
Heim >Technologie-Peripheriegeräte >KI >In wenigen Minuten vierdimensionale Inhalte generieren und Bewegungseffekte steuern: Die Peking-Universität und Michigan schlagen DG4D vor
In wenigen Minuten vierdimensionale Inhalte generieren und Bewegungseffekte steuern: Die Peking-Universität und Michigan schlagen DG4D vor

- 王林Original
- 2024-07-12 09:30:211151Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Der Autor dieses Artikels, Dr. Pan Liang, ist derzeit Forschungswissenschaftler am Shanghai Artificial Intelligence Laboratory. Zuvor war er von 2020 bis 2023 als Forschungsstipendiat am S-Lab der Nanyang Technological University in Singapur tätig und sein Berater war Professor Liu Ziwei. Seine Forschung konzentriert sich auf Computer Vision, 3D-Punktwolken und virtuelle Menschen und er hat mehrere Artikel auf führenden Konferenzen und Fachzeitschriften veröffentlicht, mit mehr als 2700 Google Scholar-Zitaten. Darüber hinaus war er als Gutachter für Top-Konferenzen und Fachzeitschriften in den Bereichen Computer Vision und maschinelles Lernen tätig.
Kürzlich haben das S-Lab des SenseTime-Nanyang Technological University Joint AI Research Center, das Shanghai Artificial Intelligence Laboratory, die Peking University und die University of Michigan gemeinsam DreamGaussian4D (DG4D) vorgeschlagen, das explizite Modellierung der räumlichen Transformation mit statischem 3D-Gauß-Splatting kombiniert ( Die GS-Technologie ermöglicht eine effiziente vierdimensionale Inhaltsgenerierung.
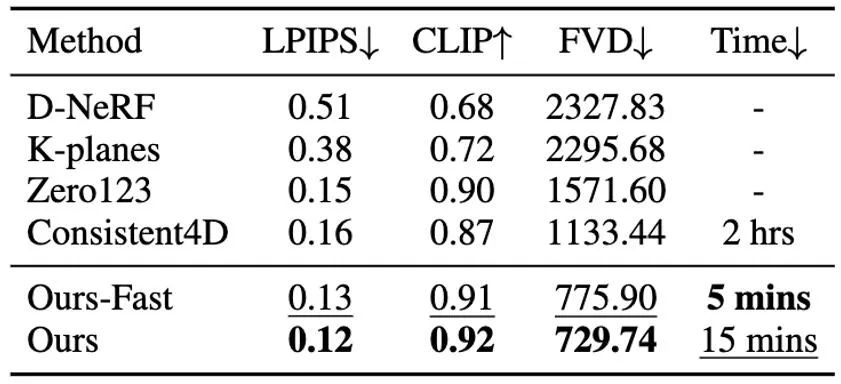
Die vierdimensionale Inhaltsgenerierung hat in letzter Zeit erhebliche Fortschritte gemacht, aber bestehende Methoden weisen Probleme wie lange Optimierungszeit, schlechte Bewegungssteuerungsfunktionen und geringe Detailqualität auf. DG4D schlägt ein Gesamtframework vor, das zwei Hauptmodule enthält: 1) Bild zu 4D-GS – wir verwenden zuerst DreamGaussianHD, um statisches 3D-GS zu generieren, und generieren dann eine dynamische Generierung basierend auf der Gaußschen Verformung basierend auf HexPlane; 2) Video-zu-Video-Texturverfeinerung – wir Die resultierende räumliche UV-Texturkarte wird verfeinert und ihre zeitliche Konsistenz wird durch die Verwendung eines vorab trainierten Bild-zu-Video-Diffusionsmodells verbessert.
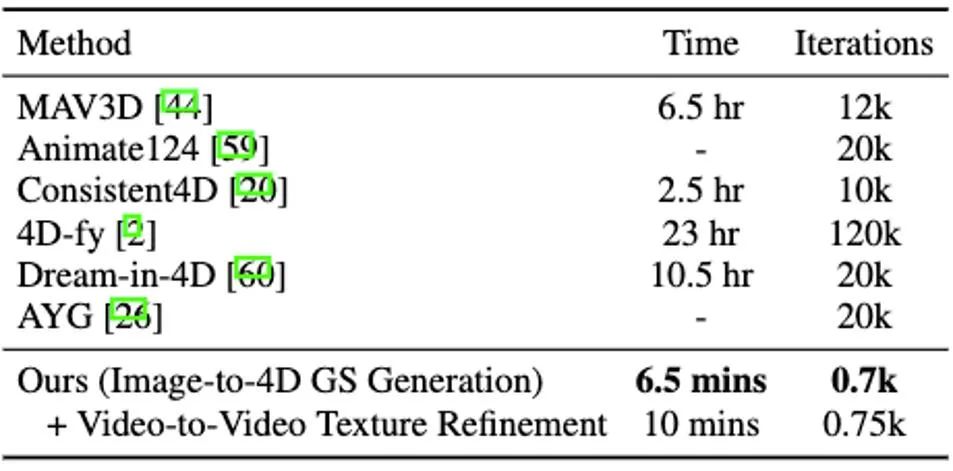
Es ist erwähnenswert, dass DG4D die Optimierungszeit der vierdimensionalen Inhaltsgenerierung von Stunden auf Minuten reduziert (wie in Abbildung 1 dargestellt), eine visuelle Kontrolle der erzeugten dreidimensionalen Bewegung ermöglicht und die Generierung von Bildern unterstützt, die möglich sind realistisch gerendert in einem dreidimensionalen animierten Netzmodell.

Papiername: DreamGaussian4D: Generative 4D Gaussian Splatting
Homepage-Adresse: https://jiawei-ren.github.io/projects/dreamgaussian4d/
Papieradresse: https:// arxiv.org/abs/2312.17142
Demo-Adresse: https://huggingface.co/spaces/jiawei011/dreamgaussian4d

Abbildung 1. DG4D kann vierdimensionale Inhalte in vier und a realisieren halbe Minuten Optimierung der grundlegenden Konvergenz
Probleme und Herausforderungen
Generative Modelle können die Produktion und Produktion verschiedener digitaler Inhalte wie 2D-Bilder, Videos und 3D-Szenen erheblich vereinfachen und haben in den letzten Jahren erhebliche Fortschritte gemacht. Vierdimensionaler Inhalt ist eine wichtige Inhaltsform für viele nachgelagerte Aufgaben wie Spiele, Filme und Fernsehen. Vierdimensional generierte Inhalte sollten auch den Import herkömmlicher Grafik-Rendering-Engine-Software (wie Blender oder Unreal Engine) unterstützen, um eine Verbindung zur vorhandenen Produktionspipeline für Grafikinhalte herzustellen (siehe Abbildung 2).
Obwohl es einige Studien gibt, die sich der dynamischen dreidimensionalen (d. h. vierdimensionalen) Generierung widmen, gibt es immer noch Herausforderungen bei der effizienten und qualitativ hochwertigen Generierung vierdimensionaler Szenen. In den letzten Jahren wurden immer mehr Forschungsmethoden eingesetzt, um eine vierdimensionale Inhaltsgenerierung durch die Kombination von Video- und dreidimensionalen Generierungsmodellen zu erreichen, um die Konsistenz des Erscheinungsbilds und der Aktionen von Inhalten aus jedem Betrachtungswinkel einzuschränken.

NeRF) sagte. Beispielsweise erreicht MAV3D [1] die Generierung von Text in vierdimensionale Inhalte durch die Verfeinerung des Text-in-Video-Diffusionsmodells auf HexPlane [2]. Consistent4D [3] führt ein Video-zu-4D-Framework ein, um kaskadiertes DyNeRF zu optimieren, um 4D-Szenen aus statisch erfassten Videos zu generieren. Mit mehreren Diffusionsmodell-Prioritäten ist Animate124 [4] in der Lage, ein einzelnes unverarbeitetes 2D-Bild über eine textuelle Bewegungsbeschreibung in ein dynamisches 3D-Video zu animieren. Basierend auf der hybriden SDS-Technologie [5] ermöglicht 4D-fy [6] die Generierung ansprechender Text-zu-vierdimensionaler Inhalte mithilfe mehrerer vorab trainierter Diffusionsmodelle. Allerdings benötigen alle oben genannten existierenden Methoden [1,3,4,6] mehrere Stunden, um ein einziges 4D-NeRF zu generieren, was ihr Anwendungspotenzial stark einschränkt. Darüber hinaus haben sie alle Schwierigkeiten, die letztendlich erzeugte Bewegung effektiv zu steuern oder auszuwählen. Die oben genannten Mängel sind hauptsächlich auf die folgenden Faktoren zurückzuführen: Erstens ist die zugrunde liegende implizite vierdimensionale Darstellung der oben genannten Methode nicht effizient genug, und es gibt Probleme wie langsame Rendering-Geschwindigkeit und schlechte Bewegungsregelmäßigkeit, zweitens die zufällige Natur von Video-SDS erhöht die Schwierigkeit der Konvergenz und führt zu Instabilität und mehreren Artefakten im Endergebnis. Einführung in die Methode Im Gegensatz zu Methoden, die 4D NeRF direkt optimieren, erstellt DG4D eine effiziente und leistungsstarke Darstellung für die Generierung von 4D-Inhalten, indem es statische Gaußsche Splashing-Technologie und explizite räumliche Transformationsmodellierung kombiniert. Darüber hinaus haben Videogenerierungsmethoden das Potenzial, wertvolle räumlich-zeitliche Priorisierungen bereitzustellen, die die hochwertige 4D-Generierung verbessern. Konkret schlagen wir ein Gesamtgerüst vor, das aus zwei Hauptphasen besteht: 1) Bild-zu-4D-GS-Generierung; 2) Verfeinerung der Texturkarte auf Basis eines großen Videomodells. D1. Die Generierung des Bildes zum 4D-GS
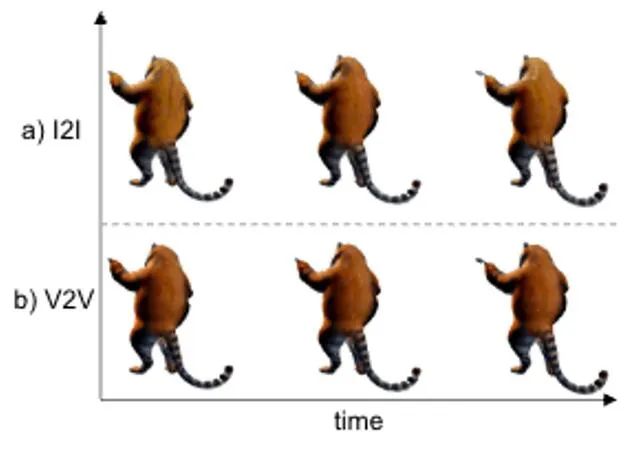
In dieser Phase verwenden wir statisches 3D-GS und seine räumliche Verformung, um die dynamische Dynamik anzuzeigen. dimensionale Szene. Basierend auf einem gegebenen 2D-Bild generieren wir statische 3D-GS mit der erweiterten DreamGaussianHD-Methode. Anschließend wird durch Optimierung des zeitabhängigen Deformationsfelds der statischen 3D-GS-Funktion die Gaußsche Deformation bei jedem Zeitstempel geschätzt, um die Form und Textur jedes deformierten Frames mit dem entsprechenden Frame im Fahrvideo in Einklang zu bringen. Am Ende dieser Phase wird eine dynamische dreidimensionale Netzmodellsequenz generiert. Basierend auf der jüngsten grafischen 3D -Objekt -Objektmethode Dreamgaussian [7] unter Verwendung von 3D GS haben wir einige weitere Verbesserungen vorgenommen und eine Reihe besserer 3D -GS -Erzeugungs- und Initialisierungsmethoden zusammengestellt. Zu den wichtigsten verbesserten Vorgängen gehören 1) die Anwendung einer Multi-View-Optimierungsmethode; 2) das Festlegen des Hintergrunds des gerenderten Bildes während des Optimierungsprozesses auf einen schwarzen Hintergrund, der für die Generierung besser geeignet ist. Wir nennen die verbesserte Version DreamGaussianHD, und die spezifischen Verbesserungsrenderings sind in Abbildung 4 zu sehen. Abbildung 5 HexPlane stellt das dynamische Verformungsfeld dar. Basierend auf dem generierten statischen 3D-GS-Modell generieren wir Videos, die den Erwartungen entsprechen, indem wir die Verformung des Gaußschen Kernels in jedem Frame vorhersagen. Dynamisches 4D-GS-Modell. Im Hinblick auf die Charakterisierung dynamischer Effekte wählen wir HexPlane (siehe Abbildung 5), um die Verschiebung, Rotation und Skalierung des Gaußschen Kernels bei jedem Zeitstempel vorherzusagen und so die Generierung eines dynamischen Modells für jeden Frame voranzutreiben. Darüber hinaus haben wir das Designnetzwerk gezielt angepasst, insbesondere das Restverbindungs- und Nullinitialisierungsdesign für die letzten Netzwerkschichten mit linearem Betrieb, sodass das dynamische Feld basierend auf dem statischen 3D-GS-Modell reibungslos und vollständig initialisiert werden kann ( Der Effekt ist wie in der Abbildung dargestellt) in 6) dargestellt.始 Abbildung 6: Der Einfluss der Initialisierung der dynamischen Formation auf die endgültige Erzeugung des dynamischen Feldes Ähnlich wie bei DreamGaussian kann nach der ersten Stufe der vierdimensionalen dynamischen Modellgenerierung basierend auf 4D GS die vierdimensionale Netzmodellsequenz extrahiert werden. Darüber hinaus können wir die Textur im UV-Raum des Netzmodells weiter optimieren, ähnlich wie es DreamGaussian tut. Im Gegensatz zu DreamGaussian, das nur Bilderzeugungsmodelle verwendet, um Texturen für einzelne 3D-Netzmodelle zu optimieren, müssen wir die gesamte 3D-Netzsequenz optimieren. Darüber hinaus haben wir festgestellt, dass, wenn wir dem Ansatz von DreamGaussian folgen, also eine unabhängige Texturoptimierung für jede 3D-Netzsequenz durchführen, die Textur des 3D-Netzes zu unterschiedlichen Zeitstempeln inkonsistent generiert wird und es häufig zu Flackern usw. kommt . Es treten Fehlerartefakte auf. Aus diesem Grund unterscheiden wir uns von DreamGaussian und schlagen eine Methode zur Optimierung der Video-zu-Video-Textur im UV-Raum vor, die auf einem großen Videogenerierungsmodell basiert. Insbesondere haben wir während des Optimierungsprozesses zufällig eine Reihe von Kameratrajektorien generiert, darauf basierend mehrere Videos gerendert und eine entsprechende Rauschaddition und Rauschunterdrückung an den gerenderten Videos durchgeführt, um die Generierung von Netzmodellsequenzen zu erreichen. Der Vergleich der Texturoptimierungseffekte der Generierung eines großen Modells basierend auf Bildern und der Generierung eines großen Modells basierend auf Videos ist in Abbildung 8 dargestellt. Im Vergleich zur vorherigen Methode zur Gesamtoptimierung von 4D NeRF wird DG4D erheblich reduziert. Die zum Generieren vierdimensionaler Inhalte erforderliche Zeit wird reduziert. Der konkrete Zeitvergleich ist in Tabelle 1 ersichtlich.
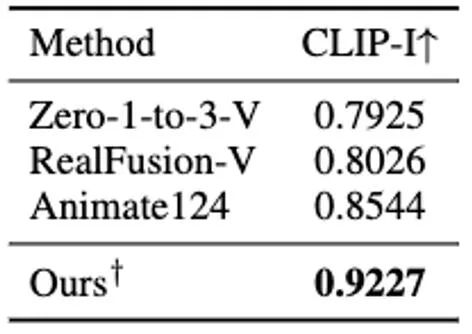
& Darüber hinaus haben wir auch einen Benutzertest zu den Generierungsergebnissen verschiedener Methoden durchgeführt, die am besten zu unseren passen Methode Probenahme Test, die Testergebnisse sind in Tabelle 4 aufgeführt.生 Tabelle 4 Benutzertest basierend auf dem vierdimensionalen Inhalt, der durch ein einzelnes Bild generiert wird Darüber hinaus haben wir auch statische 3D-Inhalte basierend auf der aktuellen direkten Feedforward-Methode zur Generierung von 3D-GS aus einem einzelnen Bild generiert (d. h. ohne Verwendung der SDS-Optimierungsmethode) und die Generierung dynamischer 4D-GS auf dieser Grundlage initialisiert. Durch die direkte Feedforward-Generierung von 3D-GS können qualitativ hochwertigere und vielfältigere 3D-Inhalte schneller erzeugt werden als auf SDS-Optimierung basierende Methoden. Der daraus resultierende vierdimensionale Inhalt ist in Abbildung 11 dargestellt.生 Abbildung 11 Der vierdimensionale dynamische Inhalt, der basierend auf der Methode zur Generierung von 3D-GS generiert wurde Fazit
Basierend auf 4D GS schlagen wir DreamGaussian4D (DG4D) vor, ein effizientes Framework zur Bild-zu-4D-Generierung. Im Vergleich zu bestehenden vierdimensionalen Content-Generierungs-Frameworks reduziert DG4D die Optimierungszeit erheblich von Stunden auf Minuten. Darüber hinaus demonstrieren wir die Verwendung generierter Videos zur angetriebenen Bewegungsgenerierung, wodurch eine visuell kontrollierbare 3D-Bewegungsgenerierung erreicht wird.
Referenzen [1] Tagungsband der 40. Internationalen Konferenz über maschinelles Lernen. 2] Cao et al. „Hexplane: Eine schnelle Darstellung für dynamische Szenen.“ [3] Jiang et al 360° dynamische Objektgenerierung aus monokularem Video.“ Die zwölfte internationale Konferenz zum Thema Lernen von Repräsentationen. 2023 (2023). [5] „DreamFusion: Text-to-3D using 2D Diffusion.“ Die elfte internationale Konferenz über Lerndarstellungen , Sherwin, et al. „4d-fy: Text-to-4d-Generierung mit Hybrid-Score-Destillation“ arXiv:2311.17984 (2023). [7] Tang et al Gaußsches Splatting für die effiziente Erstellung von 3D-Inhalten.“ Die zwölfte internationale Konferenz zum Thema Lernen von Repräsentationen. 2023.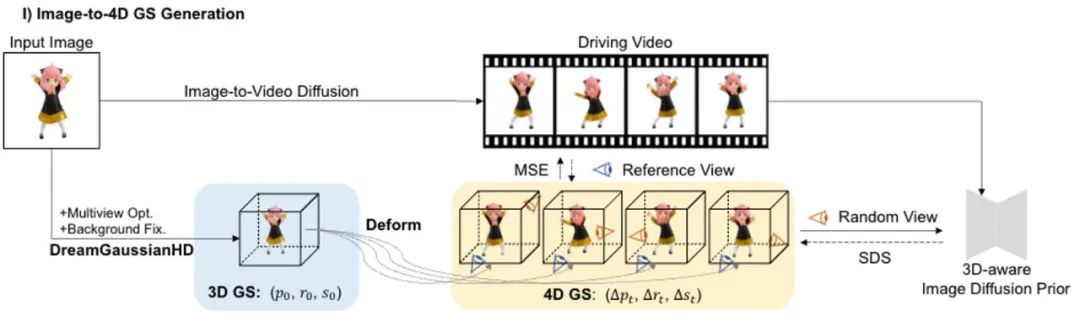


Das obige ist der detaillierte Inhalt vonIn wenigen Minuten vierdimensionale Inhalte generieren und Bewegungseffekte steuern: Die Peking-Universität und Michigan schlagen DG4D vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr