
Heim >Technologie-Peripheriegeräte >KI >ACL 2024 |. Shanghai Jiao Tong University, Tsinghua University, Cambridge University und Shanghai AILAB haben gemeinsam den akademischen audiovisuellen Datensatz M3AV veröffentlicht
ACL 2024 |. Shanghai Jiao Tong University, Tsinghua University, Cambridge University und Shanghai AILAB haben gemeinsam den akademischen audiovisuellen Datensatz M3AV veröffentlicht

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-07-12 04:11:471222Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse der Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

Papierlink: https://arxiv.org/abs/2403.14168 Projekthomepage: https://jack-zc8.github.io/M3AV-dataset-page/ -
Papiertitel: M3AV: Ein multimodaler, multigenre- und vielseitiger audiovisueller akademischer Vorlesungsdatensatz Online-Methoden. Diese Videos enthalten umfangreiche multimodale Informationen, darunter die Stimme, Mimik und Körperbewegungen des Sprechers, den Text und die Bilder in den Folien sowie die entsprechenden Papiertextinformationen. Derzeit gibt es „sehr wenige Datensätze, die gleichzeitig multimodale Aufgaben zur Inhaltserkennung und zum Verstehen unterstützen können“, was teilweise auf das Fehlen hochwertiger menschlicher Annotation zurückzuführen ist.
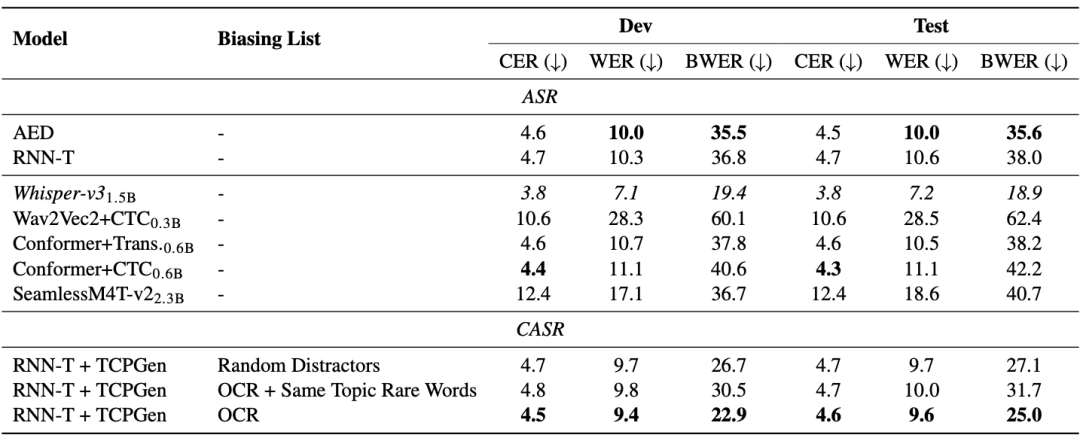
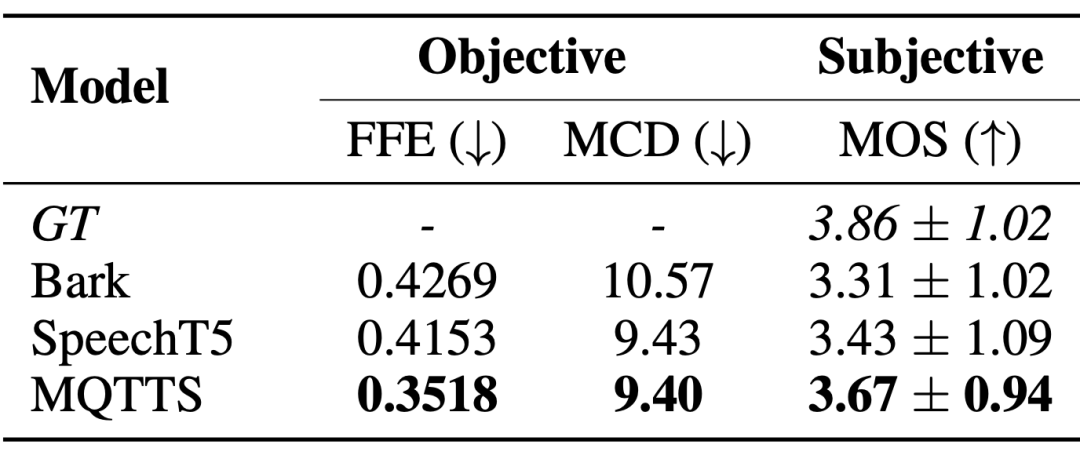
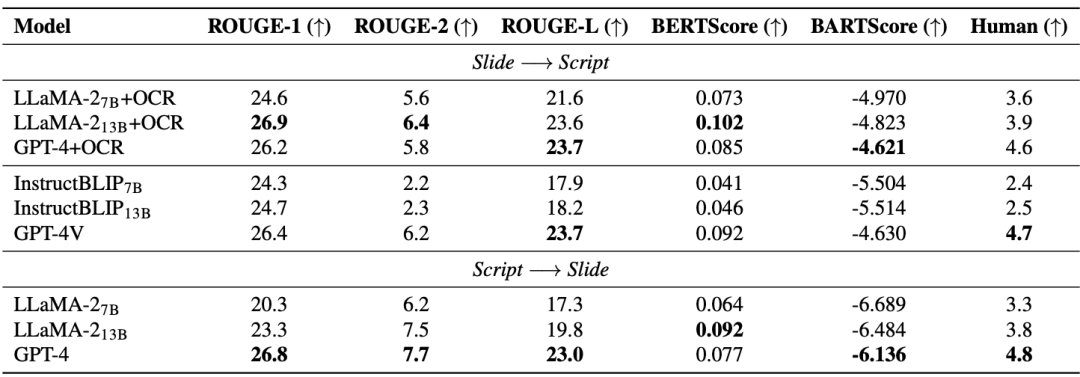
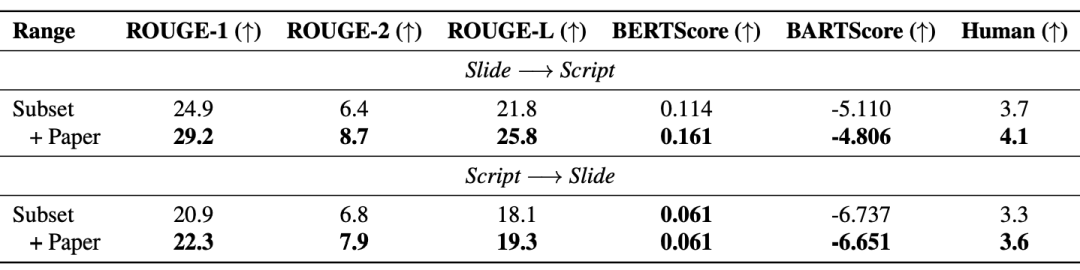
Diese Arbeit schlägt einen neuen multimodalen, vielfältigen und vielseitig einsetzbaren audiovisuellen akademischen Sprachdatensatz (M3AV) vor, der fast 367 Stunden Videos aus fünf Quellen aus den Bereichen Informatik, Mathematik, Medizin und Medizin enthält Biologische Themen. Mit hochwertigen menschlichen Anmerkungen, insbesondere hochwertigen benannten Entitäten, kann der Datensatz für eine Vielzahl audiovisueller Erkennungs- und Verständnisaufgaben verwendet werden. Auswertungen zu kontextueller Spracherkennung, Sprachsynthese sowie Folien- und Skripterstellungsaufgaben zeigen, dass die Vielfalt von M3AV es zu einem herausfordernden Datensatz macht. Diese Arbeit wurde von der ACL 2024-Hauptkonferenz angenommen.
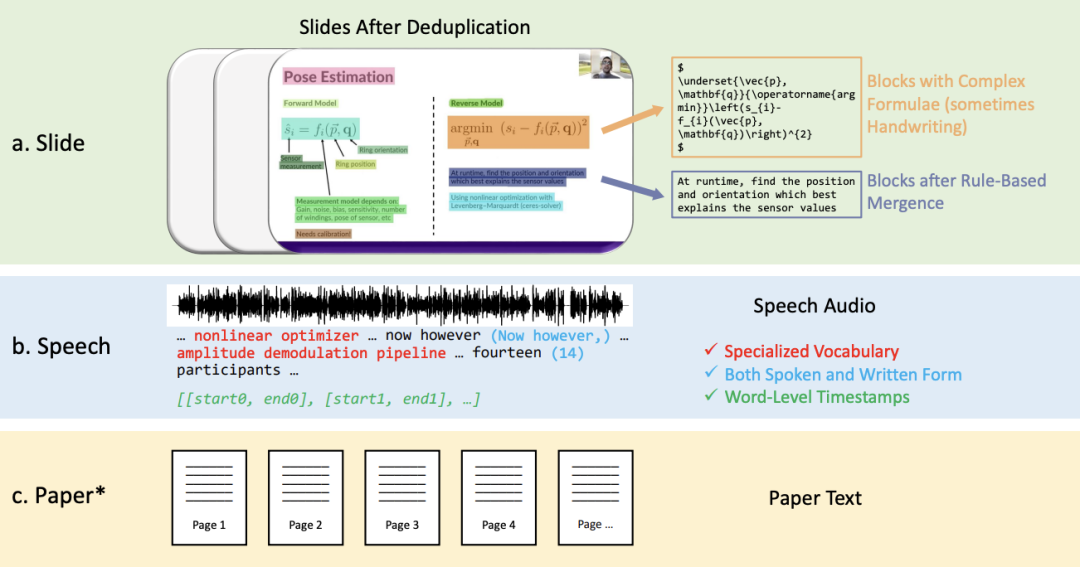
2. Sprachtranskribierter Text in gesprochener und geschriebener Form, einschließlich speziellem Vokabular und Zeitstempel auf Wortebene.
die meisten manuell kommentierten Folien, Sprach- und Papierressourcen, sodass er nicht nur multimodale Inhaltserkennungsaufgaben
 Partielle Anmerkungsschnittstelle
Partielle Anmerkungsschnittstelle
Das obige ist der detaillierte Inhalt vonACL 2024 |. Shanghai Jiao Tong University, Tsinghua University, Cambridge University und Shanghai AILAB haben gemeinsam den akademischen audiovisuellen Datensatz M3AV veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr