
Heim >Technologie-Peripheriegeräte >KI >Das erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source
Das erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-07-17 02:46:301215Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.

untersucht das Vorhandene multimodilica große Sprachmodelle (MLLMs) basieren häufig auf Transformer-Netzwerken, die eine quadratische Rechenkomplexität aufweisen. Um dieser Ineffizienz entgegenzuwirken, stellt dieser Artikel Cobra vor, ein neuartiges MLLM mit linearer Rechenkomplexität. Taucht in verschiedene modale Fusionsschemata ein, um die Integration visueller und sprachlicher Informationen im Mamba-Sprachmodell zu optimieren. Durch Experimente untersucht dieser Artikel die Wirksamkeit verschiedener Fusionsstrategien und bestimmt die Methode, die die effektivste multimodale Darstellung erzeugt. Es wurden umfangreiche Experimente durchgeführt, um die Leistung von Cobra mit parallelen Studien zu bewerten, die darauf abzielten, die Recheneffizienz des zugrunde liegenden MLLM zu verbessern. Bemerkenswert ist, dass Cobra auch mit weniger Parametern eine vergleichbare Leistung wie LLaVA erreicht, was seine Effizienz unterstreicht.

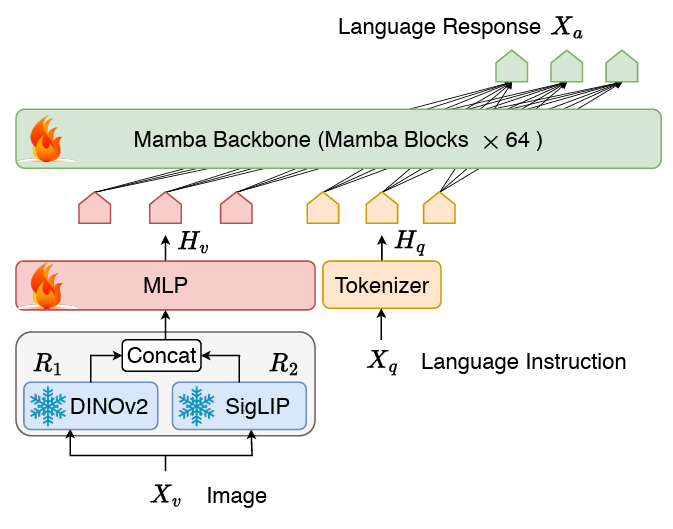
Originallink: https://arxiv.org/pdf/2403.14520v2.pdf Projektlink: https://sites.google.com/view/cobravlm/ Papiertitel: Cobra: Erweiterung von Mamba auf ein multimodales großes Sprachmodell für effiziente Inferenz LM-Struktur besteht aus einem Stateful-Projektor und dem LLM-Sprach-Backbone. Der Backbone-Teil von LLM verwendet das vorab trainierte Mamba-Sprachmodell mit 2,8B Parametern, das auf dem SlimPajama-Datensatz mit 600B-Tokens vorab trainiert und mit den Anweisungen der Konversationsdaten feinabgestimmt wurde.网络 Cobra-Netzwerkstrukturdiagramm
Neueste Untersuchungen zeigen, dass für bestehende Trainingsparadigmen, die auf LLaVA basieren (d. h. nur einmal die Vorausrichtungsphase der Projektionsschicht und die Feinabstimmungsphase des LLM-Backbones trainiert werden). In jedem Fall sind Vorausrichtungsschritte möglicherweise unnötig und das fein abgestimmte Modell ist möglicherweise immer noch unzureichend angepasst. Daher verzichtet Cobra auf die Vorausrichtungsphase und führt direkt eine Feinabstimmung des gesamten LLM-Sprach-Backbones und der Projektoren durch. Dieser Feinabstimmungsprozess wurde für zwei Epochen mit Zufallsstichproben an einem kombinierten Datensatz durchgeführt, bestehend aus:
Quantitatives Experiment - Im experimentellen Teil vergleicht dieses Papier das vorgeschlagene Cobra-Modell und das Open-Source-SOTA-VLM-Modell anhand des Basis-Benchmarks und vergleicht es mit Das gleiche Die Größe basiert auf der Antwortgeschwindigkeit des VLM-Modells basierend auf der Transformer-Architektur. Gleichzeitig mit der Generierungsgeschwindigkeit und dem Leistungsvergleich des Diagramms bietet COBRA auch die vier offenen VQA-Aufgaben VQA-V2, GQA, Vizwiz, TextVQA und VSR sowie POPE zwei für eine geschlossene Satzvorhersageaufgabe Die Ergebnisse wurden bei insgesamt 6 Benchmarks verglichen. Der Vergleich der Karte auf dem Benchmark und anderen Open-Source-Modellen
Ablationsexperiment
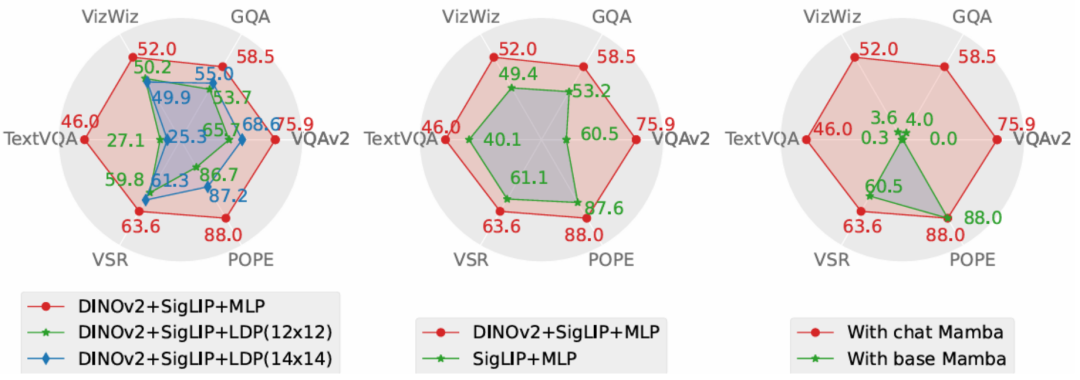
Dieses Papier schlägt Cobra vor, das den Effizienzengpass bestehender multimodaler Sprachmodelle im großen Maßstab löst, die auf Transformer-Netzwerken mit quadratischer Rechenkomplexität basieren. In diesem Artikel wird die Kombination von Sprachmodellen mit linearer Rechenkomplexität und multimodaler Eingabe untersucht. Im Hinblick auf die Verschmelzung visueller und sprachlicher Informationen optimiert dieser Artikel erfolgreich die interne Informationsintegration des Mamba-Sprachmodells und erreicht durch eingehende Forschung zu verschiedenen Modalfusionsschemata eine effektivere multimodale Darstellung. Experimente zeigen, dass Cobra nicht nur die Recheneffizienz erheblich verbessert, sondern auch in der Leistung mit fortgeschrittenen Modellen wie LLaVA vergleichbar ist, insbesondere bei der Überwindung visueller Illusionen und der Beurteilung räumlicher Beziehungen. Es reduziert sogar die Anzahl der Parameter erheblich. Dies eröffnet neue Möglichkeiten für den zukünftigen Einsatz leistungsstarker KI-Modelle in Umgebungen, die eine Hochfrequenzverarbeitung visueller Informationen erfordern, wie beispielsweise die visionsbasierte Roboter-Feedback-Steuerung. 
Das obige ist der detaillierte Inhalt vonDas erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr