
Heim >Technologie-Peripheriegeräte >KI >Ilyas erste Aktion, nachdem er seinen Job aufgegeben hatte: Mir gefiel diese Zeitung, und die Internetnutzer beeilten sich, sie zu lesen
Ilyas erste Aktion, nachdem er seinen Job aufgegeben hatte: Mir gefiel diese Zeitung, und die Internetnutzer beeilten sich, sie zu lesen

- PHPzOriginal
- 2024-06-12 11:22:14750Durchsuche
Seit Ilya Sutskever offiziell seinen Rücktritt von OpenAI bekannt gegeben hat, ist sein nächster Schritt in den Mittelpunkt aller Aufmerksamkeit gerückt.
Manche Leute achten sogar genau auf jede seiner Bewegungen.
Nein, Ilya mochte ❤️ einfach eine neue Arbeit –
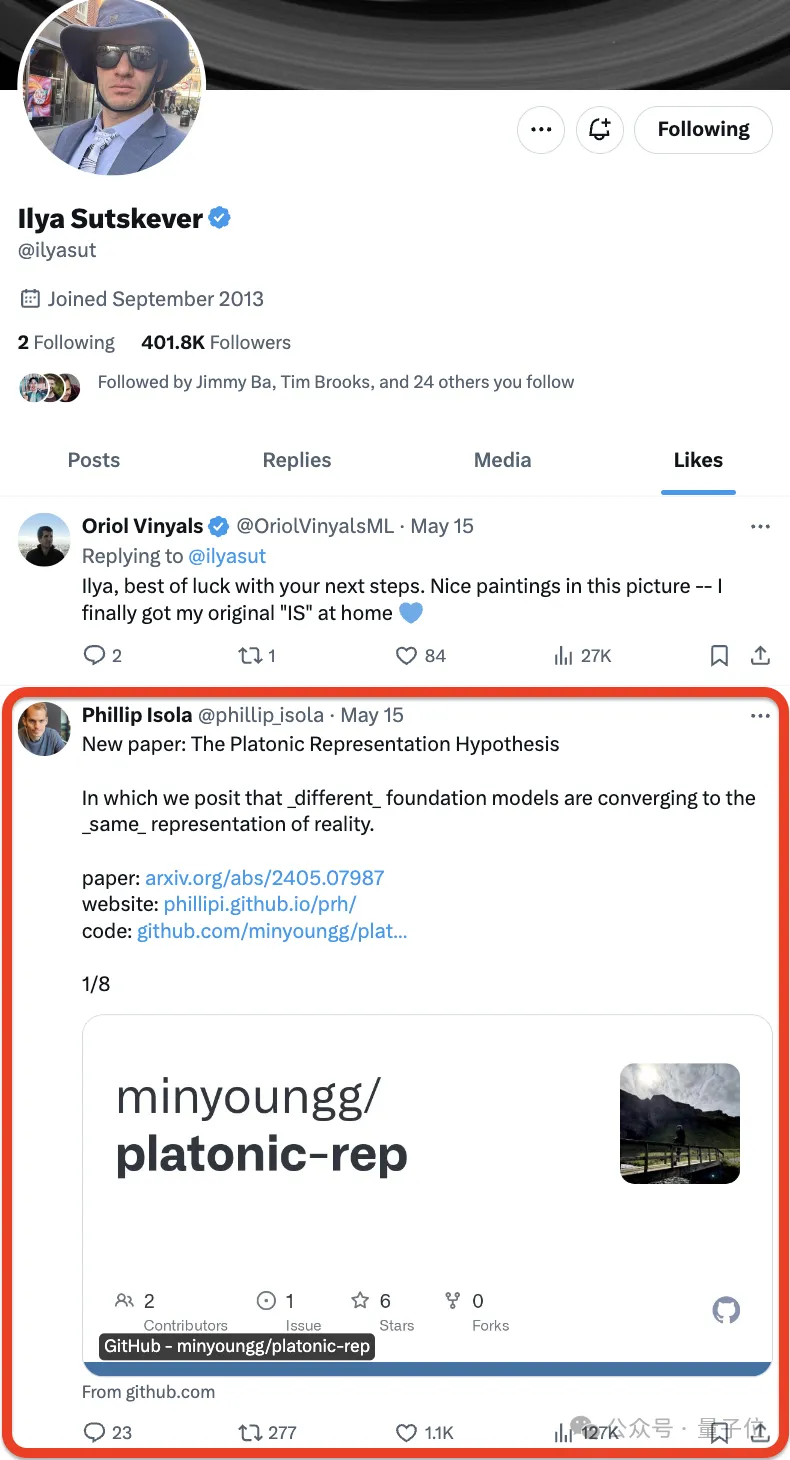
– und die Internetnutzer beeilten sich, sie zu mögen:

Die Arbeit kommt vom MIT, der Autor schlug eine Hypothese vor, die lässt sich in einem Satz wie folgt zusammenfassen:
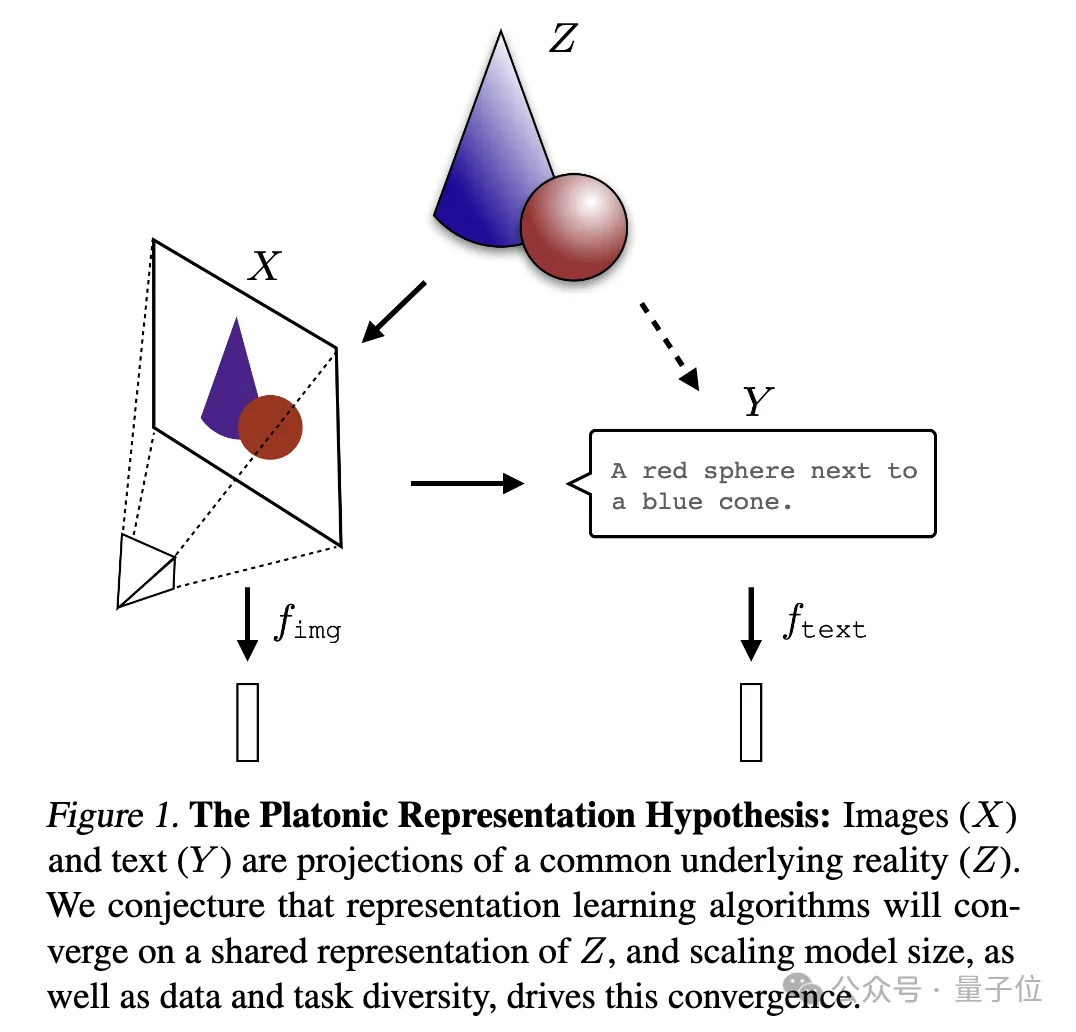
Neuronale Netze werden mit unterschiedlichen Zielen auf unterschiedliche Daten und Modalitäten trainiert und neigen dazu, in ihrem Repräsentationsraum einen gemeinsamen Repräsentationsraum zu bilden .

Sie nannten diese Spekulation die „Platonische Repräsentationshypothese“ in Anlehnung an Platons Höhlengleichnis und seine Vorstellungen über die Natur der idealen Realität.
 Die Auswahl von Ilya ist immer noch garantiert, nachdem sie es gelesen hatten:
Die Auswahl von Ilya ist immer noch garantiert, nachdem sie es gelesen hatten:
 Nachdem sie es gelesen hatten, verwendeten sie „Anna“. Zusammenfassend lässt sich der Eröffnungssatz von „Karenina“ zusammenfassen: Alle glücklichen Sprachmodelle sind ähnlich, und jedes unglückliche Sprachmodell hat sein eigenes Unglück.
Nachdem sie es gelesen hatten, verwendeten sie „Anna“. Zusammenfassend lässt sich der Eröffnungssatz von „Karenina“ zusammenfassen: Alle glücklichen Sprachmodelle sind ähnlich, und jedes unglückliche Sprachmodell hat sein eigenes Unglück.
 Um Whiteheads berühmtes Sprichwort zu paraphrasieren: Alles maschinelle Lernen ist eine Fußnote zu Platon.
Um Whiteheads berühmtes Sprichwort zu paraphrasieren: Alles maschinelle Lernen ist eine Fußnote zu Platon.
 Wir haben auch einen Blick darauf geworfen und der allgemeine Inhalt lautet:
Wir haben auch einen Blick darauf geworfen und der allgemeine Inhalt lautet:
Der Autor analysierte die
Repräsentationskonvergenz(Repräsentationskonvergenz) des KI-Systems, also die Darstellung von Datenpunkten in verschiedenen Neuronale Netzwerkmodelle werden in verschiedenen Modellarchitekturen, Trainingszielen und sogar Datenmodalitäten immer ähnlicher. Was treibt diese Konvergenz voran? Wird sich dieser Trend fortsetzen? Wo ist sein endgültiges Ziel?
Nach einer Reihe von Analysen und Experimenten spekulierten die Forscher, dass diese Konvergenz tatsächlich einen Endpunkt und ein treibendes Prinzip hat:
Verschiedene Modelle streben danach, eine genaue Darstellung der Realität zu erreichen. Ein Bild zur Erklärung:
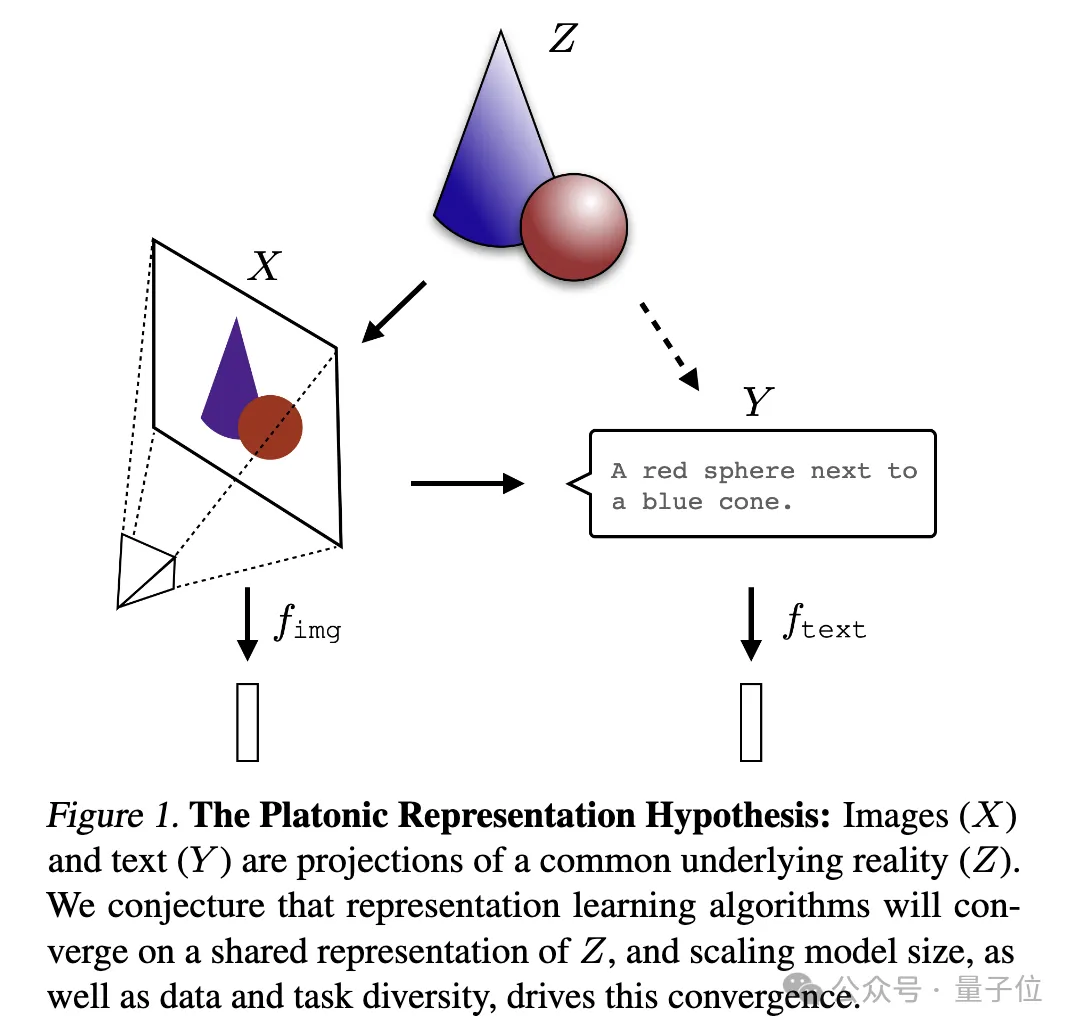 wobei Bild
wobei Bild
und Text (Y) unterschiedliche Projektionen einer gemeinsamen zugrunde liegenden Realität (Z) sind. Die Forscher spekulieren, dass Repräsentationslernalgorithmen zu einer einheitlichen Darstellung von Z konvergieren werden und dass die Zunahme der Modellgröße und die Vielfalt von Daten und Aufgaben Schlüsselfaktoren für diese Konvergenz sind. Ich kann nur sagen, dass es sich tatsächlich um eine Frage handelt, die Ilya interessiert. Sie ist zu tiefgreifend und wir verstehen sie nicht sehr gut. Bitten wir die KI, sie bei der Interpretation zu helfen und sie mit allen zu teilen~
 Beweise, die Konvergenz darstellen
Beweise, die Konvergenz darstellen
Zunächst hat der Autor eine große Anzahl früherer verwandter Studien analysiert und auch selbst Experimente durchgeführt und eine Reihe von Beweisen für Konvergenz erstellt, die Konvergenz, Umfang und Leistung sowie modalübergreifende Konvergenz demonstrieren verschiedener Modelle.
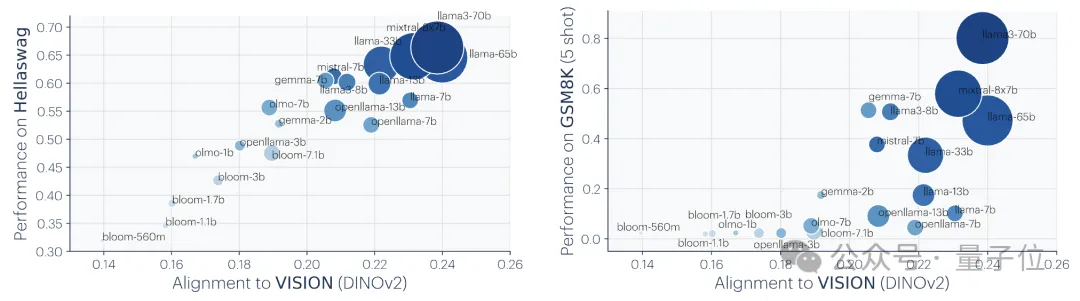
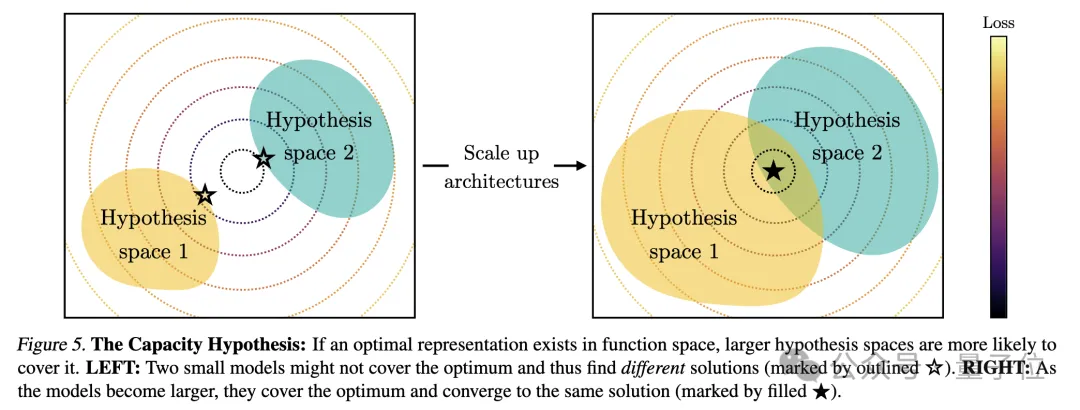
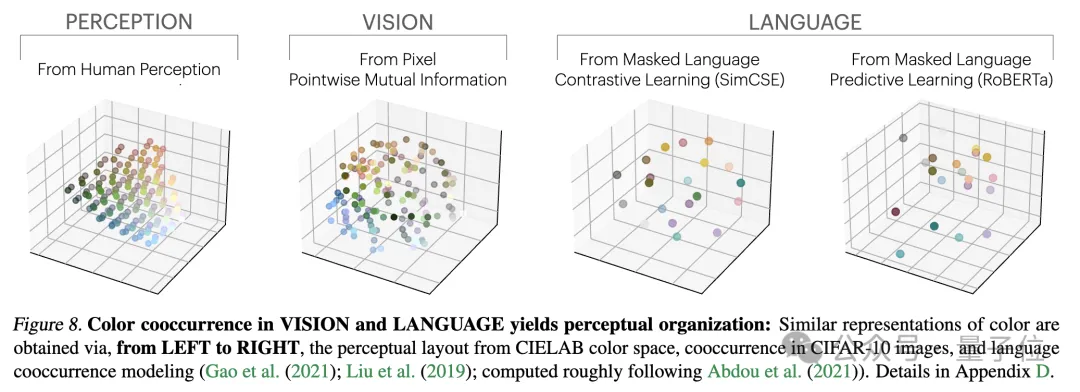
Ps: Diese Forschung konzentriert sich auf die Vektoreinbettungsdarstellung, das heißt, Daten werden in Vektorform umgewandelt und die Ähnlichkeit oder der Abstand zwischen Datenpunkten wird durch die Kernelfunktion beschrieben. Das Konzept der „Darstellungsausrichtung“ in diesem Artikel bedeutet, dass die beiden Darstellungen als ausgerichtet gelten, wenn zwei unterschiedliche Darstellungsmethoden ähnliche Datenstrukturen offenbaren.1. Die Konvergenz verschiedener Modelle mit unterschiedlichen Architekturen und Zielen ist in der Regel konsistent in ihrer zugrunde liegenden Darstellung. Die Anzahl der Systeme, die auf vorab trainierten Grundmodellen basieren, nimmt allmählich zu, und einige Modelle werden zur Standard-Kernarchitektur für Multitasking. Diese breite Anwendbarkeit in einer Vielzahl von Anwendungen spiegelt ihre gewisse Vielseitigkeit bei den Datendarstellungsmethoden wider. Während dieser Trend darauf hindeutet, dass KI-Systeme zu einem kleineren Satz von Basismodellen konvergieren, beweist er nicht, dass verschiedene Basismodelle dieselbe Darstellung bilden. Jedoch haben einige neuere Untersuchungen zum Modell-Stitching(Modell-Stitching) ergeben, dass die Darstellungen der mittleren Ebene von Bildklassifizierungsmodellen gut ausgerichtet werden können, selbst wenn sie auf verschiedenen Datensätzen trainiert werden. Einige Untersuchungen haben beispielsweise ergeben, dass die frühen Schichten von Faltungsnetzwerken, die auf den Datensätzen ImageNet und Places365 trainiert wurden, ausgetauscht werden können, was darauf hindeutet, dass sie ähnliche anfängliche visuelle Darstellungen gelernt haben. Es gibt auch Studien, die eine große Anzahl von „Rosetta-Neuronen“ entdeckt haben, also Neuronen mit sehr ähnlichen Aktivierungsmustern in verschiedenen visuellen Modellen... 2 Je größer die Modellgröße und Leistung, desto besser die Darstellung Je höher die Ausrichtung. mithilfe der Methode des gegenseitigen nächsten Nachbarn am Places-365-Datensatz gemessen und ihre Downstream-Aufgabenleistung anhand des Vision-Task-Adaption-Benchmarks VTAB bewertet. 3. Konvergenz der Modelldarstellung in verschiedenen Modi. 4. Das Modell und die Gehirndarstellung weisen ebenfalls einen gewissen Grad an Konsistenz auf, möglicherweise aufgrund ähnlicher Daten- und Aufgabenbeschränkungen. 5. Der Grad der Ausrichtung von Modelldarstellungen korreliert positiv mit der Leistung nachgelagerter Aufgaben. (logisches Denken) und GSM8K (Mathematik) . Und verwenden Sie das DINOv2-Modell als Referenz, um die Ausrichtung anderer Sprachmodelle mit dem visuellen Modell zu messen. Ein ähnliches Prinzip wurde bereits vorgeschlagen. Das Diagramm lautet wie folgt: Darüber hinaus gibt es für einfache Aufgaben mehrere Lösungen, während es für schwierige Aufgaben weniger Lösungen gibt. Daher konvergiert die Darstellung des Modells mit zunehmender Aufgabenschwierigkeit tendenziell zu besseren, weniger Lösungen. 2. Modellkapazität führt zu Konvergenz (Konvergenz über Modellkapazität) Wenn es eine global optimale Darstellung gibt, wird unter der Bedingung ausreichender Daten ein größeres Modell vorliegen effizienter sein. Daher neigen größere Modelle, die unabhängig von ihrer Architektur dasselbe Trainingsziel verwenden, dazu, dieser optimalen Lösung zuzustreben. Wenn verschiedene Trainingsziele ähnliche Minima haben, sind größere Modelle effizienter beim Finden dieser Minima und tendieren zu ähnlichen Lösungen für alle Trainingsaufgaben. 3. Konvergenz durch Simplicity Bias Tiefe Netzwerke neigen dazu, nach einfachen Anpassungen an die Daten zu suchen. Diese inhärente Tendenz zur Einfachheit führt dazu, dass große Modelle tendenziell vereinfacht dargestellt werden, was zu Konvergenz führt. Das heißt, größere Modelle haben eine größere Abdeckung und sind in der Lage, dieselben Daten auf alle möglichen Arten anzupassen. Die implizite Einfachheitspräferenz tiefer Netzwerke ermutigt jedoch größere Modelle, die einfachste dieser Lösungen zu finden. Der Endpunkt der KonvergenzNach einer Reihe von Analysen und Experimenten schlugen die Forscher, wie eingangs erwähnt, die „Plato-Repräsentationshypothese“ vor und spekulierten über den Endpunkt dieser Konvergenz. Das heißt, verschiedene KI-Modelle konvergieren, obwohl sie auf unterschiedliche Daten und Ziele trainiert wurden, in ihren Darstellungsräumen zu einem gemeinsamen statistischen Modell, das die reale Welt darstellt, die die von uns beobachteten Daten generiert. Als nächstes betrachtet der Autor eine Klasse kontrastiver Lernalgorithmen, die versuchen, eine Darstellung fX zu lernen, so dass das innere Produkt von fX(xa) und fX(xb) xa annähert und ) das Verhältnis der logarithmischen Quoten von (zufällig ausgewählt) Nach der mathematischen Ableitung stellte der Autor fest, dass dieser Algorithmus zu einer Kernelfunktion konvergiert, wenn die Daten glatt genug sind. Dies ist der Punkt gegenseitige Information (PMI) von xa und xb Das bedeutet, dass unabhängig davon, ob Darstellungen aus visuellen Daten Forscher haben diese Theorie durch eine empirische Studie zur Farbe getestet. Unabhängig davon, ob die Farbdarstellung aus der Statistik des gleichzeitigen Auftretens von Pixeln in Bildern oder aus der Statistik des gleichzeitigen Auftretens von Wörtern in Texten gelernt wird, ähneln die resultierenden Farbabstände der menschlichen Wahrnehmung, und mit zunehmender Modellgröße wird diese Ähnlichkeit immer größer. Dies steht im Einklang mit der theoretischen Analyse, das heißt, eine größere Modellfähigkeit kann die Statistiken von Beobachtungsdaten genauer modellieren und so einen PMI-Kernel erhalten, der der idealen Ereignisdarstellung näher kommt. Am Ende des Artikels fasst der Autor die möglichen Auswirkungen der Repräsentationskonvergenz auf das Gebiet der KI und zukünftige Forschungsrichtungen sowie mögliche Einschränkungen und Ausnahmen von der platonischen Repräsentationsannahme zusammen. Sie wiesen darauf hin, dass die Konvergenz der Darstellung mit zunehmender Modellgröße unter anderem folgende Auswirkungen haben kann: Der Autor betont, dass die Prämisse der oben genannten Auswirkungen darin besteht, dass die Trainingsdaten zukünftiger Modelle ausreichend vielfältig und verlustfrei sein müssen, um wirklich zu einer Darstellung zu konvergieren, die die statistischen Gesetze der tatsächlichen Welt widerspiegelt. Gleichzeitig stellte der Autor auch fest, dass Daten unterschiedlicher Modalitäten einzigartige Informationen enthalten können, was es schwierig machen kann, eine vollständige Darstellungskonvergenz zu erreichen, selbst wenn die Modellgröße zunimmt. Darüber hinaus stimmen derzeit nicht alle Darstellungen überein. Beispielsweise gibt es im Bereich der Robotik keine standardisierte Darstellungsweise. Forscher und Community-Präferenzen können dazu führen, dass Modelle sich menschlichen Darstellungen annähern und dabei andere mögliche Formen der Intelligenz ignorieren. Und intelligente Systeme, die speziell für bestimmte Aufgaben entwickelt wurden, konvergieren möglicherweise nicht zu denselben Darstellungen wie die allgemeine Intelligenz. Die Autoren betonen außerdem, dass Methoden zur Messung der Darstellungsausrichtung umstritten sind und unterschiedliche Messmethoden zu unterschiedlichen Schlussfolgerungen führen können. Auch wenn die Darstellungen verschiedener Modelle ähnlich sind, müssen noch Lücken erklärt werden, und es ist derzeit nicht möglich zu bestimmen, ob diese Lücke wichtig ist. Für weitere Details und Argumentationsmethoden werde ich das Papier hier veröffentlichen~ Link zum Papier: https://arxiv.org/abs/2405.07987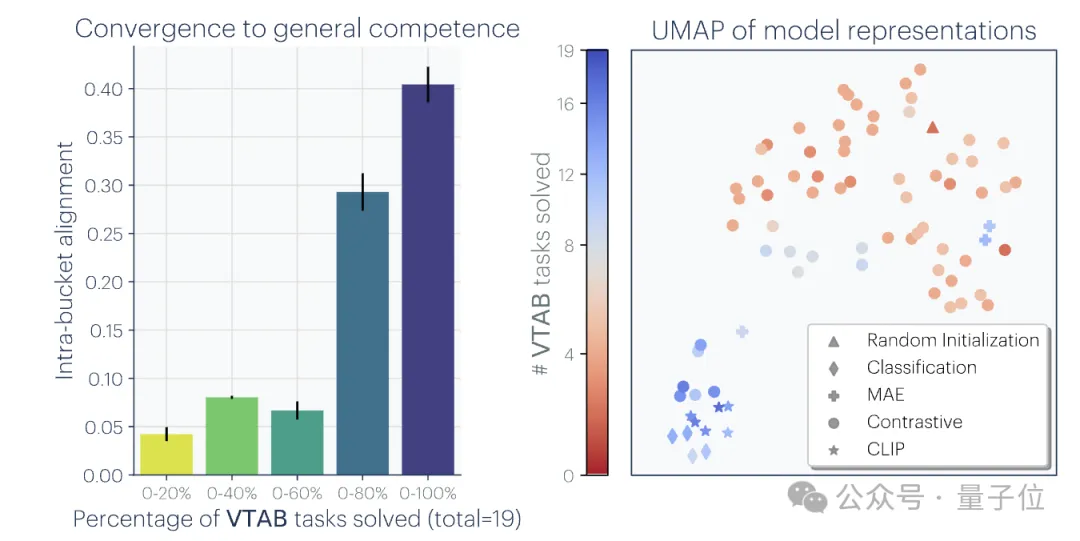




 Sie konstruierten zunächst ein idealisiertes diskretes Ereignisweltmodell. Die Welt enthält eine Reihe diskreter Ereignisse Z, jedes Ereignis wird aus einer unbekannten Verteilung P(Z) entnommen. Jedes Ereignis kann durch die Beobachtungsfunktion obs auf unterschiedliche Weise beobachtet werden, z. B. Pixel, Töne, Text usw.
Sie konstruierten zunächst ein idealisiertes diskretes Ereignisweltmodell. Die Welt enthält eine Reihe diskreter Ereignisse Z, jedes Ereignis wird aus einer unbekannten Verteilung P(Z) entnommen. Jedes Ereignis kann durch die Beobachtungsfunktion obs auf unterschiedliche Weise beobachtet werden, z. B. Pixel, Töne, Text usw. 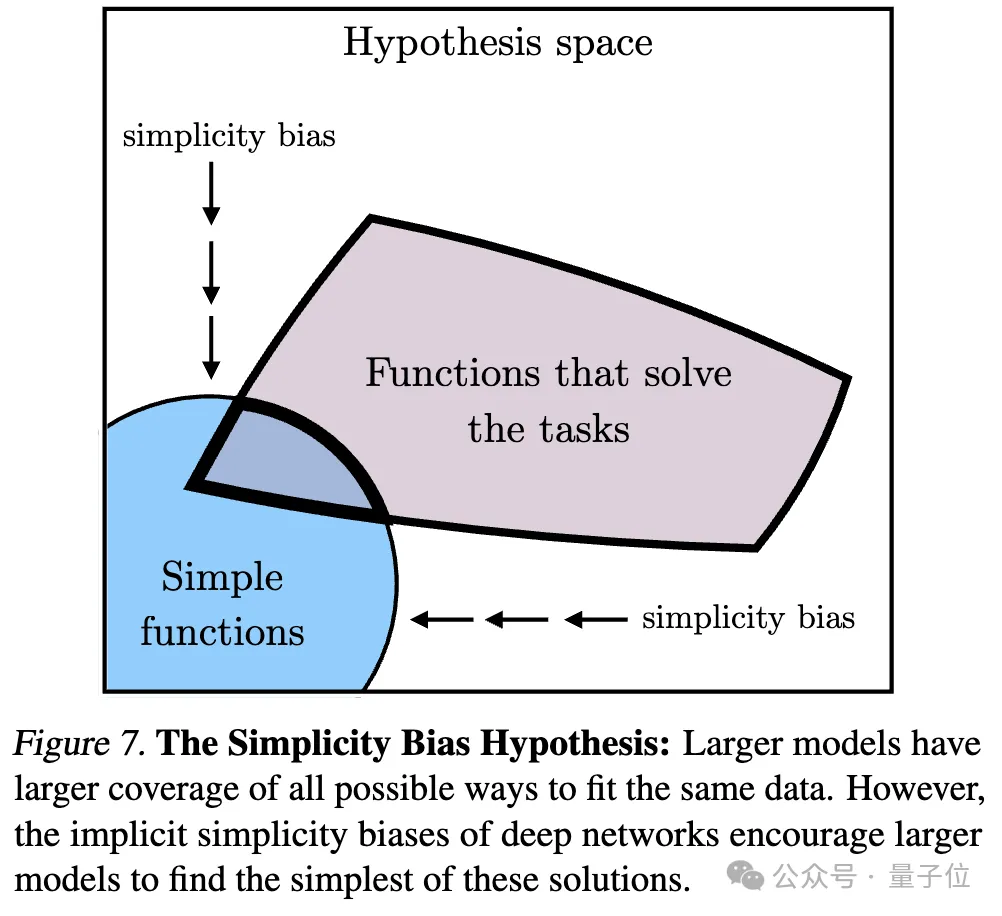 .
. 

Einige abschließende Gedanken
Das obige ist der detaillierte Inhalt vonIlyas erste Aktion, nachdem er seinen Job aufgegeben hatte: Mir gefiel diese Zeitung, und die Internetnutzer beeilten sich, sie zu lesen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So löschen Sie eine Pivot-Tabelle
- Google hat es auch gemacht? Bard wurde ausgesetzt, um ChatGPT-Daten für das Training zu verwenden. Das große Modell gerät Schritt für Schritt ins Hintertreffen.
- Die offizielle Ankündigung des Haimo Supercomputing Center: ein großes Modell mit 100 Milliarden Parametern, einer Datenskala von 1 Million Clips und einer 200-fachen Reduzierung der Trainingskosten
- Die erste behördliche Überprüfung von ChatGPT stammt möglicherweise von der US-amerikanischen Federal Trade Commission, OpenAI: noch nicht trainiertes GPT5