
Heim >Technologie-Peripheriegeräte >KI >Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct

- PHPzOriginal
- 2024-06-13 13:59:561582Durchsuche
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an.
Diese innovative Errungenschaft hat einen bedeutenden Durchbruch bei der Codegenerierungsaufgabe erzielt, CodeLlama-70B-Instruct erfolgreich übertroffen und die Spitze der Codegenerierungsleistungsliste erreicht.

Die Einzigartigkeit von StarCoder2-15B-Instruct ist seine reine Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar.
Das Modell generiert Tausende von Anweisungen über StarCoder2-15B und passt das StarCoder-15B-Basismodell als Reaktion darauf an. Es ist nicht auf teure manuelle Annotationen von Daten angewiesen und muss auch keine Daten von kommerziellen Großunternehmen beziehen Modelle wie GPT4, wodurch potenzielle Urheberrechtsprobleme vermieden werden.
Im HumanEval-Test stach StarCoder2-15B-Instruct mit einem Pass@1-Score von 72,6 % hervor, der gegenüber 72,0 % von CodeLlama-70B-Instruct verbessert wurde.
Bei der Auswertung des LiveCodeBench-Datensatzes übertraf dieses selbstausrichtende Modell sogar ähnliche Modelle, die auf GPT-4-generierten Daten trainiert wurden. Dieses Ergebnis zeigt, dass ein großes Modell auch effektiv lernen kann, sich ähnlich wie Menschen auszurichten, indem es Daten innerhalb seiner eigenen Verteilung verwendet, ohne sich auf die voreingenommene Verteilung des großen Modells von einem externen Lehrer verlassen zu müssen.
Die erfolgreiche Umsetzung dieses Projekts erhielt starke Unterstützung von Arjun Guhas Forschungsgruppe an der Northeastern University, der University of California, Berkeley, ServiceNow und Hugging Face sowie anderen Institutionen.
Technologie enthüllt
Der Datengenerierungsprozess von StarCoder2-Instruct umfasst hauptsächlich drei Kernschritte:
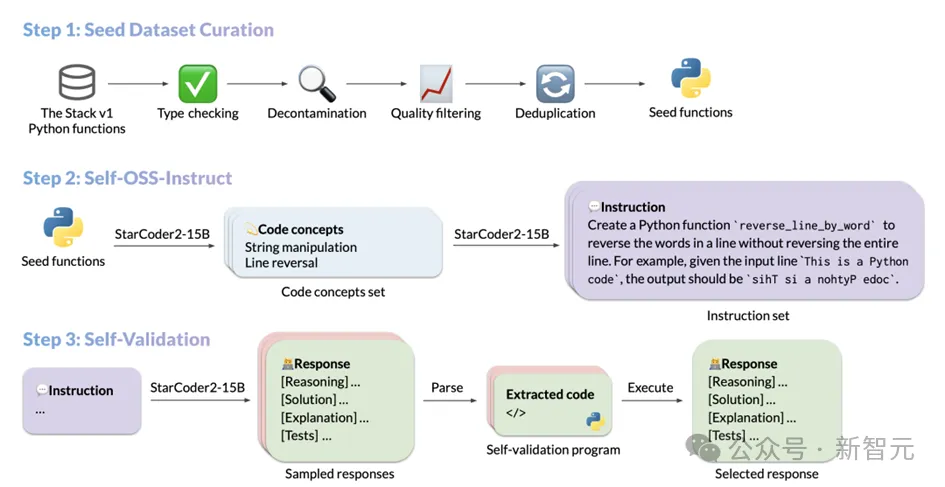
1. Sammlung von Seed-Code-Snippets: Das Team von The Stapel v1 Filtern Sie hochwertige, vielfältige Seed-Funktionen aus einem riesigen Korpus lizenzierten Quellcodes heraus. Durch strikte Filterung und Überprüfung wird die Qualität und Vielfalt des Seed-Codes sichergestellt und realistische Codeanweisungen. Diese Anweisungen decken ein breites Spektrum an Programmierszenarien ab, von der Datendeserialisierung bis zur Listenverkettung, Rekursion usw.; geführte Selbstverifizierungsmethode, die sicherstellt, dass die generierten Antworten korrekt und von hoher Qualität sind.
Die spezifischen Vorgänge jedes Schritts sind wie folgt: Der Prozess der Auswahl von Seed-Code-Snippets
Um die Fähigkeit des Codemodells, Anweisungen zu befolgen, zu verbessern, muss das Modell umfassend offengelegt werden verschiedene Programmierprinzipien anhand praktischer Abläufe kennen und erlernen. StarCoder2-15B-Instruct ist von OSS-Instruct inspiriert und lässt sich von Open-Source-Code-Snippets inspirieren, insbesondere von den gut formatierten und klar strukturierten Python-Seed-Funktionen in The Stack V1.
Beim Aufbau seines Basisdatensatzes führte StarCoder2-15B-Instruct eine eingehende Untersuchung von The Stack V1 durch, wählte alle Python-Funktionen mit dokumentierten Anweisungen aus und analysierte und leitete automatisch die von diesen Funktionen benötigten Funktionen mithilfe von ab die Autoimport-Funktion Abhängigkeiten.Um die Reinheit und hohe Qualität des Datensatzes sicherzustellen, hat StarCoder2-15B-Instruct alle ausgewählten Funktionen sorgfältig gefiltert und überprüft.
Zunächst wird eine strenge Typprüfung durch den Pyright-Typprüfer durchgeführt, wobei alle Funktionen ausgeschlossen werden, die statische Fehler erzeugen können, wodurch die Genauigkeit und Zuverlässigkeit der Daten sichergestellt wird.
Dann werden durch präzise String-Matching-Technologie Codes und Hinweise, die potenziell mit dem Bewertungsdatensatz in Zusammenhang stehen, identifiziert und eliminiert, um eine Datenkontamination zu vermeiden. Im Hinblick auf die Dokumentqualität nutzt StarCoder2-15B-Instruct einen einzigartigen Überprüfungsmechanismus.
Es verwendet seine eigenen Bewertungsfunktionen, um dem Modell 7 Beispielaufforderungen anzuzeigen, sodass das Modell beurteilen kann, ob die Dokumentqualität jeder Funktion dem Standard entspricht, und so entscheiden kann, ob sie in den endgültigen Datensatz aufgenommen werden soll.
Diese auf Modellselbstbeurteilung basierende Methode verbessert nicht nur die Effizienz und Genauigkeit des Datenscreenings, sondern gewährleistet auch die hohe Qualität und Konsistenz des Datensatzes.
Um Datenredundanz und -duplizierung zu vermeiden, verwendet StarCoder2-15B-Instruct schließlich MinHash und ortsabhängige Hashing-Algorithmen, um Funktionen im Datensatz zu deduplizieren. Durch Festlegen eines Jaccard-Ähnlichkeitsschwellenwerts von 0,5 werden doppelte Funktionen mit hoher Ähnlichkeit effektiv entfernt, wodurch die Einzigartigkeit und Vielfalt des Datensatzes sichergestellt wird.
Nach dieser Reihe feiner Prüfungen und Filterungen wählte StarCoder2-15B-Instruct schließlich 250.000 hochwertige Funktionen aus 5 Millionen Python-Funktionen mit Dokumenten als Ausgangsdatensatz aus. Dieser Ansatz ist stark vom MultiPL-T-Datenerfassungsprozess inspiriert.
Generierung verschiedener Anweisungen
Als StarCoder2-15B-Instruct die Sammlung von Seed-Funktionen abschloss, nutzte es die Self-OSS-Instruct-Technologie, um verschiedene Programmieranweisungen zu erstellen. Der Kern dieser Technologie besteht darin, das StarCoder2-15B-Basismodell in die Lage zu versetzen, durch kontextuelles Lernen autonom entsprechende Anweisungen für ein bestimmtes Seed-Codefragment zu generieren.
Um dieses Ziel zu erreichen, hat StarCoder2-15B-Instruct sorgfältig 16 Beispiele entworfen, jedes Beispiel folgt der Struktur von (Codeausschnitte, Konzepte, Anweisungen). Der Befehlsgenerierungsprozess ist in zwei Phasen unterteilt:
Identifizierung des Codekonzepts: In dieser Phase führt StarCoder2-15B eine eingehende Analyse jeder Seed-Funktion durch und generiert eine Liste mit den wichtigsten Codekonzepten in der Funktion. Diese Konzepte decken im Großen und Ganzen die Grundprinzipien und Techniken im Bereich der Programmierung ab, wie z. B. Mustervergleich, Datentypkonvertierung usw., die für Entwickler von äußerst hohem praktischen Wert sind.
Anweisungserstellung: Basierend auf dem anerkannten Codekonzept generiert StarCoder2-15B weiterhin entsprechende Anweisungen für Codierungsaufgaben. Dieser Prozess soll sicherstellen, dass die generierten Anweisungen die Kernfunktionalität und Anforderungen des Codefragments genau widerspiegeln.
Durch den oben genannten Prozess hat StarCoder2-15B-Instruct schließlich erfolgreich bis zu 238.000 Anweisungen generiert, was seinen Trainingsdatensatz erheblich bereichert und seine Leistung bei Programmieraufgaben stark unterstützt.
Selbstverifizierungsmechanismus der Antwort
Nach Erhalt der von Self-OSS-Instruct generierten Anweisungen besteht die Hauptaufgabe von StarCoder2-15B-Instruct darin, für jede Anweisung eine qualitativ hochwertige Antwort zuzuordnen .
Traditionell neigen Menschen dazu, sich auf leistungsfähigere Lehrermodelle wie GPT-4 zu verlassen, um diese Antworten zu erhalten, aber dieser Ansatz kann nicht nur mit Schwierigkeiten bei der Urheberrechtslizenzierung konfrontiert sein, sondern externe Modelle sind auch nicht immer erreichbar oder genau. Noch wichtiger ist, dass die Verwendung externer Modelle zu Verteilungsunterschieden zwischen Lehrern und Schülern führen kann, die sich auf die Genauigkeit der Endergebnisse auswirken können.
Um diese Herausforderungen zu meistern, führt StarCoder2-15B-Instruct einen Selbstverifizierungsmechanismus ein. Die Kernidee dieses Mechanismus besteht darin, das StarCoder2-15B-Modell nach dem Generieren einer Antwort in natürlicher Sprache selbst entsprechende Testfälle erstellen zu lassen. Dieser Prozess ähnelt dem Selbsttestprozess, den ein Entwickler nach dem Schreiben von Code durchläuft.
Konkret generiert StarCoder2-15B für jede Anweisung 10 Beispiele mit Antworten in natürlicher Sprache und entsprechenden Testfällen. StarCoder2-15B-Instruct führt diese Testfälle dann in einer Sandbox-Umgebung aus, um die Gültigkeit der Antworten zu überprüfen. Alle Proben, die bei der Ausführung des Tests fehlschlagen, werden herausgefiltert.
Nach diesem strengen Screening-Prozess wählt StarCoder2-15B-Instruct zufällig eine der getesteten Antworten jeder Anweisung aus und fügt sie dem endgültigen SFT-Datensatz hinzu. Während des gesamten Prozesses generierte StarCoder2-15B-Instruct insgesamt 2,4 Millionen Antwortproben (10 Proben pro Anweisung) für 238.000 Anweisungen. Nach der Einführung einer Stichprobenstrategie von 0,7 haben 500.000 Stichproben den Ausführungstest erfolgreich bestanden.
Um die Vielfalt und Qualität des Datensatzes sicherzustellen, führt StarCoder2-15B-Instruct auch eine Deduplizierungsverarbeitung durch. Am Ende blieben 50.000 Befehle übrig, jeder mit einer zufällig ausgewählten, getesteten und verifizierten Antwort von hoher Qualität. Diese Antworten bilden den endgültigen SFT-Datensatz von StarCoder2-15B-Instruct und bieten eine solide Grundlage für das anschließende Training und die Anwendung des Modells.
Hervorragende Leistung und umfassende Bewertung von StarCoder2-15B-Instruct
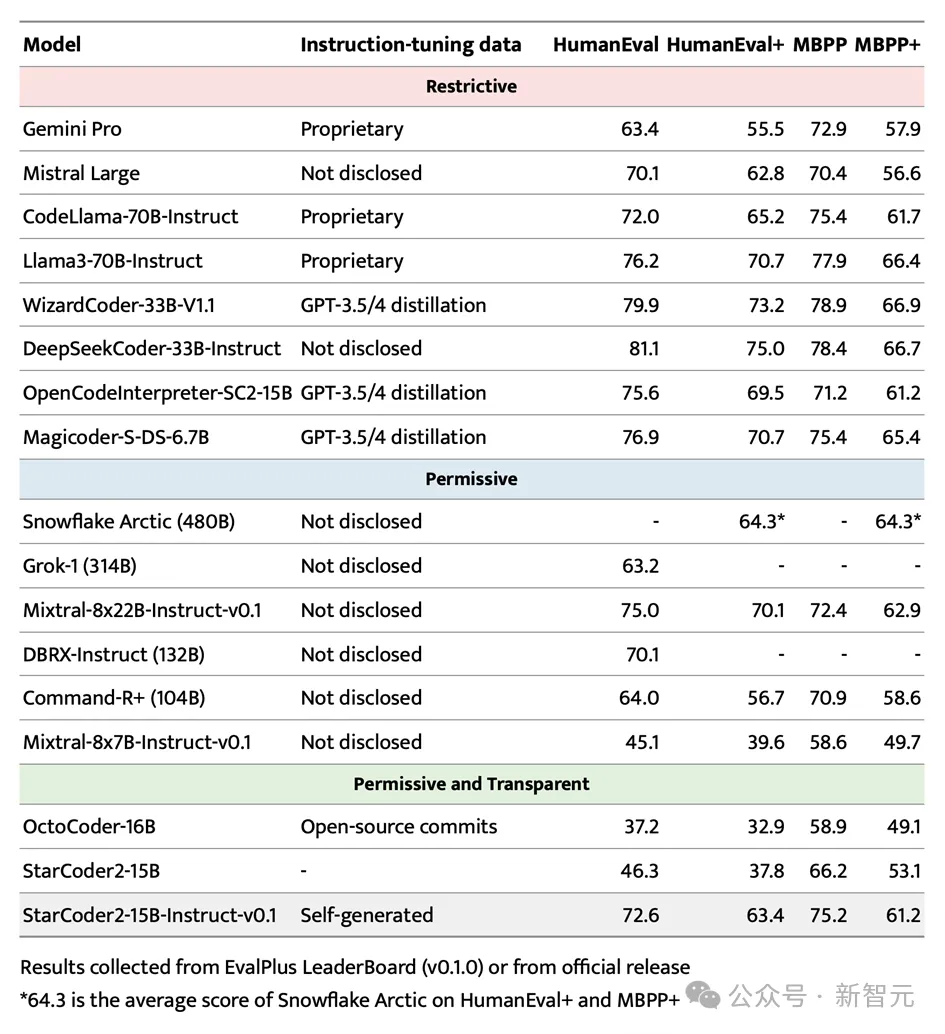
Im hochkarätigen EvalPlus-Benchmark-Test stach StarCoder2-15B-Instruct erfolgreich hervor und wurde aufgrund seiner Skalenvorteile zum leistungsstärksten autonomen System . Steuerbare große Modelle.
Es übertrifft nicht nur die größeren Grok-1 Command-R+ und DBRX, sondern kann auch mit Branchenführern wie Snowflake Arctic 480B und Mixtral-8x22B-Instruct mithalten.
Erwähnenswert ist, dass StarCoder2-15B-Instruct das erste große unabhängige Codemodell ist, das beim HumanEval-Benchmark eine Punktzahl von 70+ erreicht. Sein Trainingsprozess ist völlig transparent und die Verwendung von Daten und Methoden entspricht den Gesetzen und Vorschriften .
Im Bereich der unabhängig steuerbaren Code-Großmodelle hat StarCoder2-15B-Instruct den bisherigen Spitzenreiter OctoCoder deutlich übertroffen und damit seine führende Position in diesem Bereich unter Beweis gestellt.
Selbst im Vergleich zu großen und leistungsstarken Modellen mit eingeschränkten Lizenzen wie Gemini Pro und Mistral Large zeigt StarCoder2-15B-Instruct immer noch eine hervorragende Leistung und liegt auf Augenhöhe mit CodeLlama-70B-Instruct. Noch bemerkenswerter ist, dass StarCoder2-15B-Instruct beim Training vollständig auf selbst generierte Daten setzt, seine Leistung jedoch mit OpenCodeInterpreter-SC2-15B vergleichbar ist, der auf der Feinabstimmung der GPT-3.5/4-Daten basiert.
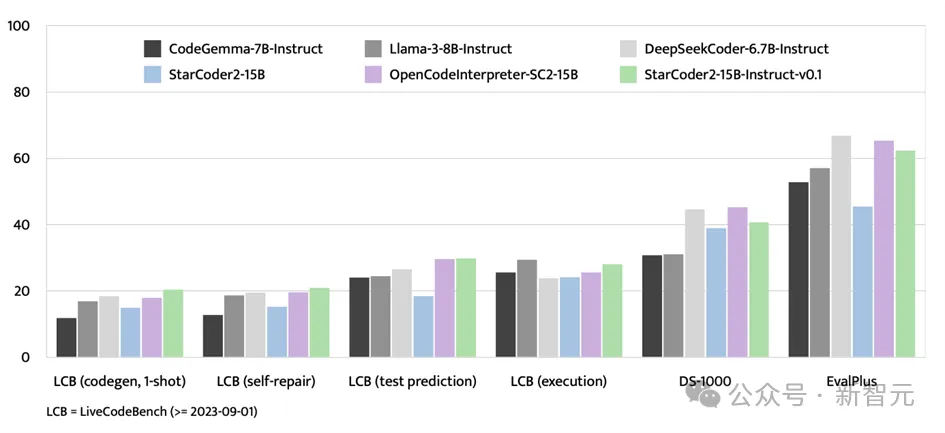
Neben dem EvalPlus-Benchmark-Test zeigte StarCoder2-15B-Instruct auch starke Stärken auf Bewertungsplattformen wie LiveCodeBench und DS-1000.
LiveCodeBench konzentriert sich auf die Bewertung von Codierungsherausforderungen, die nach dem 1. September 2023 auftreten, und StarCoder2-15B-Instruct erzielt bei diesem Benchmark die besten Ergebnisse und liegt durchweg vor dem mithilfe von GPT-4-Daten optimierten OpenCodeInterpreter -SC2-15B
Obwohl sich DS-1000 auf datenwissenschaftliche Aufgaben konzentriert, schneidet StarCoder2-15B-Instruct bei diesem Benchmark immer noch gut ab und zeigt relativ wenige datenwissenschaftliche Probleme in den Trainingsdaten. Breite Anpassungsfähigkeit und Wettbewerbsfähigkeit.
StarCoder2-15B-Instruct-v0.1 Durchbrüche und Erleuchtungen
Die Veröffentlichung von StarCoder2-15B-Instruct-v0.1 markiert den Fortschritt von Forschern bei der Selbstoptimierung von Codemodellen Im Bereich Exzellenz wurde ein wichtiger Schritt getan. Die erfolgreiche Umsetzung dieses Modells durchbricht die bisherige Einschränkung, sich auf leistungsstarke externe Lehrermodelle wie GPT-4 verlassen zu müssen, und zeigt, dass Codemodelle mit hervorragender Leistung auch durch Selbstoptimierung erstellt werden können.
Der Kern von StarCoder2-15B-Instruct-v0.1 liegt in der erfolgreichen Anwendung seiner Selbstausrichtungsstrategie im Bereich des Code-Lernens. Diese Strategie verbessert nicht nur die Leistung des Modells, sondern, was noch wichtiger ist, sie verleiht dem Modell mehr Transparenz und Interpretierbarkeit. Dies steht im krassen Gegensatz zu anderen großen Modellen wie Snowflake-Arctic, Grok-1, Mixtral-8x22B, DBRX und CommandR+, die zwar leistungsstark sind, aufgrund mangelnder Transparenz jedoch häufig ihren Umfang und ihre Vertrauenswürdigkeit einschränken.
Was noch erfreulicher ist, ist, dass StarCoder2-15B-Instruct-v0.1 seinen Datensatz und den gesamten Trainingsprozess – einschließlich Datenerfassung und Trainingsprozess – vollständig Open Source gemacht hat. Dieser Schritt zeigt nicht nur die Offenheit der Forscher, sondern legt auch eine solide Grundlage für zukünftige Forschung und Entwicklung auf diesem Gebiet.
Es gibt Grund zu der Annahme, dass die erfolgreiche Praxis von StarCoder2-15B-Instruct-v0.1 mehr Forscher dazu inspirieren wird, in die Forschung im Bereich der Selbstoptimierung von Codemodellen zu investieren und den technologischen Fortschritt und die Anwendungserweiterung in diesem Bereich voranzutreiben Feld. Gleichzeitig erwarten wir, dass auf diesem Gebiet weiterhin innovativere Ergebnisse erzielt werden, die der intelligenten Entwicklung der menschlichen Gesellschaft neue Impulse verleihen.
Über den Autor
Lehrer Zhang Lingming von der UIUC ist ein Wissenschaftler mit fundierten Kenntnissen in der Schnittstelle von Softwareentwicklung, Programmiersprache und maschinellem Lernen. Die von ihm geleitete Forschungsgruppe widmet sich seit langem der Forschung zur automatischen Softwaresynthese, -reparatur und -verifizierung auf der Grundlage großer KI-Modelle sowie der Verbesserung der Zuverlässigkeit maschineller Lernsysteme.
Kürzlich hat das Team eine Reihe innovativer großer Codemodelle und Test-Benchmark-Datensätze veröffentlicht und die Führung beim Vorschlag einer Reihe großer modellbasierter Softwaretest- und Reparaturtechnologien übernommen. Gleichzeitig wurden Tausende neuer Fehler und Lücken in mehreren realen Softwaresystemen erfolgreich entdeckt, was erheblich zur Verbesserung der Softwarequalität beitrug.
Das obige ist der detaillierte Inhalt vonKeine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!