
Heim >Technologie-Peripheriegeräte >KI >GraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code)
GraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-12 10:32:281689Durchsuche
Graph Retrieval Enhanced Generation (Graph RAG) erfreut sich zunehmender Beliebtheit und hat sich zu einer leistungsstarken Ergänzung zu herkömmlichen Vektorsuchmethoden entwickelt. Diese Methode nutzt die strukturellen Merkmale von Graphdatenbanken, um Daten in Form von Knoten und Beziehungen zu organisieren und dadurch die Tiefe und kontextbezogene Relevanz der abgerufenen Informationen zu verbessern. Diagramme haben einen natürlichen Vorteil bei der Darstellung und Speicherung vielfältiger und miteinander verbundener Informationen und können problemlos komplexe Beziehungen und Eigenschaften zwischen verschiedenen Datentypen erfassen. Vektordatenbanken können diese Art von strukturierten Informationen nicht verarbeiten und konzentrieren sich mehr auf die Verarbeitung unstrukturierter Daten, die durch hochdimensionale Vektoren dargestellt werden. In RAG-Anwendungen können wir durch die Kombination strukturierter Diagrammdaten und unstrukturierter Textvektorsuche gleichzeitig die Vorteile beider nutzen, worauf in diesem Artikel eingegangen wird.
Der Aufbau eines Wissensgraphen ist oft der schwierigste Schritt, um die Leistungsfähigkeit der grafischen Datendarstellung zu nutzen. Es erfordert das Sammeln und Organisieren von Daten, was ein tiefes Verständnis der Domänenkenntnisse und der Diagrammmodellierung erfordert. Um diesen Prozess zu vereinfachen, können Sie auf bestehende Projekte zurückgreifen oder LLM verwenden, um einen Wissensgraphen zu erstellen, und sich dann auf das Abrufen und Abrufen konzentrieren, um die Generierungsphase von LLM zu verbessern. Lassen Sie uns den entsprechenden Code unten üben.
1. Knowledge-Graph-Erstellung
Um Knowledge-Graph-Daten zu speichern, müssen Sie zunächst eine Neo4j-Instanz erstellen. Der einfachste Weg besteht darin, eine kostenlose Instanz auf Neo4j Aura zu starten, die eine Cloud-Version der Neo4j-Datenbank bereitstellt. Natürlich können Sie es auch lokal über Docker starten und dann die Diagrammdaten in die Neo4j-Datenbank importieren.
Schritt I: Einrichtung der Neo4j-Umgebung
Das Folgende ist ein Beispiel für die lokale Ausführung von Docker:
docker run -d \--restart always \--publish=7474:7474 --publish=7687:7687 \--env NEO4J_AUTH=neo4j/000000 \--volume=/yourdockerVolume/neo4j:/data \neo4j:5.19.0
Schritt II: Diagrammdatenimport
In der Demonstration können wir die Wikipedia-Seite von Elizabeth I. verwenden. Verwenden Sie den LangChain-Loader, um Dokumente von Wikipedia abzurufen und aufzuteilen und sie dann in der Neo4j-Datenbank zu speichern. Um den Effekt auf Chinesisch zu testen, haben wir den medizinischen Wissensgraphen aus diesem Projekt (QASystemOnMedicalKG) auf Github importiert, der fast 35.000 Knoten und 300.000 Tripelsätze enthält. Wir haben ungefähr die folgenden Ergebnisse erhalten:
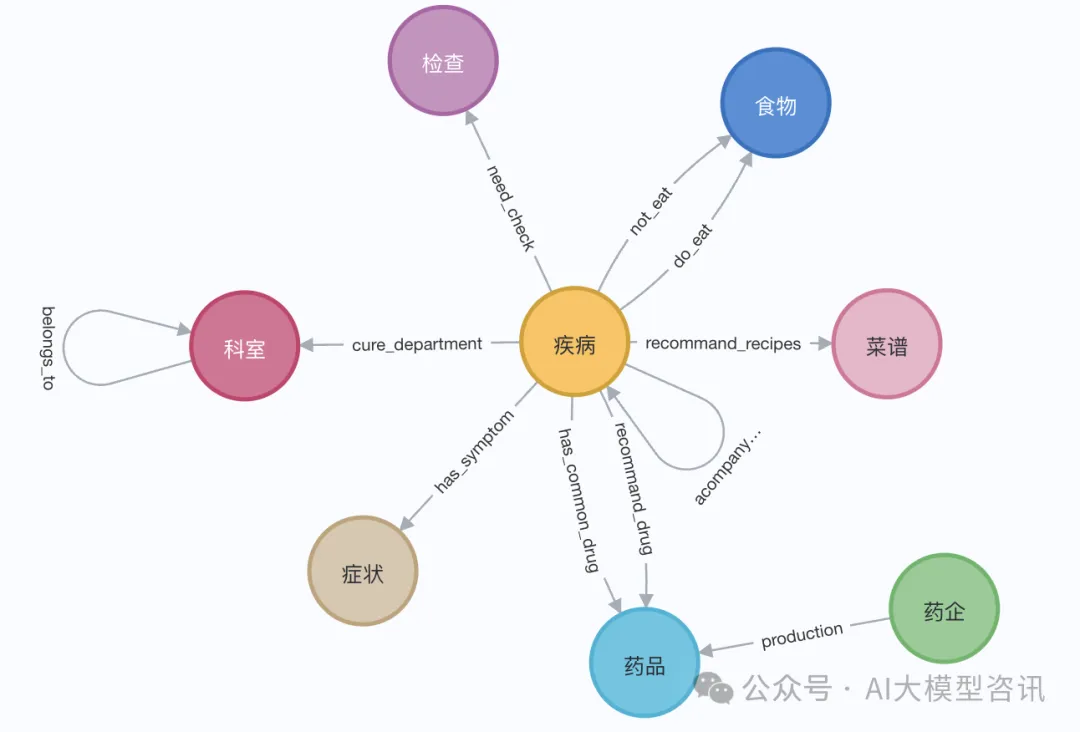 Bilder
Bilder
Oder verwenden Sie den LangChainLangChain-Loader, um Dokumente aus Wikipedia abzurufen und aufzuteilen, ungefähr wie in den folgenden Schritten gezeigt:
# 读取维基百科文章raw_documents = WikipediaLoader(query="Elizabeth I").load()# 定义分块策略text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)documents = text_splitter.split_documents(raw_documents[:3])llm=ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview")llm_transformer = LLMGraphTransformer(llm=llm)# 提取图数据graph_documents = llm_transformer.convert_to_graph_documents(documents)# 存储到 neo4jgraph.add_graph_documents(graph_documents, baseEntityLabel=True, include_source=True)
2. Vor dem Abrufen des Wissensgraphen müssen Entitäten und zugehörige Attribute vektorisiert eingebettet und gespeichert werden In die Neo4j-Datenbank:
Entitätsinformationsvektoreinbettung: Nachdem Sie den Entitätsnamen und die Beschreibungsinformationen der Entität zusammengefügt haben, verwenden Sie das Vektordarstellungsmodell, um die Vektoreinbettung durchzuführen (wie in der Methode add_embeddings im Beispielcode unten gezeigt).- Struktureller Abruf des Diagramms: Der strukturierte Abruf des Diagramms ist in vier Schritte unterteilt: Schritt 1: Abrufen der mit der Abfrage verknüpften Entitäten aus dem Diagramm; Schritt 2: Abrufen der Tags der Entitäten aus dem globalen Index; Fragen Sie den Pfad des Nachbarknotens im entsprechenden Knoten basierend auf den Entitäts-Tags ab. Schritt 4: Filtern Sie die Beziehung, um die Diversität aufrechtzuerhalten (der gesamte Abrufprozess wird in der Methode „structured_retriever“ im folgenden Beispielcode gezeigt).
class GraphRag(object):def __init__(self):"""Any embedding function implementing `langchain.embeddings.base.Embeddings` interface."""self._database = 'neo4j'self.label = 'Med'self._driver = neo4j.GraphDatabase.driver(uri=os.environ["NEO4J_URI"],auth=(os.environ["NEO4J_USERNAME"],os.environ["NEO4J_PASSWORD"]))self.embeddings_zh = HuggingFaceEmbeddings(model_name=os.environ["EMBEDDING_MODEL"])self.vectstore = Neo4jVector(embedding=self.embeddings_zh, username=os.environ["NEO4J_USERNAME"], password=os.environ["NEO4J_PASSWORD"], url=os.environ["NEO4J_URI"], node_label=self.label, index_name="vector" )def query(self, query: str, params: dict = {}) -> List[Dict[str, Any]]:"""Query Neo4j database."""from neo4j.exceptions import CypherSyntaxErrorwith self._driver.session(database=self._database) as session:try:data = session.run(query, params)return [r.data() for r in data]except CypherSyntaxError as e:raise ValueError(f"Generated Cypher Statement is not valid\n{e}")def add_embeddings(self):"""Add embeddings to Neo4j database."""# 查询图中所有节点,并且根据节点的描述和名字生成embedding,添加到该节点上query = """MATCH (n) WHERE not (n:{}) RETURN ID(n) AS id, labels(n) as labels, n""".format(self.label)print("qurey node...")data = self.query(query)ids, texts, embeddings, metas = [], [], [], []for row in tqdm(data,desc="parsing node"):ids.append(row['id'])text = row['n'].get('name','') + row['n'].get('desc','')texts.append(text)metas.append({"label": row['labels'], "context": text})self.embeddings_zh.multi_process = Falseprint("node embeddings...")embeddings = self.embeddings_zh.embed_documents(texts)print("adding node embeddings...")ids_ret = self.vectstore.add_embeddings(ids=ids,texts=texts,embeddings=embeddings,metadatas=metas)return ids_ret# Fulltext index querydef structured_retriever(self, query, limit=3, simlarity=0.9) -> str:"""Collects the neighborhood of entities mentioned in the question"""# step1 从图谱中检索与查询相关的实体。docs_with_score = self.vectstore.similarity_search_with_score(query, k=topk)entities = [item[0].page_content for item in data if item[1] > simlarity] # scoreself.vectstore.query("CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:Med) ON EACH [e.context]")result = ""for entity in entities:qry = entity# step2 从全局索引中查出entity label,query1 =f"""CALL db.index.fulltext.queryNodes('entity', '{qry}') YIELD node, score return node.label as label,node.context as context, node.id as id, score LIMIT {limit}"""data1 = self.vectstore.query(query1)# step3 根据label在相应的节点中查询邻居节点路径for item in data1:node_type = item['label']node_type = item['label'] if type(node_type) == str else node_type[0]node_id = item['id']query2 = f"""match (node:{node_type})-[r]-(neighbor) where ID(node) = {node_id} RETURN type(r) as rel, node.name+' - '+type(r)+' - '+neighbor.name as output limit 50"""data2 = self.vectstore.query(query2)# step4 为了保持多样性,对关系进行筛选rel_dict = defaultdict(list)if len(data2) > 3*limit:for item1 in data2:rel_dict[item1['rel']].append(item1['output'])if rel_dict:rel_dict = {k:random.sample(v, 3) if len(v)>3 else v for k,v in rel_dict.items()}result += "\n".join(['\n'.join(el) for el in rel_dict.values()]) +'\n'else:result += "\n".join([el['output'] for el in data2]) +'\n'return result
Abschließend wird ein großes Sprachmodell (LLM) verwendet, um die endgültige Antwort basierend auf den aus dem Wissensgraphen abgerufenen strukturierten Informationen zu generieren. Im folgenden Code nehmen wir als Beispiel das große Sprachmodell von Tongyi Qianwen Open Source:
Schritt I: Laden Sie das LLM-Modell
from langchain import HuggingFacePipelinefrom transformers import pipeline, AutoTokenizer, AutoModelForCausalLMdef custom_model(model_name, branch_name=None, cache_dir=None, temperature=0, top_p=1, max_new_tokens=512, stream=False):tokenizer = AutoTokenizer.from_pretrained(model_name, revision=branch_name, cache_dir=cache_dir)model = AutoModelForCausalLM.from_pretrained(model_name,device_map='auto',torch_dtype=torch.float16,revision=branch_name,cache_dir=cache_dir)pipe = pipeline("text-generation",model = model,tokenizer = tokenizer,torch_dtype = torch.bfloat16,device_map = 'auto',max_new_tokens = max_new_tokens,do_sample = True)llm = HuggingFacePipeline(pipeline = pipe,model_kwargs = {"temperature":temperature, "top_p":top_p,"tokenizer":tokenizer, "model":model})return llmtongyi_model = "Qwen1.5-7B-Chat"llm_model = custom_model(model_name=tongyi_model)tokenizer = llm_model.model_kwargs['tokenizer']model = llm_model.model_kwargs['model']
Schritt II: Geben Sie die Abrufdaten ein, um eine Antwort zu generieren
final_data = self.get_retrieval_data(query)prompt = ("请结合以下信息,简洁和专业的来回答用户的问题,若信息与问题关联紧密,请尽量参考已知信息。\n""已知相关信息:\n{context} 请回答以下问题:{question}".format(cnotallow=final_data, questinotallow=query))messages = [{"role": "system", "content": "你是**开发的智能助手。"},{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(self.device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)
Eine Abfragefrage wurde separat getestet. Im Vergleich zu der Situation, in der nur LLM zum Generieren von Antworten ohne RAG verwendet wird, beantwortet das LLM-Modell mit GraphRAG eine größere Menge an Informationen und ist genauer.
Das obige ist der detaillierte Inhalt vonGraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!