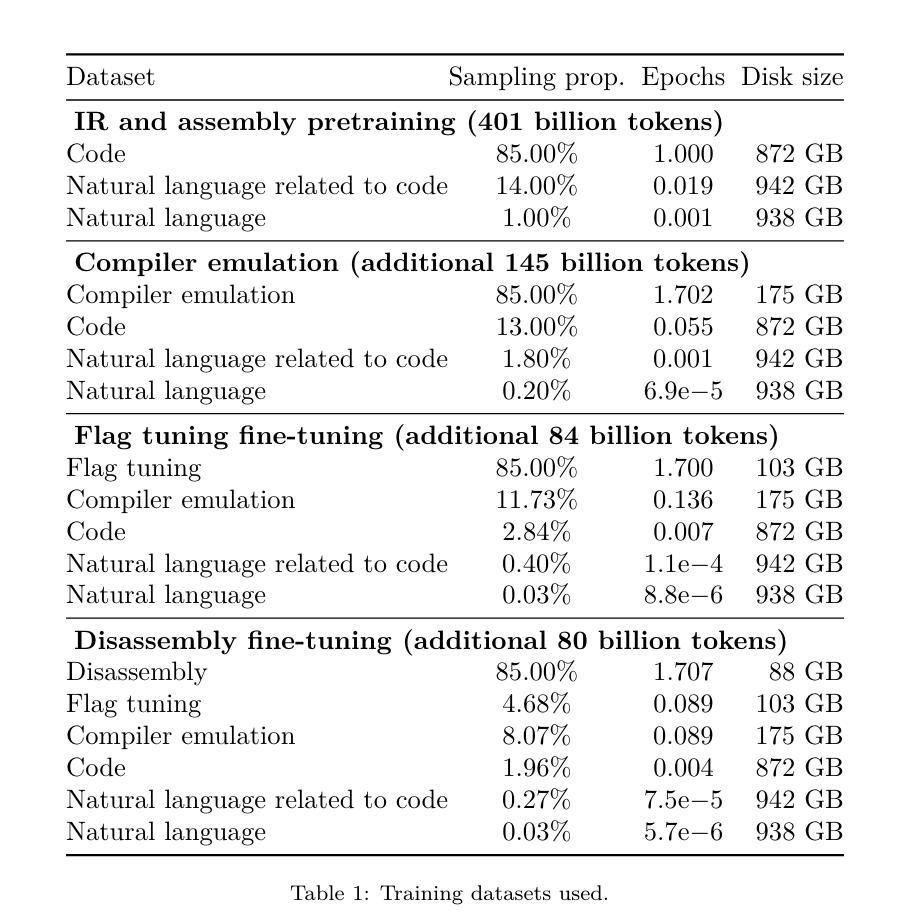
Meta hat einen fantastischen LLM-Compiler entwickelt, der Programmierern dabei hilft, Code effizienter zu schreiben.
Gestern haben sich die drei großen KI-Giganten OpenAI, Google und Meta zusammengetan, um die neuesten Forschungsergebnisse ihrer eigenen großen Modelle zu veröffentlichen – OpenAI hat ein neues Modell CriticGPT auf Basis von GPT-4 auf den Markt gebracht Schulung, die sich auf die Suche nach Fehlern spezialisiert hat, Google Open Source 9B und 27B Versionen von Gemma2, und Meta hat den neuesten bahnbrechenden künstlichen Intelligenz-LLM-Compiler entwickelt. Dies ist ein leistungsstarker Satz von Open-Source-Modellen, die darauf ausgelegt sind, Code zu optimieren und das Compiler-Design zu revolutionieren. Diese Innovation hat das Potenzial, die Art und Weise, wie Entwickler an die Codeoptimierung herangehen, zu verändern und sie schneller, effizienter und kostengünstiger zu machen. Es wird berichtet, dass das Optimierungspotenzial des LLM-Compilers 77 % der automatischen Optimierungssuche erreicht. Dieses Ergebnis kann die Kompilierungszeit erheblich verkürzen und die Codeeffizienz verschiedener Anwendungen verbessern, und in Bezug auf die Demontage ist dies der Fall Reise Die Erfolgsquote der Demontage liegt bei 45 %. Einige Internetnutzer sagten, dass dies eine Art Game Changer für die Codeoptimierung und -zerlegung sei. Das sind unglaublich gute Neuigkeiten für Entwickler. Große Sprachmodelle haben bei vielen Softwareentwicklungs- und Programmieraufgaben hervorragende Fähigkeiten gezeigt, ihre Anwendung im Bereich Codeoptimierung und Compiler wurde jedoch noch nicht vollständig ausgeschöpft. Das Training dieser LLMs erfordert umfangreiche Rechenressourcen, einschließlich teurer GPU-Zeit und großer Datensätze, was viele Forschungen und Projekte oft unhaltbar macht. Um diese Lücke zu schließen, hat das Meta-Forschungsteam einen LLM-Compiler eingeführt, um Code gezielt zu optimieren und das Compiler-Design zu revolutionieren. Durch das Training des Modells auf einem riesigen Korpus von 546 Milliarden LLVM-IR-Tokens und Assembler-Code ermöglichten sie dem Modell, Compiler-Zwischendarstellungen, Assemblersprache und Optimierungstechniken zu verstehen. Link zum Papier: https://ai.meta.com/research/publications/meta-large-Language-Model-Compiler-Foundation-Models-of-Compiler-Optimization/ „LLM Compiler bietet ein verbessertes Verständnis von Compiler-Zwischendarstellungen (IRs), Assemblersprache und Optimierungstechniken“, erklärt ihr Artikel. Dieses verbesserte Verständnis ermöglicht es Modellen, Aufgaben auszuführen, die zuvor menschlichen Experten oder spezialisierten Tools vorbehalten waren. Der Trainingsprozess des LLM-Compilers ist in Abbildung 1 dargestellt. Der LLM-Compiler erzielt bedeutende Ergebnisse bei der Optimierung der Codegröße. In Tests erreichte das Optimierungspotenzial des Modells 77 % der automatischen Optimierungssuche, ein Ergebnis, das die Kompilierungszeit erheblich verkürzen und die Codeeffizienz für eine Vielzahl von Anwendungen verbessern kann. Das Modell lässt sich besser zerlegen. Der LLM-Compiler erreicht bei der Rückkonvertierung von x86_64- und ARM-Assemblercode in LLVM-IR eine Round-Trip-Disassembly-Erfolgsrate von 45 % (14 % davon sind exakte Übereinstimmungen). Diese Fähigkeit kann für Reverse-Engineering-Aufgaben und die Wartung von Legacy-Code von unschätzbarem Wert sein. Einer der Hauptmitwirkenden des Projekts, Chris Cummins, hob die potenziellen Auswirkungen dieser Technologie hervor: „Durch die Bereitstellung vorab trainierter Modelle in zwei Größen (700 Millionen und 1,3 Milliarden Parameter) und den Nachweis ihrer Wirksamkeit durch Fein- optimierte Versionen: „Der LLM-Compiler ebnet den Weg, das ungenutzte Potenzial von LLM im Bereich der Code- und Compiler-Optimierung zu erkunden“, sagte er LLMs bestehen in der Regel hauptsächlich aus höheren Quellsprachen wie Python, Assembler-Code macht in diesen Datensätzen einen vernachlässigbaren Anteil aus und Compiler-IR macht einen kleineren Anteil aus.Um ein LLM mit gutem Verständnis dieser Sprachen zu erstellen, initialisierte das Forschungsteam das LLM-Compiler-Modell mit den Gewichten von Code Llama und trainierte dann hauptsächlich 401 Milliarden Token auf einem Compiler-zentrierten Datensatz besteht aus Assembler-Code und Compiler-IR, wie in Tabelle 1 gezeigt. Der Datensatz-LLM-Compiler wird hauptsächlich auf der von LLVM (Version 17.0.6) generierten Compiler-Zwischendarstellung und dem Assembler-Code trainiert. Diese Daten werden aus demselben Datensatz abgeleitet, der zum Trainieren von Code Llama verwendet wird, was in Tabelle 2 angegeben ist Der Datensatz ist in dargestellt. Wie Code Llama erhalten wir auch kleine Trainingsbatches aus Datensätzen natürlicher Sprache.  Anweisungsfeinabstimmung für die CompilersimulationUm den Mechanismus der Codeoptimierung zu verstehen, führte das Forschungsteam eine Anweisungsfeinabstimmung am LLM-Compilermodell durch, um die Compileroptimierung zu simulieren, wie in Abbildung 2 dargestellt. Die Idee besteht darin, eine große Anzahl von Beispielen aus einer begrenzten Sammlung nicht optimierter Seed-Programme zu generieren, indem zufällig generierte Sequenzen von Compiler-Optimierungen auf diese Programme angewendet werden. Anschließend trainierten sie das Modell, um den durch die Optimierung generierten Code vorherzusagen, und trainierten das Modell außerdem, die Codegröße nach Anwendung der Optimierung vorherzusagen. Aufgabenvorgaben. Generieren Sie bei gegebenem nicht optimiertem LLVM-IR (Ausgabe vom Clang-Frontend), einer Liste von Optimierungsdurchgängen und einer Startcodegröße den resultierenden Code und die Codegröße nach Anwendung dieser Optimierungen. Es gibt zwei Arten dieser Aufgabe: Bei der ersten erwartet das Modell die Ausgabe einer Compiler-IR; bei der zweiten erwartet das Modell die Ausgabe von Assemblercode. Die Eingabe-IR, der Optimierungsprozess und die Codegröße sind für beide Typen gleich und der Hinweis bestimmt das erforderliche Ausgabeformat. Codegröße. Sie verwenden zwei Metriken, um die Codegröße zu messen: Anzahl der IR-Anweisungen und Binärgröße. Die Binärgröße wird als Summe der .TEXT- und .DATA-Segmentgrößen nach dem Downgrade der IR oder Assembly auf eine Objektdatei berechnet. Wir schließen das .BSS-Segment aus, da es keinen Einfluss auf die Größe der Festplatte hat. Pass optimieren. In dieser Arbeit zielt das Forschungsteam auf LLVM 17.0.6 ab und verwendet den neuen Prozessmanager (PM, 2021), der Durchläufe in verschiedene Ebenen wie Module, Funktionen, Schleifen usw. klassifiziert sowie Durchläufe konvertiert und analysiert . Ein Transformationsdurchlauf ändert eine bestimmte Eingabe-IR, während ein Analysedurchlauf Informationen generiert, die sich auf nachfolgende Transformationen auswirken. Von 346 möglichen Passparametern für opt wählten sie 167 zur Verwendung aus. Dies umfasst jede Standardoptimierungspipeline (z. B. Modul (default)), einzelne Optimierungstransformationsdurchgänge (z. B. Modul (constmerge)), schließt jedoch nicht optimierende Dienstprogrammdurchgänge (z. B. Modul (dot-callgraph)) aus und behält keinen semantischen Konvertierungsdurchlauf bei (z. B. module (internalize)). Sie schließen Analysedurchläufe aus, da sie keine Nebenwirkungen haben und wir uns darauf verlassen, dass der Durchlaufmanager bei Bedarf abhängige Analysedurchläufe einfügt. Für Durchgänge, die Parameter akzeptieren, verwenden wir Standardwerte (z. B. Modul (licm)). Tabelle 9 enthält eine Liste aller verwendeten Durchgänge. Wir verwenden das opt-Tool von LLVM, um die Pass-Liste anzuwenden, und clang, um die resultierende IR in eine Objektdatei herunterzustufen. Listing 1 zeigt die verwendeten Befehle.
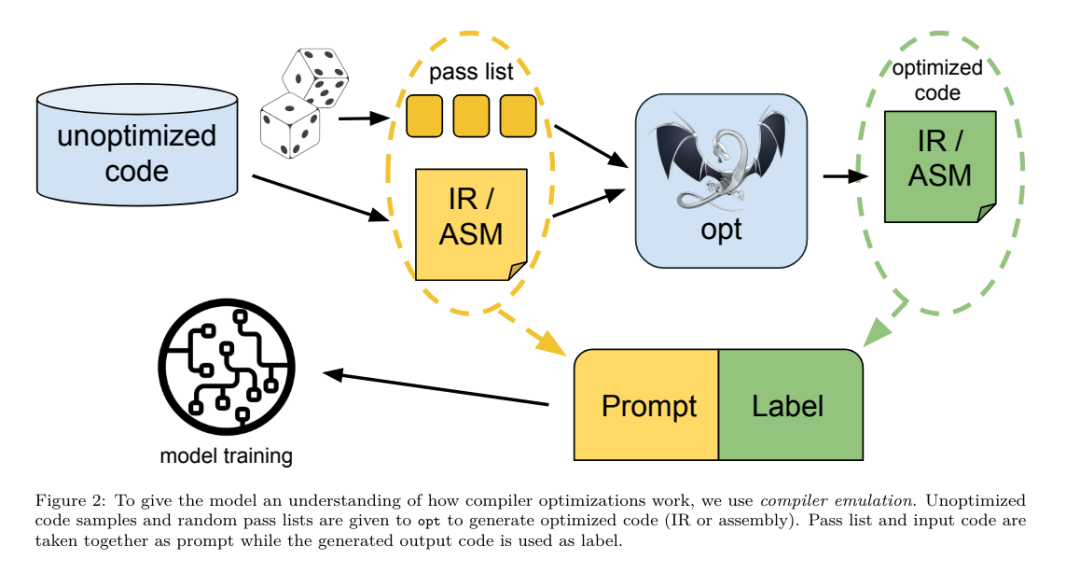
Anweisungsfeinabstimmung für die CompilersimulationUm den Mechanismus der Codeoptimierung zu verstehen, führte das Forschungsteam eine Anweisungsfeinabstimmung am LLM-Compilermodell durch, um die Compileroptimierung zu simulieren, wie in Abbildung 2 dargestellt. Die Idee besteht darin, eine große Anzahl von Beispielen aus einer begrenzten Sammlung nicht optimierter Seed-Programme zu generieren, indem zufällig generierte Sequenzen von Compiler-Optimierungen auf diese Programme angewendet werden. Anschließend trainierten sie das Modell, um den durch die Optimierung generierten Code vorherzusagen, und trainierten das Modell außerdem, die Codegröße nach Anwendung der Optimierung vorherzusagen. Aufgabenvorgaben. Generieren Sie bei gegebenem nicht optimiertem LLVM-IR (Ausgabe vom Clang-Frontend), einer Liste von Optimierungsdurchgängen und einer Startcodegröße den resultierenden Code und die Codegröße nach Anwendung dieser Optimierungen. Es gibt zwei Arten dieser Aufgabe: Bei der ersten erwartet das Modell die Ausgabe einer Compiler-IR; bei der zweiten erwartet das Modell die Ausgabe von Assemblercode. Die Eingabe-IR, der Optimierungsprozess und die Codegröße sind für beide Typen gleich und der Hinweis bestimmt das erforderliche Ausgabeformat. Codegröße. Sie verwenden zwei Metriken, um die Codegröße zu messen: Anzahl der IR-Anweisungen und Binärgröße. Die Binärgröße wird als Summe der .TEXT- und .DATA-Segmentgrößen nach dem Downgrade der IR oder Assembly auf eine Objektdatei berechnet. Wir schließen das .BSS-Segment aus, da es keinen Einfluss auf die Größe der Festplatte hat. Pass optimieren. In dieser Arbeit zielt das Forschungsteam auf LLVM 17.0.6 ab und verwendet den neuen Prozessmanager (PM, 2021), der Durchläufe in verschiedene Ebenen wie Module, Funktionen, Schleifen usw. klassifiziert sowie Durchläufe konvertiert und analysiert . Ein Transformationsdurchlauf ändert eine bestimmte Eingabe-IR, während ein Analysedurchlauf Informationen generiert, die sich auf nachfolgende Transformationen auswirken. Von 346 möglichen Passparametern für opt wählten sie 167 zur Verwendung aus. Dies umfasst jede Standardoptimierungspipeline (z. B. Modul (default)), einzelne Optimierungstransformationsdurchgänge (z. B. Modul (constmerge)), schließt jedoch nicht optimierende Dienstprogrammdurchgänge (z. B. Modul (dot-callgraph)) aus und behält keinen semantischen Konvertierungsdurchlauf bei (z. B. module (internalize)). Sie schließen Analysedurchläufe aus, da sie keine Nebenwirkungen haben und wir uns darauf verlassen, dass der Durchlaufmanager bei Bedarf abhängige Analysedurchläufe einfügt. Für Durchgänge, die Parameter akzeptieren, verwenden wir Standardwerte (z. B. Modul (licm)). Tabelle 9 enthält eine Liste aller verwendeten Durchgänge. Wir verwenden das opt-Tool von LLVM, um die Pass-Liste anzuwenden, und clang, um die resultierende IR in eine Objektdatei herunterzustufen. Listing 1 zeigt die verwendeten Befehle.  Datensatz. Das Forschungsteam erstellte einen Compiler-Simulationsdatensatz, indem es eine Liste von 1 bis 50 zufälligen Optimierungsdurchgängen auf das in Tabelle 2 zusammengefasste nicht optimierte Programm anwendete. Die Länge jeder Passliste wird einheitlich und zufällig gewählt. Die Durchlaufliste wird durch gleichmäßige Stichprobenentnahme aus dem oben genannten Satz von 167 Durchgängen erstellt. Passlisten, die nach 120 Sekunden zum Absturz des Compilers oder zu einer Zeitüberschreitung führen, sind ausgeschlossen. LLM-Compiler-FTD: Erweitern Sie Downstream-Kompilierungsaufgaben. Anweisungsfeinabstimmung für die Optimierung von Flags. Die Manipulation von Compiler-Flags hat erhebliche Auswirkungen auf die Laufzeitleistung und den Code Größe. Das Forschungsteam trainierte das LLM-Compiler-FTD-Modell, um die nachgelagerte Aufgabe der Auswahl von Flags für das IR-Optimierungstool von LLVM auszuführen und so die kleinste Codegröße zu erzeugen.
Datensatz. Das Forschungsteam erstellte einen Compiler-Simulationsdatensatz, indem es eine Liste von 1 bis 50 zufälligen Optimierungsdurchgängen auf das in Tabelle 2 zusammengefasste nicht optimierte Programm anwendete. Die Länge jeder Passliste wird einheitlich und zufällig gewählt. Die Durchlaufliste wird durch gleichmäßige Stichprobenentnahme aus dem oben genannten Satz von 167 Durchgängen erstellt. Passlisten, die nach 120 Sekunden zum Absturz des Compilers oder zu einer Zeitüberschreitung führen, sind ausgeschlossen. LLM-Compiler-FTD: Erweitern Sie Downstream-Kompilierungsaufgaben. Anweisungsfeinabstimmung für die Optimierung von Flags. Die Manipulation von Compiler-Flags hat erhebliche Auswirkungen auf die Laufzeitleistung und den Code Größe. Das Forschungsteam trainierte das LLM-Compiler-FTD-Modell, um die nachgelagerte Aufgabe der Auswahl von Flags für das IR-Optimierungstool von LLVM auszuführen und so die kleinste Codegröße zu erzeugen. Flag-tuned Machine-Learning-Methoden haben bisher gute Ergebnisse gezeigt, hatten jedoch Schwierigkeiten bei der Verallgemeinerung über verschiedene Programme hinweg.Bei früheren Arbeiten mussten oft Dutzende oder Hunderte Male neue Programme kompiliert werden, um verschiedene Konfigurationen auszuprobieren und die leistungsstärkste Option zu finden. Das Forschungsteam trainierte und evaluierte das LLM-Compiler-FTD-Modell anhand einer Zero-Shot-Version dieser Aufgabe, indem es Flags vorhersagte, um die Codegröße unsichtbarer Programme zu minimieren.
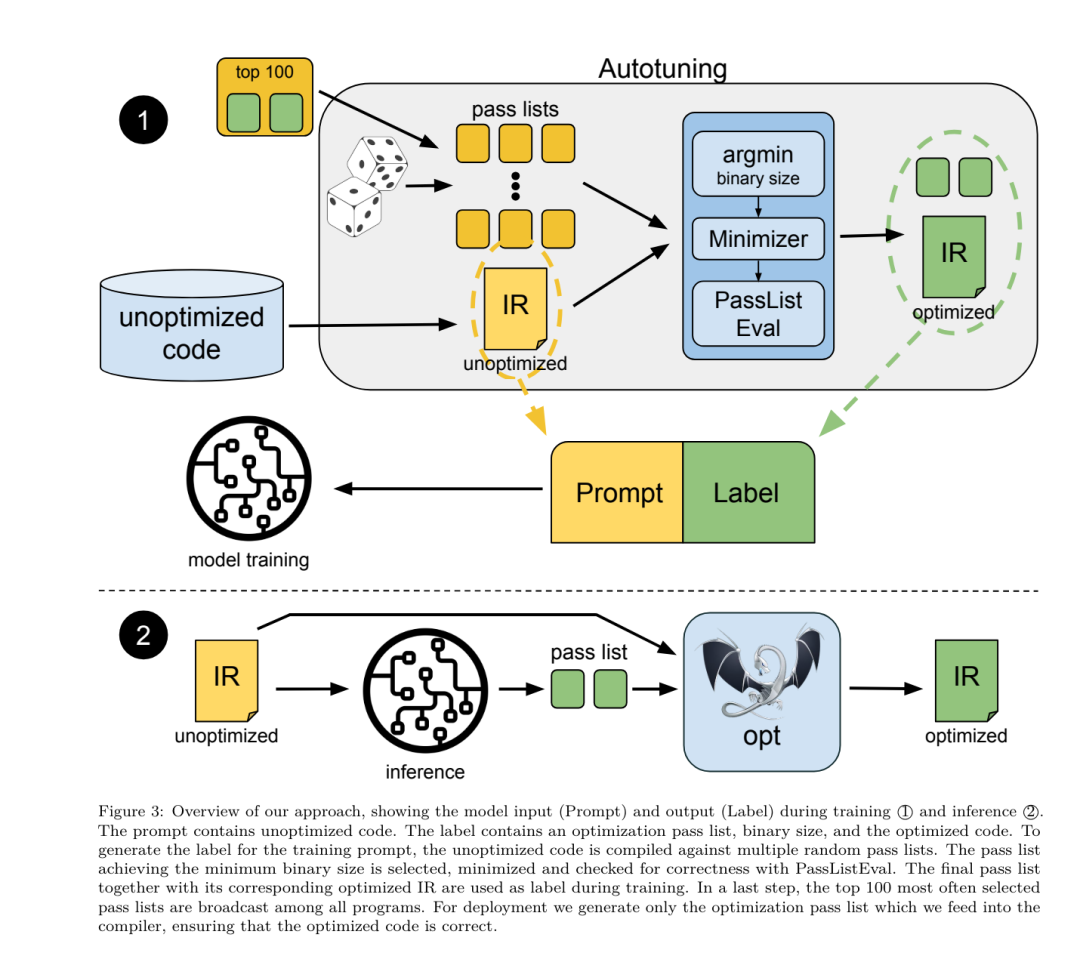
Ihr Ansatz hängt nicht vom gewählten Compiler und den Optimierungsmetriken ab und sie beabsichtigen, in Zukunft auf die Laufzeitleistung abzuzielen. Derzeit vereinfacht die Optimierung der Codegröße die Erfassung von Trainingsdaten. Aufgabenvorgaben. Das Forschungsteam präsentierte dem LLM-Compiler-FTD-Modell ein nicht optimiertes LLVM-IR (generiert vom Clang-Frontend) und forderte es auf, eine Liste der anzuwendenden Opt-Flags, die Binärgröße vor und nach der Anwendung dieser Optimierungen und die zu generieren Ausgabecode, wenn er nicht für den Eingabecode verwendet werden kann. Es wurden Verbesserungen vorgenommen, um eine kurze Ausgabenachricht zu erzeugen, die nur die nicht optimierte Binärgröße enthält. Sie verwendeten den gleichen Satz eingeschränkter Optimierungsdurchgänge wie die Compiler-Simulationsaufgabe und berechneten die Binärgröße auf die gleiche Weise. Abbildung 3 zeigt den Prozess zur Generierung von Trainingsdaten und wie das Modell zum Zeitpunkt der Inferenz verwendet wird. Für die Auswertung wird nur die generierte Bestandenliste benötigt. Sie extrahieren die Pass-Liste aus der Modellausgabe und führen opt mit den angegebenen Parametern aus. Forscher können dann die Genauigkeit der vorhergesagten Binärgröße des Modells bewerten und den Ausgabecode optimieren. Dabei handelt es sich jedoch um zusätzliche Lernaufgaben, die für die Verwendung nicht erforderlich sind. Richtigkeit. Der LLVM-Optimierer ist nicht unfehlbar und die Ausführung von Optimierungsdurchläufen in einer unerwarteten oder ungetesteten Reihenfolge kann subtile Korrektheitsfehler aufdecken, die den Nutzen des Modells verringern. Um dieses Risiko zu mindern, entwickelte das Forschungsteam PassListEval, ein Tool zur automatischen Identifizierung von Pass-Listen, die die Programmsemantik beeinträchtigen oder zum Absturz von Compilern führen. Abbildung 4 zeigt eine Übersicht über das Tool. 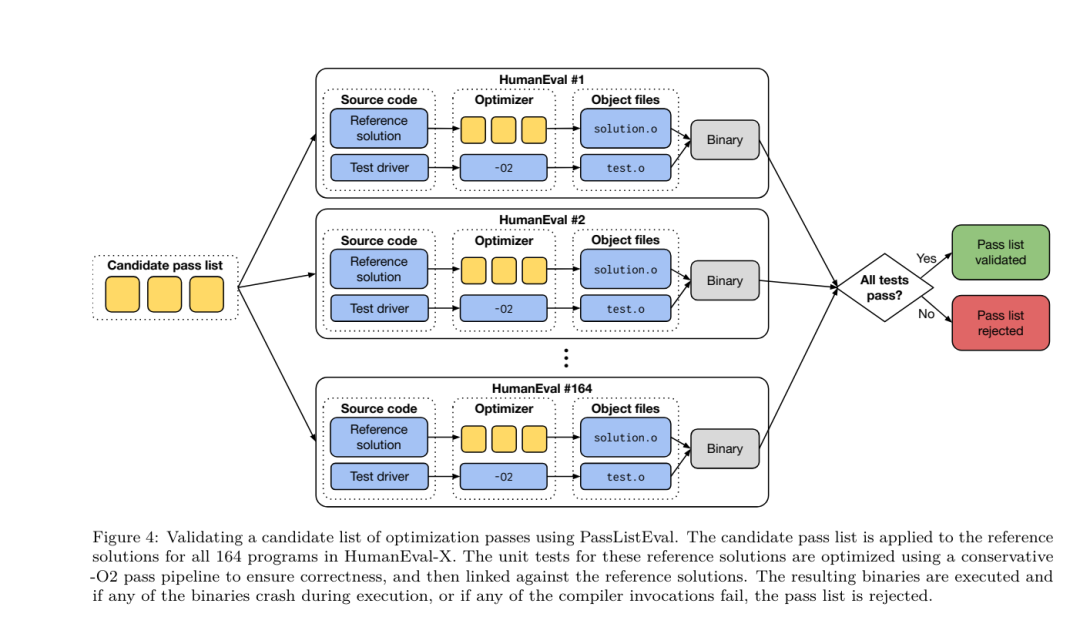 PassListEval akzeptiert als Eingabe eine Liste bestandener Kandidaten und wertet sie anhand einer Suite von 164 selbsttestenden C++-Programmen aus, die von HumanEval-X übernommen wurden. Jedes Programm enthält eine Referenzlösung für eine Programmierherausforderung, z. B. „Überprüfen Sie, ob der Abstand zwischen zwei Zahlen in einem bestimmten Zahlenvektor kleiner als ein bestimmter Schwellenwert ist“, sowie eine Reihe von Komponententests zur Überprüfung der Richtigkeit. Sie wenden die Liste der Kandidatendurchläufe auf Referenzlösungen an und verknüpfen sie dann mit Testsuiten, um Binärdateien zu generieren. Wenn bei der Ausführung ein Test fehlschlägt, stürzt die Binärdatei ab. Wenn eine Binärdatei abstürzt oder ein Compileraufruf fehlschlägt, lehnen wir die Kandidatenliste ab. Datensatz. Das Team trainierte das LLM-Compiler-FTD-Modell anhand eines Flag-abgestimmten Beispieldatensatzes, der aus 4,5 Millionen nicht optimierten IRs abgeleitet wurde, die für das Vortraining verwendet wurden. Um für jedes Programm die besten Passlistenbeispiele zu generieren, führten sie einen umfangreichen iterativen Kompilierungsprozess durch, wie in Abbildung 3 dargestellt. 1. Das Forschungsteam nutzt eine groß angelegte Zufallssuche, um eine erste Kandidatenliste mit den besten Bestehen für das Programm zu erstellen. Für jedes Programm erstellten sie unabhängig eine Zufallsliste mit bis zu 50 Durchgängen, die einheitlich aus dem zuvor beschriebenen Satz von 167 durchsuchbaren Durchgängen ausgewählt wurden. Jedes Mal, wenn sie die Durchlaufliste eines Programms auswerteten, zeichneten sie die resultierende Binärgröße auf und wählten dann die Durchlaufliste jedes Programms aus, das die kleinste Binärgröße erzeugte. Sie führten 22 Milliarden unabhängige Zusammenstellungen durch, durchschnittlich 4.877 pro Programm. 2. Die durch die Zufallssuche generierte Durchlaufliste kann redundante Durchläufe enthalten, die keinen Einfluss auf das Endergebnis haben. Darüber hinaus sind einige Durchlaufreihenfolgen austauschbar und eine Neuordnung hat keinen Einfluss auf das Endergebnis. Da diese Störungen in die Trainingsdaten einbringen, entwickelten sie einen Minimierungsprozess und wendeten ihn auf jede Passliste an. Die Minimierung umfasst drei Schritte: Eliminierung redundanter Durchgänge, Blasensortierung und Einfügungssuche. Bei der Eliminierung redundanter Durchgänge minimieren sie die optimale Durchlaufliste, indem sie iterativ einzelne Durchläufe entfernen, um zu sehen, ob sie zur Binärgröße beitragen, und sie andernfalls zu verwerfen. Wiederholen Sie diesen Vorgang, bis keine Durchgänge mehr verworfen werden können. Die Blasensortierung versucht dann, eine einheitliche Reihenfolge für Teilsequenzen von Durchgängen bereitzustellen, indem Durchgänge anhand von Schlüsselwörtern sortiert werden. Schließlich führt die Einfügungssortierung eine lokale Suche durch, indem sie jeden Durchgang in der Durchgangsliste durchläuft und versucht, jeden der 167 Suchdurchgänge davor einzufügen. Wenn dadurch die Binärgröße verbessert wird, behalten Sie diese neue Passliste bei. Die gesamte Minimierungspipeline wird in einer Schleife durchlaufen, bis ein fester Punkt erreicht ist. Die minimierte Durchlauflistenlängenverteilung ist in Abbildung 9 dargestellt. Die durchschnittliche Länge der bestandenen Liste beträgt 3,84.3. Sie wenden die zuvor beschriebene PassListEval auf die Liste der besten Bestehens des Kandidaten an. Auf diese Weise identifizierten sie 167.971 von 1.704.443 eindeutigen Passlisten (9,85 %), die Kompilierungs- oder Laufzeitfehler verursachen würden 4. Sie sendeten die 100 häufigsten optimalen Passlisten an alle Programme und Aktualisierungen die beste Erfolgsliste für jedes Programm, wenn Verbesserungen festgestellt werden. Danach wurde die Gesamtzahl der eindeutigen Best-Pass-Listen von 1.536.472 auf 581.076 reduziert. Die obige Auto-Tuning-Pipeline führte zu einer Reduzierung der geometrischen mittleren Binärgröße um 7,1 % im Vergleich zu -Oz. Abbildung 10 zeigt die Häufigkeit eines einzelnen Durchgangs. Für sie ist diese automatische Abstimmung der Goldstandard für jede Programmoptimierung. Obwohl die festgestellten Einsparungen bei der Binärgröße erheblich sind, erforderte dies 28 Milliarden zusätzliche Kompilierungen mit einem Rechenaufwand von über 21.000 CPU-Tagen. Das Ziel der Befehlsfeinabstimmung des LLM-Compiler-FTD zur Durchführung von Flag-Tuning-Aufgaben besteht darin, einen Bruchteil der Auto-Tuner-Leistung zu erreichen, ohne den Compiler tausende Male ausführen zu müssen. Feinabstimmung der Anweisungen für die Disassemblierung Hebt Code von der Assemblersprache in eine übergeordnete Struktur, die zusätzliche Optimierungen ausführen kann, z. B. Bibliothekscode direkt in Anwendungscode integrieren oder Legacy-Code darauf portieren neue Architektur. Im Bereich der Dekompilierung wurden Fortschritte bei der Anwendung maschineller Lerntechniken erzielt, um aus binären ausführbaren Dateien lesbaren und genauen Code zu generieren. In dieser Studie zeigt das Forschungsteam, wie LLM Compiler FTD durch Feinabstimmung eine Disassemblierung durchführen kann und dabei die Beziehung zwischen Assemblercode und Compiler-IR lernt. Die Aufgabe besteht darin, die umgekehrte Übersetzung von clang -xir - -o - -S zu lernen, wie in Abbildung 5 dargestellt.
PassListEval akzeptiert als Eingabe eine Liste bestandener Kandidaten und wertet sie anhand einer Suite von 164 selbsttestenden C++-Programmen aus, die von HumanEval-X übernommen wurden. Jedes Programm enthält eine Referenzlösung für eine Programmierherausforderung, z. B. „Überprüfen Sie, ob der Abstand zwischen zwei Zahlen in einem bestimmten Zahlenvektor kleiner als ein bestimmter Schwellenwert ist“, sowie eine Reihe von Komponententests zur Überprüfung der Richtigkeit. Sie wenden die Liste der Kandidatendurchläufe auf Referenzlösungen an und verknüpfen sie dann mit Testsuiten, um Binärdateien zu generieren. Wenn bei der Ausführung ein Test fehlschlägt, stürzt die Binärdatei ab. Wenn eine Binärdatei abstürzt oder ein Compileraufruf fehlschlägt, lehnen wir die Kandidatenliste ab. Datensatz. Das Team trainierte das LLM-Compiler-FTD-Modell anhand eines Flag-abgestimmten Beispieldatensatzes, der aus 4,5 Millionen nicht optimierten IRs abgeleitet wurde, die für das Vortraining verwendet wurden. Um für jedes Programm die besten Passlistenbeispiele zu generieren, führten sie einen umfangreichen iterativen Kompilierungsprozess durch, wie in Abbildung 3 dargestellt. 1. Das Forschungsteam nutzt eine groß angelegte Zufallssuche, um eine erste Kandidatenliste mit den besten Bestehen für das Programm zu erstellen. Für jedes Programm erstellten sie unabhängig eine Zufallsliste mit bis zu 50 Durchgängen, die einheitlich aus dem zuvor beschriebenen Satz von 167 durchsuchbaren Durchgängen ausgewählt wurden. Jedes Mal, wenn sie die Durchlaufliste eines Programms auswerteten, zeichneten sie die resultierende Binärgröße auf und wählten dann die Durchlaufliste jedes Programms aus, das die kleinste Binärgröße erzeugte. Sie führten 22 Milliarden unabhängige Zusammenstellungen durch, durchschnittlich 4.877 pro Programm. 2. Die durch die Zufallssuche generierte Durchlaufliste kann redundante Durchläufe enthalten, die keinen Einfluss auf das Endergebnis haben. Darüber hinaus sind einige Durchlaufreihenfolgen austauschbar und eine Neuordnung hat keinen Einfluss auf das Endergebnis. Da diese Störungen in die Trainingsdaten einbringen, entwickelten sie einen Minimierungsprozess und wendeten ihn auf jede Passliste an. Die Minimierung umfasst drei Schritte: Eliminierung redundanter Durchgänge, Blasensortierung und Einfügungssuche. Bei der Eliminierung redundanter Durchgänge minimieren sie die optimale Durchlaufliste, indem sie iterativ einzelne Durchläufe entfernen, um zu sehen, ob sie zur Binärgröße beitragen, und sie andernfalls zu verwerfen. Wiederholen Sie diesen Vorgang, bis keine Durchgänge mehr verworfen werden können. Die Blasensortierung versucht dann, eine einheitliche Reihenfolge für Teilsequenzen von Durchgängen bereitzustellen, indem Durchgänge anhand von Schlüsselwörtern sortiert werden. Schließlich führt die Einfügungssortierung eine lokale Suche durch, indem sie jeden Durchgang in der Durchgangsliste durchläuft und versucht, jeden der 167 Suchdurchgänge davor einzufügen. Wenn dadurch die Binärgröße verbessert wird, behalten Sie diese neue Passliste bei. Die gesamte Minimierungspipeline wird in einer Schleife durchlaufen, bis ein fester Punkt erreicht ist. Die minimierte Durchlauflistenlängenverteilung ist in Abbildung 9 dargestellt. Die durchschnittliche Länge der bestandenen Liste beträgt 3,84.3. Sie wenden die zuvor beschriebene PassListEval auf die Liste der besten Bestehens des Kandidaten an. Auf diese Weise identifizierten sie 167.971 von 1.704.443 eindeutigen Passlisten (9,85 %), die Kompilierungs- oder Laufzeitfehler verursachen würden 4. Sie sendeten die 100 häufigsten optimalen Passlisten an alle Programme und Aktualisierungen die beste Erfolgsliste für jedes Programm, wenn Verbesserungen festgestellt werden. Danach wurde die Gesamtzahl der eindeutigen Best-Pass-Listen von 1.536.472 auf 581.076 reduziert. Die obige Auto-Tuning-Pipeline führte zu einer Reduzierung der geometrischen mittleren Binärgröße um 7,1 % im Vergleich zu -Oz. Abbildung 10 zeigt die Häufigkeit eines einzelnen Durchgangs. Für sie ist diese automatische Abstimmung der Goldstandard für jede Programmoptimierung. Obwohl die festgestellten Einsparungen bei der Binärgröße erheblich sind, erforderte dies 28 Milliarden zusätzliche Kompilierungen mit einem Rechenaufwand von über 21.000 CPU-Tagen. Das Ziel der Befehlsfeinabstimmung des LLM-Compiler-FTD zur Durchführung von Flag-Tuning-Aufgaben besteht darin, einen Bruchteil der Auto-Tuner-Leistung zu erreichen, ohne den Compiler tausende Male ausführen zu müssen. Feinabstimmung der Anweisungen für die Disassemblierung Hebt Code von der Assemblersprache in eine übergeordnete Struktur, die zusätzliche Optimierungen ausführen kann, z. B. Bibliothekscode direkt in Anwendungscode integrieren oder Legacy-Code darauf portieren neue Architektur. Im Bereich der Dekompilierung wurden Fortschritte bei der Anwendung maschineller Lerntechniken erzielt, um aus binären ausführbaren Dateien lesbaren und genauen Code zu generieren. In dieser Studie zeigt das Forschungsteam, wie LLM Compiler FTD durch Feinabstimmung eine Disassemblierung durchführen kann und dabei die Beziehung zwischen Assemblercode und Compiler-IR lernt. Die Aufgabe besteht darin, die umgekehrte Übersetzung von clang -xir - -o - -S zu lernen, wie in Abbildung 5 dargestellt. 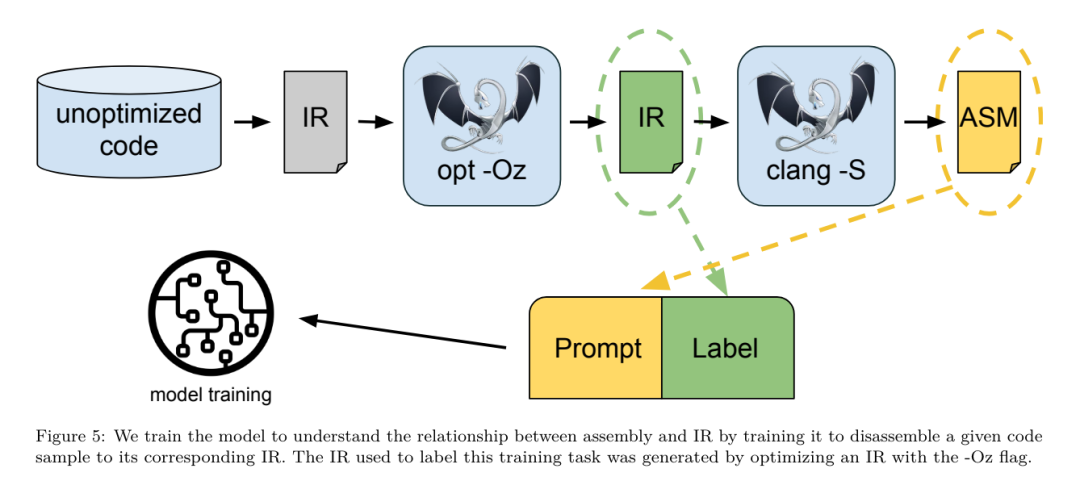 Hin- und Rückfahrttest. Die Verwendung von LLM zur Demontage kann zu Korrektheitsproblemen führen. Verstärkter Code muss mit einem Äquivalenzprüfer überprüft werden, was nicht immer möglich ist oder eine manuelle Überprüfung der Richtigkeit oder ausreichende Testfälle erfordert, um Vertrauen zu gewinnen. Durch Round-Trip-Tests kann jedoch eine Untergrenze für die Korrektheit ermittelt werden. Das heißt, durch erneutes Kompilieren der angehobenen IR in Assembler-Code ist die IR korrekt, wenn der Assembler-Code derselbe ist. Dies bietet einen einfachen Weg zur Nutzung der LLM-Ergebnisse und ist eine einfache Möglichkeit, den Nutzen des zerlegten Modells zu messen. Aufgabenvorgaben. Das Forschungsteam fütterte den Modell-Assembler-Code und trainierte ihn, entsprechende Demontage-IRs auszusenden. Die Kontextlänge für diese Aufgabe wurde auf 8.000 Token für den Eingabe-Assembly-Code und 8.000 Token für die Ausgabe-IR festgelegt. Datensatz. Sie leiteten Assemblercode- und IR-Paare aus dem in früheren Aufgaben verwendeten Datensatz ab. Ihr Feinabstimmungsdatensatz enthält 4,7 Millionen Samples, und die Eingabe-IR wurde mit -Oz optimiert, bevor sie auf x86-Assembly reduziert wurde. Die Daten werden per Bytepaarkodierung tokenisiert, wobei derselbe Tokenizer wie Code Llama, Llama und Llama 2 verwendet wird. Sie verwenden für alle vier Trainingsphasen die gleichen Trainingsparameter. Sie verwendeten die meisten der gleichen Trainingsparameter wie das Code-Llama-Basismodell und verwendeten den AdamW-Optimierer mit Werten von 0,9 und 0,95 für β1 und β2. Sie verwendeten eine Kosinusplanung mit einem Aufwärmschritt von 1000 Schritten und stellten die endgültige Lernrate auf 1/30 der Spitzenlernrate ein. Im Vergleich zum Code-Llama-Basismodell erhöhte das Team die Kontextlänge einer einzelnen Sequenz von 4096 auf 16384, behielt aber die Stapelgröße konstant bei 4 Millionen Token. Um längere Kontexte zu berücksichtigen, setzten sie die Lernrate auf 2e-5 und änderten die Parameter der RoPE-Positionseinbettung, wobei sie die Häufigkeit auf den Basiswert θ=10^6 zurücksetzten. Diese Einstellungen stehen im Einklang mit dem langen Kontexttraining des Code Llama-Basismodells. Das Forschungsteam bewertet die Leistung des LLM-Compiler-Modells bei Flag-Tuning- und Disassemblierungsaufgaben, Compiler-Simulation, Vorhersage des nächsten Tokens und Software-Engineering-Aufgaben. Methode. Sie bewerten die Leistung des LLM Compiler FTD bei der Optimierung von Optimierungsflags für unsichtbare Programme und vergleichen sie mit GPT-4 Turbo und Code Llama – Instruct. Sie führen eine Inferenz für jedes Modell durch und extrahieren eine Liste von Optimierungsdurchgängen aus der Modellausgabe. Anschließend optimieren sie mit dieser Durchlaufliste ein bestimmtes Programm und zeichnen die Binärgröße des Programms auf, wenn es mit -Oz optimiert wird. Für GPT-4 Turbo und Code Llama – Instruct wird nach der Eingabeaufforderung ein Suffix angehängt, um zusätzlichen Kontext zur weiteren Beschreibung des Problems und des erwarteten Ausgabeformats bereitzustellen.Alle vom Modell generierten Bestandenlisten werden mit PassListEval überprüft, und -Oz wird als Alternative verwendet, wenn die Überprüfung fehlschlägt. Um die Richtigkeit der vom Modell generierten Durchlaufliste weiter zu überprüfen, verknüpften sie die endgültige Programmbinärdatei und testeten ihre Ausgabe differenziell mit der Benchmark-Ausgabe, die mithilfe einer konservativen -O2-Optimierungspipeline optimiert wurde. Datensatz. Das Forschungsteam führte die Bewertung anhand von 2.398 Testhinweisen durch, die aus der MiBench-Benchmark-Suite extrahiert wurden. Um diese Hinweise zu generieren, nehmen sie alle 713 Übersetzungseinheiten, aus denen die 24 MiBench-Benchmarks bestehen, generieren aus jeder Einheit nicht optimierte IRs und formatieren sie dann in Hinweise. Wenn die generierten Hinweise 15.000 Token überschreiten, teilen sie das LLVM-Modul, das diese Übersetzungseinheit darstellt, mithilfe von llvm-extract in kleinere Module auf, eines pro Funktion. Dies führt zu 1.985 Hinweisen, die in das 15.000-Token-Kontextfenster passen, sodass 443 Übersetzungseinheiten übrig bleiben. Nicht geeignet . Bei der Berechnung der Leistungsbewertungen verwendeten sie -Oz für die 443 ausgeschlossenen Übersetzungseinheiten. Tabelle 10 fasst die Benchmarks zusammen.
Hin- und Rückfahrttest. Die Verwendung von LLM zur Demontage kann zu Korrektheitsproblemen führen. Verstärkter Code muss mit einem Äquivalenzprüfer überprüft werden, was nicht immer möglich ist oder eine manuelle Überprüfung der Richtigkeit oder ausreichende Testfälle erfordert, um Vertrauen zu gewinnen. Durch Round-Trip-Tests kann jedoch eine Untergrenze für die Korrektheit ermittelt werden. Das heißt, durch erneutes Kompilieren der angehobenen IR in Assembler-Code ist die IR korrekt, wenn der Assembler-Code derselbe ist. Dies bietet einen einfachen Weg zur Nutzung der LLM-Ergebnisse und ist eine einfache Möglichkeit, den Nutzen des zerlegten Modells zu messen. Aufgabenvorgaben. Das Forschungsteam fütterte den Modell-Assembler-Code und trainierte ihn, entsprechende Demontage-IRs auszusenden. Die Kontextlänge für diese Aufgabe wurde auf 8.000 Token für den Eingabe-Assembly-Code und 8.000 Token für die Ausgabe-IR festgelegt. Datensatz. Sie leiteten Assemblercode- und IR-Paare aus dem in früheren Aufgaben verwendeten Datensatz ab. Ihr Feinabstimmungsdatensatz enthält 4,7 Millionen Samples, und die Eingabe-IR wurde mit -Oz optimiert, bevor sie auf x86-Assembly reduziert wurde. Die Daten werden per Bytepaarkodierung tokenisiert, wobei derselbe Tokenizer wie Code Llama, Llama und Llama 2 verwendet wird. Sie verwenden für alle vier Trainingsphasen die gleichen Trainingsparameter. Sie verwendeten die meisten der gleichen Trainingsparameter wie das Code-Llama-Basismodell und verwendeten den AdamW-Optimierer mit Werten von 0,9 und 0,95 für β1 und β2. Sie verwendeten eine Kosinusplanung mit einem Aufwärmschritt von 1000 Schritten und stellten die endgültige Lernrate auf 1/30 der Spitzenlernrate ein. Im Vergleich zum Code-Llama-Basismodell erhöhte das Team die Kontextlänge einer einzelnen Sequenz von 4096 auf 16384, behielt aber die Stapelgröße konstant bei 4 Millionen Token. Um längere Kontexte zu berücksichtigen, setzten sie die Lernrate auf 2e-5 und änderten die Parameter der RoPE-Positionseinbettung, wobei sie die Häufigkeit auf den Basiswert θ=10^6 zurücksetzten. Diese Einstellungen stehen im Einklang mit dem langen Kontexttraining des Code Llama-Basismodells. Das Forschungsteam bewertet die Leistung des LLM-Compiler-Modells bei Flag-Tuning- und Disassemblierungsaufgaben, Compiler-Simulation, Vorhersage des nächsten Tokens und Software-Engineering-Aufgaben. Methode. Sie bewerten die Leistung des LLM Compiler FTD bei der Optimierung von Optimierungsflags für unsichtbare Programme und vergleichen sie mit GPT-4 Turbo und Code Llama – Instruct. Sie führen eine Inferenz für jedes Modell durch und extrahieren eine Liste von Optimierungsdurchgängen aus der Modellausgabe. Anschließend optimieren sie mit dieser Durchlaufliste ein bestimmtes Programm und zeichnen die Binärgröße des Programms auf, wenn es mit -Oz optimiert wird. Für GPT-4 Turbo und Code Llama – Instruct wird nach der Eingabeaufforderung ein Suffix angehängt, um zusätzlichen Kontext zur weiteren Beschreibung des Problems und des erwarteten Ausgabeformats bereitzustellen.Alle vom Modell generierten Bestandenlisten werden mit PassListEval überprüft, und -Oz wird als Alternative verwendet, wenn die Überprüfung fehlschlägt. Um die Richtigkeit der vom Modell generierten Durchlaufliste weiter zu überprüfen, verknüpften sie die endgültige Programmbinärdatei und testeten ihre Ausgabe differenziell mit der Benchmark-Ausgabe, die mithilfe einer konservativen -O2-Optimierungspipeline optimiert wurde. Datensatz. Das Forschungsteam führte die Bewertung anhand von 2.398 Testhinweisen durch, die aus der MiBench-Benchmark-Suite extrahiert wurden. Um diese Hinweise zu generieren, nehmen sie alle 713 Übersetzungseinheiten, aus denen die 24 MiBench-Benchmarks bestehen, generieren aus jeder Einheit nicht optimierte IRs und formatieren sie dann in Hinweise. Wenn die generierten Hinweise 15.000 Token überschreiten, teilen sie das LLVM-Modul, das diese Übersetzungseinheit darstellt, mithilfe von llvm-extract in kleinere Module auf, eines pro Funktion. Dies führt zu 1.985 Hinweisen, die in das 15.000-Token-Kontextfenster passen, sodass 443 Übersetzungseinheiten übrig bleiben. Nicht geeignet . Bei der Berechnung der Leistungsbewertungen verwendeten sie -Oz für die 443 ausgeschlossenen Übersetzungseinheiten. Tabelle 10 fasst die Benchmarks zusammen. 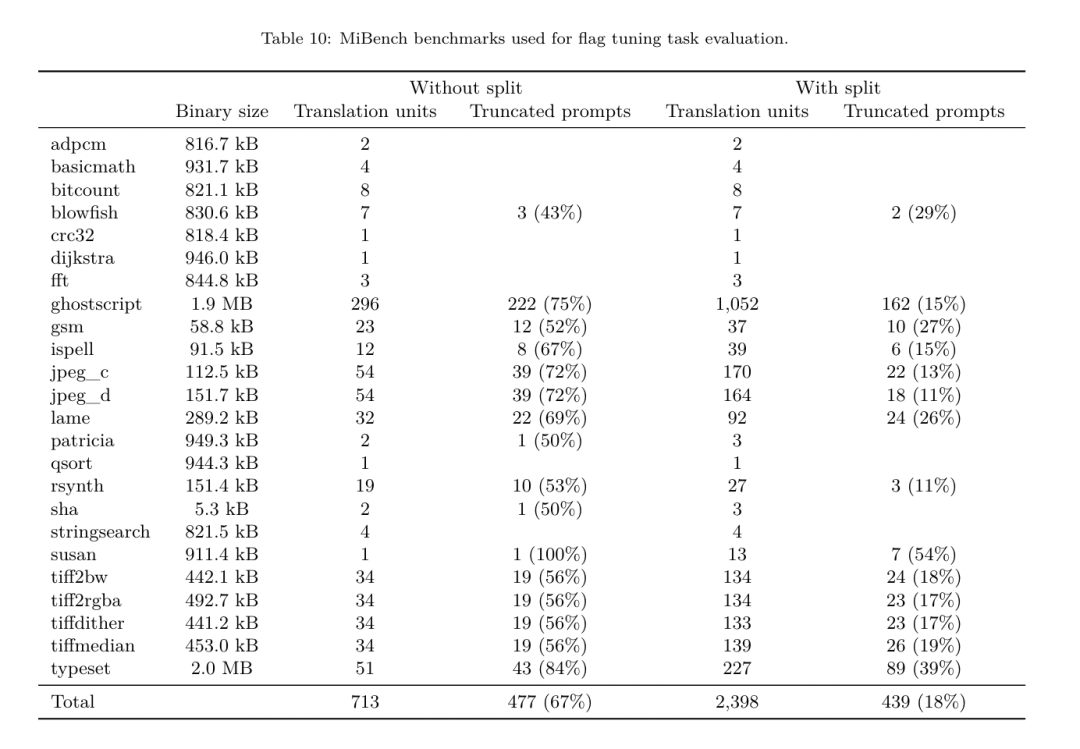 Ergebnisse. Tabelle 3 zeigt die Zero-Shot-Leistung aller Modelle bei der Flag-Tuning-Aufgabe. Nur das LLM Compiler FTD-Modell verbesserte sich gegenüber -Oz, wobei das 13B-Parametermodell das kleinere Modell leicht übertraf und in 61 % der Fälle kleinere Objektdateien als -Oz erzeugte.
Ergebnisse. Tabelle 3 zeigt die Zero-Shot-Leistung aller Modelle bei der Flag-Tuning-Aufgabe. Nur das LLM Compiler FTD-Modell verbesserte sich gegenüber -Oz, wobei das 13B-Parametermodell das kleinere Modell leicht übertraf und in 61 % der Fälle kleinere Objektdateien als -Oz erzeugte. 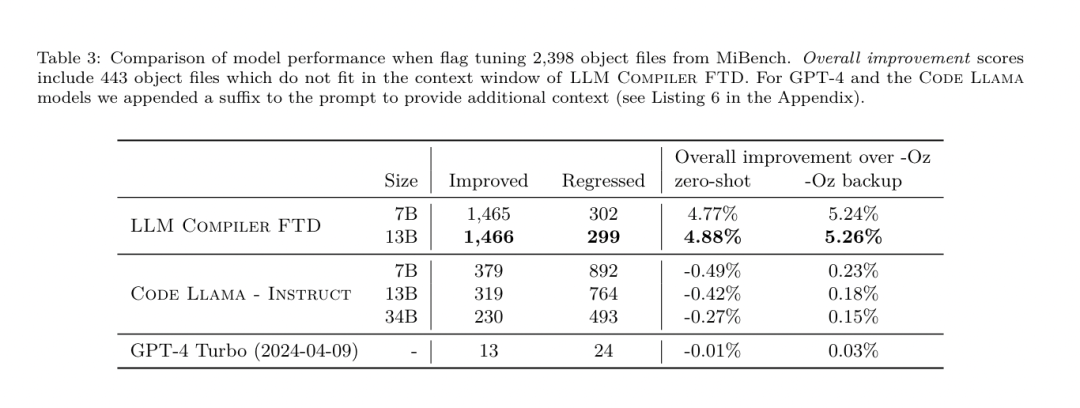 In einigen Fällen führte die vom Modell generierte Passliste zu einer größeren Zieldateigröße als -Oz. Beispielsweise kommt es beim LLM Compiler FTD 13B in 12 % der Fälle zu einer Verschlechterung. Diese Verschlechterungen können vermieden werden, indem das Programm einfach zweimal kompiliert wird: einmal mit der vom Modell generierten Durchlaufliste und einmal mit -Oz, und dann die Durchlaufliste auszuwählen, die die besten Ergebnisse liefert. Durch die Eliminierung der Verschlechterung im Vergleich zu -Oz erhöhen diese -Oz-Backup-Scores die Gesamtverbesserung von LLM Compiler FTD 13B im Vergleich zu -Oz auf 5,26 % und ermöglichen Code Llama - Instruct und GPT-4 Turbo, bescheidene Verbesserungen im Vergleich zu -Oz zu erzielen. Abbildung 6 zeigt die Leistungsaufschlüsselung jedes Modells bei verschiedenen Benchmarks.
In einigen Fällen führte die vom Modell generierte Passliste zu einer größeren Zieldateigröße als -Oz. Beispielsweise kommt es beim LLM Compiler FTD 13B in 12 % der Fälle zu einer Verschlechterung. Diese Verschlechterungen können vermieden werden, indem das Programm einfach zweimal kompiliert wird: einmal mit der vom Modell generierten Durchlaufliste und einmal mit -Oz, und dann die Durchlaufliste auszuwählen, die die besten Ergebnisse liefert. Durch die Eliminierung der Verschlechterung im Vergleich zu -Oz erhöhen diese -Oz-Backup-Scores die Gesamtverbesserung von LLM Compiler FTD 13B im Vergleich zu -Oz auf 5,26 % und ermöglichen Code Llama - Instruct und GPT-4 Turbo, bescheidene Verbesserungen im Vergleich zu -Oz zu erzielen. Abbildung 6 zeigt die Leistungsaufschlüsselung jedes Modells bei verschiedenen Benchmarks. 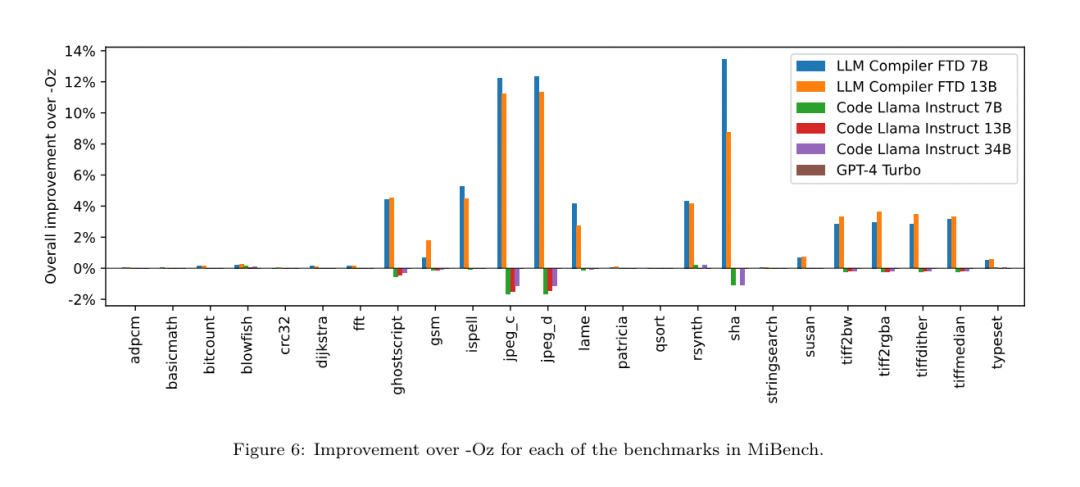 Binäre Größengenauigkeit. Während die vom Modell generierten Binärgrößenvorhersagen keinen Einfluss auf die tatsächliche Kompilierung haben, kann das Forschungsteam die Leistung des Modells bei der Vorhersage der Binärgröße vor und nach der Optimierung bewerten, um zu verstehen, wie gut jedes Modell die Optimierung versteht. Abbildung 7 zeigt die Ergebnisse.
Binäre Größengenauigkeit. Während die vom Modell generierten Binärgrößenvorhersagen keinen Einfluss auf die tatsächliche Kompilierung haben, kann das Forschungsteam die Leistung des Modells bei der Vorhersage der Binärgröße vor und nach der Optimierung bewerten, um zu verstehen, wie gut jedes Modell die Optimierung versteht. Abbildung 7 zeigt die Ergebnisse.  Die Binärgrößenvorhersagen des LLM Compiler FTD korrelieren gut mit der tatsächlichen Situation, wobei das 7B-Parametermodell MAPE-Werte von 0,083 bzw. 0,225 für nicht optimierte und optimierte Binärgrößen erreicht. Die MAPE-Werte für das 13B-Parametermodell waren ähnlich und lagen bei 0,082 bzw. 0,225. Die Binärgrößenvorhersagen von Code Llama - Instruct und GPT-4 Turbo stimmen kaum mit der Realität überein. Die Forscher stellten fest, dass LLM Compiler FTD bei optimiertem Code etwas höhere Fehler aufwies als bei nicht optimiertem Code. Insbesondere neigt LLM Compiler FTD gelegentlich dazu, die Wirksamkeit der Optimierung zu überschätzen, was zu vorhergesagten Binärgrößen führt, die niedriger sind als sie tatsächlich sind. Ablationsforschung. Tabelle 4 zeigt eine Ablationsstudie zur Leistung des Modells bei einem kleinen Hold-Out-Validierungssatz von 500 Hinweisen aus derselben Verteilung wie ihre Trainingsdaten (aber nicht im Training verwendet). Sie führten in jeder Phase der in Abbildung 1 gezeigten Trainingspipeline ein Flag-Tuning-Training durch, um die Leistung zu vergleichen. Wie gezeigt, führte das Demontagetraining zu einem leichten Leistungsabfall von durchschnittlich 5,15 % auf 5,12 % (Verbesserung gegenüber -Oz). Sie demonstrieren auch die Leistung des Autotuners, der zur Generierung der in Abschnitt 2 beschriebenen Trainingsdaten verwendet wird. Der LLM Compiler FTD erreicht 77 % der Leistung des Autotuners.
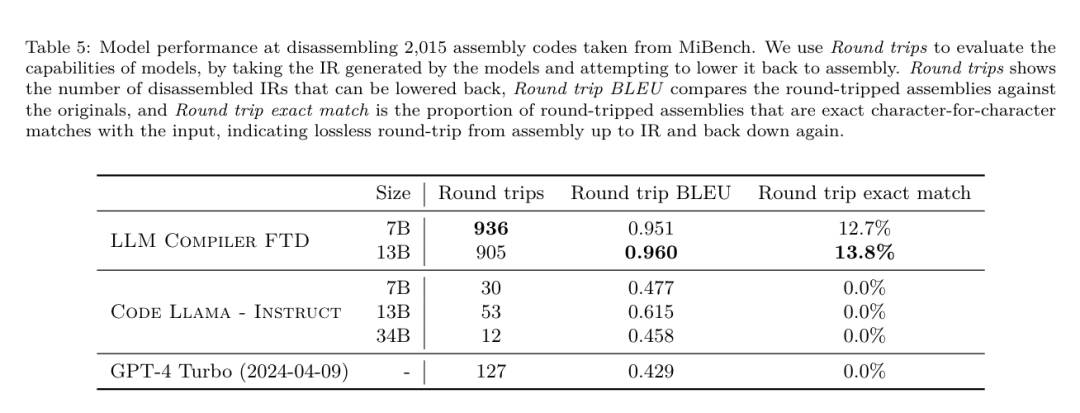
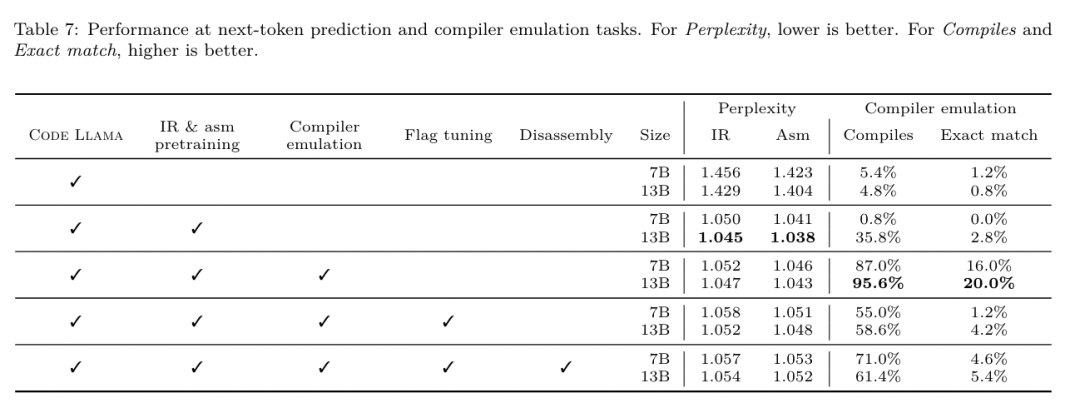
Die Binärgrößenvorhersagen des LLM Compiler FTD korrelieren gut mit der tatsächlichen Situation, wobei das 7B-Parametermodell MAPE-Werte von 0,083 bzw. 0,225 für nicht optimierte und optimierte Binärgrößen erreicht. Die MAPE-Werte für das 13B-Parametermodell waren ähnlich und lagen bei 0,082 bzw. 0,225. Die Binärgrößenvorhersagen von Code Llama - Instruct und GPT-4 Turbo stimmen kaum mit der Realität überein. Die Forscher stellten fest, dass LLM Compiler FTD bei optimiertem Code etwas höhere Fehler aufwies als bei nicht optimiertem Code. Insbesondere neigt LLM Compiler FTD gelegentlich dazu, die Wirksamkeit der Optimierung zu überschätzen, was zu vorhergesagten Binärgrößen führt, die niedriger sind als sie tatsächlich sind. Ablationsforschung. Tabelle 4 zeigt eine Ablationsstudie zur Leistung des Modells bei einem kleinen Hold-Out-Validierungssatz von 500 Hinweisen aus derselben Verteilung wie ihre Trainingsdaten (aber nicht im Training verwendet). Sie führten in jeder Phase der in Abbildung 1 gezeigten Trainingspipeline ein Flag-Tuning-Training durch, um die Leistung zu vergleichen. Wie gezeigt, führte das Demontagetraining zu einem leichten Leistungsabfall von durchschnittlich 5,15 % auf 5,12 % (Verbesserung gegenüber -Oz). Sie demonstrieren auch die Leistung des Autotuners, der zur Generierung der in Abschnitt 2 beschriebenen Trainingsdaten verwendet wird. Der LLM Compiler FTD erreicht 77 % der Leistung des Autotuners.  Methode. Das Forschungsteam bewertet die funktionale Korrektheit von LLM-generiertem Code bei der Zerlegung von Assembler-Code in LLVM-IR. Sie evaluieren den LLM Compiler FTD und vergleichen ihn mit Code Llama – Instruct und GPT-4 Turbo und stellen fest, dass zusätzliche Hinweissuffixe erforderlich sind, um die beste Leistung aus diesen Modellen herauszuholen. Das Suffix bietet zusätzlichen Kontext zur Aufgabe und zum erwarteten Ausgabeformat. Um die Leistung des Modells zu bewerten, stuften sie die vom Modell erzeugte Demontage-IR zurück auf die Montage herab. Dadurch können wir die Genauigkeit der Demontage bewerten, indem wir die BLEU-Werte der Originalbaugruppe mit den Round-Trip-Ergebnissen vergleichen.Eine verlustfreie, perfekte Demontage von der Montage zur IR hat einen Round-Trip-BLEU-Score von 1,0 (exakte Übereinstimmung). Datensatz. Sie evaluierten anhand von 2.015 Testhinweisen, die aus der MiBench-Benchmark-Suite extrahiert wurden, und nutzten die 2.398 Übersetzungseinheiten, die für die obige Flag-Tuning-Bewertung verwendet wurden, um Demontagehinweise zu generieren. Anschließend filterten sie die Tipps basierend auf der maximalen 8.000-Token-Länge und ließen 8.000 Token für die Modellausgabe zu, so dass 2.015 übrig blieben. Tabelle 11 fasst die Benchmarks zusammen. Ergebnisse. Tabelle 5 zeigt die Leistung des Modells bei der Demontageaufgabe. LLM Compiler FTD 7B hat eine etwas höhere Round-Trip-Erfolgsrate als LLM Compiler FTD 13B, aber LLM Compiler FTD 13B hat die höchste Round-Trip-Assembly-Genauigkeit (Round-Trip BLEU) und produziert am häufigsten perfekte Disassemblierungen ( genaue Hin- und Rückfahrt-Übereinstimmung). Code Llama – Instruct und GPT-4 Turbo haben Schwierigkeiten, syntaktisch korrektes LLVM-IR zu generieren. Abbildung 8 zeigt die Verteilung der Round-Trip-BLEU-Scores für alle Modelle. Ablationsforschung. Tabelle 6 zeigt eine Ablationsstudie zur Leistung des Modells anhand eines kleinen Hold-out-Validierungssatzes von 500 Hinweisen, der dem zuvor verwendeten MiBench-Datensatz entnommen wurde. Sie führten in jeder Phase der in Abbildung 1 gezeigten Trainingspipeline ein Demontagetraining durch, um die Leistung zu vergleichen. Die Roundtrip-Rate ist beim Durchlaufen des gesamten Trainingsdatenstapels am höchsten und nimmt mit jeder Trainingsphase weiter ab, obwohl sich die Roundtrip-BLEU in jeder Phase kaum ändert. Grundlegende ModellaufgabeMethode. Das Forschungsteam führte Ablationsforschung am LLM-Compiler-Modell für zwei grundlegende Modellaufgaben durch: Vorhersage des nächsten Tokens und Compiler-Simulation. Sie führen diese Bewertung in jeder Phase der Trainingspipeline durch, um zu verstehen, wie sich das Training für jede aufeinanderfolgende Aufgabe auf die Leistung auswirkt. Für die Vorhersage des nächsten Tokens berechnen sie die Perplexität anhand einer kleinen Stichprobe von LLVM-IR und Assembler-Code auf allen Optimierungsebenen. Sie bewerten Compilersimulationen anhand von zwei Metriken: ob der generierte IR- oder Assemblercode kompiliert werden kann und ob der generierte IR- oder Assemblercode genau mit dem übereinstimmt, was der Compiler erzeugt. Datensatz. Für die Vorhersage des nächsten Tokens verwenden sie einen kleinen Holdout-Validierungsdatensatz aus derselben Verteilung wie unsere Trainingsdaten, der jedoch nicht für das Training verwendet wird. Sie verwenden eine Mischung aus Optimierungsstufen, einschließlich nicht optimiertem Code, mit -Oz optimiertem Code und zufällig generierten Passlisten. Für Compiler-Simulationen wurden sie anhand von 500 aus MiBench generierten Tipps unter Verwendung zufällig generierter Pass-Listen auf die in Abschnitt 2.2 beschriebene Weise ausgewertet. Ergebnisse. Tabelle 7 zeigt die Leistung von LLM Compiler FTD bei zwei Basismodell-Trainingsaufgaben (Vorhersage des nächsten Tokens und Compiler-Simulation) über alle Trainingsphasen hinweg. Die Leistung der nächsten Token-Vorhersage steigt nach Code Llama, der IR und Assemblierung kaum erkennt, stark an und sinkt mit jeder weiteren Feinabstimmungsstufe leicht. Bei Compiler-Simulationen erbringen das Code-Llama-Basismodell und vorab trainierte Modelle keine gute Leistung, da sie nicht für diese Aufgabe trainiert sind. Die maximale Leistung wird direkt nach dem Compiler-Simulationstraining erreicht, bei dem 95,6 % der vom LLM Compiler FTD 13B generierten IRs und Assemblys kompiliert werden und 20 % exakt mit dem Compiler übereinstimmen. Nach dem Flag-Tuning und der Feinabstimmung der Demontage sank die Leistung. Software-Engineering-AufgabenMethoden. Während der Zweck von LLM Compiler FTD darin besteht, ein Basismodell für die Codeoptimierung bereitzustellen, baut es auf dem Basismodell des Code Llama auf, das für Softwareentwicklungsaufgaben trainiert wurde. Um zu bewerten, wie sich zusätzliches Training des LLM Compiler FTD auf die Leistung der Codegenerierung auswirkt, verwendeten sie dieselbe Benchmark-Suite wie Code Llama, um die Fähigkeit von LLM zu bewerten, Python-Code aus Eingabeaufforderungen in natürlicher Sprache zu generieren, z. B. „Schreiben Sie eine Funktion, die die längste Kette findet.“ aus Mengenpaaren gebildet. Sie verwenden HumanEval- und MBPP-Benchmarks, genau wie Code Llama. Ergebnisse. Tabelle 8 zeigt die Greedy-Dekodierungsleistung (pass@1) für alle Modelltrainingsstufen und Modellgrößen ausgehend vom Code-Llama-Basismodell.Außerdem werden die Ergebnisse des Modells für bestanden@10 und bestanden@100 angezeigt, die mit p=0,95 und Temperatur=0,6 generiert wurden. Jede Compiler-zentrierte Trainingsphase führt zu einer leichten Verschlechterung der Python-Programmierfähigkeiten. Bei HumanEval und MBPP sank die Pass@1-Leistung des LLM-Compilers um bis zu 18 % bzw. 5 % und die LLM-Compiler-FTD sank um bis zu 29 % bzw. 22 % nach zusätzlicher Flag-Optimierung und Feinabstimmung der Demontage. Alle Modelle übertreffen Llama 2 bei beiden Aufgaben immer noch.
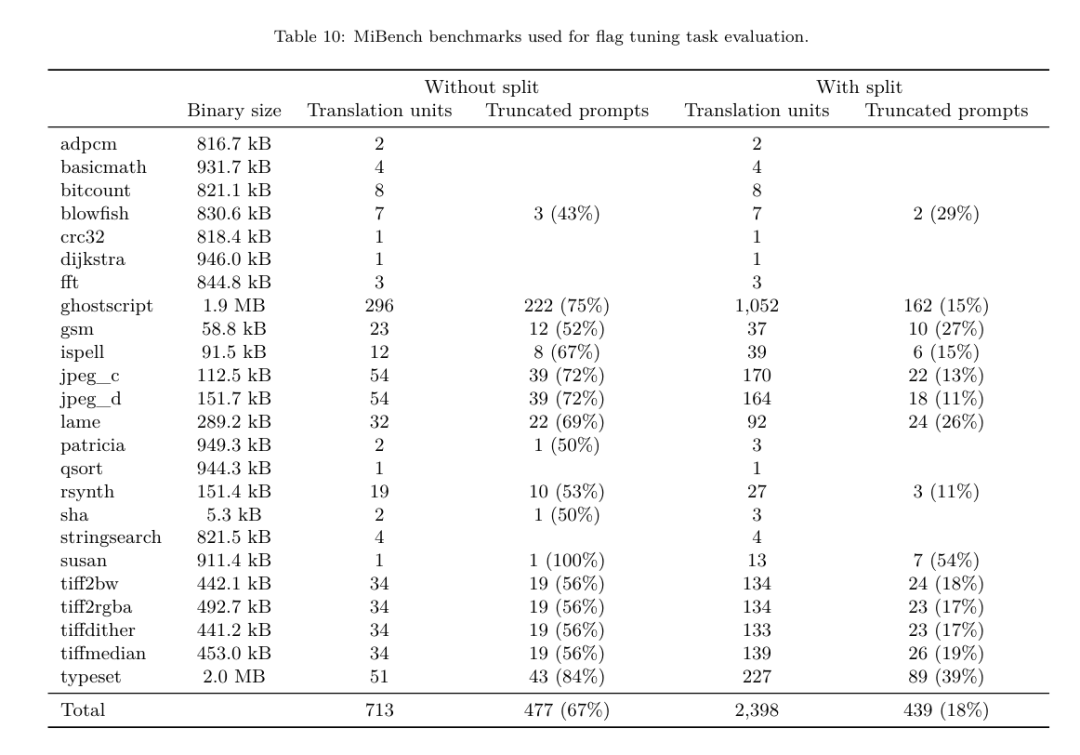
Methode. Das Forschungsteam bewertet die funktionale Korrektheit von LLM-generiertem Code bei der Zerlegung von Assembler-Code in LLVM-IR. Sie evaluieren den LLM Compiler FTD und vergleichen ihn mit Code Llama – Instruct und GPT-4 Turbo und stellen fest, dass zusätzliche Hinweissuffixe erforderlich sind, um die beste Leistung aus diesen Modellen herauszuholen. Das Suffix bietet zusätzlichen Kontext zur Aufgabe und zum erwarteten Ausgabeformat. Um die Leistung des Modells zu bewerten, stuften sie die vom Modell erzeugte Demontage-IR zurück auf die Montage herab. Dadurch können wir die Genauigkeit der Demontage bewerten, indem wir die BLEU-Werte der Originalbaugruppe mit den Round-Trip-Ergebnissen vergleichen.Eine verlustfreie, perfekte Demontage von der Montage zur IR hat einen Round-Trip-BLEU-Score von 1,0 (exakte Übereinstimmung). Datensatz. Sie evaluierten anhand von 2.015 Testhinweisen, die aus der MiBench-Benchmark-Suite extrahiert wurden, und nutzten die 2.398 Übersetzungseinheiten, die für die obige Flag-Tuning-Bewertung verwendet wurden, um Demontagehinweise zu generieren. Anschließend filterten sie die Tipps basierend auf der maximalen 8.000-Token-Länge und ließen 8.000 Token für die Modellausgabe zu, so dass 2.015 übrig blieben. Tabelle 11 fasst die Benchmarks zusammen. Ergebnisse. Tabelle 5 zeigt die Leistung des Modells bei der Demontageaufgabe. LLM Compiler FTD 7B hat eine etwas höhere Round-Trip-Erfolgsrate als LLM Compiler FTD 13B, aber LLM Compiler FTD 13B hat die höchste Round-Trip-Assembly-Genauigkeit (Round-Trip BLEU) und produziert am häufigsten perfekte Disassemblierungen ( genaue Hin- und Rückfahrt-Übereinstimmung). Code Llama – Instruct und GPT-4 Turbo haben Schwierigkeiten, syntaktisch korrektes LLVM-IR zu generieren. Abbildung 8 zeigt die Verteilung der Round-Trip-BLEU-Scores für alle Modelle. Ablationsforschung. Tabelle 6 zeigt eine Ablationsstudie zur Leistung des Modells anhand eines kleinen Hold-out-Validierungssatzes von 500 Hinweisen, der dem zuvor verwendeten MiBench-Datensatz entnommen wurde. Sie führten in jeder Phase der in Abbildung 1 gezeigten Trainingspipeline ein Demontagetraining durch, um die Leistung zu vergleichen. Die Roundtrip-Rate ist beim Durchlaufen des gesamten Trainingsdatenstapels am höchsten und nimmt mit jeder Trainingsphase weiter ab, obwohl sich die Roundtrip-BLEU in jeder Phase kaum ändert. Grundlegende ModellaufgabeMethode. Das Forschungsteam führte Ablationsforschung am LLM-Compiler-Modell für zwei grundlegende Modellaufgaben durch: Vorhersage des nächsten Tokens und Compiler-Simulation. Sie führen diese Bewertung in jeder Phase der Trainingspipeline durch, um zu verstehen, wie sich das Training für jede aufeinanderfolgende Aufgabe auf die Leistung auswirkt. Für die Vorhersage des nächsten Tokens berechnen sie die Perplexität anhand einer kleinen Stichprobe von LLVM-IR und Assembler-Code auf allen Optimierungsebenen. Sie bewerten Compilersimulationen anhand von zwei Metriken: ob der generierte IR- oder Assemblercode kompiliert werden kann und ob der generierte IR- oder Assemblercode genau mit dem übereinstimmt, was der Compiler erzeugt. Datensatz. Für die Vorhersage des nächsten Tokens verwenden sie einen kleinen Holdout-Validierungsdatensatz aus derselben Verteilung wie unsere Trainingsdaten, der jedoch nicht für das Training verwendet wird. Sie verwenden eine Mischung aus Optimierungsstufen, einschließlich nicht optimiertem Code, mit -Oz optimiertem Code und zufällig generierten Passlisten. Für Compiler-Simulationen wurden sie anhand von 500 aus MiBench generierten Tipps unter Verwendung zufällig generierter Pass-Listen auf die in Abschnitt 2.2 beschriebene Weise ausgewertet. Ergebnisse. Tabelle 7 zeigt die Leistung von LLM Compiler FTD bei zwei Basismodell-Trainingsaufgaben (Vorhersage des nächsten Tokens und Compiler-Simulation) über alle Trainingsphasen hinweg. Die Leistung der nächsten Token-Vorhersage steigt nach Code Llama, der IR und Assemblierung kaum erkennt, stark an und sinkt mit jeder weiteren Feinabstimmungsstufe leicht. Bei Compiler-Simulationen erbringen das Code-Llama-Basismodell und vorab trainierte Modelle keine gute Leistung, da sie nicht für diese Aufgabe trainiert sind. Die maximale Leistung wird direkt nach dem Compiler-Simulationstraining erreicht, bei dem 95,6 % der vom LLM Compiler FTD 13B generierten IRs und Assemblys kompiliert werden und 20 % exakt mit dem Compiler übereinstimmen. Nach dem Flag-Tuning und der Feinabstimmung der Demontage sank die Leistung. Software-Engineering-AufgabenMethoden. Während der Zweck von LLM Compiler FTD darin besteht, ein Basismodell für die Codeoptimierung bereitzustellen, baut es auf dem Basismodell des Code Llama auf, das für Softwareentwicklungsaufgaben trainiert wurde. Um zu bewerten, wie sich zusätzliches Training des LLM Compiler FTD auf die Leistung der Codegenerierung auswirkt, verwendeten sie dieselbe Benchmark-Suite wie Code Llama, um die Fähigkeit von LLM zu bewerten, Python-Code aus Eingabeaufforderungen in natürlicher Sprache zu generieren, z. B. „Schreiben Sie eine Funktion, die die längste Kette findet.“ aus Mengenpaaren gebildet. Sie verwenden HumanEval- und MBPP-Benchmarks, genau wie Code Llama. Ergebnisse. Tabelle 8 zeigt die Greedy-Dekodierungsleistung (pass@1) für alle Modelltrainingsstufen und Modellgrößen ausgehend vom Code-Llama-Basismodell.Außerdem werden die Ergebnisse des Modells für bestanden@10 und bestanden@100 angezeigt, die mit p=0,95 und Temperatur=0,6 generiert wurden. Jede Compiler-zentrierte Trainingsphase führt zu einer leichten Verschlechterung der Python-Programmierfähigkeiten. Bei HumanEval und MBPP sank die Pass@1-Leistung des LLM-Compilers um bis zu 18 % bzw. 5 % und die LLM-Compiler-FTD sank um bis zu 29 % bzw. 22 % nach zusätzlicher Flag-Optimierung und Feinabstimmung der Demontage. Alle Modelle übertreffen Llama 2 bei beiden Aufgaben immer noch. 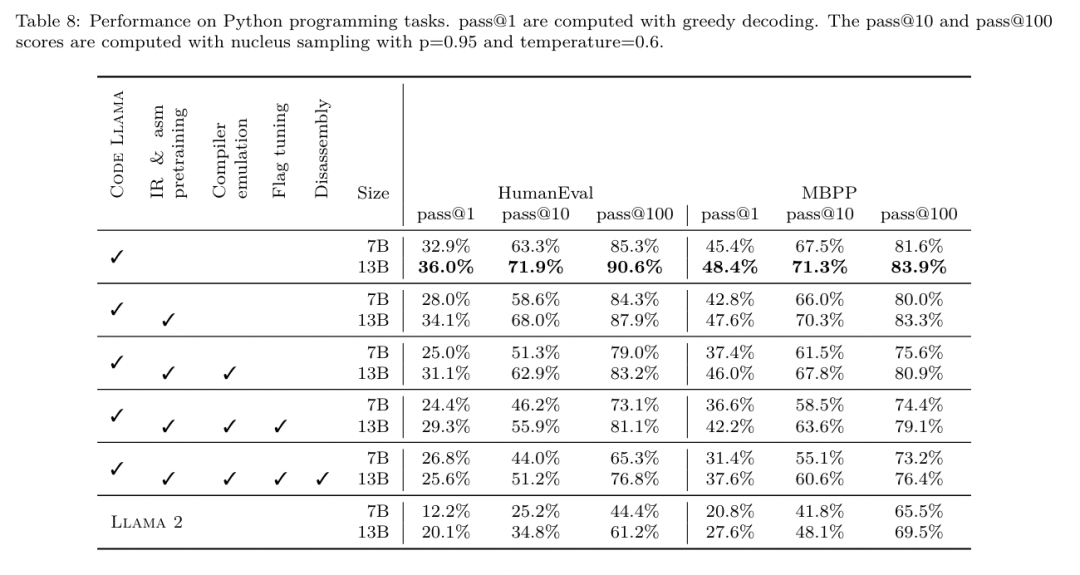 Das Meta-Forschungsteam hat gezeigt, dass der LLM-Compiler bei Compiler-Optimierungsaufgaben gut funktioniert und im Vergleich zu früheren Arbeiten ein besseres Verständnis der Compiler-Darstellung und des Assembler-Codes bietet. Es gibt jedoch immer noch einige Einschränkungen. Die Haupteinschränkung ist die begrenzte Sequenzlänge der Eingabe (Kontextfenster). LLM Compiler unterstützt ein Kontextfenster mit 16.000 Token, der Programmcode kann jedoch viel länger sein. Bei der Formatierung als Flag-Tuning-Tipp überschritten beispielsweise 67 % der MiBench-Übersetzungseinheiten dieses Kontextfenster, wie in Tabelle 10 dargestellt. Um dieses Problem zu lindern, teilen sie die größeren Übersetzungseinheiten in separate Funktionen auf, obwohl dies den Umfang der durchführbaren Optimierung einschränkt und immer noch 18 % der aufgeteilten Übersetzungseinheiten zu groß sind, als dass das Modell zu groß wäre als Eingabe akzeptiert werden. Forscher nutzen immer mehr Kontextfenster, begrenzte Kontextfenster bleiben jedoch ein häufiges Problem im LLM. Die zweite Einschränkung und ein allen LLMs gemeinsames Problem ist die Genauigkeit der Modellausgabe. Benutzern des LLM Compilers wird empfohlen, ihre Modelle mithilfe von Compiler-spezifischen Bewertungsbenchmarks zu bewerten. Da Compiler nicht fehlerfrei sind, müssen alle vorgeschlagenen Compiler-Optimierungen gründlich getestet werden. Wenn ein Modell in Assembler-Code dekompiliert wird, sollte seine Genauigkeit durch Roundtripping, manuelle Inspektion oder Unit-Tests bestätigt werden. Bei einigen Anwendungen kann die LLM-Generierung auf reguläre Ausdrücke beschränkt oder mit einer automatischen Validierung kombiniert werden, um die Korrektheit sicherzustellen. Referenzlink: Forschung/Veröffentlichungen/Meta -large-lingual-model-compiler-foundation-models-of-compiler-optimization/?utm_source=twitter&utm_medium=organic_social&utm_content=link&utm_campaign=fair
Das Meta-Forschungsteam hat gezeigt, dass der LLM-Compiler bei Compiler-Optimierungsaufgaben gut funktioniert und im Vergleich zu früheren Arbeiten ein besseres Verständnis der Compiler-Darstellung und des Assembler-Codes bietet. Es gibt jedoch immer noch einige Einschränkungen. Die Haupteinschränkung ist die begrenzte Sequenzlänge der Eingabe (Kontextfenster). LLM Compiler unterstützt ein Kontextfenster mit 16.000 Token, der Programmcode kann jedoch viel länger sein. Bei der Formatierung als Flag-Tuning-Tipp überschritten beispielsweise 67 % der MiBench-Übersetzungseinheiten dieses Kontextfenster, wie in Tabelle 10 dargestellt. Um dieses Problem zu lindern, teilen sie die größeren Übersetzungseinheiten in separate Funktionen auf, obwohl dies den Umfang der durchführbaren Optimierung einschränkt und immer noch 18 % der aufgeteilten Übersetzungseinheiten zu groß sind, als dass das Modell zu groß wäre als Eingabe akzeptiert werden. Forscher nutzen immer mehr Kontextfenster, begrenzte Kontextfenster bleiben jedoch ein häufiges Problem im LLM. Die zweite Einschränkung und ein allen LLMs gemeinsames Problem ist die Genauigkeit der Modellausgabe. Benutzern des LLM Compilers wird empfohlen, ihre Modelle mithilfe von Compiler-spezifischen Bewertungsbenchmarks zu bewerten. Da Compiler nicht fehlerfrei sind, müssen alle vorgeschlagenen Compiler-Optimierungen gründlich getestet werden. Wenn ein Modell in Assembler-Code dekompiliert wird, sollte seine Genauigkeit durch Roundtripping, manuelle Inspektion oder Unit-Tests bestätigt werden. Bei einigen Anwendungen kann die LLM-Generierung auf reguläre Ausdrücke beschränkt oder mit einer automatischen Validierung kombiniert werden, um die Korrektheit sicherzustellen. Referenzlink: Forschung/Veröffentlichungen/Meta -large-lingual-model-compiler-foundation-models-of-compiler-optimization/?utm_source=twitter&utm_medium=organic_social&utm_content=link&utm_campaign=fair
Das obige ist der detaillierte Inhalt vonEntwickler sind begeistert! Metas neueste Version des LLM Compilers erreicht eine automatische Optimierungseffizienz von 77 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn