Große Sprachmodelle (LLM) werden zunehmend in verschiedenen Bereichen eingesetzt. Allerdings ist ihr Textgenerierungsprozess teuer und langsam. Diese Ineffizienz wird dem Algorithmus der autoregressiven Dekodierung zugeschrieben: Die Generierung jedes Worts (Tokens) erfordert einen Vorwärtsdurchlauf, der Zugriff auf ein LLM mit Milliarden bis Hunderten von Milliarden Parametern erfordert. Dies führt dazu, dass die herkömmliche autoregressive Dekodierung langsamer ist. Kürzlich haben die University of Waterloo, das Canadian Vector Institute, die Peking University und andere Institutionen gemeinsam EAGLE veröffentlicht, das darauf abzielt, die Inferenzgeschwindigkeit großer Sprachmodelle zu verbessern und gleichzeitig eine konsistente Verteilung des Modellausgabetextes sicherzustellen. Diese Methode extrapoliert den zweiten Merkmalsvektor der obersten Ebene von LLM, was die Generierungseffizienz erheblich verbessern kann. 
- Technischer Bericht: https://sites.google.com/view/eagle-llm
- Code (unterstützt kommerzielles Apache 2.0): https://github.com/SafeAILab/EAGLE
EAGLE hat die folgenden Funktionen:
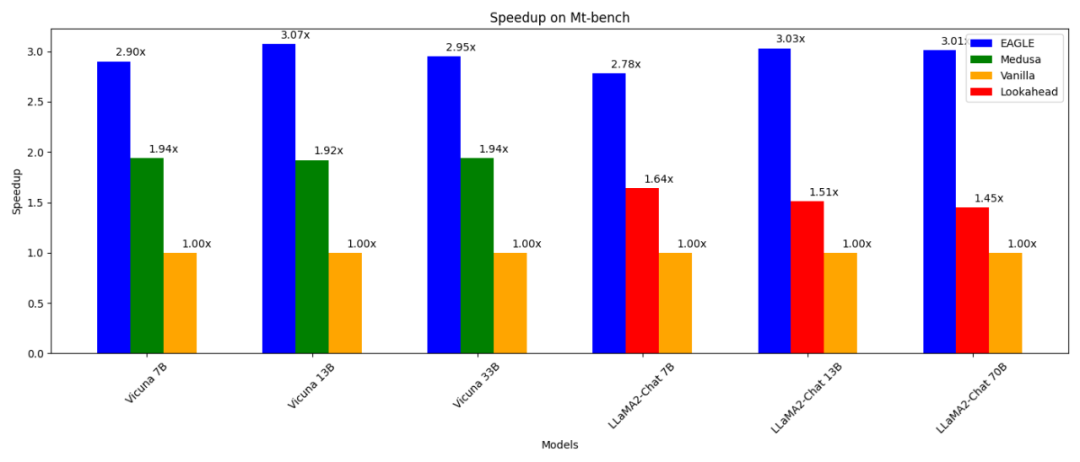
- 3-mal schneller als gewöhnliche autoregressive Dekodierung (13B);
- 2-mal schneller als Lookahead-Dekodierung (13B);
- als Medusa Decode (13B) 1,6-mal schneller;
- kann bei der Verteilung des generierten Textes nachweislich konsistent sein
-
kann auf RTX 3090 trainiert und getestet werden; kann in Verbindung mit anderen parallelen Technologien wie vLLM, DeepSpeed, Mamba, FlashAttention, Quantisierung und Hardwareoptimierung verwendet werden.
Eine Möglichkeit, die autoregressive Dekodierung zu beschleunigen, ist das spekulative Sampling. Diese Technik verwendet ein kleineres Entwurfsmodell, um die nächsten mehreren Wörter über die standardmäßige autoregressive Generierung zu erraten. Das ursprüngliche LLM überprüft dann diese erratenen Wörter parallel (wobei nur ein Vorwärtsdurchlauf zur Überprüfung erforderlich ist). Wenn das Entwurfsmodell α-Wörter genau vorhersagt, kann ein einziger Vorwärtsdurchlauf des ursprünglichen LLM α+1-Wörter erzeugen.
Beim spekulativen Sampling besteht die Aufgabe des Entwurfsmodells darin, das nächste Wort basierend auf der aktuellen Wortfolge vorherzusagen. Die Bewältigung dieser Aufgabe mit einem Modell mit einer deutlich geringeren Anzahl von Parametern ist äußerst anspruchsvoll und führt häufig zu suboptimalen Ergebnissen. Darüber hinaus sagt das Entwurfsmodell im standardmäßigen spekulativen Sampling-Ansatz das nächste Wort unabhängig voraus, ohne die umfangreichen semantischen Informationen zu nutzen, die vom ursprünglichen LLM extrahiert wurden, was zu potenziellen Ineffizienzen führt.
Diese Einschränkung inspirierte die Entwicklung von EAGLE. EAGLE nutzt die vom ursprünglichen LLM extrahierten Kontextmerkmale (d. h. den von der zweitobersten Ebene des Modells ausgegebenen Merkmalsvektor). EAGLE basiert auf den folgenden ersten Prinzipien:
Merkmalsvektorsequenzen sind komprimierbar, sodass es einfacher ist, nachfolgende Merkmalsvektoren basierend auf vorherigen Merkmalsvektoren vorherzusagen.
EAGLE trainiert ein leichtes Plug-in namens Auto-Regression Head, das zusammen mit der Worteinbettungsschicht das nächste Feature aus der zweitobersten Ebene des Originalmodells basierend auf der aktuellen Feature-Sequenz vorhersagt. Der eingefrorene Klassifizierungskopf des ursprünglichen LLM wird dann verwendet, um das nächste Wort vorherzusagen. Merkmale enthalten mehr Informationen als Wortsequenzen, was die Aufgabe der Regression von Merkmalen viel einfacher macht als die Aufgabe, Wörter vorherzusagen. Zusammenfassend lässt sich sagen, dass EAGLE auf der Merkmalsebene extrapoliert, indem es einen kleinen autoregressiven Kopf verwendet und dann einen eingefrorenen Klassifizierungskopf verwendet, um vorhergesagte Wortsequenzen zu generieren. Im Einklang mit ähnlichen Arbeiten wie Speculative Sampling, Medusa und Lookahead konzentriert sich EAGLE auf die Latenz der Inferenz pro Cue und nicht auf den Gesamtsystemdurchsatz.
EAGLE – eine Methode zur Steigerung der Effizienz der Generierung großer Sprachmodelle Die obige Abbildung zeigt den Unterschied in der Eingabe und Ausgabe zwischen EAGLE und der standardmäßigen spekulativen Stichprobe, Medusa und Lookahead. Die folgende Abbildung zeigt den Workflow von EAGLE. Im Vorwärtsdurchlauf des ursprünglichen LLM sammelt EAGLE Features aus der zweitobersten Ebene. Der autoregressive Kopf nimmt diese Merkmale und die Worteinbettungen zuvor generierter Wörter als Eingabe und beginnt, das nächste Wort zu erraten. Anschließend wird der eingefrorene Klassifizierungskopf (LM Head) verwendet, um die Verteilung des nächsten Wortes zu bestimmen, sodass EAGLE eine Stichprobe aus dieser Verteilung ziehen kann. Durch mehrmaliges Wiederholen der Stichproben führt EAGLE einen baumartigen Generierungsprozess durch, wie auf der rechten Seite der folgenden Abbildung dargestellt. In diesem Beispiel „erriet“ der dreifache Vorwärtspass von EAGLE einen Baum mit 10 Wörtern.
EAGLE verwendet einen leichten autoregressiven Kopf, um Merkmale des ursprünglichen LLM vorherzusagen. Um die Konsistenz der generierten Textverteilung sicherzustellen, validiert EAGLE anschließend die vorhergesagte Baumstruktur. Dieser Verifizierungsprozess kann mit einem Vorwärtsdurchgang abgeschlossen werden. Durch diesen Zyklus aus Vorhersage und Überprüfung ist EAGLE in der Lage, schnell Textwörter zu generieren. Die Kosten für das Training eines autoregressiven Kopfes sind sehr gering. EAGLE wird mithilfe des ShareGPT-Datensatzes trainiert, der knapp 70.000 Dialogrunden enthält. Auch die Anzahl der trainierbaren Parameter des autoregressiven Kopfes ist sehr gering. Wie im Bild oben blau dargestellt, sind die meisten Komponenten eingefroren. Das einzige zusätzliche Training, das erforderlich ist, ist der autoregressive Kopf, bei dem es sich um eine einschichtige Transformer-Struktur mit Parametern von 0,24 B bis 0,99 B handelt. Autoregressive Köpfe können auch dann trainiert werden, wenn die GPU-Ressourcen begrenzt sind. Beispielsweise kann die autoregressive Regression von Vicuna 33B in 24 Stunden auf einem RTX 3090-Server mit 8 Karten trainiert werden. Warum Worteinbettungen verwenden, um Funktionen vorherzusagen? Medusa verwendet nur die Funktionen der zweitobersten Ebene, um das nächste Wort vorherzusagen, das nächste Wort ... Im Gegensatz zu Medusa verwendet EAGLE auch dynamisch die aktuell abgetastete Worteinbettung als autoregressiven Kopfeingabeteil, um Vorhersagen zu treffen. Diese zusätzlichen Informationen helfen EAGLE, mit der unvermeidlichen Zufälligkeit im Stichprobenprozess umzugehen. Betrachten Sie das Beispiel im Bild unten, wobei davon ausgegangen wird, dass das Aufforderungswort „I“ ist. LLM gibt die Wahrscheinlichkeit an, dass auf „ich“ ein „bin“ oder „immer“ folgt. Medusa berücksichtigt nicht, ob „am“ oder „immer“ abgetastet wird, und sagt direkt die Wahrscheinlichkeit des nächsten Wortes unter „I“ voraus. Daher besteht Medusas Ziel darin, das nächste Wort für „Ich bin“ oder „Ich immer“ vorherzusagen, wenn nur „Ich“ gegeben wird. Aufgrund der zufälligen Natur des Sampling-Prozesses kann die gleiche Eingabe „I“ für Medusa ein unterschiedliches nächstes Wort als Ausgabe „ready“ oder „begin“ haben, was zu einem Mangel an konsistenter Zuordnung zwischen Eingaben und Ausgaben führt. Im Gegensatz dazu umfasst die Eingabe in EAGLE die Worteinbettungen der Stichprobenergebnisse, wodurch eine konsistente Zuordnung zwischen Eingabe und Ausgabe gewährleistet wird. Diese Unterscheidung ermöglicht es EAGLE, nachfolgende Wörter genauer vorherzusagen, indem der durch den Sampling-Prozess erstellte Kontext berücksichtigt wird.
Baumartige GenerationsstrukturAnders als andere Rate-Verifizierungs-Frameworks wie Speculative Sampling, Lookahead und Medusa übernimmt EAGLE dabei in der Phase des „Rateworts“ eine baumartige Generationsstruktur Erzielung einer höheren Dekodierungseffizienz. Wie in der Abbildung gezeigt, ist der Generierungsprozess der standardmäßigen spekulativen Stichprobenziehung und Lookahead linear oder verkettet. Da der Kontext während der Ratephase nicht konstruiert werden kann, generiert die Methode von Medusa Bäume durch das kartesische Produkt, was zu einem vollständig verbundenen Diagramm zwischen benachbarten Schichten führt. Dieser Ansatz führt oft zu bedeutungslosen Kombinationen, wie zum Beispiel „Ich fange an“. Im Gegensatz dazu erstellt EAGLE eine spärlichere Baumstruktur. Diese spärliche Baumstruktur verhindert die Bildung bedeutungsloser Sequenzen und konzentriert die Rechenressourcen auf sinnvollere Wortkombinationen.
Mehrere Runden spekulativer StichprobenziehungDie standardmäßige spekulative Stichprobenmethode behält die Konsistenz der Verteilung während des Prozesses des „Erratens von Wörtern“ bei. Um sich an baumartige Wortratenszenarien anzupassen, erweitert EAGLE diese Methode in eine mehrrundenrekursive Form. Im Folgenden wird der Pseudocode für mehrere Runden spekulativer Stichprobenentnahme dargestellt. Während des Baumgenerierungsprozesses zeichnet EAGLE die Wahrscheinlichkeit auf, die jedem abgetasteten Wort entspricht. Durch mehrere Runden spekulativer Stichproben stellt EAGLE sicher, dass die endgültig generierte Verteilung jedes Wortes mit der des ursprünglichen LLM übereinstimmt.
Weitere experimentelle ErgebnisseDie folgende Abbildung zeigt die Beschleunigungswirkung von EAGLE auf Vicuna 33B bei verschiedenen Aufgaben. „Coding“-Aufgaben mit einer großen Anzahl fester Vorlagen zeigen die beste Beschleunigungsleistung.
Begrüßen Sie alle, EAGLE zu erleben und Feedback und Vorschläge über die GitHub-Ausgabe zu geben: https://github.com/SafeAILab/EAGLE/issuesDas obige ist der detaillierte Inhalt vonDie Inferenzeffizienz großer Modelle wurde ohne Verlust um das Dreifache verbessert. Die University of Waterloo, die Peking University und andere Institutionen haben EAGLE veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn