
Heim >Technologie-Peripheriegeräte >KI >CLIP wird als CVPR ausgewählt, wenn es als RNN verwendet wird: Es kann unzählige Konzepte ohne Schulung segmentieren | Oxford University & Google Research
CLIP wird als CVPR ausgewählt, wenn es als RNN verwendet wird: Es kann unzählige Konzepte ohne Schulung segmentieren | Oxford University & Google Research

- PHPzOriginal
- 2024-06-09 12:53:28496Durchsuche
Rufen Sie CLIP in einer Schleife auf, um unzählige Konzepte ohne zusätzliche Schulung effektiv zu segmentieren.
Jede Phrase, einschließlich Filmfiguren, Sehenswürdigkeiten, Marken und allgemeine Kategorien.
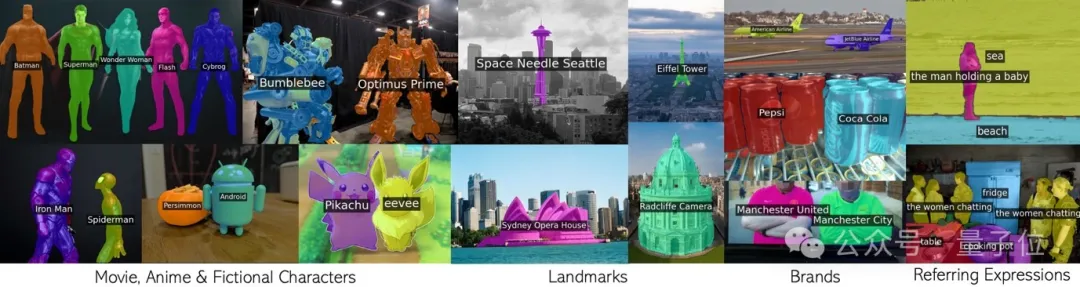
Diese neue Errungenschaft des gemeinsamen Teams der Universität Oxford und Google Research wurde von CVPR 2024 akzeptiert und der Code wurde als Open Source bereitgestellt.

Das Team schlug eine neue Technologie namens CLIP as RNN (kurz CaR) vor, die mehrere Schlüsselprobleme im Bereich der Bildsegmentierung mit offenem Vokabular löst:
- Keine Trainingsdaten erforderlich: Traditionelle Methoden erfordern eine große Menge an Ob Maskenanmerkungen oder ein Bild-Text-Datensatz zur Feinabstimmung, die CaR-Technologie funktioniert ohne zusätzliche Trainingsdaten.
- Einschränkungen des offenen Vokabulars: Vorab trainierte visuelle Sprachmodelle (VLMs) sind nach der Feinabstimmung nur begrenzt in der Lage, mit offenem Vokabular umzugehen. Die CaR-Technologie bewahrt den großen Vokabularraum von VLMs.
- Textabfrageverarbeitung für Konzepte, die nicht in Bildern enthalten sind: Ohne Feinabstimmung ist es für VLMs schwierig, Konzepte, die nicht in Bildern vorhanden sind, genau zu segmentieren. CaR wird schrittweise durch einen iterativen Prozess optimiert, um die Segmentierungsqualität zu verbessern.
Inspiriert von RNN, zyklischer Aufruf von CLIP
Um das Prinzip von CaR zu verstehen, müssen Sie zuerst das wiederkehrende neuronale Netzwerk RNN überprüfen.
RNN führt das Konzept des verborgenen Zustands ein, der wie ein „Gedächtnis“ ist, das Informationen aus vergangenen Zeitschritten speichert. Und jeder Zeitschritt hat den gleichen Satz an Gewichten, wodurch Sequenzdaten gut modelliert werden können.
Inspiriert von RNN ist CaR auch als zyklisches Framework konzipiert, das aus zwei Teilen besteht:
- Maskenvorschlagsgenerator: generiert mit Hilfe von CLIP eine Maske für jede Textabfrage.
- Maskenklassifikator: Verwenden Sie dann ein CLIP-Modell, um den Übereinstimmungsgrad jeder generierten Maske und der entsprechenden Textabfrage zu bewerten. Wenn der Übereinstimmungsgrad niedrig ist, wird die Textabfrage eliminiert.
Durch die weitere Iteration auf diese Weise wird die Textabfrage immer genauer und die Qualität der Maske wird immer höher.
Wenn sich der Abfragesatz schließlich nicht mehr ändert, kann das endgültige Segmentierungsergebnis ausgegeben werden.

Der Grund für die Entwicklung dieses rekursiven Frameworks besteht darin, das „Wissen“ des CLIP-Vortrainings maximal beizubehalten.
Im CLIP-Vortraining sind viele Konzepte zu sehen, die alles abdecken, von Prominenten über Wahrzeichen bis hin zu Anime-Charakteren. Wenn Sie einen aufgeteilten Datensatz verfeinern, wird der Wortschatz zwangsläufig erheblich schrumpfen.
Zum Beispiel kann das SAM-Modell „Alles teilen“ nur eine Flasche Coca-Cola erkennen, aber nicht einmal eine Flasche Pepsi-Cola.

Aber wenn CLIP direkt zur Segmentierung verwendet wird, ist der Effekt nicht zufriedenstellend.
Das liegt daran, dass das Pre-Training-Ziel von CLIP ursprünglich nicht für eine dichte Vorhersage konzipiert war. Insbesondere wenn bestimmte Textabfragen im Bild nicht vorhanden sind, kann CLIP leicht falsche Masken generieren.
CaR löst dieses Problem geschickt durch Iteration im RNN-Stil. Durch wiederholtes Auswerten und Filtern von Abfragen bei gleichzeitiger Verbesserung der Maske wird schließlich eine qualitativ hochwertige Segmentierung des offenen Vokabulars erreicht.
Lassen Sie uns abschließend der Interpretation des Teams folgen und mehr über die Details des CaR-Frameworks erfahren.
Technische Details zum CaR
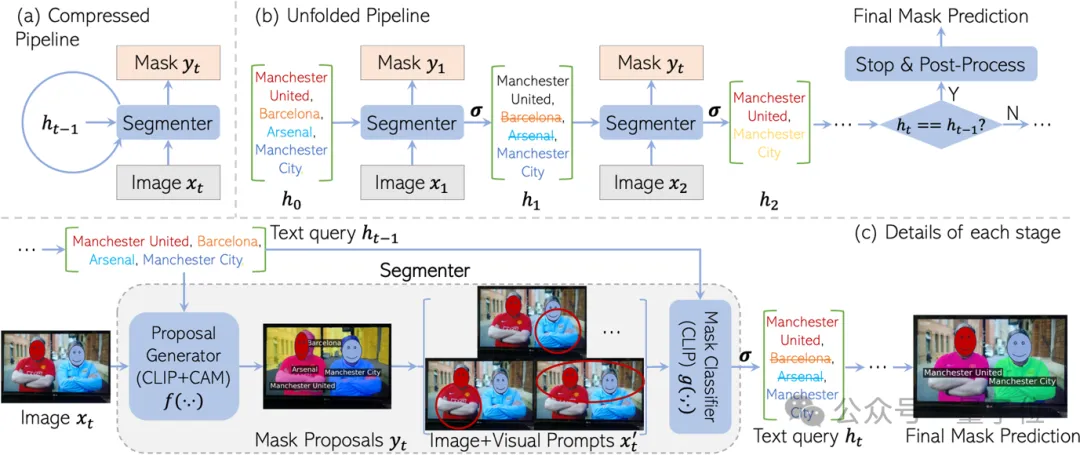
- Rekurrentes neuronales Netzwerk-Framework: CaR verwendet ein neuartiges zyklisches Framework, um die Korrespondenz zwischen Textabfragen und Bildern durch einen iterativen Prozess kontinuierlich zu optimieren.
- Zweistufiger Segmentierer: Er besteht aus einem Maskenvorschlagsgenerator und einem Maskenklassifikator, die beide auf dem vorab trainierten CLIP-Modell basieren, und die Gewichte bleiben während des Iterationsprozesses unverändert.
- Maskenvorschlagsgenerierung: Mithilfe der gradCAM-Technologie werden Maskenvorschläge basierend auf Ähnlichkeitswerten von Bild- und Textmerkmalen generiert.
- Visuelle Hinweise: Wenden Sie visuelle Hinweise wie rote Kreise, Hintergrundunschärfe usw. an, um den Fokus des Modells auf bestimmte Bildbereiche zu verstärken.
- Schwellenwertfunktion: Durch Festlegen eines Ähnlichkeitsschwellenwerts werden Maskenvorschläge herausgefiltert, die stark mit der Textabfrage übereinstimmen.
- Nachbearbeitung: Maskenverfeinerung mithilfe dichter bedingter Zufallsfelder (CRF) und optionaler SAM-Modelle.
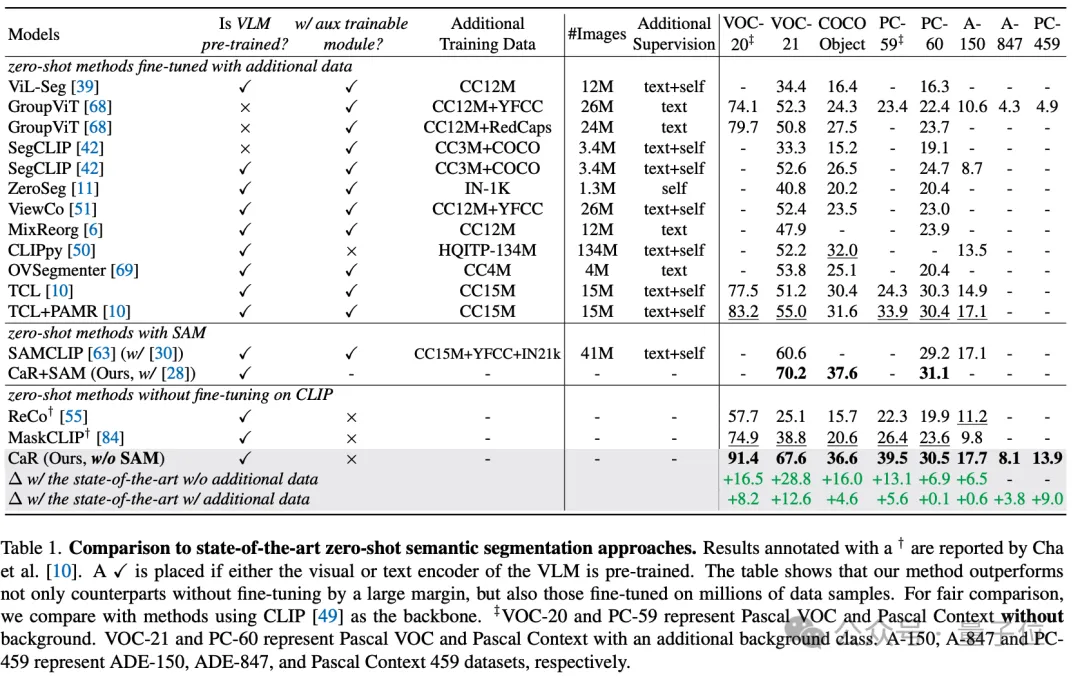
Durch diese technischen Mittel hat die CaR-Technologie erhebliche Leistungsverbesserungen bei mehreren Standarddatensätzen erzielt, die herkömmliche Zero-Shot-Lernmethoden übertreffen, und auch im Vergleich zu Modellen, die einer umfassenden Datenfeinabstimmung unterzogen wurden, eine überlegene Leistung gezeigt. Wie in der folgenden Tabelle gezeigt, ist zwar kein zusätzliches Training und keine Feinabstimmung erforderlich, CaR zeigt jedoch bei acht verschiedenen Indikatoren der semantischen Zero-Shot-Segmentierung eine bessere Leistung als frühere Methoden, die auf zusätzlichen Daten feinabgestimmt wurden.
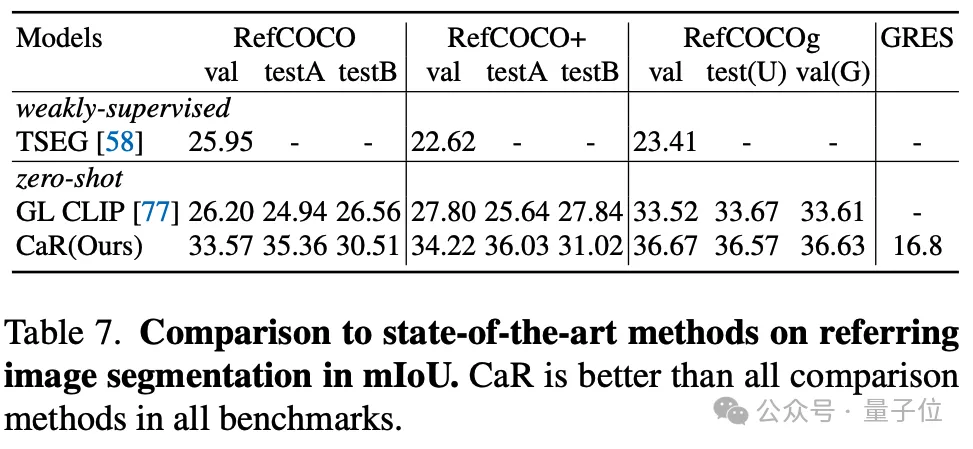
Der Autor testete auch die Wirkung von CaR auf die Nullstichproben-Referenzsegmentierung. Auch die Referenzsegmentierung zeigte eine stärkere Leistung als die vorherige Nullstichprobenmethode.
Zusammenfassend ist CaR (CLIP als RNN) ein innovatives wiederkehrendes neuronales Netzwerk-Framework, das semantische und referenzielle Bildsegmentierungsaufgaben ohne zusätzliche Trainingsdaten effektiv ausführen kann. Es verbessert die Segmentierungsqualität erheblich, indem der breite Vokabularraum vorab trainierter visueller Sprachmodelle erhalten bleibt und ein iterativer Prozess genutzt wird, um die Ausrichtung von Textabfragen mit Maskenvorschlägen kontinuierlich zu optimieren.
Die Vorteile von CaR sind seine Fähigkeit, komplexe Textabfragen ohne Feinabstimmung zu verarbeiten und seine Skalierbarkeit auf den Videobereich, was bahnbrechende Fortschritte im Bereich der Bildsegmentierung mit offenem Vokabular bringt.
Papierlink: https://arxiv.org/abs/2312.07661.
Projekthomepage: https://torrvision.com/clip_as_rnn/.
Das obige ist der detaillierte Inhalt vonCLIP wird als CVPR ausgewählt, wenn es als RNN verwendet wird: Es kann unzählige Konzepte ohne Schulung segmentieren | Oxford University & Google Research. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!