
Heim >Technologie-Peripheriegeräte >KI >ICML 2024 |. Gradient Checkpointing zu langsam? Ohne den Videospeicher zu verlangsamen und zu sparen, verbessert LowMemoryBP die Effizienz des Backpropagation-Videospeichers erheblich
ICML 2024 |. Gradient Checkpointing zu langsam? Ohne den Videospeicher zu verlangsamen und zu sparen, verbessert LowMemoryBP die Effizienz des Backpropagation-Videospeichers erheblich

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-07-18 01:39:51767Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Der Erstautor dieses Artikels ist Yang Yuchen, ein Masterstudent im zweiten Jahr an der School of Statistics and Data Science der Nankai University, und sein Berater ist außerordentlicher Professor Xu Jun an der Fakultät für Statistik und Datenwissenschaft der Nankai-Universität. Der Forschungsschwerpunkt des Teams von Professor
Da große Transformer-Modelle in verschiedenen Bereichen nach und nach zu einer einheitlichen Architektur geworden sind, ist die Feinabstimmung zu einem wichtigen Mittel geworden, um vorab trainierte große Modelle auf nachgelagerte Aufgaben anzuwenden. Da jedoch die Größe des Modells von Tag zu Tag zunimmt, nimmt auch der für die Feinabstimmung erforderliche Videospeicher allmählich zu. Die effiziente Reduzierung des Feinabstimmungs-Videospeichers ist zu einem wichtigen Thema geworden. Bisher bestand der übliche Ansatz bei der Feinabstimmung des Transformer-Modells zur Einsparung von Grafikspeicher-Overhead darin, Gradienten-Checkpointing (auch Aktivierungsneuberechnung genannt) zu verwenden, um die für den Backpropagation-Prozess (BP) erforderliche Zeit auf Kosten der Trainingsgeschwindigkeit zu reduzieren . Aktivieren Sie die Videospeichernutzung.
Kürzlich wurde in dem auf der ICML 2024 vom Team von Lehrer BP)-Prozess, ohne den Rechenaufwand zu erhöhen, wird die Spitzenauslastung des Aktivierungsspeichers erheblich reduziert.

Papier: Reduzierung des Feinabstimmungs-Speicheraufwands durch Approximate und Memory-Sharing Backpropagation
Papierlink: https://arxiv.org/abs/2406.16282
Projektlink: https:/ / /github.com/yyyyychen/LowMemoryBP
Der Artikel schlägt zwei Strategien zur Verbesserung der Backpropagation vor, nämlich Approximate Backpropagation (Approx-BP) und Memory-Sharing Backpropagation (MS-BP). Approx-BP und MS-BP stellen jeweils zwei Lösungen zur Verbesserung der Speichereffizienz bei der Backpropagation dar, die zusammen als LowMemoryBP bezeichnet werden können. Ob im theoretischen oder praktischen Sinne, der Artikel bietet bahnbrechende Anleitungen für ein effizienteres Backpropagation-Training.
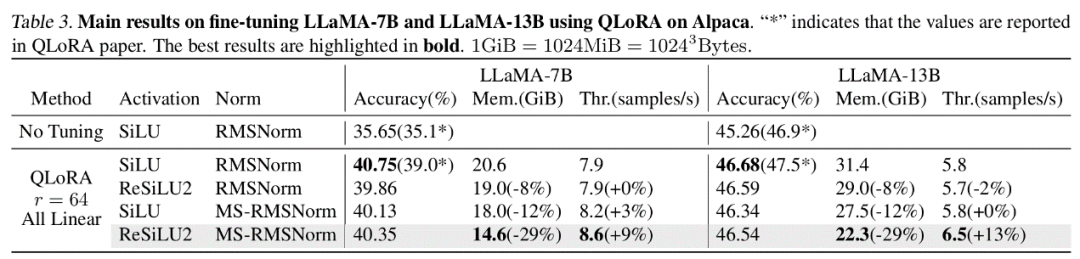
In der theoretischen Speicheranalyse kann LowMemoryBP die Aktivierungsspeichernutzung durch Aktivierungsfunktionen und Normalisierungsschichten erheblich reduzieren. Am Beispiel von ViT und LLaMA kann die Feinabstimmung von ViT den Aktivierungsspeicher um 39,47 % reduzieren, und die Feinabstimmung von LLaMA kann die Aktivierung um reduzieren 29,19 % Videospeicher.
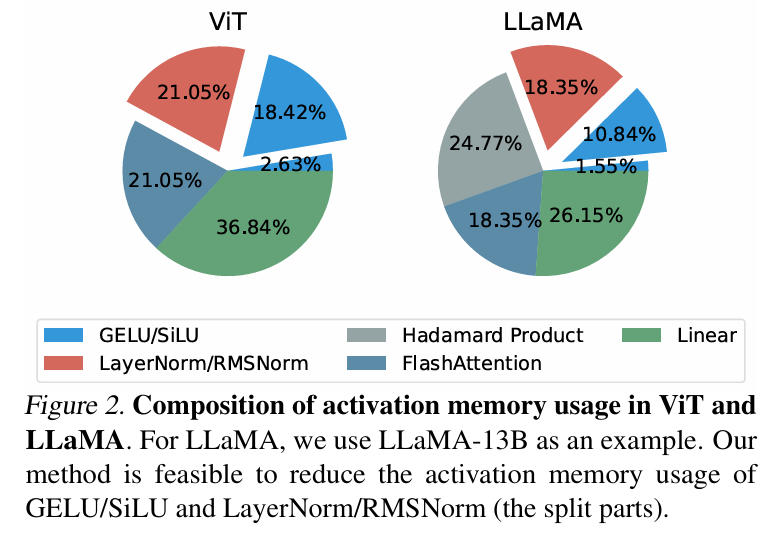
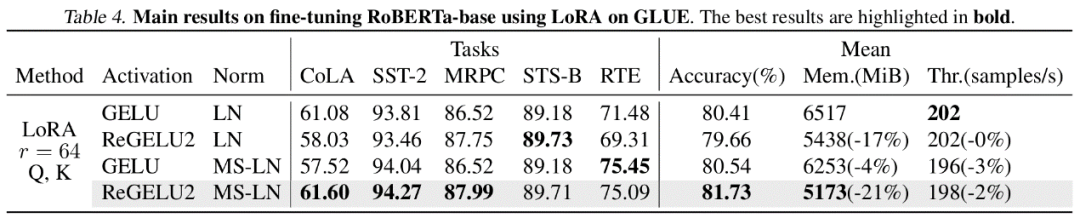
In tatsächlichen Experimenten kann LowMemoryBP die Spitzenspeichernutzung der Feinabstimmung des Transformer-Modells, einschließlich ViT, LLaMA, RoBERTa, BERT und Swin, effektiv um 20 % bis 30 % reduzieren und erhöht nicht den Trainingsdurchsatz und -verlust der Testgenauigkeit.
Approx-BP
Beim herkömmlichen Backpropagation-Training entspricht die Backpropagation des Gradienten der Aktivierungsfunktion genau ihrer Ableitungsfunktion. Für die im Transformer-Modell üblicherweise verwendeten GELU- und SiLU-Funktionen bedeutet dies, dass die Eingabe erforderlich ist Der Feature-Tensor wird vollständig im aktiven Videospeicher gespeichert. Der Autor dieses Artikels schlug eine Reihe von Backpropagation-Approximationstheorien vor, nämlich die Approx-BP-Theorie. Basierend auf dieser Theorie verwendet der Autor eine stückweise lineare Funktion, um die Aktivierungsfunktion anzunähern, und ersetzt die Rückausbreitung des GELU/SiLU-Gradienten durch die Ableitung der stückweisen linearen Funktion (Schrittfunktion). Dieser Ansatz führt zu zwei asymmetrischen speichereffizienten Aktivierungsfunktionen: ReGELU2 und ReSiLU2. Diese Art von Aktivierungsfunktion verwendet eine 4-stufige Schrittfunktion für die Rücksendung, sodass der Aktivierungsspeicher nur einen 2-Bit-Datentyp verwenden muss.
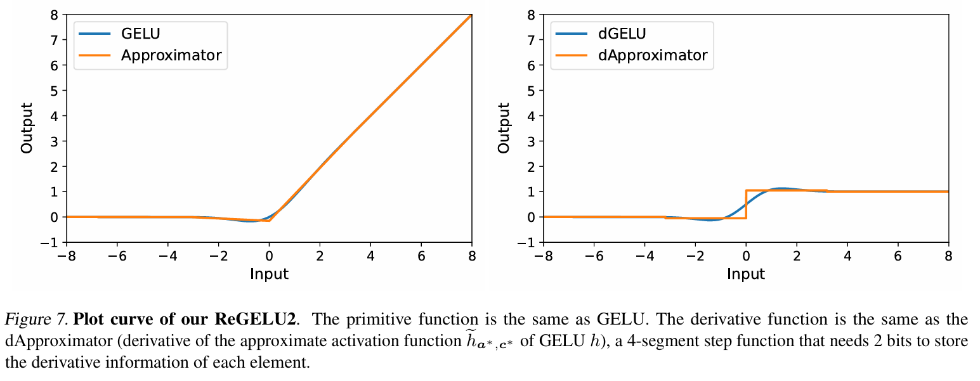
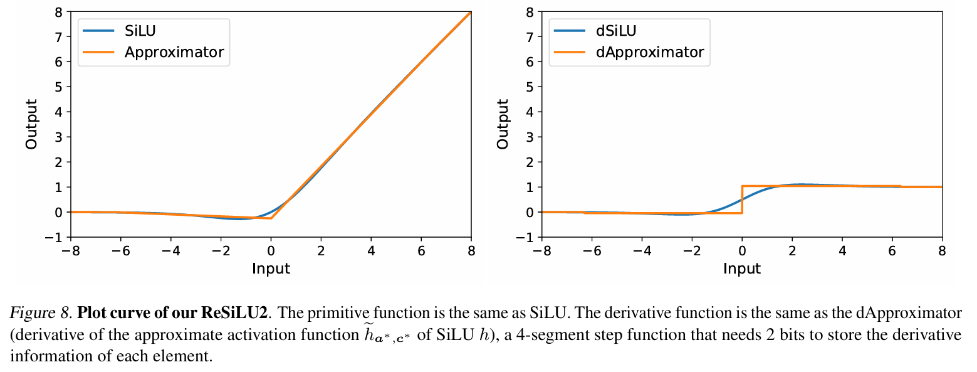
MS-BP
BP Jede Schicht des Netzwerks speichert normalerweise den Eingabetensor im Aktivierungsspeicher für die Backpropagation-Berechnung. Der Autor weist darauf hin, dass, wenn die Backpropagation einer bestimmten Schicht in eine ausgabeabhängige Form umgeschrieben werden kann, diese Schicht und die nachfolgende Schicht denselben Aktivierungstensor teilen können, wodurch die Redundanz des Aktivierungsspeichers verringert wird.
Der Artikel weist darauf hin, dass LayerNorm und RMSNorm, die üblicherweise in Transformer-Modellen verwendet werden, die Anforderungen der MS-BP-Strategie gut erfüllen können, nachdem affine Parameter in der linearen Schicht der letzteren Schicht zusammengeführt wurden. Die neu gestalteten MS-LayerNorm und MS-RMSNorm generieren keinen unabhängigen aktiven Grafikspeicher mehr.

Experimentelle Ergebnisse
Der Autor führte Feinabstimmungsexperimente an mehreren repräsentativen Modellen in den Bereichen Computer Vision und Verarbeitung natürlicher Sprache durch. Unter anderem reduzierte die im Artikel vorgeschlagene Methode in den Feinabstimmungsexperimenten von ViT, LLaMA und RoBERTa die Spitzenspeichernutzung um 27 %, 29 % bzw. 21 %, ohne dass es zu einem Verlust des Trainingseffekts und der Trainingsgeschwindigkeit kam. Beachten Sie, dass der Vergleich Mesa (eine 8-Bit-Aktivierungskomprimierungs-Trainingsmethode) die Trainingsgeschwindigkeit um etwa 20 % reduziert, während die im Artikel vorgeschlagene LowMemoryBP-Methode die Trainingsgeschwindigkeit vollständig beibehält.
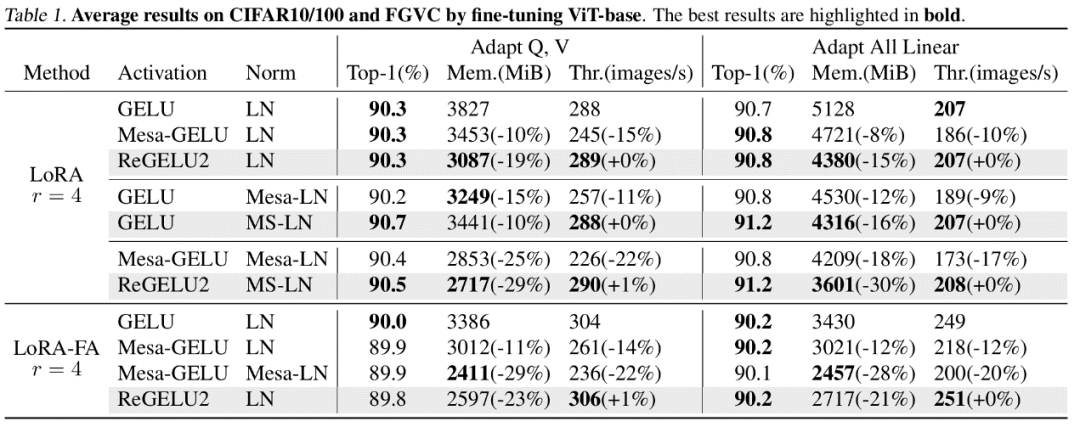
Schlussfolgerung und Bedeutung
Die beiden im Artikel vorgeschlagenen Strategien zur Verbesserung des Blutdrucks, Approx-BP und MS-BP, erreichen beide die Aktivierung des Videogedächtnisses bei gleichzeitiger Aufrechterhaltung des Trainingseffekts und des Trainings Geschwindigkeit. Erhebliche Einsparungen. Dies bedeutet, dass die Optimierung nach dem BP-Prinzip eine vielversprechende Lösung zur Speichereinsparung ist. Darüber hinaus durchbricht die im Artikel vorgeschlagene Approx-BP-Theorie den Optimierungsrahmen traditioneller neuronaler Netze und bietet theoretische Machbarkeit für die Verwendung ungepaarter Ableitungen. Die abgeleiteten Modelle ReGELU2 und ReSiLU2 zeigen den wichtigen praktischen Wert dieses Ansatzes.
Sie können gerne das Papier oder den Code lesen, um die Details des Algorithmus zu verstehen. Die relevanten Module wurden im Github-Repository des LowMemoryBP-Projekts offengelegt.
Das obige ist der detaillierte Inhalt vonICML 2024 |. Gradient Checkpointing zu langsam? Ohne den Videospeicher zu verlangsamen und zu sparen, verbessert LowMemoryBP die Effizienz des Backpropagation-Videospeichers erheblich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr