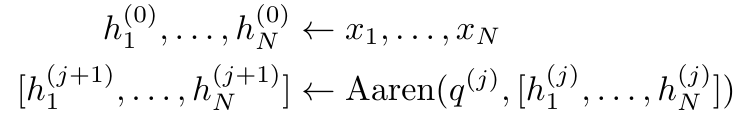Fortschritte bei der Sequenzmodellierung waren äußerst wirkungsvoll, da sie in einer Vielzahl von Anwendungen eine wichtige Rolle spielen, darunter verstärkendes Lernen (z. B. Robotik und autonomes Fahren), Zeitreihenklassifizierung (z. B. Erkennung von Finanzbetrug und medizinische Diagnose). In den letzten Jahren stellte das Aufkommen von Transformer einen großen Durchbruch in der Sequenzmodellierung dar, vor allem aufgrund der Tatsache, dass Transformer eine Hochleistungsarchitektur bereitstellt, die die Vorteile der GPU-Parallelverarbeitung nutzen kann. Allerdings hat Transformer während der Inferenz einen hohen Rechenaufwand, der hauptsächlich auf die quadratische Erweiterung des Speichers und der Rechenanforderungen zurückzuführen ist, wodurch seine Anwendung in Umgebungen mit geringen Ressourcen (z. B. mobile und eingebettete Geräte) eingeschränkt wird. Obwohl Techniken wie KV-Caching zur Verbesserung der Inferenzeffizienz eingesetzt werden können, ist Transformer für ressourcenarme Domänen immer noch sehr teuer, da (1) der Speicher linear mit der Anzahl der Token zunimmt und (2) alle vorherigen Token im Cache gespeichert werden Modell. Dieses Problem wirkt sich noch stärker auf die Transformer-Inferenz in Umgebungen mit langen Kontexten (d. h. einer großen Anzahl von Tokens) aus. Um dieses Problem zu lösen, haben Forscher des Royal Bank of Canada AI Research Institute Borealis AI und der Universität Montreal in der Arbeit „Attention as an RNN“ eine Lösung bereitgestellt. Erwähnenswert ist, dass wir den Turing-Award-Gewinner Yoshua Bengio in der Autorenkolumne gefunden haben. 
- Papieradresse: https://arxiv.org/pdf/2405.13956
- Papiertitel: Aufmerksamkeit als
Recherchieren Sie insbesondere den Autor untersuchten zunächst den Aufmerksamkeitsmechanismus in Transformer, der die Komponente darstellt, die dazu führt, dass die Rechenkomplexität von Transformer quadratisch zunimmt. Diese Studie zeigt, dass der Aufmerksamkeitsmechanismus als eine besondere Art eines wiederkehrenden neuronalen Netzwerks (RNN) betrachtet werden kann, mit der Fähigkeit, viele-zu-eins-RNN-Ausgaben effizient zu berechnen. Unter Verwendung der RNN-Formulierung der Aufmerksamkeit zeigt diese Studie, dass beliebte aufmerksamkeitsbasierte Modelle wie Transformer und Perceiver als RNN-Varianten betrachtet werden können.
Im Gegensatz zu herkömmlichen RNNs wie LSTM und GRU können jedoch beliebte Aufmerksamkeitsmodelle wie Transformer und Perceiver als RNN-Varianten betrachtet werden. Leider können sie nicht effizient mit neuen Token aktualisiert werden.
Um dieses Problem zu lösen, führt diese Forschung eine neue Aufmerksamkeitsformel ein, die auf dem parallelen Präfix-Scan-Algorithmus basiert und die Viele-zu-Viele-Aufmerksamkeit (Viele-zu-Viele) effizient berechnen kann. viele) RNN-Ausgabe, um effiziente Aktualisierungen zu erreichen. Basierend auf dieser neuen Aufmerksamkeitsformel schlägt die Studie Aaren ([A] Aufmerksamkeit [a] ist ein [re] aktuelles neuronales [n] Netzwerk) vor, ein recheneffizientes Modul, das nicht nur wie Transformer parallel trainiert werden kann , kann aber auch genauso effizient aktualisiert werden wie RNN. Experimentelle Ergebnisse zeigen, dass die Leistung von Aaren mit der von Transformer in 38 Datensätzen vergleichbar ist, die vier gängige Sequenzdateneinstellungen abdecken: Verstärkungslernen, Ereignisvorhersage, Zeitreihenklassifizierung und Zeitreihenvorhersageaufgaben. Außerdem ist sie in Bezug auf Zeit und Zeit effizienter Erinnerung. Methodeneinführung
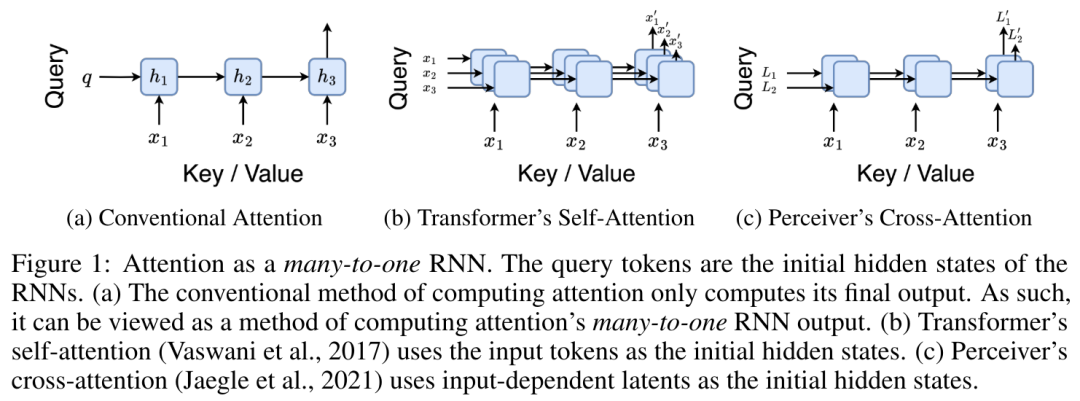
Um die oben genannten Probleme zu lösen, schlägt der Autor ein effizientes, auf Aufmerksamkeit basierendes Modul vor, das die GPU-Parallelität nutzen und gleichzeitig effizient aktualisieren kann. Zunächst zeigen die Autoren in Abschnitt 3.1, dass Aufmerksamkeit als eine Art RNN mit der besonderen Fähigkeit angesehen werden kann, die Ausgabe von Viele-zu-Eins-RNNs effizient zu berechnen (Abbildung 1a). Mithilfe der RNN-Form der Aufmerksamkeit veranschaulichen die Autoren außerdem, dass beliebte aufmerksamkeitsbasierte Modelle wie Transformer (Abbildung 1b) und Perceiver (Abbildung 1c) als RNNs betrachtet werden können. Im Gegensatz zu herkömmlichen RNNs können sich diese Modelle jedoch nicht effizient auf der Grundlage neuer Token aktualisieren, was ihr Potenzial bei sequentiellen Problemen einschränkt, bei denen Daten in Form eines Streams eintreffen. Um dieses Problem zu lösen, stellt der Autor in Abschnitt 3.2 eine effiziente Methode zur Berechnung der Aufmerksamkeit in Many-to-Many-RNN vor, die auf einem parallelen Präfix-Scan-Algorithmus basiert. Auf dieser Grundlage stellte der Autor Aaren in Abschnitt 3.3 vor – ein recheneffizientes Modul, das nicht nur parallel trainiert werden kann (genau wie Transformer), sondern auch während der Inferenz effizient mit neuen Token aktualisiert werden kann und nur einen konstanten Speicher benötigt (gerade). wie traditionelles RNN).Betrachten Sie Aufmerksamkeit als Viele-zu-Eins-RNNDie Aufmerksamkeit des Abfragevektors q kann als Funktion angesehen werden, die die Schlüssel und Werte von N Kontexttoken x_1:N übergibt Es wird einer einzelnen Ausgabe zugeordnet: o_N = Attention (q, k_1:N, v_1:N). Bei s_i = dot (q, k_i) kann die Ausgabe o_N ausgedrückt werden als: wobei der Zähler und der Nenner ist. Wenn man sich Aufmerksamkeit als RNN vorstellt, können und iterativ in einer rollierenden Summationsweise berechnet werden, wenn k = 1,...,.... In der Praxis ist diese Implementierung jedoch instabil und leidet unter numerischen Problemen aufgrund der begrenzten Präzisionsdarstellung und möglicherweise sehr kleinen oder sehr großen Exponenten (d. h. exp (s)). Um dieses Problem zu lindern, verwendet der Autor den kumulativen Maximalterm , um die Rekursionsformel zur Berechnung von und neu zu schreiben. Es ist erwähnenswert, dass das Endergebnis dasselbe ist , die Schleifenberechnung von m_k lautet wie folgt:
Durch die Kapselung der zyklischen Berechnung von a_k, c_k und m_k aus a_(k-1), c_(k-1) und m_(k-1) stellt der Autor eine RNN-Einheit vor, die die Aufmerksamkeitsausgabe iterativ berechnen kann (siehe Figur 2). Die Aufmerksamkeits-RNN-Einheit nimmt (a_(k-1), c_(k-1), m_(k-1), q) als Eingabe und berechnet (a_k, c_k, m_k, q). Beachten Sie, dass der Abfragevektor q in der RNN-Einheit übergeben wird. Der anfängliche verborgene Zustand des Aufmerksamkeits-RNN ist (a_0, c_0, m_0, q) = (0, 0, 0, q). Methoden zur Berechnung der Aufmerksamkeit: Indem Sie die Aufmerksamkeit als RNN betrachten, können Sie verschiedene Möglichkeiten zur Berechnung der Aufmerksamkeit erkennen: Schleifenberechnung Token für Token im O (1)-Speicher (d. h. sequentielle Berechnung); oder Berechnung auf herkömmliche Weise (d. h. paralleles Rechnen), das linearen O(N)-Speicher erfordert. Da Aufmerksamkeit als RNN betrachtet werden kann, kann die herkömmliche Methode zur Berechnung der Aufmerksamkeit auch als effiziente Methode zur Berechnung der Ausgabe von Aufmerksamkeits-Viele-zu-Eins-RNN angesehen werden, dh die Ausgabe von RNN nimmt mehrere Kontext-Token an Eingabe, aber am Ende des RNN wird nur ein Token ausgegeben (siehe Abbildung 1a). Schließlich kann Aufmerksamkeit auch als RNN berechnet werden, das Token Stück für Stück verarbeitet, anstatt vollständig sequentiell oder vollständig parallel, was O(b) Speicher erfordert, wobei b die Größe des Blocks ist. Behandeln Sie vorhandene Aufmerksamkeitsmodelle als RNNs. Durch die Behandlung von Aufmerksamkeit als RNN können bestehende aufmerksamkeitsbasierte Modelle auch als Varianten von RNN betrachtet werden. Beispielsweise ist die Selbstaufmerksamkeit des Transformers ein RNN (Abbildung 1b), und das Kontexttoken ist sein anfänglicher verborgener Zustand. Die Queraufmerksamkeit des Wahrnehmenden ist ein RNN (Abbildung 1c), dessen anfänglicher verborgener Zustand eine kontextabhängige latente Variable ist. Durch die Nutzung von RNN-Formen ihres Aufmerksamkeitsmechanismus können diese vorhandenen Modelle ihre Ausgabespeicher effizient berechnen. Wenn jedoch bestehende aufmerksamkeitsbasierte Modelle (wie Transformers) als RNNs betrachtet werden, fehlen diesen Modellen wichtige Eigenschaften, die üblicherweise in traditionellen RNNs (wie LSTM und GRU) zu finden sind. Es ist erwähnenswert, dass LSTM und GRU in der Lage sind, sich effizient mit neuen Token in nur O(1) konstantem Speicher und Berechnung zu aktualisieren, im Gegensatz dazu wird die RNN-Ansicht von Transformer (siehe Abbildung 1b) ein neues Token hinzufügen als Anfangszustand und ein neues RNN wird hinzugefügt, um das neue Token zu verarbeiten. Dieses neue RNN verarbeitet alle vorherigen Token und erfordert eine lineare O(N)-Berechnung. In Perceiver sind latente Variablen (L_i in Abbildung 1c) aufgrund ihrer Architektur eingabeabhängig, was bedeutet, dass sich ihre Werte ändern, wenn neue Token empfangen werden. Da sich der anfängliche verborgene Zustand (d. h. latente Variablen) seines RNN ändert, muss Perceiver daher sein RNN von Grund auf neu berechnen, was einen linearen Rechenaufwand von O (NL) erfordert, wobei N die Anzahl der Token und L die Anzahl von ist latente Variablen. Betrachten Sie Aufmerksamkeit als ein Viele-zu-Viele-RNNAls Reaktion auf diese Einschränkungen schlägt der Autor vor, ein aufmerksamkeitsbasiertes Modell zu entwickeln, das die Fähigkeit der RNN-Formulierung nutzt, effiziente Aktualisierungen durchzuführen . Zu diesem Zweck stellt der Autor zunächst eine effiziente Parallelisierungsmethode zur Berechnung der Aufmerksamkeit als Viele-zu-Viele-RNN vor, also eine Methode des Parallelrechnens . Zu diesem Zweck verwenden die Autoren den parallelen Präfix-Scan-Algorithmus (siehe Algorithmus 1), eine parallele Rechenmethode, die N Präfixe aus N aufeinanderfolgenden Datenpunkten über den Korrelationsoperator ⊕ berechnet.Dieser Algorithmus kann Bewertung effizient berechnen, wobei , Um effizient zu berechnen, können und durch einen parallelen Scan-Algorithmus berechnet und dann zur Berechnung mit a_k und c_k kombiniert werden . ⊕ ,. Die Eingabe für den parallelen Scan-Algorithmus ist
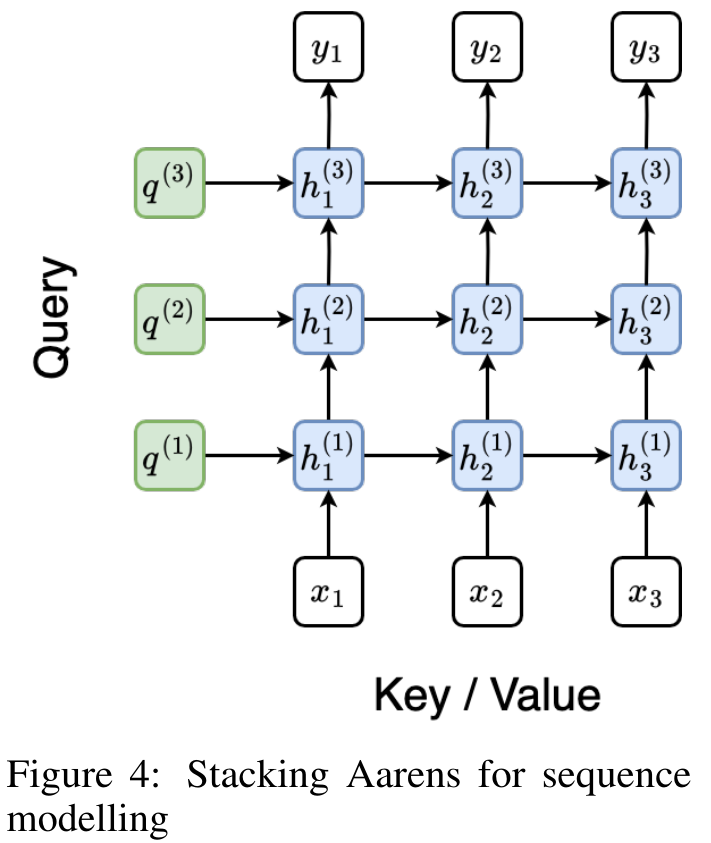
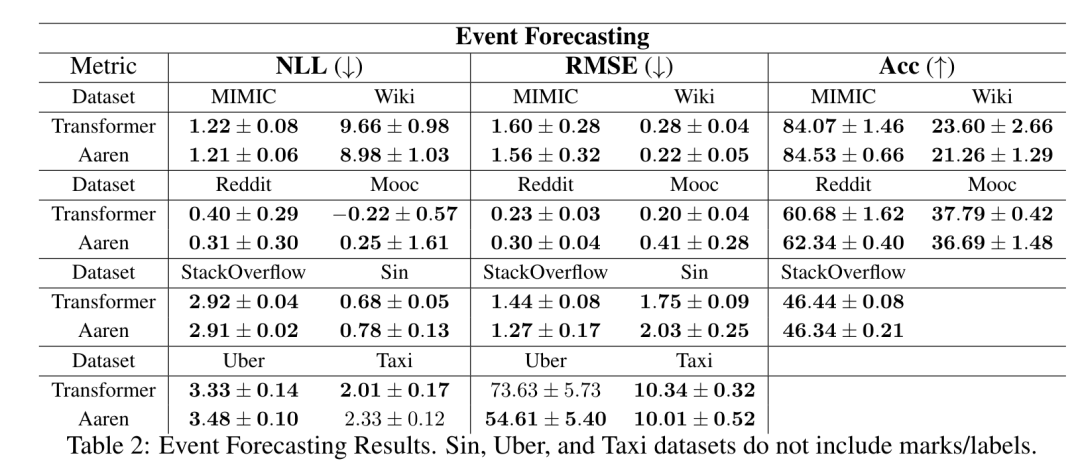
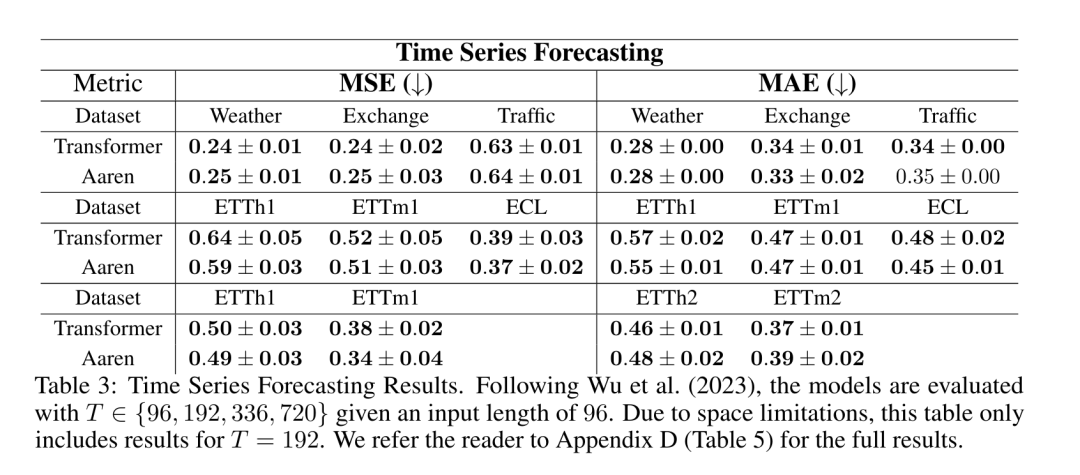
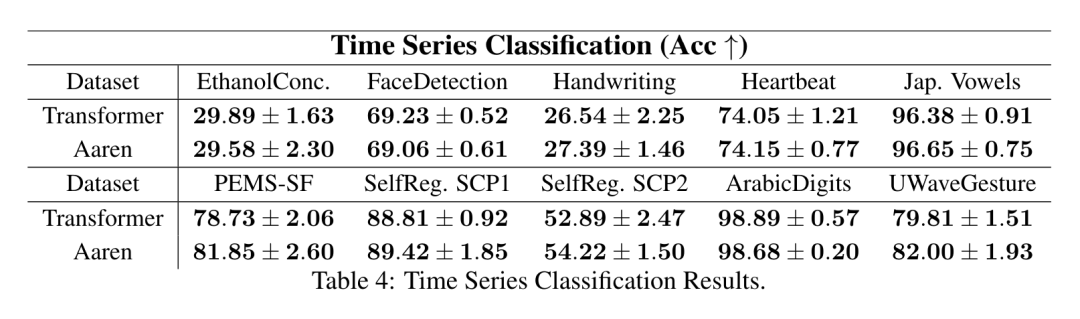
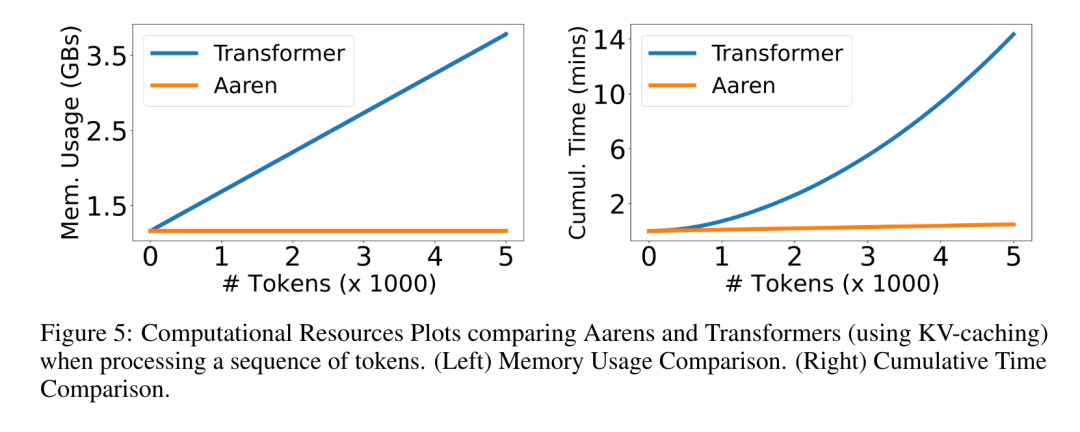
. Der Algorithmus wendet den Operator ⊕ rekursiv an und funktioniert wie folgt: , wobei , . Nach Abschluss der rekursiven Anwendung des Operators gibt der Algorithmus aus. Auch bekannt als . Durch die Kombination der letzten beiden Werte des Ausgabetupels wird abgerufen, was zu einer effizienten parallelen Methode zur Berechnung der Aufmerksamkeit als Viele-zu-Viele-RNN führt (Abbildung 3). Aaren: [A] Aufmerksamkeit [a] ist ein [aktuelles] neuronales [n] NetzwerkAarens Schnittstelle ist die gleiche wie bei Transformer, d. h. N Eingänge werden auf N Ausgaben abgebildet, und die i-te Ausgabe ist die Aggregation der ersten bis i-ten Eingaben. Darüber hinaus ist Aaren von Natur aus stapelbar und kann für jeden Sequenz-Token separate Verlustterme berechnen. Im Gegensatz zu Transformers, die kausale Selbstaufmerksamkeit verwenden, verwendet Aaren jedoch die obige Methode zur Berechnung der Aufmerksamkeit als Viele-zu-Viele-RNN, was sie effizienter macht. Die Form von Aaren ist wie folgt: Anders als bei Transformer ist in Transformer die Abfrage einer der in die Aufmerksamkeit eingegebenen Token, während in Aaren das Abfragetoken q durch Backpropagation weitergeleitet wird während des Trainingsprozesses Gelernt. Die folgende Abbildung zeigt ein Beispiel eines gestapelten Aaren-Modells. Das Eingabekontext-Token des Modells ist x_1:3 und die Ausgabe ist y_1:3. Es ist erwähnenswert, dass das Stapeln von Aarens auch dem Stapeln von RNN entspricht, da Aaren den Aufmerksamkeitsmechanismus in Form von RNN nutzt. Daher ist Aarens auch in der Lage, effizient mit neuen Token zu aktualisieren, d. h. die iterative Berechnung von y_k erfordert nur eine konstante Berechnung, da sie nur von h_k-1 und x_k abhängt. Transformer-basierte Modelle erfordern linearen Speicher (bei Verwendung des KV-Cache) und müssen alle vorherigen Token speichern, einschließlich der in der Transformer-Zwischenschicht, aber Aaren-basierte Modelle erfordern nur konstanten Speicher. Und es ist nicht erforderlich, alle vorherigen Token zu speichern, wodurch Aarens in Bezug auf die Recheneffizienz deutlich besser ist als Transformer. Ziel des experimentellen Teils ist es, Aaren und Transformer hinsichtlich Leistung und benötigter Ressourcen (Zeit und Speicher) zu vergleichen. Für einen umfassenden Vergleich führten die Autoren Bewertungen zu vier Problemen durch: Reinforcement Learning, Ereignisvorhersage, Zeitreihenvorhersage und Zeitreihenklassifizierung. Der Autor verglich zunächst die Leistung von Aaren und Transformer beim Reinforcement Learning. Reinforcement Learning ist in interaktiven Umgebungen wie Robotik, Empfehlungsmaschinen und Verkehrssteuerung beliebt. Die Ergebnisse in Tabelle 1 zeigen, dass Aaren in allen 12 Datensätzen und 4 Umgebungen eine mit Transformer vergleichbare Leistung erbringt. Im Gegensatz zu Transformer ist Aaren jedoch auch ein RNN und kann daher neue Umgebungsinteraktionen in kontinuierlichen Berechnungen effizient verarbeiten, wodurch es sich besser für bestärkendes Lernen eignet. Als nächstes verglich der Autor die Leistung von Aaren und Transformer bei der Ereignisvorhersage. Ereignisvorhersagen sind in vielen realen Umgebungen beliebt, beispielsweise im Finanzwesen (z. B. Transaktionen), im Gesundheitswesen (z. B. Patientenbeobachtung) und im E-Commerce (z. B. Einkäufe). Die Ergebnisse in Tabelle 2 zeigen, dass Aaren in allen Datensätzen auf Augenhöhe mit Transformer abschneidet.Aarens Fähigkeit, neue Eingaben effizient zu verarbeiten, ist besonders nützlich in Umgebungen zur Ereignisvorhersage, in denen Ereignisse in unregelmäßigen Strömen auftreten. Dann verglich der Autor die Leistung von Aaren und Transformer bei der Zeitreihenvorhersage. Zeitreihenprognosemodelle werden häufig in Bereichen eingesetzt, die mit Klima (z. B. Wetter), Energie (z. B. Angebot und Nachfrage) und Wirtschaft (z. B. Aktienkurse) zusammenhängen. Die Ergebnisse in Tabelle 3 zeigen, dass Aaren bei allen Datensätzen eine mit Transformer vergleichbare Leistung erbringt. Im Gegensatz zu Transformer kann Aaren jedoch Zeitreihendaten effizient verarbeiten, wodurch es besser für zeitreihenbezogene Felder geeignet ist. ZeitreihenklassifizierungAls nächstes verglich der Autor die Leistung von Aaren und Transformer bei der Zeitreihenklassifizierung. Die Klassifizierung von Zeitreihen ist in vielen wichtigen Anwendungen üblich, beispielsweise bei der Mustererkennung (z. B. Elektrokardiogramm), der Erkennung von Anomalien (z. B. Bankbetrug) oder der Fehlervorhersage (z. B. Schwankungen im Stromnetz). Wie aus Tabelle 4 ersichtlich ist, schneidet Aaren in allen Datensätzen auf Augenhöhe mit Transformer ab. Abschließend vergleicht der Autor die von Aaren und Transformer benötigten Ressourcen. Speicherkomplexität: In Abbildung 5 (links) vergleichen die Autoren die Speichernutzung von Aaren und Transformer (unter Verwendung des KV-Cache) zur Inferenzzeit. Es ist ersichtlich, dass durch die Verwendung der KV-Cache-Technologie die Speichernutzung von Transformer linear zunimmt. Im Gegensatz dazu nutzt Aaren unabhängig davon, wie die Anzahl der Token wächst, nur eine konstante Menge an Speicher und ist daher viel effizienter. Zeitkomplexität: In Abbildung 5 (rechts) vergleicht der Autor die kumulierte Zeit, die Aaren und Transformer (unter Verwendung des KV-Cache) benötigen, um eine Folge von Token nacheinander zu verarbeiten. Für Transformer ist der kumulative Berechnungsbetrag das Quadrat der Anzahl der Token, d. h. O (1 + 2 + ... + N) = O (N^2). Im Gegensatz dazu ist Aarens kumulativer Rechenaufwand linear. In der Abbildung können Sie sehen, dass die vom Modell benötigte kumulative Zeit zu ähnlichen Ergebnissen führt. Insbesondere erhöht sich die von Transformer benötigte Gesamtzeit quadratisch, während die von Aaren benötigte Gesamtzeit linear zunimmt. Anzahl der Parameter: Aufgrund der Notwendigkeit, den anfänglichen verborgenen Zustand q zu lernen, benötigt das Aaren-Modul etwas mehr Parameter als das Transformer-Modul. Da q jedoch nur ein Vektor ist, ist der Unterschied nicht signifikant. Durch empirische Messungen an ähnlichen Modellen stellten die Autoren fest, dass Transformer 3.152.384 Parameter verwendete. Im Vergleich dazu verwendet das entsprechende Aaren 3.152.896 Parameter, was einer Parametersteigerung von nur 0,016 % entspricht – ein vernachlässigbarer Preis für den erheblichen Unterschied in der Speicher- und Zeitkomplexität. Das obige ist der detaillierte Inhalt vonNeue Arbeit von Bengio et al.: Attention kann als RNN angesehen werden. Das neue Modell ist vergleichbar mit Transformer, ist aber super speichersparend.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn



 Um dieses Problem zu lösen, stellt der Autor in Abschnitt 3.2 eine effiziente Methode zur Berechnung der Aufmerksamkeit in Many-to-Many-RNN vor, die auf einem parallelen Präfix-Scan-Algorithmus basiert. Auf dieser Grundlage stellte der Autor Aaren in Abschnitt 3.3 vor – ein recheneffizientes Modul, das nicht nur parallel trainiert werden kann (genau wie Transformer), sondern auch während der Inferenz effizient mit neuen Token aktualisiert werden kann und nur einen konstanten Speicher benötigt (gerade). wie traditionelles RNN).
Um dieses Problem zu lösen, stellt der Autor in Abschnitt 3.2 eine effiziente Methode zur Berechnung der Aufmerksamkeit in Many-to-Many-RNN vor, die auf einem parallelen Präfix-Scan-Algorithmus basiert. Auf dieser Grundlage stellte der Autor Aaren in Abschnitt 3.3 vor – ein recheneffizientes Modul, das nicht nur parallel trainiert werden kann (genau wie Transformer), sondern auch während der Inferenz effizient mit neuen Token aktualisiert werden kann und nur einen konstanten Speicher benötigt (gerade). wie traditionelles RNN).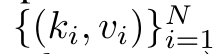 Es wird einer einzelnen Ausgabe zugeordnet: o_N = Attention (q, k_1:N, v_1:N). Bei s_i = dot (q, k_i) kann die Ausgabe o_N ausgedrückt werden als:
Es wird einer einzelnen Ausgabe zugeordnet: o_N = Attention (q, k_1:N, v_1:N). Bei s_i = dot (q, k_i) kann die Ausgabe o_N ausgedrückt werden als: 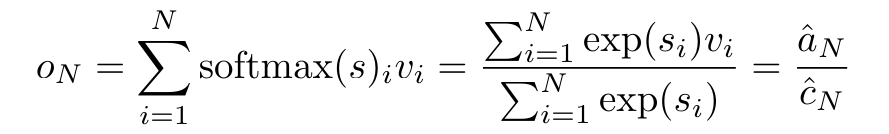
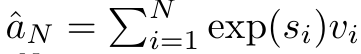 und der Nenner
und der Nenner 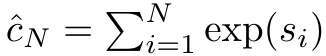 ist. Wenn man sich Aufmerksamkeit als RNN vorstellt, können
ist. Wenn man sich Aufmerksamkeit als RNN vorstellt, können 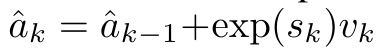 und
und  iterativ in einer rollierenden Summationsweise berechnet werden, wenn k = 1,...,.... In der Praxis ist diese Implementierung jedoch instabil und leidet unter numerischen Problemen aufgrund der begrenzten Präzisionsdarstellung und möglicherweise sehr kleinen oder sehr großen Exponenten (d. h. exp (s)). Um dieses Problem zu lindern, verwendet der Autor den kumulativen Maximalterm
iterativ in einer rollierenden Summationsweise berechnet werden, wenn k = 1,...,.... In der Praxis ist diese Implementierung jedoch instabil und leidet unter numerischen Problemen aufgrund der begrenzten Präzisionsdarstellung und möglicherweise sehr kleinen oder sehr großen Exponenten (d. h. exp (s)). Um dieses Problem zu lindern, verwendet der Autor den kumulativen Maximalterm 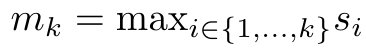 , um die Rekursionsformel zur Berechnung von
, um die Rekursionsformel zur Berechnung von 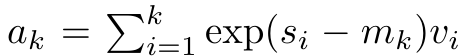 und
und 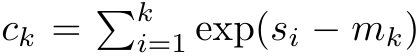 neu zu schreiben. Es ist erwähnenswert, dass das Endergebnis dasselbe ist
neu zu schreiben. Es ist erwähnenswert, dass das Endergebnis dasselbe ist 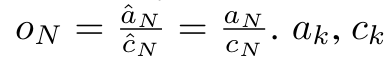 , die Schleifenberechnung von m_k lautet wie folgt:
, die Schleifenberechnung von m_k lautet wie folgt: 

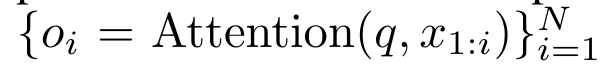 . Zu diesem Zweck verwenden die Autoren den parallelen Präfix-Scan-Algorithmus (siehe Algorithmus 1), eine parallele Rechenmethode, die N Präfixe aus N aufeinanderfolgenden Datenpunkten über den Korrelationsoperator ⊕ berechnet.Dieser Algorithmus kann
. Zu diesem Zweck verwenden die Autoren den parallelen Präfix-Scan-Algorithmus (siehe Algorithmus 1), eine parallele Rechenmethode, die N Präfixe aus N aufeinanderfolgenden Datenpunkten über den Korrelationsoperator ⊕ berechnet.Dieser Algorithmus kann 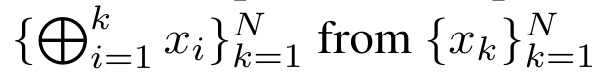

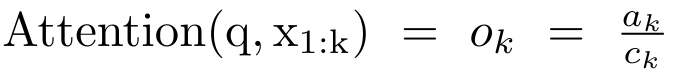 effizient berechnen, wobei
effizient berechnen, wobei 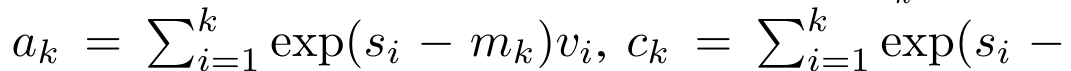
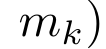 ,
, 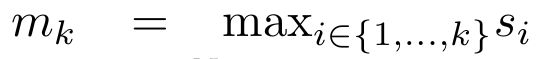 Um
Um 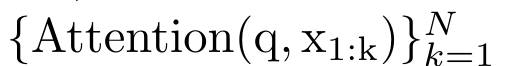 effizient zu berechnen, können
effizient zu berechnen, können 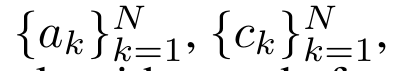 und
und  durch einen parallelen Scan-Algorithmus berechnet und dann zur Berechnung mit a_k und c_k kombiniert werden
durch einen parallelen Scan-Algorithmus berechnet und dann zur Berechnung mit a_k und c_k kombiniert werden  . ⊕ ,
. ⊕ ,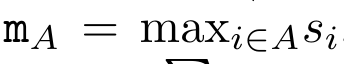 , wobei
, wobei 
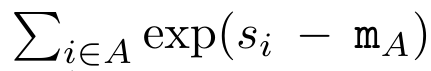 ,
, 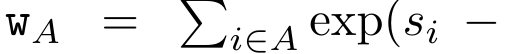
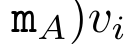 .
. 
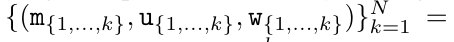
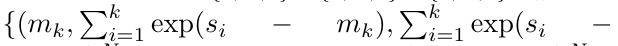
 aus. Auch bekannt als
aus. Auch bekannt als 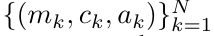 . Durch die Kombination der letzten beiden Werte des Ausgabetupels wird
. Durch die Kombination der letzten beiden Werte des Ausgabetupels wird 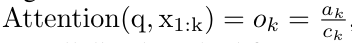 abgerufen, was zu einer effizienten parallelen Methode zur Berechnung der Aufmerksamkeit als Viele-zu-Viele-RNN führt (Abbildung 3).
abgerufen, was zu einer effizienten parallelen Methode zur Berechnung der Aufmerksamkeit als Viele-zu-Viele-RNN führt (Abbildung 3).