaufnahmeprüfung SAT erzielten Ergebnisse zu vergleichen und zu verstehen.
• Quantitative Ergebnisse sind natürlich aktuell (z. B. ist die Fähigkeit von GPT4, die US-amerikanische Anwaltszertifizierungsprüfung problemlos zu bestehen, äußerst auffällig).
Aber wenn Sie sich mit der Trainingsmethode großer Modelle befassen, werden Sie feststellen, dass diese schrittweise Denkkettenmethode zur Generierung der endgültigen Antwort nicht „zuverlässig“ ist.
Die Frage erscheint genau im Schritt-für-Schritt-Antwortprozess!
Das Pre-Training-Modell hat während des Pre-Trainings bereits Billionen von Wortelementen gesehen. Es ist schwer zu sagen, ob das zu bewertende Modell die entsprechenden Daten bereits gesehen hat und die Fragen durch „Auswendiglernen“ richtig beantworten kann. Bei der Schritt-für-Schritt-Antwort wissen wir nicht, ob das Modell aufgrund des richtigen Verständnisses und der richtigen Argumentation die richtige Option auswählt, da die Bewertungsmethode hauptsächlich auf der Überprüfung der endgültigen Antwort beruht.
Obwohl die akademische Gemeinschaft weiterhin Datensätze wie GSM8K und MMLU aktualisiert und umwandelt, beispielsweise eine mehrsprachige Version des MGSM-Datensatzes auf GSM8K einführt und schwierigere Fragen auf Basis von MMLU einführt, gibt es immer noch keine Möglichkeit, sie loszuwerden des Problems, die Lücken auszuwählen oder auszufüllen.
Darüber hinaus waren diese Datensätze alle mit ernsthaften Sättigungsproblemen konfrontiert. Die Werte großer Sprachmodelle für diese Indikatoren haben ihren Höhepunkt erreicht und sie haben allmählich ihre Unterscheidung verloren.
Zu diesem Zweck hat sich das Jiajiaya-Team mit vielen bekannten Universitäten wie MIT, Tsinghua und Cambridge zusammengetan und mit inländischen Head-Annotation-Unternehmen zusammengearbeitet, um einen Bewertungsdatensatz MR-Ben für den Argumentationsprozess komplexer Probleme zu annotieren.
MR-Ben hat eine „Bewertung“-Paradigmentransformation durchgeführt, die auf den Fragen aus den Vortrainings- und Testdatensätzen großer Modelle wie GSM8K, MMLU, LogiQA, MHPP und anderen großen Modellen basiert. Die generierten neuen Datensätze sind mehr schwieriger, differenzierter und realistischer. Es spiegelt die Denkfähigkeit des Modells wider!
Die Arbeit des Jiajiaya-Teams hat dieses Mal auch gezielte Verbesserungen vorgenommen, um bestehende Schwachstellen bei der Bewertung anzugehen:
Haben Sie keine Angst, dass Datenlecks dazu führen, dass Fragen in großem Umfang im Modell gespeichert werden, was zu überhöhten Ergebnissen führt? Es ist nicht erforderlich, die Fragen neu zu finden oder die Fragen zu verformen, um die Robustheit des Modells zu testen. MR-Ben ändert das Modell direkt von der Studentenidentität des Beantworters in den „Bewertungs“-Modus des Antwortprozesses und ermöglicht so das Große Modell soll der Lehrer sein, um zu testen, wie gut es die Wissenspunkte beherrscht!
Befürchten Sie nicht, dass das Modell kein Bewusstsein für den Problemlösungsprozess hat und möglicherweise „Illusionen“ oder Missverständnisse hat und die Antwort falsch versteht? MR-Ben rekrutiert direkt eine Gruppe hochrangiger Master- und Doktorgutachter, um den Problemlösungsprozess einer großen Anzahl von Fragen sorgfältig zu kommentieren. Zeigen Sie detailliert auf, ob der Problemlösungsprozess korrekt ist, wo der Fehler liegt und wo der Fehler liegt, und vergleichen Sie die Bewertungsergebnisse des großen Modells mit den Bewertungsergebnissen menschlicher Experten, um das Wissen des Modells zu testen Punkte.
Konkret organisierte das Jiajiaya-Team die gängigen Bewertungsdatensätze auf dem Markt wie GSM8K, MMLU, LogiQA, MHPP und andere Datensätze und unterteilte sie in mehrere Kategorien wie Mathematik, Physik, Chemie, Biologie, Code, Logik, Medizin usw., und auch verschiedene Schwierigkeitsgrade unterschieden. Für jede Kategorie und jede gesammelte Frage hat das Team sorgfältig den entsprechenden Schritt-für-Schritt-Problemlösungsprozess zusammengestellt und wurde von professionellen Master- und Doktorkommentatoren geschult und kommentiert.
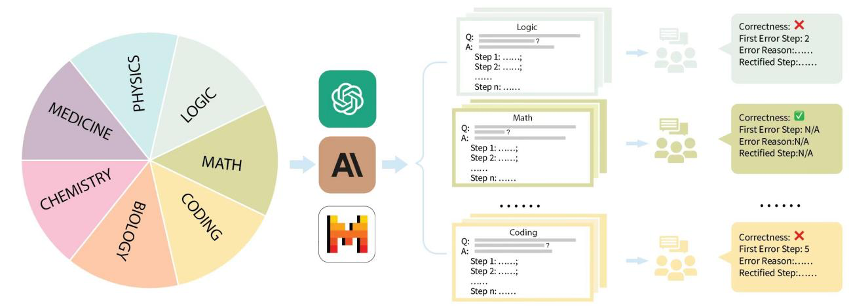
Next, let’s combine the specific examples given in MR-Ben’s work to see why the step-by-step method of generating final answers and related evaluations are unreliable.
As the evaluated "grading" model, GPT4-Turbo did not find the calculation errors hidden in the second step:
E.1 Mathematics
Subject: High School Mathematics
Question: Which smallest integer is divided by 4 as remainder 1, remainder 2 when divided by 3, remainder 2 when divided by 5?
Options: [A] 67 [B] 43 [C] 57 [D] 37
Answer: D
Sampling Model: Claude2
Model Solution Steps:
- Step 1: Check option A (67) when When 67 is divided by 4, the remainder is 3, not 1. So 67 is not the correct answer.
- Step 2: Check option B (43) When 43 is divided by 4, the remainder is 1. When 43 is divided by 3, the remainder is 3, not 2. So 43 is not the correct answer.
- Step 3: Check option C (57) When 57 is divided by 4, the remainder is 1. When 57 is divided by 3, the remainder is 0, not 2. So 57 is not the correct answer.
- Step 4: Check option D (37) When 37 is divided by 4, the remainder is 1. When 37 is divided by 3, the remainder is 1. When 37 is divided by 5, the remainder is 2.
-
Step 5: Option D (37) meets all conditions and is the correct answer.
Answer: Option D
Human annotation
Model answer correctness: Incorrect
First wrong step: Step 2
Model answer error reason:
In step 2, the model incorrectly calculated that the remainder of 43 divided by 4 is 1 instead of 3. The model assumes that when 43 is divided by 4 the remainder is 1, but the remainder should be 3. There is a calculation error here.The first correct step after correction: Step 2
When 43 is divided by 4, the remainder is 1. When 43 is divided by 3, the remainder is 1. When 43 is divided by 5, the remainder is 3, not 2. Therefore, 43 is not the correct answer.
Evaluation model: gpt-4-turbo
Model reply:
-Step 1: Step check the remainder of 67 divided by 4 and 3, and find that it meets the condition of being divided by 4 and remaining 3, which is a correct verification.
-Step 2: Check the remainders of dividing 43 by 4, 3, and 5, and find that the remainders of 1, 3, and 5 correctly match the expectations, except that the remainder of 5 does not meet the conditions.
-Step 3: Step Calculate the remainder of dividing 57 by 4 and 3, the remainders are 1 and 0 respectively. When 57 is divided by 3 the remainder does not meet the criteria.
-Step 4: Check and verify the remainders of dividing 37 by 4, 3, and 5. It is found that all expected remainders are accurate, and 37 meets all the conditions in the question.Is the solution process correct? Correct
The first error step: Not applicable
The reason for the first error step: Not applicable
It can be seen that when the question is given and the solution process is determined, the evaluation The language model method is transformed into allowing the model to "mark" the answer process, judge whether it is correct or incorrect, and point out the location and cause of the error. The accuracy of the solution process and the potential error locations can be calculated by comparing with the annotation results. The evaluation of model error steps and reasons can be handed over to GPT4 to determine whether the model is correct by comparing the explanation of the error reasons given by the annotator and the explanation of the error reasons of the model.
From the evaluation method, the method proposed by MR-Ben requires the model to conduct a detailed analysis of the premises, assumptions, and logic of each step in the problem-solving process, and to preview the reasoning process to determine whether the current step can lead to the correct direction. Answer. fenye1. This "grading" evaluation method is far more difficult than the evaluation method of just answering questions, but it can effectively avoid the problem of falsely high scores caused by the model's memorization of questions. It is difficult for a student who can only memorize questions to become a qualified marking teacher.
- Secondly, MR-Ben has achieved a large number of high-quality annotations by using manual and precise annotation process control, and the clever process design allows the evaluation method to be intuitively quantified.
- The Jiajiaya team also tested the top ten most representative language models and different versions. It can be seen that among the closed-source large language models, GPT4-Turbo has the best performance (although no calculation errors were found during "grading"). In most subjects, there are demos (k=1) and no demos. (k=0) are ahead of other models.
**Evaluation results of some open source large language models on the MR-Ben data set
It can be seen that the effects of some of the strongest open source large language models have caught up with some commercial models, and even the strongest closed source models are in MR-Ben. The performance on the Ben data set is still not saturated, and the difference between different models is large.
In addition, there are more interesting analyzes and findings in MR-Ben’s original paper, such as:

The open source models released by Qwen and Deepseek are not inferior to the PK closed source model even in the global echelon.
The pricing strategies and actual performance of different closed-source models are intriguing. Friends who are concerned about reasoning ability in usage scenarios can find their favorite model to use based on price and capabilities.
In low-resource scenarios, small models also have many highlights. In the MR-Ben evaluation, Phi-3-mini stood out among the small models, even higher than or the same as large models with tens of billions of parameters, showing the ability to fine-tune data importance.
MR-Ben scenes contain complex logical analysis and step-by-step inference. Too long context in Few-shot mode will confuse the model and cause a decline in performance.
MR-Ben has evaluated many generation-reflection-regeneration ablation experiments to check the differences between different prompting strategies and found that it has no effect on low-level models, and the effect on high-level models such as GPT4-Turbo is not obvious. On the contrary, for intermediate-level models, the effect is slightly improved because the wrong ones are always corrected and the right ones are corrected.
After roughly dividing the subjects evaluated by MR-Ben into knowledge-based, logical, computational, and algorithmic types, different models have their own advantages and disadvantages in different reasoning types.
The Jiajiaya team has uploaded a one-click evaluation method on github. All partners who are concerned about complex reasoning are welcome to evaluate and submit their own models. The team will update the corresponding leaderboard in a timely manner.
By the way, one-click evaluation using the official script only costs about 12M tokens. The process is very smooth, so give it a try!
Reference
Training Verifiers to Solve Math Word Problems (https://arxiv.org/abs/2110.14168)
Measuring Massive Multitask Language Understanding (https://arxiv.org/abs/2009.03300)
LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning(https://arxiv.org/abs/2007.08124)
MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation(https://arxiv.org/abs/2405.11430)
Sparks of Artificial General Intelligence: Early experiments with GPT-4(https://arxiv.org/abs/2303.12712)
Qwen Technical Report(https://arxiv.org/abs/2309.16609)
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model(https://arxiv.org/abs/2405.04434)
Textbooks Are All You Need(https://arxiv.org/abs/2306.11644)
Large Language Models Cannot Self- Correct Reasoning Yet(https://arxiv.org/abs/2310.01798)
Das obige ist der detaillierte Inhalt vonDas Team von Jia Jiaya hat sich mit der Cambridge Tsinghua University und anderen zusammengetan, um ein neues Bewertungsparadigma zu fördern, um „hohe Werte und niedrige Energie' in großen Modellen in einer Sekunde zu erkennen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr