
Heim >Technologie-Peripheriegeräte >KI >So laden Sie Llama 2 lokal herunter und installieren es
So laden Sie Llama 2 lokal herunter und installieren es

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-14 20:33:401090Durchsuche
Vor diesem Hintergrund haben wir eine Schritt-für-Schritt-Anleitung erstellt, wie Sie mit Text-Generation-WebUI ein quantisiertes Llama 2 LLM lokal auf Ihren Computer laden können.
Warum Llama 2 lokal installieren
Es gibt viele Gründe, warum sich Menschen dafür entscheiden, Llama 2 direkt auszuführen. Einige tun dies aus Datenschutzgründen, andere aus Gründen der Anpassung und wieder andere aus Gründen der Offline-Funktionalität. Wenn Sie Llama 2 für Ihre Projekte erforschen, verfeinern oder integrieren, ist der Zugriff auf Llama 2 über die API möglicherweise nicht das Richtige für Sie. Der Sinn der lokalen Ausführung eines LLM auf Ihrem PC besteht darin, die Abhängigkeit von KI-Tools von Drittanbietern zu verringern und KI jederzeit und überall zu nutzen, ohne sich Sorgen machen zu müssen, dass potenziell sensible Daten an Unternehmen und andere Organisationen weitergegeben werden.
Nachdem dies gesagt ist, beginnen wir mit der Schritt-für-Schritt-Anleitung zur lokalen Installation von Llama 2.
Schritt 1: Visual Studio 2019 Build Tool installieren
Zur Vereinfachung verwenden wir einen Ein-Klick-Installer für Text-Generation-WebUI (das Programm, das zum Laden von Llama 2 mit GUI verwendet wird). Damit dieses Installationsprogramm funktioniert, müssen Sie jedoch das Visual Studio 2019 Build Tool herunterladen und die erforderlichen Ressourcen installieren.
Herunterladen:Visual Studio 2019 (kostenlos)
Laden Sie die Community-Edition der Software herunter. Installieren Sie nun Visual Studio 2019 und öffnen Sie dann die Software. Aktivieren Sie nach dem Öffnen das Kontrollkästchen „Desktop-Entwicklung mit C++“ und klicken Sie auf „Installieren“.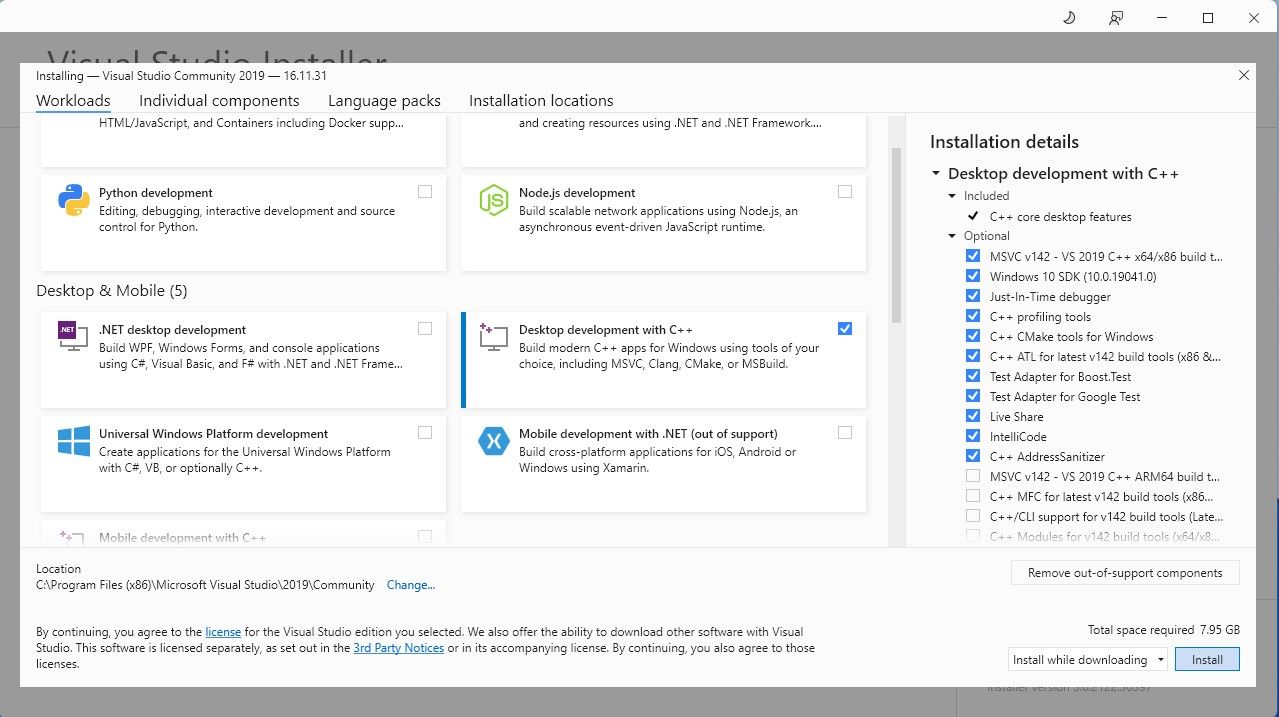
Da Sie nun die Desktop-Entwicklung mit C++ installiert haben, ist es an der Zeit, das Ein-Klick-Installationsprogramm für Text-Generation-WebUI herunterzuladen.
Schritt 2: Text-Generation-WebUI installieren
Der One-Click-Installer von Text-Generation-WebUI ist ein Skript, das automatisch die erforderlichen Ordner erstellt und die Conda-Umgebung sowie alle erforderlichen Anforderungen zum Ausführen eines KI-Modells einrichtet.
Um das Skript zu installieren, laden Sie das One-Click-Installationsprogramm herunter, indem Sie auf Code > klicken. ZIP herunterladen.
Download:Text-Generation-WebUI Installer (Kostenlos)
Nach dem Herunterladen extrahieren Sie die ZIP-Datei an Ihren bevorzugten Speicherort und öffnen Sie dann den extrahierten Ordner. Scrollen Sie im Ordner nach unten und suchen Sie nach dem passenden Startprogramm für Ihr Betriebssystem. Führen Sie die Programme aus, indem Sie auf das entsprechende Skript doppelklicken. Wenn Sie Windows verwenden, wählen Sie „start_windows“-Batchdatei für MacOS, „start_macos-Shell-Skript“ für Linux und „start_linux-Shell-Skript“.
Ihr Antivirenprogramm erstellt möglicherweise eine Warnung; das ist in Ordnung. Bei der Eingabeaufforderung handelt es sich lediglich um einen Antiviren-False-Positive-Test für die Ausführung einer Batchdatei oder eines Skripts. Klicken Sie auf „Trotzdem ausführen“. Ein Terminal öffnet sich und startet die Einrichtung. Zu Beginn pausiert das Setup und fragt Sie, welche GPU Sie verwenden. Wählen Sie den entsprechenden GPU-Typ aus, der auf Ihrem Computer installiert ist, und drücken Sie die Eingabetaste. Für diejenigen ohne dedizierte Grafikkarte wählen Sie „Keine“ (ich möchte Modelle im CPU-Modus ausführen). Beachten Sie, dass die Ausführung im CPU-Modus viel langsamer ist als die Ausführung des Modells mit einer dedizierten GPU.
 Sobald die Einrichtung abgeschlossen ist, können Sie Text-Generation-WebUI jetzt lokal starten. Sie können dies tun, indem Sie Ihren bevorzugten Webbrowser öffnen und die bereitgestellte IP-Adresse in die URL eingeben.
Sobald die Einrichtung abgeschlossen ist, können Sie Text-Generation-WebUI jetzt lokal starten. Sie können dies tun, indem Sie Ihren bevorzugten Webbrowser öffnen und die bereitgestellte IP-Adresse in die URL eingeben. Die WebUI ist jetzt einsatzbereit.
Die WebUI ist jetzt einsatzbereit.
Das Programm ist jedoch nur ein Modelllader. Laden wir Llama 2 herunter, damit der Modelllader startet.
Schritt 3: Laden Sie das Llama 2-Modell herunter
Bei der Entscheidung, welche Version von Llama 2 Sie benötigen, müssen einige Dinge berücksichtigt werden. Dazu gehören Parameter, Quantisierung, Hardwareoptimierung, Größe und Nutzung. Alle diese Informationen finden Sie im Namen des Modells.
Parameter: Die Anzahl der Parameter, die zum Trainieren des Modells verwendet werden. Größere Parameter machen leistungsfähigere Modelle, allerdings auf Kosten der Leistung. Verwendung: Kann entweder Standard oder Chat sein. Ein Chat-Modell ist für die Verwendung als Chatbot wie ChatGPT optimiert, während der Standard das Standardmodell ist. Hardwareoptimierung: Bezieht sich darauf, welche Hardware das Modell am besten ausführt. GPTQ bedeutet, dass das Modell für die Ausführung auf einer dedizierten GPU optimiert ist, während GGML für die Ausführung auf einer CPU optimiert ist. Quantisierung: Bezeichnet die Präzision von Gewichten und Aktivierungen in einem Modell. Für die Inferenzierung ist eine Genauigkeit von q4 optimal. Größe: Bezieht sich auf die Größe des jeweiligen Modells.Beachten Sie, dass einige Modelle möglicherweise anders angeordnet sind und möglicherweise nicht einmal die gleichen Arten von Informationen angezeigt werden. Allerdings ist diese Art der Namenskonvention in der HuggingFace-Modellbibliothek ziemlich verbreitet, sodass es sich dennoch lohnt, sie zu verstehen.

In diesem Beispiel kann das Modell als mittelgroßes Llama-2-Modell identifiziert werden, das auf 13 Milliarden Parametern trainiert wurde, die für die Chat-Inferenz unter Verwendung einer dedizierten CPU optimiert wurden.
Wählen Sie für diejenigen, die eine dedizierte GPU verwenden, ein GPTQ-Modell, während Sie für diejenigen, die eine CPU verwenden, GGML wählen. Wenn Sie mit dem Modell wie mit ChatGPT chatten möchten, wählen Sie „Chat“. Wenn Sie jedoch mit dem Modell mit allen Funktionen experimentieren möchten, verwenden Sie das Standardmodell. Was die Parameter angeht, sollten Sie wissen, dass die Verwendung größerer Modelle bessere Ergebnisse auf Kosten der Leistung liefert. Ich persönlich würde Ihnen empfehlen, mit einem 7B-Modell zu beginnen. Verwenden Sie für die Quantisierung q4, da dies nur der Schlussfolgerung dient.
Download:GGML (Kostenlos)
Download:GPTQ (Kostenlos)
Nachdem Sie nun wissen, welche Version von Llama 2 Sie benötigen, laden Sie das gewünschte Modell herunter.
In meinem Fall verwende ich, da ich dies auf einem Ultrabook verwende, ein für den Chat optimiertes GGML-Modell, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
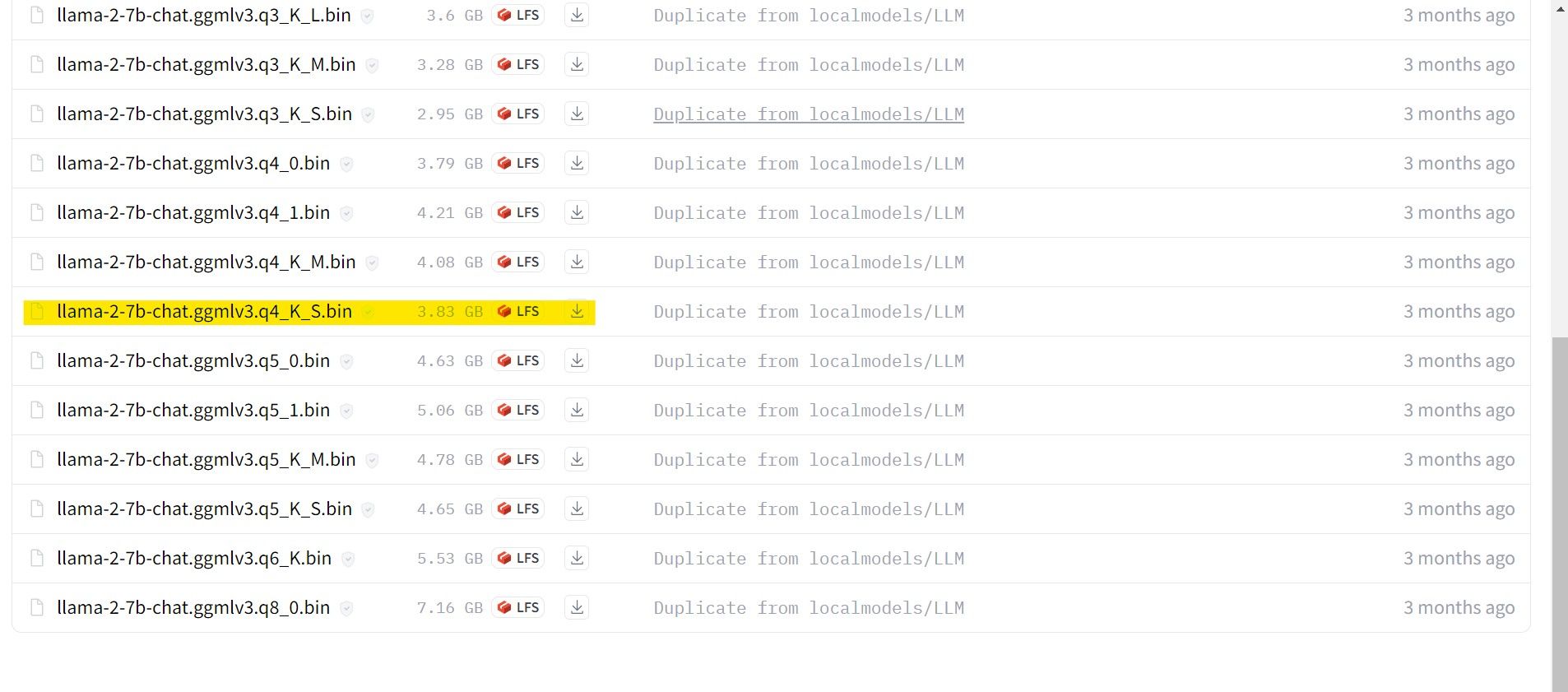
Nachdem der Download abgeschlossen ist, platzieren Sie das Modell in text-generation-webui-main > Modelle.

Nachdem Sie nun Ihr Modell heruntergeladen und im Modellordner abgelegt haben, ist es an der Zeit, den Modelllader zu konfigurieren.
Schritt 4: Text-Generierung-WebUI konfigurieren
Jetzt beginnen wir mit der Konfigurationsphase.
Öffnen Sie Text-Generation-WebUI noch einmal, indem Sie die Datei start_(Ihr Betriebssystem) ausführen (siehe die vorherigen Schritte oben). Klicken Sie auf den Registerkarten oberhalb der GUI auf Modell. Klicken Sie im Modell-Dropdown-Menü auf die Schaltfläche „Aktualisieren“ und wählen Sie Ihr Modell aus. Klicken Sie nun auf das Dropdown-Menü des Modellladers und wählen Sie AutoGPTQ für diejenigen, die ein GTPQ-Modell verwenden, und ctransformers für diejenigen, die ein GGML-Modell verwenden. Klicken Sie abschließend auf „Laden“, um Ihr Modell zu laden. Um das Modell zu verwenden, öffnen Sie die Registerkarte „Chat“ und beginnen Sie mit dem Testen des Modells.
Um das Modell zu verwenden, öffnen Sie die Registerkarte „Chat“ und beginnen Sie mit dem Testen des Modells.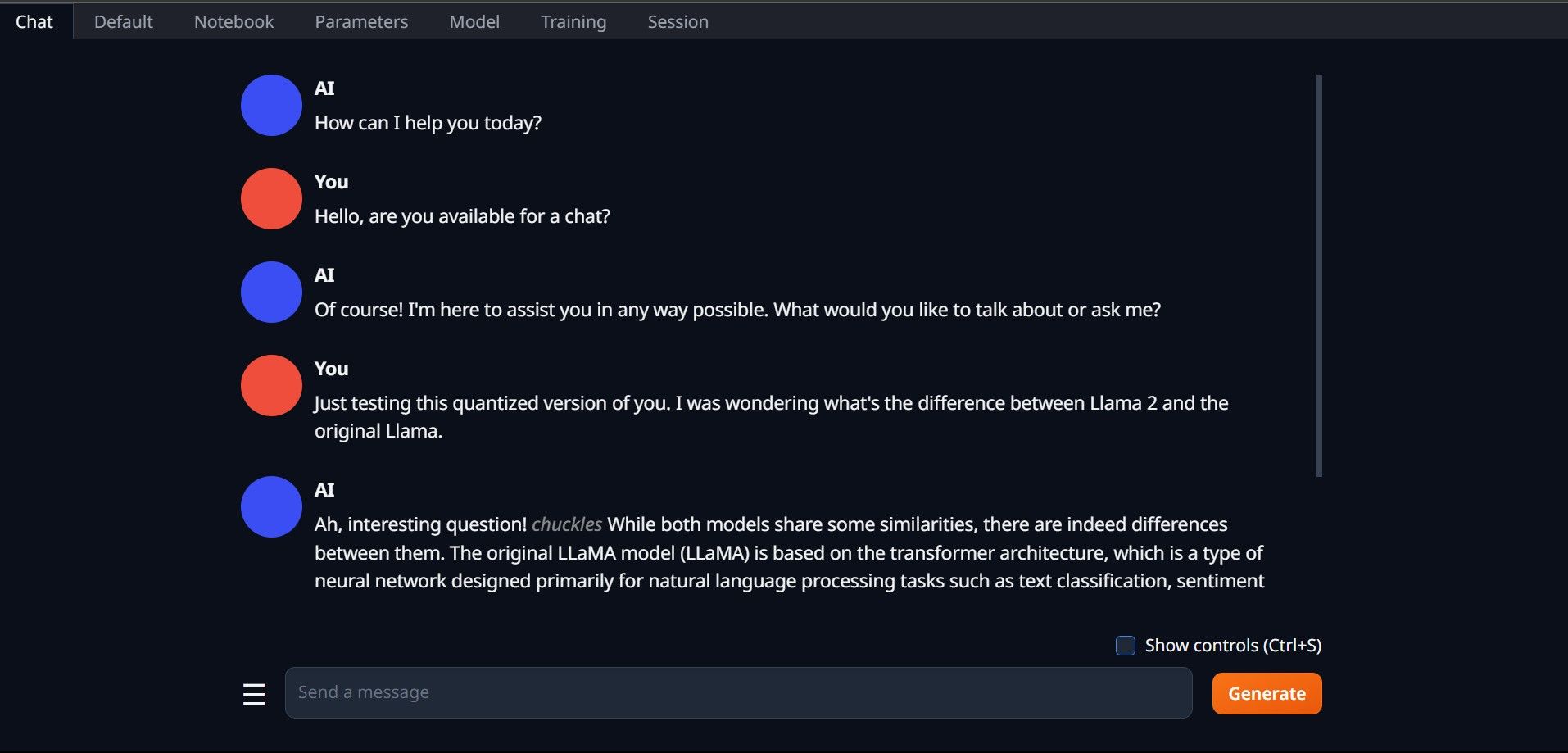
Herzlichen Glückwunsch, Sie haben Llama2 erfolgreich auf Ihren lokalen Computer geladen!
Probieren Sie andere LLMs aus
Nachdem Sie nun wissen, wie Sie Llama 2 mit Text-Generation-WebUI direkt auf Ihrem Computer ausführen, sollten Sie neben Llama auch andere LLMs ausführen können. Denken Sie nur an die Namenskonventionen von Modellen und daran, dass nur quantisierte Versionen von Modellen (normalerweise q4-Präzision) auf normale PCs geladen werden können. Viele quantisierte LLMs sind auf HuggingFace verfügbar. Wenn Sie andere Modelle erkunden möchten, suchen Sie in der Modellbibliothek von HuggingFace nach TheBloke. Dort sollten viele Modelle verfügbar sein.
Das obige ist der detaillierte Inhalt vonSo laden Sie Llama 2 lokal herunter und installieren es. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr